







这是我参与「第五届青训营 」伴学笔记创作活动的第 15 天
为什么需要Redis
数据从单表演进成了分库分表,而MySQL从单机演进出了集群,但是随着业务的扩展,数据量开始大大增长,读写数据的压力也在不断增加。对于实时查询,高QPS等,MySQL是扛不住的
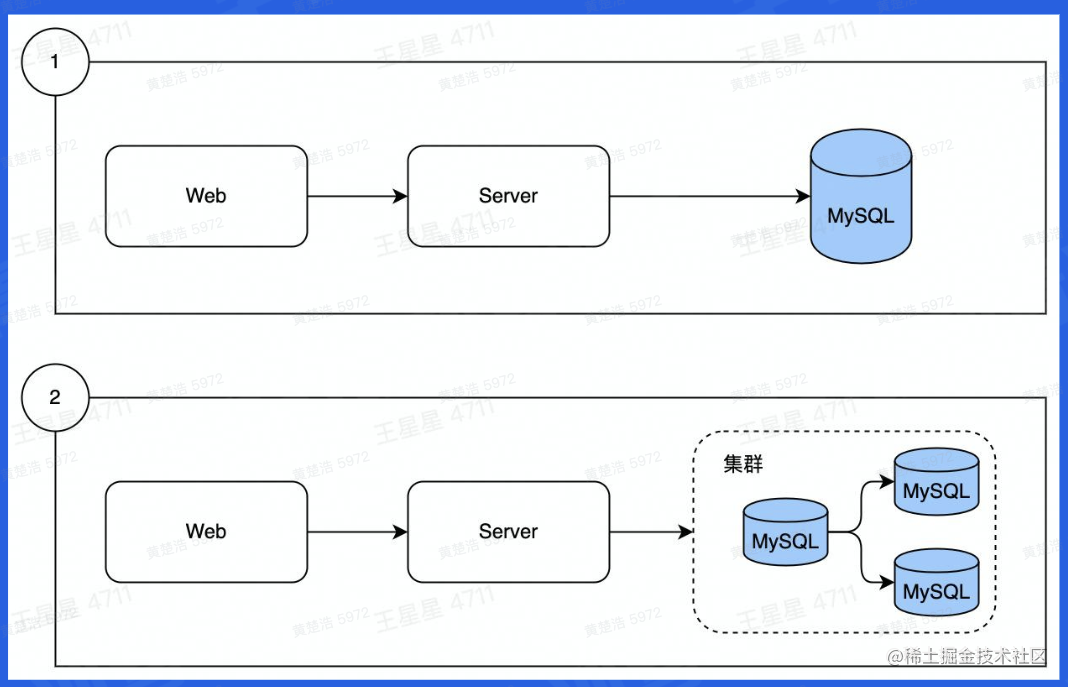
于是我们将数据分为冷数据和热数据,对于某些需要高频使用的数据,将数据存在内存中,将其视作为热数据。
Redis的基本工作原理和特性就是:
- 数据从内存中读写
- 数据在一定程度上持久化,不会因为宕机导致数据丢失(使用RESP协议持久化)
- 单线程处理所有操作指令
Redis数据结构
String数据结构
在Redis中是个数据安全的二进制数据,可以存储字符串、数字、二进制数据。
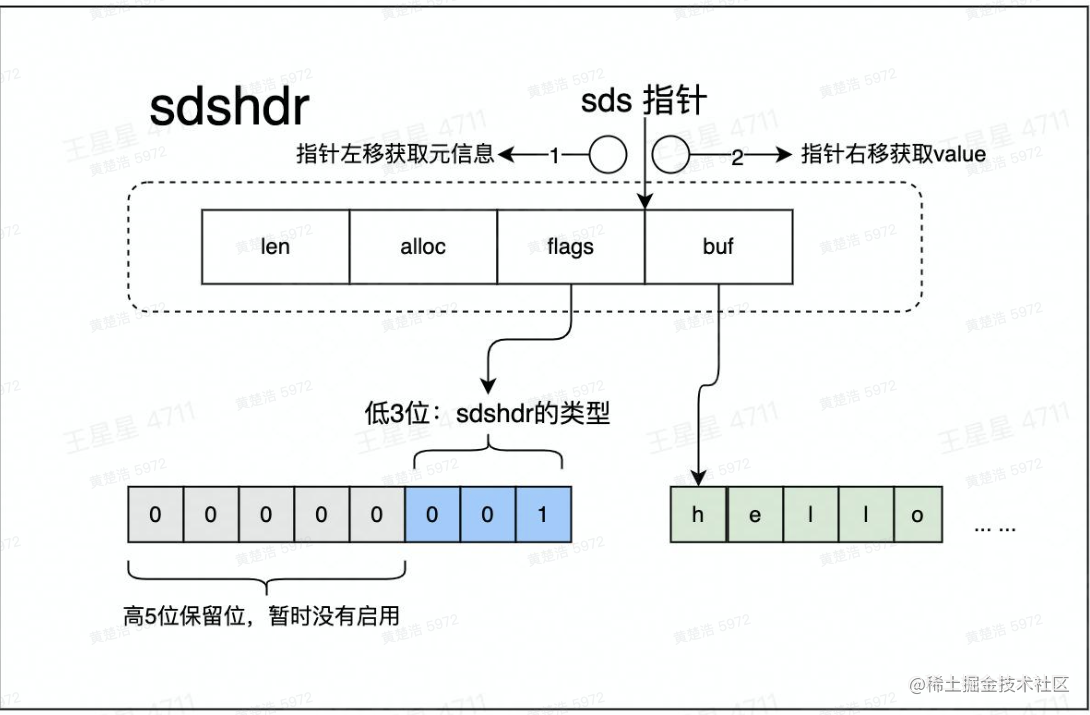
String的内容会存入到buf中,buf会预分配一定的空间,只有用完空间后才会扩容。
