






参考了两篇总结:点击跳转1
Day7 DataLoader
前言——回顾Pytorch的数据读取机制
之前学习过Dataset读取数据,其实,DataLoader和DataSet就是数据读取子模块中的核心机制。引用一张图来说明:
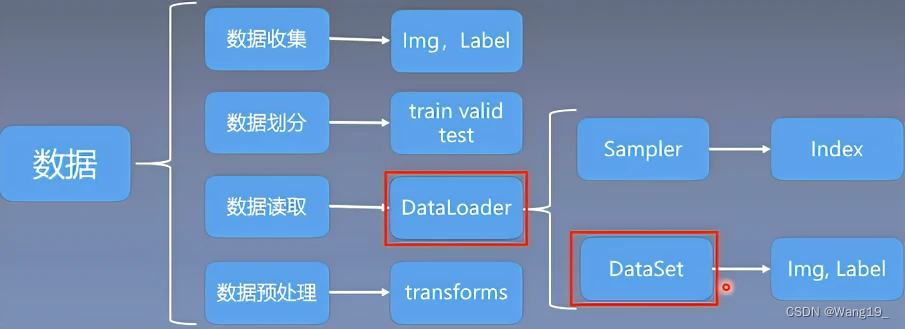
torch.utils.data.Dataset(): Dataset抽象类,
所有自定义的Dataset都需要继承它,并且必须重写getitem、init、len这个类的方法。
getitem方法是Dataset的核心,作用是接收一个索引(将路径对应数据通过os.dirlist合并为一个列表并返回), 返回一个样本,参数里面接收index,然后编写如何通过这个索引去读取数据部分。接下来正文部分介绍DataLoader。
一、DataLaoder介绍
torch.utils.data.DataLoader():构建可迭代的数据装载器,,我们在训练的时候,每一次for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。
DataLoader的参数很多,但我们常用的主要有5个:
dataset:Dataset类, 决定数据从哪读取以及如何读取bathsize:批大小num_works:是否多进程读取机制shuffle:每个epoch是否乱序drop_last:当样本数不能被batchsize整除时, 是否舍弃最后一批数据
二、具体过程
1.准备数据
代码如下:
#导入包
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#下载数据集,以CIFAR10为例
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
#加载数据集
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
注意:
- 加载数据时的参数
dataset指向下载的数据集 - 每次循环取
batch_size=4张数据 shuffle为true表示随机打乱drop_last表示最后一组数据不足4张时候舍弃。
下载数据集完成:
2.在控制台查看加载好的数据
代码如下:
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)
也可以直接查看加载好的第一张图片信息:
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape) # torch.Size([3, 32, 32]) 单张图片的尺寸和通道数
print(target) # 输出为 3
3.通过tensorboard加载多组图片信息
writer = SummaryWriter("dataloader")
# 测试数据集上所有的图片 imgs 是复数
for epoch in range(2): # 进行两轮,上面的 shuffle,是对这个位置有影响,而不是 for data 那个循环有影响
step = 0
for data in test_loader: # 这个loader,返回的内容,就已经是包含了 img 和 target 两个值了,这个在 cifar 数据集的 getitem 函数里,写了
imgs, targets = data
# print(imgs.shape) # torch.Size([4, 3, 32, 32]) 这个输出的结果,其中的 4 ,是 batch_size 设定的值, 后面的 3, 32, 32 是单张图片的尺寸和通道数
# print(targets) # tensor([2, 8, 0, 2]) 这4个数字,是对 target 的打包,是随机的,数值代表所在的分类;debug一下,可以看到 sampler中的取值方式,是 RandomSampler
# 随机从 Data 中,抓取 4 个数据
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
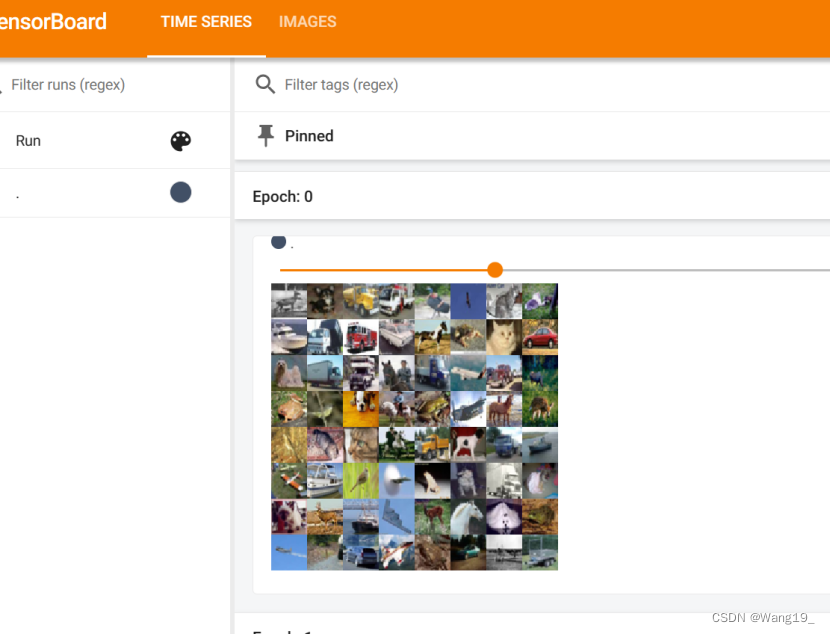
三、运行结果展示
1.Epoch0
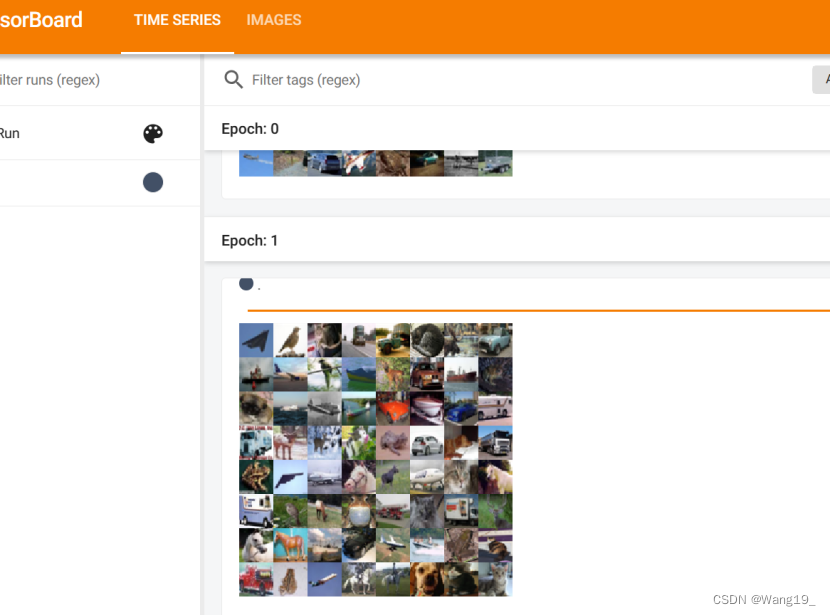
2.Epoch1
四、总结
在本文中回顾了Dataset加载数据的方式,以及学习了DataLoader的机制、简单操作过程,并以读取CIFAR10中的数据为例,借助Tensorboard的展示读取到的数据,更好的理解了dataloader的参数含义,能为后续神经网络的训练奠定基础,同时更好的学习和使用pytorch。
发现了一篇关于PyTorch读取数据机制的文章,非常适合学习,链接附上:
点击跳转















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









