







就 RAG 而言,索引是指以某种方式组织大量文本数据的过程,以便 RAG 系统能够快速找到与给定查询最相关的信息。这就像为 LLM 建立一个超高效的图书馆,无需翻阅页面,它就可以立即找到满足用户需求的确切部分。
索引
在选择针对给定问题使用哪种算法时,需要考虑两个因素——准确性和速度。
如果我们需要更高的准确性,我们可能需要采取暴力方法,将每个存储的向量与查询向量进行比较。或者,我们可以使用近似技术来提高速度,但以牺牲准确性为代价。
关于如何加快搜索速度,以下是两个关键策略:
-
修剪向量大小:这可以通过采用降维技术或最小化用于表示向量值的位数来实现。
-
缩小搜索范围:根据特定属性、相似性或距离选择聚类或将向量构造成树形结构。然后,将搜索重点放在最近的聚类上,或筛选最相似的分支以提高效率。
1. k-近邻
KNN(K-最近邻)索引是 RAG 模型检索阶段使用的一种强力技术。
核心概念:
-
相似度度量:确定两个向量之间“接近度”的函数(例如,余弦相似度、L2 距离)。检索过程旨在识别其向量表示与查询向量最相似的段落/文档。
注意:当特征的大小很重要时,使用 L2 距离(当原始值及其差异很重要时,这是理想的选择,例如根据年龄和收入比较用户配置文件),否则使用余弦相似度(根据单词主题比较文档时的理想选择,无论总体情况如何)字数)。
-
k 值:为每个查询检索的最近邻居的数量。较高的 k 值可提供更多样化的结果,而较低的 k 值会优先考虑最相关的结果。

搜索过程:
-
查询向量化:使用应用于语料库的相同方法将用户的查询转换为向量。
-
KNN 搜索:它使用给定的相似性度量从语料库中检索 k 个最近邻向量。它的时间复杂度是O(N log k),但是使用KD树进行搜索会将时间复杂度降低到O(log N)
2.IVF
IVF 索引是一种用于加速 RAG 检索阶段的 ANN 技术。它与 KNN 索引有一些相似之处,但操作方式略有不同。
核心概念:
-
聚类:使用 K 均值聚类等技术将向量空间划分为簇。每个簇都有一个质心,表示该簇在向量空间中的中心。
-
倒排文件:创建倒排文件数据结构(就像Python字典一样)。该文件将每个质心映射到属于相应簇的数据点 ID(段落/文档)列表。

搜索过程:
-
最近质心搜索: IVF 索引根据相似性度量(通常是余弦相似度)有效搜索最近质心(与查询向量最相似的簇质心向量)。
-
精细搜索:在由最近质心标识的簇内,使用更昂贵的距离度量(例如 L2 距离)检索较少数量的最近邻居(数据点)。此步骤细化了最有希望的簇内的搜索。
3. 局部敏感哈希
LSH 索引有助于加快检索过程。与之前讨论的方法(KNN、IVF)不同,LSH 专注于将相似的数据点以高概率映射到相同的“存储桶”,即使它可能无法保证最近的邻居。
核心概念:
-
哈希函数: LSH 利用一系列哈希函数,以高概率将相似的数据点(表示为向量)映射到相同的“哈希桶”。然而,不同的数据点也可能在同一个桶中发生冲突。
-
相似度度量:函数(如余弦相似度)确定两个向量之间的“接近度”。 LSH 函数旨在以比不相似向量更高的概率将相似向量(基于相似性度量)映射到同一存储桶。
-
多个哈希表: LSH 通常使用多个哈希表,每个哈希表使用不同的 LSH 函数。这种方法增加了找到相似项目的可能性,即使它们在一个表中发生冲突,因为它们可能在另一个表中分开。

搜索过程步骤:
-
LSH 哈希:使用 LSH 系列中的每个哈希函数对查询向量进行哈希处理,从而为每个表生成一组哈希代码(桶索引)。
-
候选检索:根据生成的哈希码,与任何表中的查询共享至少一个哈希码(即,基于 LSH 函数可能相似)的文档被视为候选匹配。
4. 随机投影
RP 索引将高维数据(文本向量)投影到低维空间,同时尝试保留相似关系。
核心概念:
-
降维: RP 旨在降低表示为向量的文本数据的维度。比较高维向量的计算成本可能很高。
-
随机投影矩阵:生成随机矩阵,每个元素包含随机值(通常遵循高斯分布)。该矩阵的大小决定了目标较低维度。
-
相似性保留:目标是以在高维空间(二进制形式)中尽可能保留其相对相似性的方式将数据点(向量)投影到低维空间上。就像 SVM 一样,当超平面法向量与另一个向量产生 +ve 点积时,我们将其编码为 1 else 0。这允许在低维空间中进行有效搜索,同时仍然捕获相关连接。
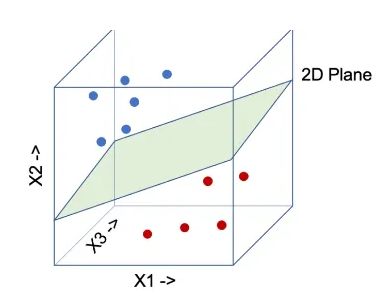
搜索过程步骤:
-
随机投影:使用预先计算的随机投影矩阵将语料库中的查询向量和文档向量投影到低维空间。这会产生数据的低维表示(二进制向量)。
-
低维搜索:在低维空间中使用高效搜索算法(寻找最接近匹配的汉明距离)来查找投影向量与投影查询向量最相似的文档。由于维度降低,该搜索可以更快。
5. PQ
PQ 索引用于加速搜索过程并减少内存占用。
核心概念:
-
向量分解:高维查询和文档向量被分解为表示低维子空间的较小子向量。这有效地将复杂的向量分解为更简单的部分。
-
密码本创建:对于每个子空间,使用 k 均值聚类等技术创建密码本。该码本包含一组代表性质心,每个质心代表一组相似的子向量。
-
编码:然后通过识别其相应码本中最接近的质心来“编码”每个子向量。该编码过程根据子向量最近的质心为其分配索引。