- flags一共8位,低3位为当前数据类型,高五位保留,暂时没有启用
- alloc表示buf有多少空间
- len表示buf已经使用了多少空间
消息通知
Redis通常使用list作为消息队列,例如文章更新的时候,将更新后的文章推送到ES,用户就能搜索到最新的文章数据。
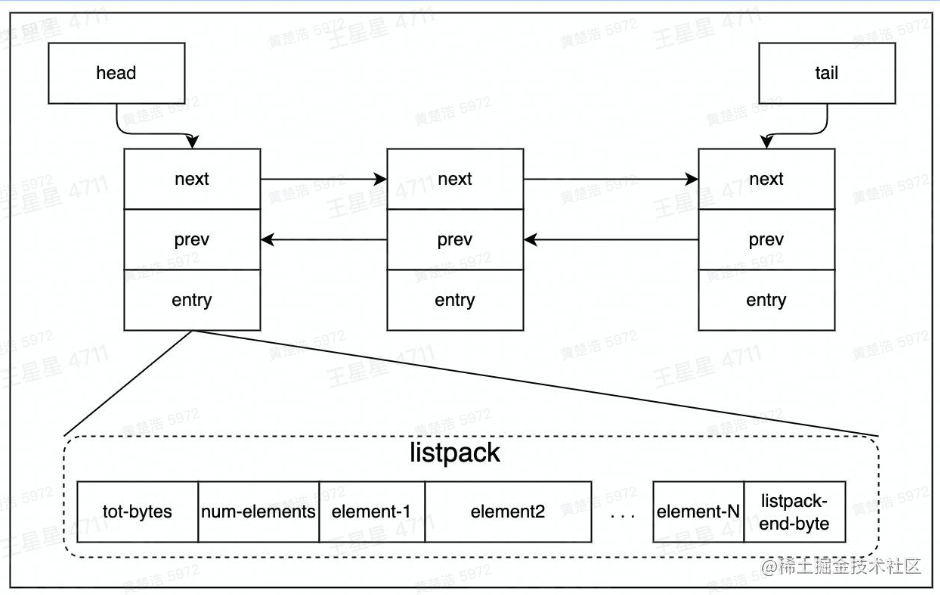
Redis中的List称为QuickList,是由一个双向链表和一个listpack实现的
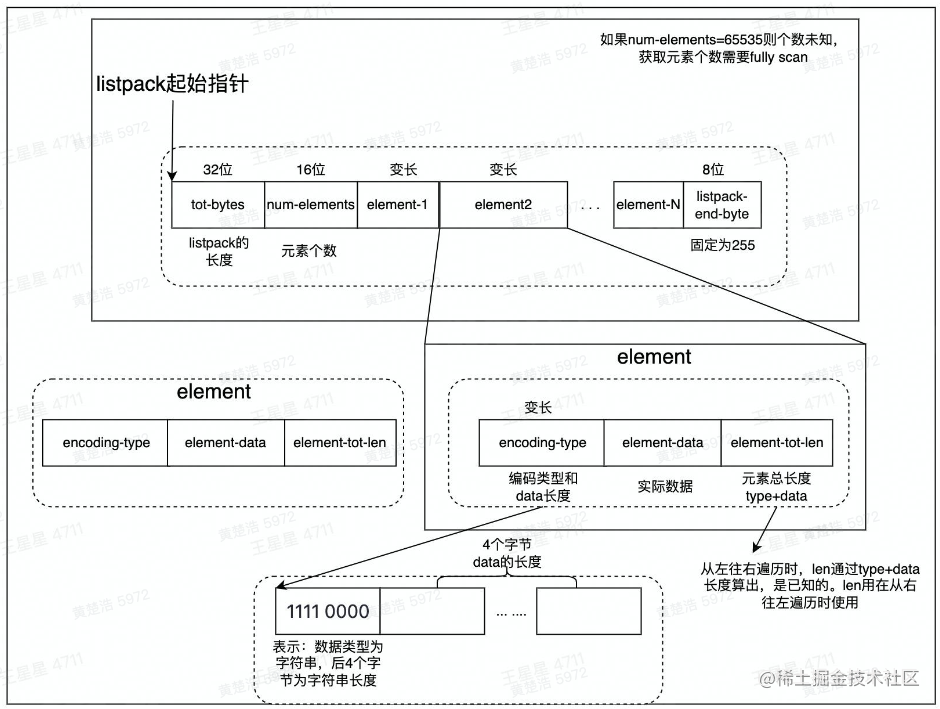
为什么要这样设计呢?Redis为了节省内存,会在一个节点上存储多个数据。Redis会为一个listpack开辟一块大空间,在一个listpack中,tot-bytes是总的大小,num-elements是数据的数量,接下来就是各个元素,element-n
Hash结构存储
一个用户通常有多项计数需求,可以通过hash结构存储。
