






Day2 加载数据
前言:Dataset 和 DataLoader
pytorch中有关加载数据的操作,主要涉及Dataset和DataLoader。
其中,Dataset主要获取数据,包括如何读取对应数据和获取数据的数量即长度len(这样可以知道什么时候做完一整轮操作)。DataLoader主要用于加载获取到的数据,以特定的方式为网络提供数据
一、Dataset类
- 导入:
from torch.utils.data import Dataset - 继承Dataset抽象类需要重写的方法:
__init__(初始化,得到相应的数据列表)、__getitem__(提供方式加载对应数据项)和__len__(返回数据集长度)
二、__init__具体介绍
1.主要功能
文件路径、合并文件路径、把文件夹中的每一个文件名称记录下来做成一个列表存储,方便通过idx去获取每一个数据
2.代码实现
代码如下(示例):
def __init__(self, root_dir, label_dir): # 初始化,为这个函数用来设置在类中的全局变量
self.root_dir = root_dir # 定义全局变量
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) # 通过os.path.join()连接获得路径,因为在win下和linux下的斜线方向不一样
self.img_path = os.listdir(self.path) # 注意通过os.listdir()之后,img_path 的返回值是一个列表
注意:
import os- 通过
os.path.join()连接获得路径 - 通过
os.listdir()将数据集返回成一个列表
三、__getitem__具体介绍
1.主要功能
访问init中返回的列表,把列表中的数据名称逐一传递给一个变量,命名为name,再次合并路径(将name和init中连接得到的路径再次连接,即把文件名连接在路径之后),接下来,用PIL中的Image.open函数,读取(加载)上述路径的文件(命名为img接收)(这里肯定是图像了),返回图像 img 和标签 label。
注意:此时获取到的img图片类型为PIL型,下节tensorboard会着重强调数据类型转化
2.代码实现
代码如下:
def __getitem__(self, idx): # 获取数据对应的 label
img_name = self.img_path[idx] # img_path 在上一个函数的最后,返回就是一个列表了
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) # 加上文件名了,所以这次连接之后得到单个图片的路径
img = Image.open(img_item_path) # 这个步骤是不可缺少的,要show或者操作图片之前,必须要把图片打开(读取),也就是 Image.open()
label = self.label_dir
return img,label # img 是每一张图片的名称,根据这个名称,就可以使用查看、print、size
注意:
img_path是一个列表,加上idx即可获取列表中每一个文件名- 再次
