






第十七周:机器学习基础回顾
摘要
本周回顾了机器学习基础,以及了解了Transformer在计算机视觉领域的应用。二分类是计算机视觉中常见的任务之一,通过将图像划分为两个类别,我们可以实现诸如图像分类、目标检测等任务。借助深度学习的方法,我们能够有效地训练分类模型,以进行高精度的图像分类。随机初始化是深度学习中的一个重要步骤。通过在网络中引入随机性,我们能够更好地突破局部最优解,从而提高模型的泛化能力,并避免陷入过拟合的问题。正则化是提高模型泛化能力的一种常用方法。通过在损失函数中引入正则化项,我们能够对模型的复杂度进行约束,从而防止过拟合问题的发生。本文将详细介绍二分类、随机初始化、核对矩阵维数、正则化的原理及过程。
Abstract
This week reviewed machine learning fundamentals as well as learned about Transformer’s application in computer vision. Binary classification is one of the common tasks in computer vision and by dividing an image into two categories, we can achieve tasks such as image classification and target detection. With the help of deep learning methods, we are able to effectively train classification models for high accuracy image classification. Random initialization is an important step in deep learning. By introducing randomness into the network, we are able to better break through the local optimum solution, thus improving the generalization ability of the model and avoiding the problem of falling into overfitting. Regularization is a common method to improve the generalization ability of the model. By introducing a regularization term in the loss function, we are able to constrain the complexity of the model, thus preventing the overfitting problem. In this paper, we will introduce the principle and process of bisection, random initialization, kernel matrix dimension, and regularization in detail.
1. 二分类
当我们有m个样本的训练集时,我们可能会习惯的去遍历这个样本数据,但事实上,在实现一个神经网络,如果我们要遍历整个样本集,并不需要通过for循环来进行。
神经网络在计算过程中,往往会有一个正向过程,也就是正向传播,同时也有一个反向过程(反向传播),本小节,我们将来了解神经网络为什么计算过程可以分为正向传播和反向传播。
逻辑回归是用于二分类的算法,我们用简单的例子来解释二分类问题,例如我们图片输入的是一个小猫的照片,通过二分类算法,我们可以输出对应识别此图的标签,如果是小猫,那输出结果为1,反之则输出结果为0 。这便是二分类。

接下来我们来看看,这张图片在计算机中是如何表示的。
