






论文题目:RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
介绍
检索增强语言模型(RAG)已成为问题解答任务的强大工具。它们通过整合外部知识来增强标准语言模型的能力,使其能够适应世界的变化,并处理训练数据中本身不包含的信息。由斯坦福大学研究人员开发的 RAPTOR(文本检索递归抽象处理)提供了一种开创性的基于树的检索系统,其性能明显优于现有的 RAG 方法。
现有方法的不足:现有方法仅限于检索短小、连续的文本块,这可能会妨碍对整个文档上下文的整体理解。
为了应对这一挑战,由 Parth Sarthi 领导的斯坦福大学研究团队开发了 RAPTOR,这是一种基于树结构的新型检索系统,可递归嵌入、聚类和总结文本块,为语言模型提供不同抽象程度的上下文信息。
PAPTOP 架构概述:
RAPTOR 的体系结构由两个主要部分组成:树构建过程、检索方法
树构建
- 将检索语料切分成短小、连续的文本(叶节点);
- 使用 SBERT 对叶节点进行Embedding;
- 使用高斯混杂模型(GMM)和 UMAP 降维对叶节点进行聚类;
- 使用LLM 对聚类中心进行摘要总结(gpt-3.5-turbo);
- 重新对上一层的摘要文本进行聚类和摘要,知道聚类中心变得只有一个为止。
具体而言,Tree 的构建过程可以详细描述如下:
PAPTOR 的树构建过程首先是将检索语料分割成简短、连续的文本,每个文本约 100 个词组。如果一个句子超过了 100 个标记符的限制,它就会被移到下一个语块,以保持每个语块中文本的上下文和语义连贯性。然后使用基于 BERT 的编码器 SBERT(multi-qa-mpnet-base-cos-v1)嵌入这些文本块,形成树的叶节点 。
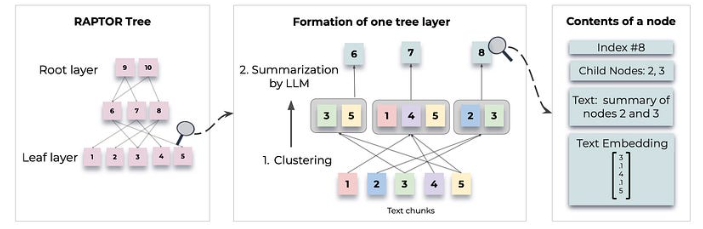
RAPTOR 采用基于高斯混合模型 (GMM) 的聚类算法对相似文本块进行分组。GMM 假设数据点是由多个高斯分布的混合物生成的,因此可以进行软聚类,节点可以属于多个聚类,而不需要固定的聚类数量。为了减轻向量嵌入的高维性所带来的挑战,RAPTOR 采用了统一曲面逼近和投影(UMAP)技术来降低维度。
聚类过程分两步进行:
- 先确定全局聚类,然后通过改变 UMAP 中的最近邻参数数,在这些全局聚类中进行局部聚类。这种方法可以捕捉到文本数据之间从广泛主题到具体细节的广泛关系。如果一个局部聚类的综合上下文超过了摘要模型的标记阈值,算法就会在聚类内递归应用聚类,以确保上下文保持在标记阈值范围内。这里,贝叶斯信息标准(BIC)用于确定最佳聚类数,平衡模型复杂性和拟合度。在确定了最佳聚类数之后,就可以使用期望最大化算法来估计 GMM 参数,即均值、协方差和混合物权重。
- 对节点进行聚类后,每个聚类中的节点会被发送到 LLM(gpt-3.5-turbo)中进行摘要。然后,汇总后的文本被重新嵌入,嵌入、聚类和汇总循环往复,直到进一步的聚类变得不可行,最终形成原始文档的结构化多层树形表示
检索方法
RAPTOR 提供两种不同的树形结构查询策略:树遍历和折叠树。