os.path.join()连接加上了文件名,可以获得单个图片的路径,可以定位到具体图片了 img = Image.open(img_item_path)这个步骤是不可缺少的,要show或者操作图片之前,必须要把图片读取
四、__len__具体介绍
较简单直接上代码:
代码实现
def __len__(self):
return len(self.img_path) # len()对列表进行操作
五、完整代码(实例化)和运行结果
1.代码如下:
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
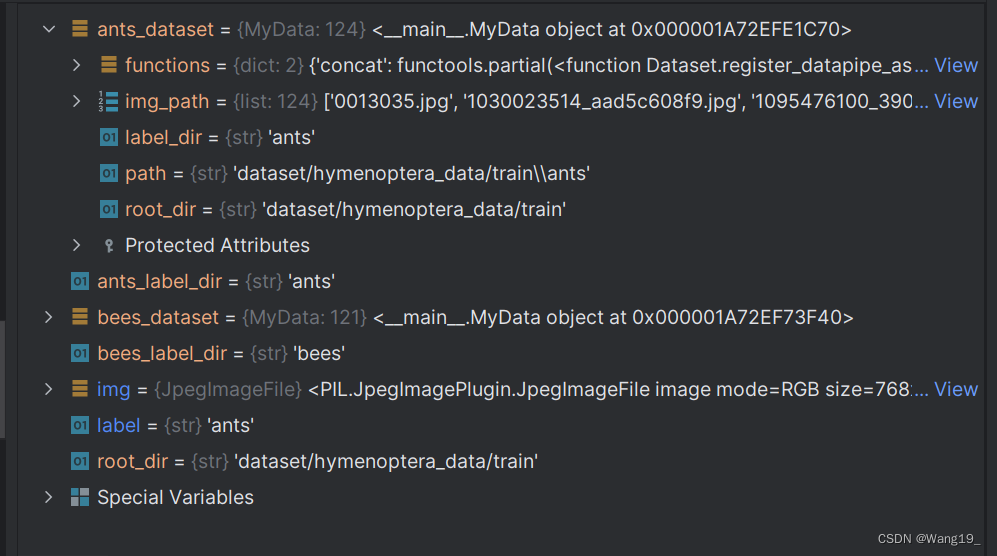
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
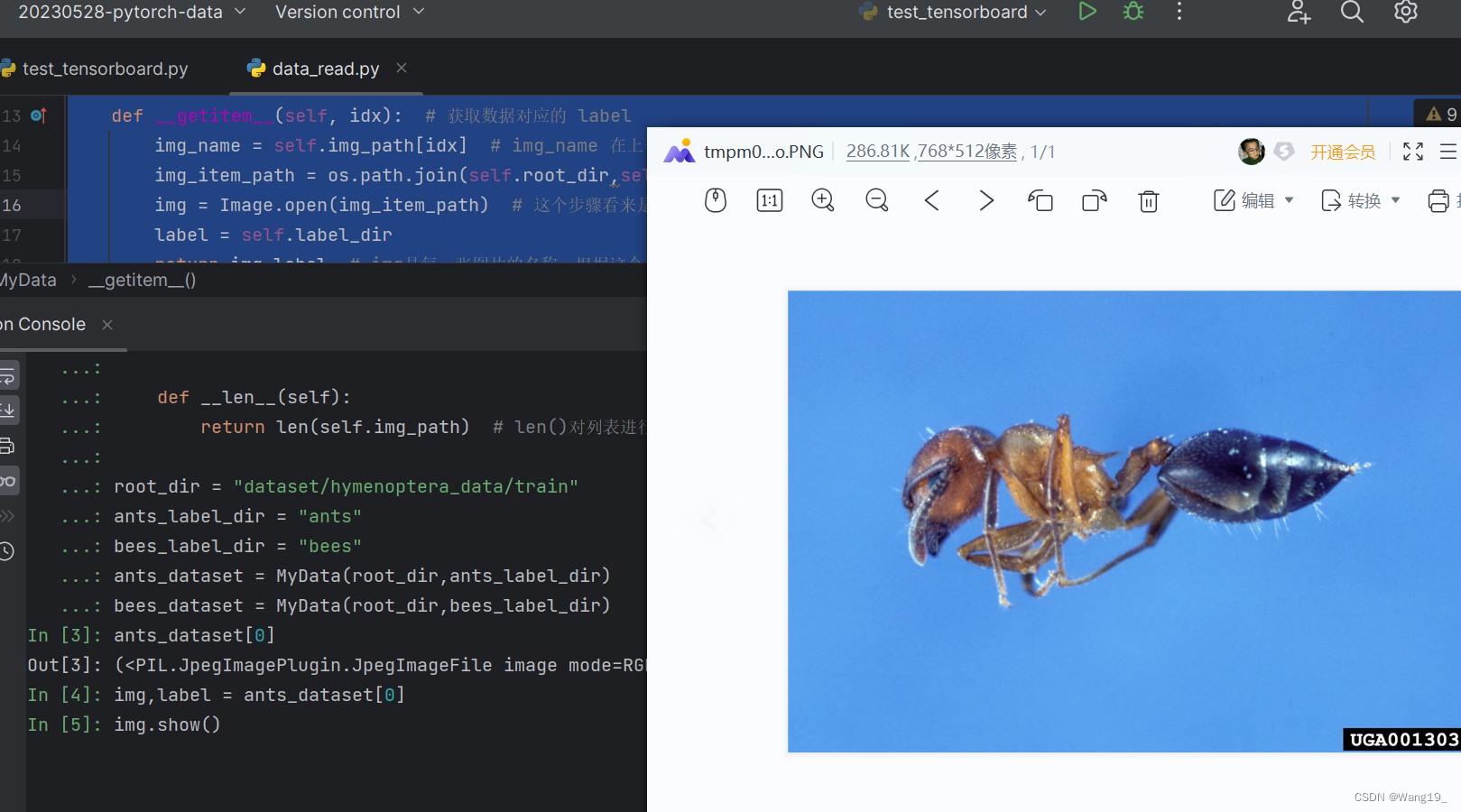
2.运行结果(示例):
ants_dataset[0]
Out[3]: (<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512>, 'ants')
img,label = ants_dataset[0]
img.show()
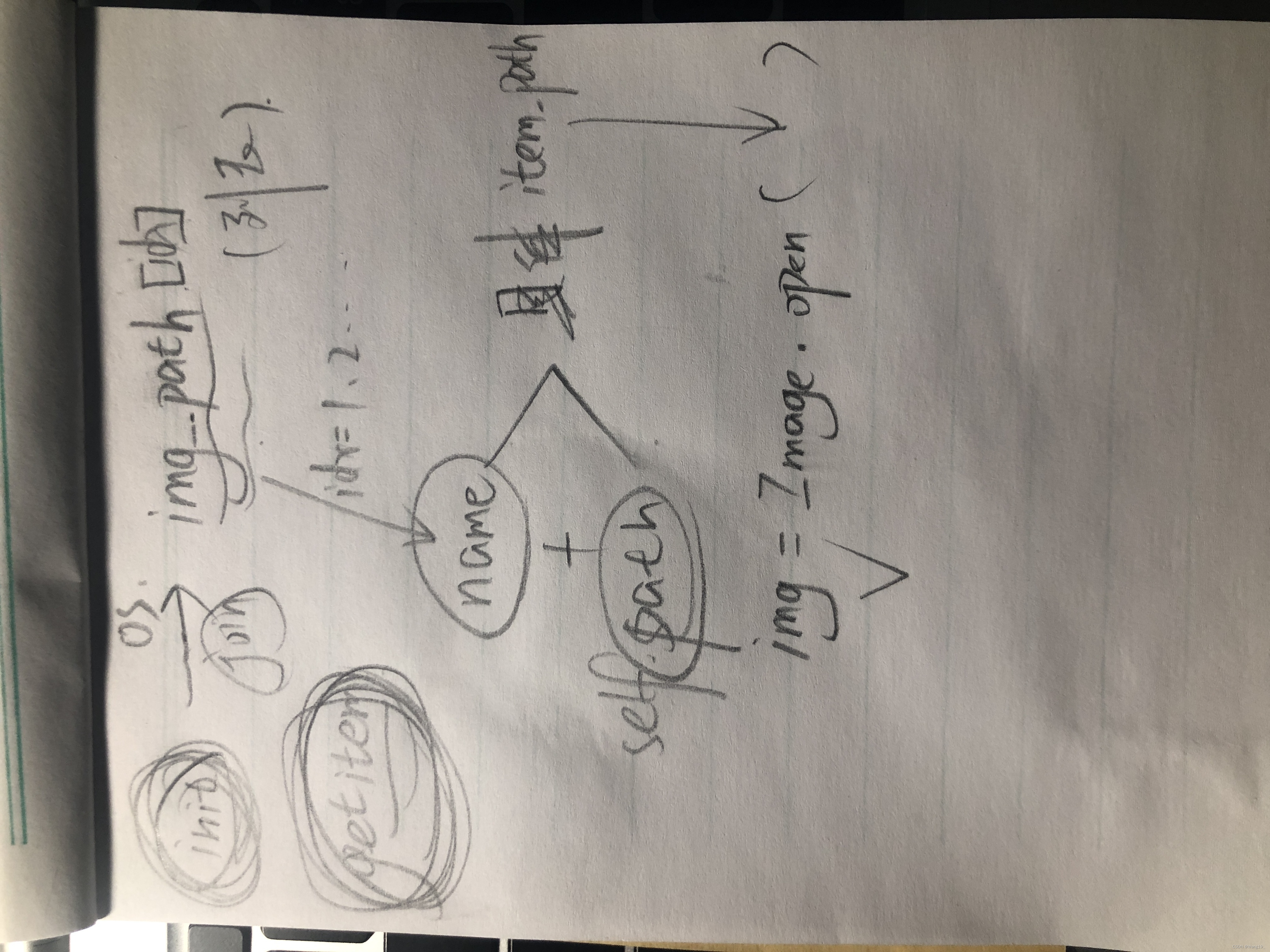
补充一张流程图(自己画的为了方便之后复盘)















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