计算机保存一张图片,要保存三个独立矩阵,分别为红、绿、蓝三个颜色通道,如果输入的图片是6464像素的,那么对应的三个矩阵大小均为6464,然后我们要把这三个矩阵放进一个特征向量中,即把这些像素值都提出来,放入一个特征向量x,将三个矩阵向量的每个像素点的值加到特征向量x上,这也就知道,如果三个颜色通道的大小是64*64,那么特征向量x的大小也就为64 * 64 * 3 。
在二分类问题中,我们的目标是训练一个分类器,它以图片的特征向量x作为输入,预测输出的结果标签y是1还是0。
常见的二分类算法是逻辑回归算法和线性回归算法。
线性回归算法过于简单了,其w和b不管如何变化,线性回归始终都是一条直线,因此无法拟合复杂的折线,就比如我们现在要预测一个视频的点阅量,可能今天点阅量很高,明天点阅量就下降了,这种情况线性回归不能够准确预测,这也是其最大的一个缺陷。
为了解决这种问题,也就有了逻辑回归,而逻辑回归与线性回归的区别在于,逻辑回归增加了sigmod、ReLU、tanh等激活函数,而这些激活函数均是非线性的,取值范围在0~1,而二分类恰恰需要最终输出的值是0还是1,即 y = σ ( w x + b ) y= \sigma(wx+b) y=σ(wx+b),加上激活函数后,预测效果更好。具体线性回归和逻辑回归基础请见 http://t.csdnimg.cn/bMHsf,这里不过多赘述。
2. 随机初始化
当我们训练神经网络时,随机初始化权重非常重要,对于逻辑回归,我们可以将权重初始化为零,但如果将神经网络的各个参数数组全部初始化为0,再使用梯度下降算法,那将会完全无效。
我们来看看这是为什么,假设我们有两个输入特征,输入层有两个隐藏单元
x
1
、
x
2
x_1、x_2
x1、x2,由这两个输入单元可以得到
a
1
[
1
]
、
a
2
[
1
]
a^{[1]}_{1}、a^{[1]}_{2}
a1[1]、a2[1],即隐藏层有两个隐藏单元,所以和隐层相关的矩阵
w
[
1
]
w^{[1]}
w[1]就为一个 2*2 的权重矩阵,假设我们将其初始化为0,即权重矩阵里所有的值都为0,对应得偏置矩阵
b
[
1
]
b^{[1]}
b[1] 也全为0,这种初始化形式得问题在于,无论我们初始给神经网络输入任何的样本数据,最终到达隐层的时候,得到的
a
1
[
1
]
、
a
2
[
1
]
a^{[1]}_{1}、a^{[1]}_{2}
a1[1]、a2[1]是一样的,即两个隐藏单元都在做完全一样的计算。当我们计算反向传播时,出于对称性
d
z
1
[
1
]
、
d
z
2
[
1
]
d^{[1]}_{z_{1}}、d^{[1]}_{z_{2}}
dz1[1]、dz2[1]也是相同的,这两个隐藏单元会以同样的方式初始化。如果以这种方式初始化,那么隐藏层里的隐藏单元就完全一样了。

我们需要隐藏层的两个隐藏单元是不同的,去计算不同的函数,这个问题的解决方案是随机初始化所有参数,我们可以令 w^{[1]}=np.random.randn(2,2)*0.01,这可以产生参数为(2,2)的高斯分布随机变量,然后再乘上一个很小的数字,比如0.01,然后偏置矩阵b初始化成0是可以的,因为b^{[1]}=np.zeros(2,1)

3. 核对矩阵的维数
当我们实现深度神经网络的时候,我们常用的检查代码有错的方法就是检查算法中各个矩阵的维数,接下来将通过一个具体的神经网络来了解具体该如何做。

这里的神经网络,除了输入层,一共有5层,总共4个隐层,一个输出层,如果我们想实现正向传播,第一步是 z [ 1 ] = w [ 1 ] ∗ x + b z^{[1]}=w^{[1]}*x+b z[1]=w[1]∗x+b,这里的第一隐层有三个隐藏单元
n [ 0 ] = 2 n^{[0]}=2 n[0]=2表示的是第0层(输入层)有两个样本数据,然后我们来看看z、w、x的维数,z是第一个隐藏激活函数向量,在第一个隐藏层中,z的维度是3 * 1,也就是一个三维的向量,我们可以将其写出 ( n [ 1 ] , 1 n^{[1]},1 n[1],1),接下来看输入特征x,x在这里有两个输入特征,所以x的维度是 2 * 1,可以将其写出 ( n [ 0 ] , 1 n^{[0]},1 n[0],1),所以我们可以将 w 的维数求出来,w的维数就为 3 * 2,可以写出 ( n [ 1 ] , n [ 0 ] n^{[1]},n^{[0]} n[1],n[0]),总结下来 w [ l ] w^{[l]} w[l] 的维度必须是 ( n [ l ] , n [ l − 1 ] n^{[l]},n^{[l-1]} n[l],n[l−1])。
