







网络压缩(Network Compression):就是把一个大的网络压缩成一个小的网络。现如今,手机设备、手表等都比较流行,但我们平常训练的网络都比较大,在一些“小”的设备或许很难存储和运行。所以这就需要把网络进行压缩。
常用的方法:
Network Pruning(网络剪枝):将训练完的network不重要的参数或神经元进行删除,然后在训练一次。在我们训练网络时,有的参数或者神经元其实并没有起作用或者起很大的作用,所以可以把这些参数或者神经元删除,然后在训练一遍。但为什么要再训练一遍呢,因为你删除参数或者神经元是可能会影响之前网络的表现(performance),所以再训练一次可以把删除掉的参数或者神经元所带来的影响降到最小。
这里可能有人会想,为什么要把大网络剪枝成一个小网络,一开始训练一个小网络就行了,干嘛搞那么复杂。
原因:大的网络有很多冗余的参数,而小的网络又很难训练的,所以把大的网络删成小的网络就好了。
另外,由于神经网络训练经常是使用矩阵运算,所以一般是删除神经元,因为删除参数也就是权重的话一般是把参数设置为0,矩阵的大小并没有改变,那么也并不能做到压缩。

此图来自李宏毅老师的课程截图
Knowledge Distillation(知识蒸馏):利用一个已经学好的大model来教一个小model如何最好任务。
比如分类任务:假设大的model在对一张数字照片进行分类时,是1的概率为0.7,7的概率为0.2,9的概率为0.1,那么转化为one-hot就是[1,0,0],所以让小model学习大model的结果,也就是把同样的一张数字照片输入到小model里面,让小model得出一个结果和大model一样,从而去训练小model的参数。在这里顺便提一下,小model要学习的结果是一个概率值,也就是1的概率是0.7,7的概率是0.2,9的概率是0.1,而不是结果的one-hot编码[1,0,0],如果是结果的one-hot编码,那么就没必要训练一个大的model了,直接把label当做小model的结果,然后进行训练就好了。
那为什么要概率值当做小model 的结果呢?
原因是假设把概率值当做小model的结果,那么小model是可以学到其他数字的特征,举例来说,当小model进行训练时,训练集并没有7,但是他还是有可能识别出7这个数字,因为大model 之前训练的结果就告诉小model1和7是比较相似的,所以在没见过7的情况下小model也是有可能把7识别出来,这就是为什么小model的结果要设置大model的概率值而不是one-hot编码。
Architecture Design(调整结构设计):
假设一个网络的第一层为N个神经网络,第二层为M个神经元,中间为参数的数量W(如左图),然后我们在第一层和第二层中间插入一层linear,以达到减少参数的数量(如右图,U、V代表参数数量,K代表linear的神经元数量)。
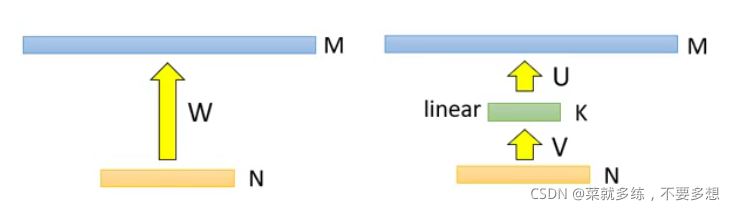 此图来自李宏毅老师的课程截图
此图来自李宏毅老师的课程截图
如上图左边的图,在中间插入linear层,那么参数的数量就会变成U+V=MK+NK
变成矩阵运算也就是下图:
参数量:
MN≈MK+N*K=(M+N)*K
当K比较小的时候,那么右边参数的数量会远小于左边参数的数量
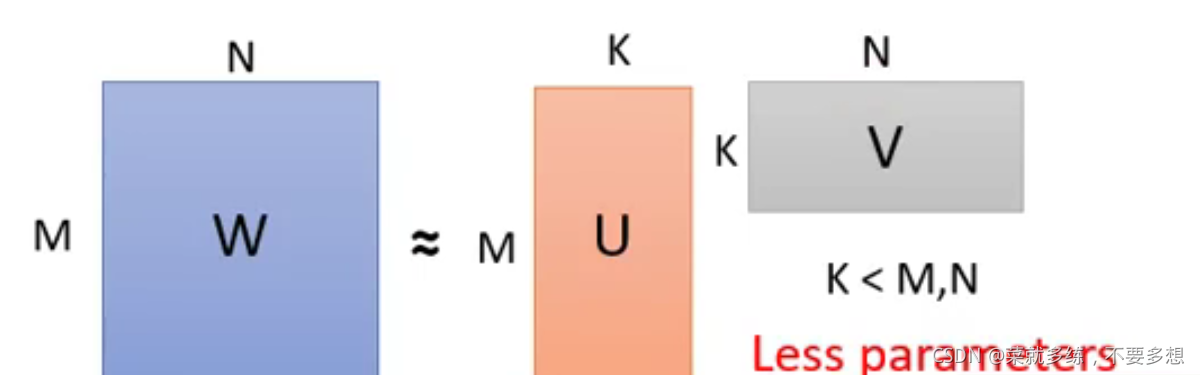 此图来自李宏毅老师的课程截图
此图来自李宏毅老师的课程截图















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









