







正则表达式与通配符是完全不一样的东西。通配符是bash接口的一个功能,正在表达式是一种字符串处理的表示方式。一些特殊字符的意义:
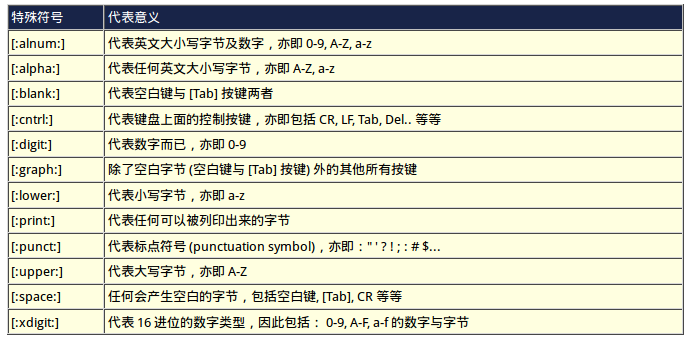
grep [-acinvAB] [--color=auto] '查找字符串' filename
-a: 将binary文件以text文件的方式查找数据
-c:计算找到‘查找字符串’的次数
-i : 忽略大小写的不同,所以大小写视为相同
-n:显示行号
-v: 反向选择
-A:后面可加数字,是after的意思,除了列出该行外,后续的n行也列出来
-B :后面可加数字,是before的意思,除了列出该行外,前面的n行也列出来
--color=auto:将找到的关键字加上颜色
正则表达式中,^:行首,$:行尾,^$:表示空白行,^在[]中表示反向选择
查找空白行:
grep -n '^$' regular_express.txt
去除shell文本的注释(#开头)去除空白行
grep -v '^$' man.config | grep -v '^#'点. :表示一定有一个任意字符 *(星号):表示重复前一个0到无穷多次的意思, .* 可表示0个或多个任意字符,而在通配符中*表示0个到无限多个字符,通配符与正则表达式不同!正则表达式表:

扩展的正则表达式,grep默认支持基础正则表达式,如果使用扩展的,则使用grep -E或直接使用egrep
之前的使用grep -v '^$' man.config | grep -v '^#',需要查找两次,如果使用扩展正则表达式则是 egrep -v '^$|^#' man.config, 在单引号内|表示or或的意思,通过一次查找将空白行和以#开头的行都去除,扩展正则表达式:

*:0个或多个前一个字符,+:1个或多个前个字符, ?:0个或1个字符,\{n,m\}:n到m个前字符 , \:转义字符
^: 开头,$:结尾 , [|:列表 [^]:不包含列表内字符 or查找字符串, ():找出组
!并不是特殊字符
sed命令:
sed [-nefr] 动作
-n:使用安静模式,在一般的sed用法中,所有都会输出在屏幕上,如果加上-n,则只有经过sed特殊处理的行才会列出来
-e:直接在命令行模式上进行sed,默认,可省略
-f: 直接将动作写在一个文件内,-f filename可以直接执行filename的sed动作
-r:支持扩展正则表达式
-i:直接修改读取的内容,而不是由屏幕输出
动作:[n1[,n2]] function, n1,n2代表执行动作的行数,可选
a:新增,a的后面可以接字符串,字符串会在目前下一行(新的一行)出现
c:替换,c的后面可以接字符串,字符串替换在n1, n2之间的行
d:删除,后面通常不接任何参数
i:插入,i后接字符串,字符串会在目前的上一行(新行)出现
p:打印,通常与-n一起使用,只输出打印的行
s:替换,可以搭配正则表达式,与vim替换命令类似,1,20s/old/new/g
删除批注之后的数据,以下删除的数据成了空白行
cat man.config | grep 'MAN' | sed 's/#.*$//g'
再删除空白行
cat man.config | grep 'MAN' | sed 's/#.*$//g' | sed '/^$/d'
修改原文件,将regular_express.txt内每一行结尾为‘.’换成‘!’
sed -i 's/\.$/!/g' regular_express.txt
在文件最后一行添加‘this is a test’
sed -i '$a this is a test' regular_express.txt
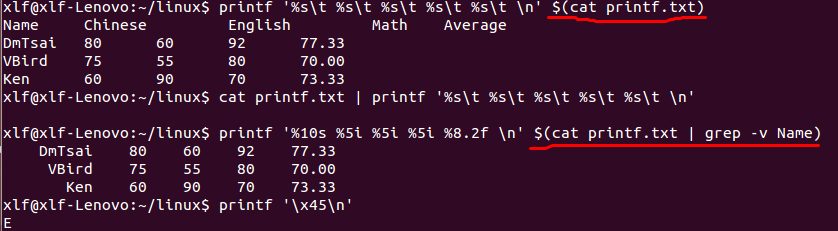
printf格式命令:

printf不是管道命令,所以不能使用|,应该使用$(cmd),如下操作
awk:数据处理工具,sed常常用于一整行的处理,awk倾向于将一行分成数个“字段”来处理,默认的分割符为空格键或tab键
awk '条件类型1{动作1} 条件类型2{动作2}...' filename
$0: 代表一整行数据,$1:第一个字段,$2:第二个字段...., awk以行为一次处理单位,而以字段为最小处理单位,awk的内置变量
| NF | 每一行($0)拥有的字段总数 |
| NR | 目前awk处理的是第几行数据 |
| FS | 目前的分割符,默认空格符 |

awk也可以有逻辑运算符:

第一条命令,第一行输出不正确,因为读入第1行时,变量默认是以空格键分割的(鸟哥是这么说的,为啥呢),FS=:的条件仅能在第2行以后生效,但awk可以预设遍历,利用BEGIN关键字就可以了,还有END关键字。
awk的处理流程:
1 读入第一行,并将第一行的数据填入$0, $1, $2等变量中
2 依据条件类型的限制,判断是否需要进行后面的动作
3 做完所有的动作与条件类型
4 若还有行,则重复1,2,3,直到所有数据读取完。
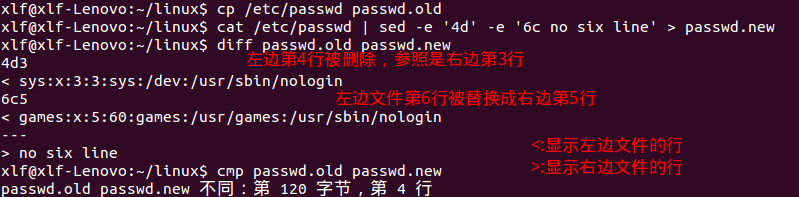
比较文件的工具:
diff, cmp,diff以行为单位进行比较,主要用在新旧版本上的比较, diff也可以比较两个目录的不同,cmp以字节为单位进行比较,
如下比较:















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