然后我们来看向量b的维度,b是一个 3 * 1 的向量,如果我们要做向量加法,我们必须再加上同样 3 * 1 维度的向量,b的维度必须和
w
[
l
]
x
w^{[l]}x
w[l]x 的维度一致

3. 正则化
正则化是解决训练过拟合的一种常见方式。
过拟合(overfitting)是指机器学习模型在训练数据上表现良好,但在新的未见过的数据上表现较差的情况。这种情况通常出现在模型过于复杂或样本不平衡的情况下。
过拟合发生的原因是模型过于拟合训练数据,从而失去了对未见过的数据的泛化能力。当模型过于复杂时,它可以记住训练数据中的噪声和异常值,导致对新数据的预测出现错误。此外,如果训练数据中某些类别的样本数量远远超过其他类别,模型可能会更关注这些类别,而忽略其他类别的学习。
接下来我们就来一起回顾下正则化的作用原理。
L2正则化
我们用逻辑回归来实现这些设想,损失函数
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
i
,
y
i
)
+
λ
2
m
∣
∣
w
∣
∣
2
2
J(w,b)=\frac{1}{m} \sum_{i=1}^{m}L(\hat{y}^{i},y^{i})+\frac{\lambda}{2m}||w||^{2}_{2}
J(w,b)=m1∑i=1mL(y^i,yi)+2mλ∣∣w∣∣22,在逻辑回归函数中加入正则化,只需添加参数
λ
\lambda
λ ,也就是正则化参数,即加上
λ
2
m
\frac{\lambda}{2m}
2mλ乘上w平方的范数,
∣
∣
w
∣
∣
2
2
=
∑
j
=
1
n
x
w
j
2
=
w
T
w
||w||^{2}_{2}=\sum_{j=1}^{n_x}w^{2}_{j}=w^{T}w
∣∣w∣∣22=∑j=1nxwj2=wTw,此方法称为L2正则化。
L1正则化
L1正则化加的不是L2范数,而是正则项
λ
m
\frac{\lambda}{m}
mλ
∑
i
=
1
n
x
∣
w
∣
=
λ
m
∣
∣
w
∣
∣
1
\sum_{i=1}^{n_x}|w|=\frac{\lambda}{m}||w||_{1}
∑i=1nx∣w∣=mλ∣∣w∣∣1,如果用L1正则化,w最终会是稀疏的,也就是说w向量中会有很多的0,我们在正则化时,更倾向于用L2正则化。
4 Transformer在计算机视觉领域的应用
Transformer最早应用于自然语言处理领域,是一种主要基于自注意力机制的深度神经网络。由于其强大的表示能力,研究人员正在寻找将 Transformer 应用于计算机视觉任务的方法。在各种视觉基准中,基于 Transformer 的模型的性能与其他类型的网络(例如CNN和RNN)相似或更好。在本文中,作者通过对不同任务进行分类并分析它们的优缺点来回顾这些基于Transfomer架构的视觉模型,主要类别包括主干网络、高/中级视觉、低级视觉和视频处理,此外,作者还提供了用于将Transformer应用于实际应用程序的方法。
在视觉应用中,CNN 被认为是基本组成部分,我们可以通过训练了一个序列转换器来自动回归预测像素,而这种预测结果在图像分类任务上取得了与 CNN 相当的结果,由此可见Transformer 可以是 CNN 的潜在替代品。另一种视觉变换器模型是 ViT,它将纯Transformer直接应用于图像块序列以对完整图像进行分类,最近由 Dosovitskiy 等人提出,它在多个图像识别基准上实现了最先进的性能。除了图像分类之外,Transformer 还被用来解决各种其他视觉问题,包括对象检测、语义分割 、图像处理 。由于其卓越的性能,越来越多的研究人员提出基于 Transformer 的模型来改善各种视觉任务。