- 树遍历方法是逐层浏览树形结构,根据节点与查询嵌入的余弦相似度,修剪并选择每一层中最相关的前 k 个节点。这一过程从根层开始,递归到每层所选节点的子节点,直至叶节点。然后将所有选定节点的文本连接起来,形成检索到的上下文。
- 而折叠树方法则是将多层树扁平化为单层,将所有节点放在同一层面上进行比较。计算查询嵌入与折叠集合中所有节点的嵌入之间的余弦相似度,然后选择余弦相似度得分最高的前 k 个节点,直到达到预定义的最大标记数为止。
研究人员进行的实验表明,折叠树方法的性能始终优于树遍历方法,这可能是由于折叠树方法在检索特定问题的适当粒度信息方面具有更大的灵活性。因此,RAPTOR 选择了最多 2000 个标记的折叠树方法作为主要查询策略。
上述这些方法的集成使 RAPTOR 能够构建一个分层树结构,同时捕捉文本的高层和低层细节,使语言模型能够访问不同抽象层次的上下文信息。这种结构与高效的检索方法和强大的问答系统相结合,使 RAPTOR 在多项问答任务中取得了一流的性能。
PAPTOR的优势
-
分层结构:RAPTOR 构建了一个多层树状结构,可捕捉文本的高层和低层细节。这种分层结构允许模型访问不同抽象层次的上下文信息,从而更全面地理解文档。相比之下,传统的 RAG 方法通常只能检索短小、连续的文本块,这可能会限制其捕捉整个文档上下文的能力。
-
灵活检索:RAPTOR 提供两种检索策略:树状遍历和折叠树。在实验中,折叠树方法的性能一直优于树状遍历,它在针对给定问题以适当的粒度检索信息方面提供了更大的灵活性。与传统的 RAG 方法相比,这种适应性使 RAPTOR 能够有效处理更广泛的查询。
-
提高相关性:与传统的 RAG 方法相比,RAPTOR 能够根据问题所需的详细程度,从树状结构的不同层次选择节点,从而检索到更相关、更全面的信息。这一优势在需要全面了解文件的专题问题和多跳问题中尤为明显。
-
可扩展性:RAPTOR 在令牌支出和构建时间方面都是线性扩展,因此适合处理大型复杂语料库。这种可扩展性确保了 RAPTOR 可以有效地应用于广泛的现实世界应用中,而传统的 RAG 方法在处理大量文本语料库时可能会难以提高计算效率。
-
最先进的性能:论文中进行的实验表明,在多个问题解答数据集(NarrativeQA、QASPER 和 QuALITY)中,RAPTOR 的性能始终优于 SBERT、BM25 和 DPR 等传统检索方法。RAPTOR 与 GPT-4 等功能强大的语言模型相结合,设定了新的先进基准,大大超过了以前的最佳结果。
-
可解释性:RAPTOR 的树形结构提供了一种更易于解释的文档层次表示法,使用户能够理解信息是如何组织和检索的。这种可解释性在对透明度和可解释性要求很高的应用中很有价值,例如在法律或医疗领域。
-
多功能性:RAPTOR 的结构设计具有模块化和适应性强的特点,可以集成各种嵌入、聚类和摘要技术。这种多功能性使研究人员和从业人员能够根据自己的具体需求定制 RAPTOR,并探索不同的组件组合以进一步提高性能。
-
可扩展性和计算效率:RAPTOR 的主要优势之一是其计算效率和成本效益。在消费级笔记本电脑上进行的实验表明,RAPTOR 在令牌支出和构建时间方面都呈线性扩展,因此适合处理大型复杂语料库。这种可扩展性确保了 RAPTOR 可以有效地应用于广泛的现实世界应用中。
结论
RAPTOR 代表了检索增强语言模型的重大进步,它提供了一种新颖的基于树的方法,其性能优于传统的 RAG 方法。通过构建分层结构和采用灵活的检索策略,RAPTOR 在多个问题解答数据集上实现了最先进的性能。它的可扩展性、可解释性和多功能性使其成为广泛现实世界应用中极具吸引力的解决方案。随着自然语言处理领域的不断发展,RAPTOR 的优势可能会推动其应用,为更准确、高效和全面的自然语言理解系统铺平道路。
附录
Raptor 中使用的算法简介
GMM
高斯混合模型(GMM):给定一组 N 个文本片段,每个片段用 d 维密集向量嵌入表示,给定文本向量 x 在第 k 个高斯分布中的成员资格,其可能性用 P(x|k) = N(x; μₖ, Σₖ)表示,其中 μₖ 和 Σₖ 分别是第 k 个高斯分布的均值和协方差矩阵。总体概率分布是 K 个高斯分布的加权组合:
P(x) = Σᵏ₌₁ᴷ πₖ N(x; μₖ, Σₖ)
P(x) = Σᵏ₌₁ᴷ πₖ N(x; μₖ, Σₖ)
其中,πₖ 表示第 k 个高斯分布的混合物权重。
BIC
贝叶斯信息准则(BIC):给定 GMM 的BIC 计算公式如下:
BIC = ln(N)k — 2 ln(L̂)
BIC = ln(N)k - 2 ln(L̂)
其中,N 是文本片段(或数据点)的数量,k 是模型参数的数量,L̂ 是模型似然函数的最大值。就 GMM 而言,参数 k 的数量是输入向量维度和聚类数量的函数。
余弦相似度
RAPTOR 使用余弦相似度来衡量节点与查询嵌入的相关性。两个向量 a 和 b 之间的余弦相似度计算如下:
cosine_similarity(a, b) = (a · b) / (||a|| ||b||)
cosine_similarity(a, b) = (a - b) / (||a|| |||b|||)
其中,a - b 是两个向量的点积,||a||| 和 ||b|| 是向量的欧氏规范。

















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









