







在训练模型时,我们经常会对数据进行归一化,甚至在隐藏层中也加入归一化。这样做的主要目的是为了加快模型收敛速度。
假设特征在经过卷积层后没有经过归一化的数据如下图分布(xx表示数据点),用sigmoid函数作为激活函数。那么在不经过归一化的时候数据所在的分布会使sigmoid的函数值接近0,这样会导致出现梯度消失的情况。

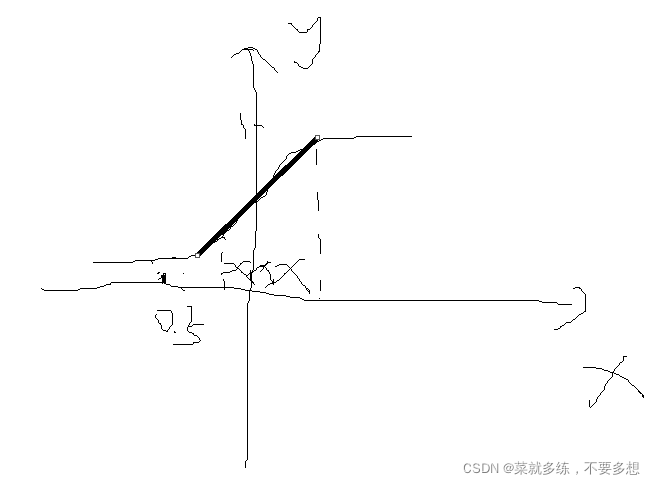
假设在对经过卷积层的数据进行归一化后,数据分布如下图所示,分布会处在中间状态,sigmoid的函数值会取到比较大的值(相对于0)。这样便会加快模型的收敛速度。
但是,我们一般并不是简单的对数据进行归一化,即让数据表现一个正态分布,如果简单地把数据进行标准化,那么就会改变原始数据的分布状态,这不利于神经网络学习原始数据的分布状态,所以在对数据进行标准化后(x-u/方差),会对标准化后的结果在进行处理。
假设标准化后的结果是x,那么再对x进行处理
z = γ * x + β
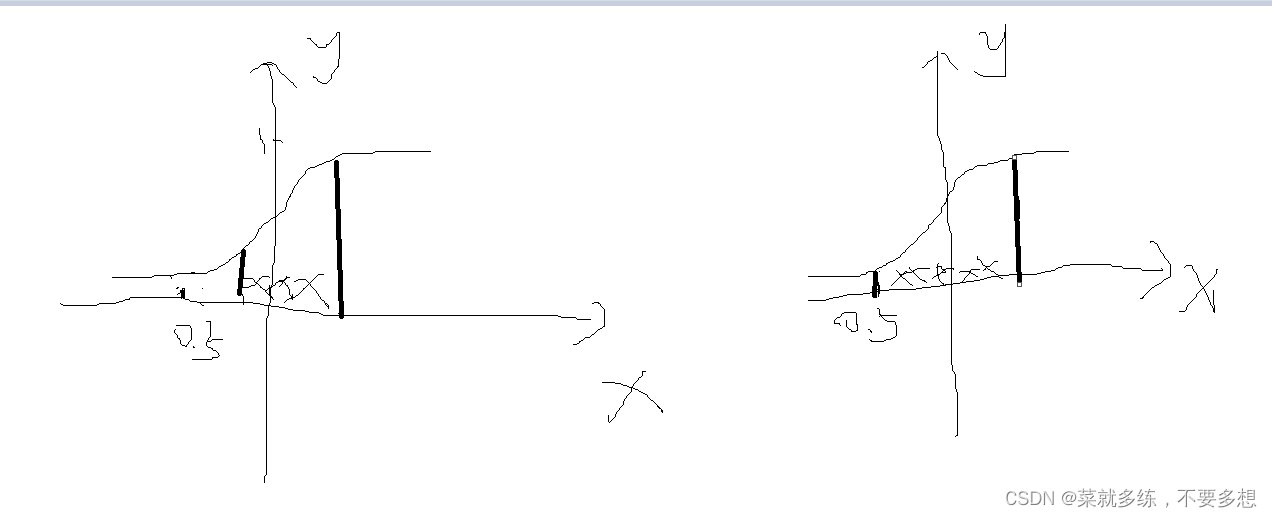
为什么要多加两个可学习的参数呢,如下图
左边为没有对x再进行处理,右边为对x再进行处理
对x再进行处理可以使x可贴近原始数据的分布,而不会单纯地让数据分布集中地处于中间那一部分。
另外,如果数据集中地处于中间那一部分,那么sigmoid中间那一部分也可以看成线性函数了,这样也弱化了加激活函数的作用。激活函数本身就是想增强网络的非线性能力。
以上处于个人理解,如果有错误欢迎指正。














 1305
1305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