在本文,作者将重点全面阐述Transformer在视觉领域的最新进展。这其中包括骨干网络、高/中级视觉、低级视觉、视频处理,鉴于在基于 DNN 的视觉系统中,高级和中级视觉之间的差距变得越来小,可以将其归为一类,解决这些高/中级视觉任务的 Transformer 模型的一些例子包括 DETR、用于对象检测的可变形 DETR 和用于分割的 Max-DeepLab ,Transformer很少应用在低级视觉,由于视频的顺序特性,Transformer 本质上非常适合用于视频任务,在视频任务中,它的性能开始与传统 CNN 和 RNN 相当。
【注】由于Transformer原理我们在第15周已经了解过了,具体Transformer细节原理请参见http://t.csdnimg.cn/siP9k
受了Transformer在NLP领域取得的成功的启发,越来越多的研究人员在探索Transformer架构是否对处理图像有所帮助,图像更难建模,与文本相比,它涉及更多维度、噪声和冗余模态。可以将CNN和Transformer结合,共同构成一个新的网络去进行图像处理。
除了 CNN 之外,Transformer 还可以用作图像分类的骨干网络,采用 ResNet 作为方便的基线,并使用视觉Transformer来取代最后阶段的卷积。
【注】:ResNet详解请参见:http://t.csdnimg.cn/NXBnd
具体来说,用卷积层来提取低级特征,然后将其输入视觉Transformer。对于视觉Transformer,使用标记器将像素分组为少量视觉标记,每个标记代表图像中的语义概念。这些视觉标记直接用于图像分类,而Transformer则用于对标记之间的关系进行建模。如下图所示,该工作可以分为纯粹使用Transformer进行视觉和结合CNN和Transformer。

4.1 VIT
**Vision Transformer(ViT)**是一个纯粹的Transformer架构,直接应用于图像分类任务的图像块序列,它尽可能遵循Transformer的原始设计。下图展示了ViT的框架。
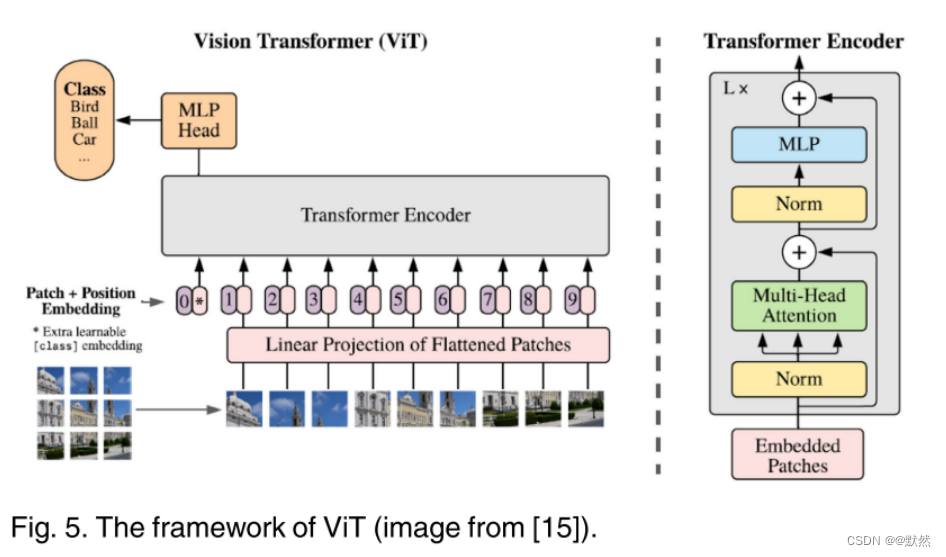
首先需要将一张
h
∗
w
∗
c
h*w*c
h∗w∗c 三通道的2D图像转化成一系列2D小图,其中
c
c
c是通道数,
(
h
,
w
)
(h,w)
(h,w)是原始图像的分辨率,而
(
p
,
p
)
(p,p)
(p,p)是每个小图的分辨率,因而,Transformer的有效序列长度为
h
w
p
2
\frac{hw}{p^{2}}
p2hw,并且Transformer网络架构的输入和输出维度始终相同,可训练的线性投影将每个矢量化路径映射到模型维度 d,其输出称为patch嵌入,将输入端的一系列小图像进行Embedding操作和位置编码操作,然后通过Transformer编码器进行图像分类,最后经过前馈神经网络和softmax归一化输出结果。在 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近甚至超过了最先进的性能。但是原始的VIT模型虽然擅长铺货各个图像小块之间的远程依赖关系,但忽略了局部特征特区。
【注】具体VIT模型详解我会在随后几周介绍
4.2 TNT
TNT(Transformer in Transformer)是一种基于Transformer模型的改进版本,在传统的Transformer模型中,自注意力机制是用于对输入序列内不同位置之间的关系进行建模的关键部分。
而在TNT中,它引入了两个层级的自注意力机制,即外部自注意力和内部自注意力。外部自注意力用于建模全局的上下文信息,类似于传统Transformer中的自注意力机制。它可以学习到全局特征和位置之间的交互关系。内部自注意力则用于更细粒度的特征建模。它将输入序列划分为多个小块,并在每个小块内部进行自注意力计算。这样可以更好地捕捉到局部特征和位置之间的关系,从而提升模型的表达能力。
通过引入外部自注意力和内部自注意力,TNT模型在一定程度上增强了对多尺度特征的处理能力,并在一些计算机视觉任务中取得了优秀的表现。这种层级结构的设计也为模型的进一步改进和优化提供了思路。