搜索过程步骤:
-
向量分解:根据预定义的子空间将查询向量分解为子向量。
-
子空间编码:通过在相应的码本中找到其最近的质心来对每个子向量进行编码,从而产生代表编码子向量的一组索引。
-
近似距离计算:使用来自查询向量和文档向量的编码子向量索引,应用有效的距离度量来估计两个向量之间的相似性。
6.分层可导航小世界
HNSW擅长在大型集合中查找与给定查询最相似的数据点,但它可能无法精确定位绝对精确的最近邻居。这种完美准确性和检索速度之间的权衡使 HNSW 成为 RAG 索引等应用的理想选择,在这些应用中,快速返回高度相关的信息至关重要。
核心概念:
-
可导航小世界图: HNSW 建立在可导航小世界图的概念之上。想象一个社交网络,其中每个人都与几个亲密的朋友有联系,但也与网络中较远的人有一些随机联系。这可以实现高效导航——通常,通过有策略地跟踪近距离和远距离的连接,您可以在少量跳跃内联系到任何人。HNSW 将这个概念转化为一种图形结构,其中数据点(矢量)是节点,连接代表它们的相似性。
-
跳表:与链表数据结构类似,HNSW 向图中引入了层次结构。这意味着有多个层,每个层都有不同的连接“粒度”(跳过连接)。顶层的连接少得多,但在向量空间中跨越的距离更大,允许快速探索。较低层有更多连接,但注重更细粒度的相似性。这种层次结构可以实现高效搜索——算法从顶层开始进行广泛的初始搜索,然后在较低层中逐步细化以找到最近的邻居。但为此,我们需要构建一个排序的跳过列表。
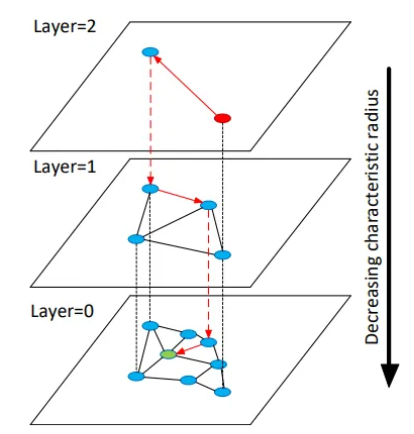
搜索过程:
-
顶层探索: HNSW 利用顶层的长距离连接来识别一小组潜在有前途的节点(候选最近邻居)。
-
分层下降:该算法迭代地探索较低层中的这些候选者,使用较短距离的连接来细化搜索并更接近真正的最近邻居。
-
选择:在整个搜索过程中,根据距离阈值或其他标准选择预定义数量的最近邻居。
在 RAG 系统中建立索引时遇到一些关键挑战:
-
数据质量和相关性:检索到的信息的质量在很大程度上取决于索引数据的质量。索引中不准确、不完整或不相关的数据可能会导致 RAG 模型生成不准确或误导性的响应。
-
文本嵌入的高维数:随着嵌入维数的增加,向量之间的距离计算变得不那么有意义,使得识别真正相似的数据点变得更加困难。
-
平衡速度和准确性:找到检索速度和准确性之间的完美平衡至关重要。 RAG 系统需要快速检索才能实时生成响应。然而,过于激进的过滤技术可能会排除相关信息。像 HNSW 这样的索引方法提供了一个很好的折衷方案,但是微调这些方法以获得最佳性能可能具有挑战性。
-
有限的评估指标:缺乏专门设计用于评估 RAG 索引中检索到的信息质量的标准化指标。当前的指标通常侧重于检索速度或召回率(检索到的相关项目的数量),但可能无法充分捕获信息与用户查询的真正相关性。
应对这些挑战对于构建强大且有效的 RAG 系统至关重要,该系统可以利用大型语言模型的力量来提供准确且信息丰富的响应。















 2177
2177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