【注】这里只是简单了解一下TNT架构,在随后我会详解TNT架构
4.3 Swin Transformer
Swin Transformer 是一种基于 Transformer 架构的神经网络模型,用于图像识别和计算机视觉任务。
与传统的自然语言处理领域中使用的 Transformer 模型类似,Swin Transformer 基于自注意力机制来提取图像特征并建立图像上下文的长距离依赖关系。然而,由于图像数据的特殊性,Swin Transformer 引入了一种名为“窗口式交互”的机制,它将图像分割成多个互不重叠的子区域(或称为窗口),并仅在这些子区域上执行自注意力操作。
这种窗口式交互机制使得 Swin Transformer 可以在处理大尺寸图像时保持较低的计算和存储成本,并且能够捕捉到全局语义信息。通过引入分层的 Transformer 结构,Swin Transformer 进一步提高了模型的可扩展性和表征能力。
4.4 Shuffle Transformer
Shuffle Transformer(Shuffle 注意力机制)是一种基于自注意力机制的神经网络模型,用于处理序列数据,例如自然语言处理任务。
传统的自注意力机制在计算上的复杂度较高,随着序列长度的增加,计算成本也会呈指数级增长。为了解决这个问题,Shuffle Transformer 引入了一种称为 Shuffle 注意力机制的改进方法。这一方法通过将序列进行分组,并对分组进行注意力计算,从而在保持模型性能的同时减少计算成本。
具体而言,Shuffle Transformer 将序列分成小块,并使用“局部注意力”的方式对每个小块进行内部注意力计算。然后,在进行全局注意力时,它首先对全局范围内的信息进行交互,然后再考虑不同小块之间的交互。这种分块和交互的处理方式使得 Shuffle Transformer 在处理长序列时能够更高效地进行计算,并且具备较好的模型性能。
4.5 RegionViT
RegionViT 是一种基于 Transformer 架构的神经网络模型,用于图像识别和视觉任务。它在 2021 年由 Facebook AI 提出,旨在将 Transformer 模型应用于处理大尺寸图像的场景。
与传统的视觉 Transformers(如 ViT)只能处理固定尺寸的图像不同,RegionViT 通过引入图像分割的思想,将图像划分成多个区域,并将每个区域作为输入进行处理。这样做的目的是同时保留图像中的全局和局部信息,并且能够处理不同尺度和长宽比的图像。
RegionViT 使用类似于自然语言处理领域的 Transformer 模型中的自注意力机制,通过对图像的不同区域进行交互来捕捉图像的相关上下文。它利用局部和全局的自注意力操作,实现对区域之间的依赖关系的建模,并提取图像的特征表示。
RegionViT 是一种基于 Transformer 架构的图像处理模型,在解决处理大尺寸图像和保留全局局部特征方面具有优势。它是将自注意力机制应用于视觉领域的一项重要进展。
作为 Transformer 的关键组件,自注意力层提供了图像块之间全局交互的能力。改进self-attention层的计算吸引了许多研究人员,DeepViT提出建立跨头通信来重新生成注意力图,以增加不同层的多样性。KVT 引入了 k-NN 注意力来利用图像块的局部性,并通过仅计算具有前 k 个相似标记的注意力来忽略噪声标记。Refiner探索高维空间中的注意力扩展,并应用卷积来增强注意力图的局部模式。 还有其他类型的架构,例如双流架构和U-net架构。神经架构搜索(NAS)也被研究来寻找更好的转换器架构,例如 Scaling-ViT 、ViTAS 、AutoFormer 和 GLiT 。目前,视觉Transformer的网络设计和NAS主要借鉴了CNN的经验。除了上述方法之外,还有一些其他方向可以进一步改进视觉变压器,例如位置编码,归一化策略,快捷连接和去除注意力。
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