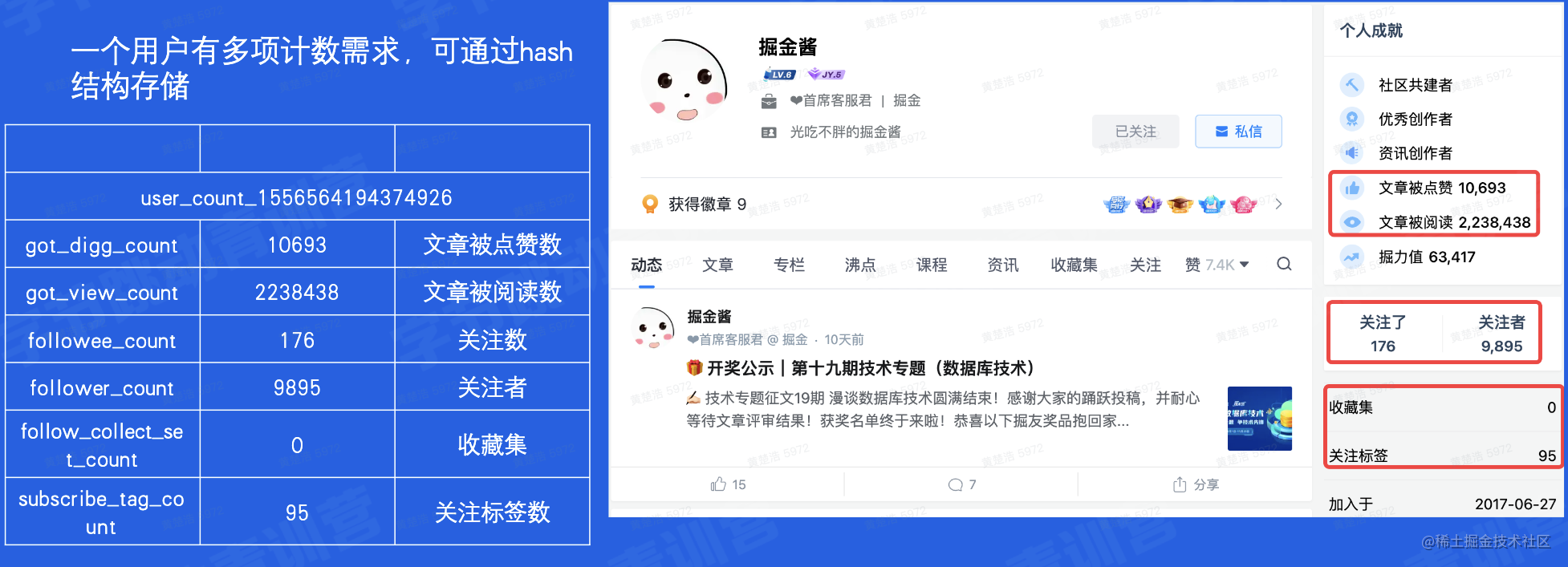
在Redis中,只需查询ex05_user_count_1556564194374926就可以查看到该用户下的所有key_value,而不需要分次查找
在Redis中,Hash的数据结构如下:
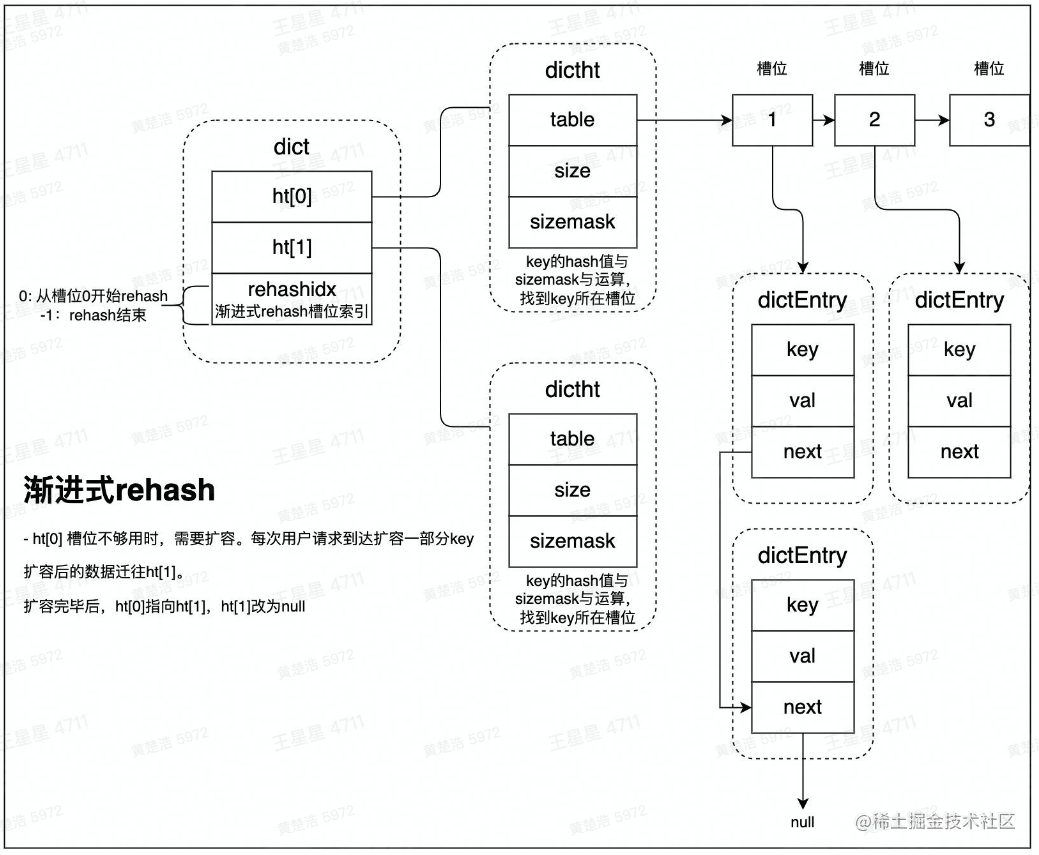
在一个dict中,有一个ht表(HashTable的缩写),里面存放着若干的HashTable。一个HashTable就和我们平时认识的Hash表一样,下属多个节点,在Redis中称为槽位,一个槽位对应一个Hash值,每个槽位对应一个单向链表的拉链,经过Hash运算后会将数据节点分配到对应的槽位中。
但是如果数据量较大,一个槽位中会有过多的数据,从而导致访问速度变慢,这时候就需要引入多个HashTable了,比如说在dicit中引入另一个HashTable,ht[1]。然后将ht[0]中的数据逐渐迁移到ht[1]中去。具体迁移方式分为rehash和渐进式rehash两种方法。
rehash会将ht[0]中的数据全部迁移到ht[1]中,但是数据量大的时候会阻塞用户的请求;渐进式rehash的基本原理是,每次用户访问时都会迁移少量数据到ht[1],将整个迁移过程平摊到所有访问过程中。
限流
要求1秒内发行n个请求,超过n则禁止访问,用于禁止用户使用脚本超发请求。
在某一用户下生成一个key:comment_freq_limit_161356046,后面的数字是时间戳(精确到秒),若用户发送了请求对这个key调用自增函数incr,那么这个key就会记录一秒内用户发送请求的数量,超过限制n则会禁止访问
ZSet数据结构
对于某些实时性比较高、数据量比较大的排行榜,尤其是抖音、b站等排行榜,如果采用MySQL的OrderBy命令对用户热度进行排序,再更新排行榜,那么服务器将不堪重负。对于这种场景,可以使用Redis中的ZSet数据结构
ZSet数据结构使用跳跃表zskiplist实现,其结构如下:
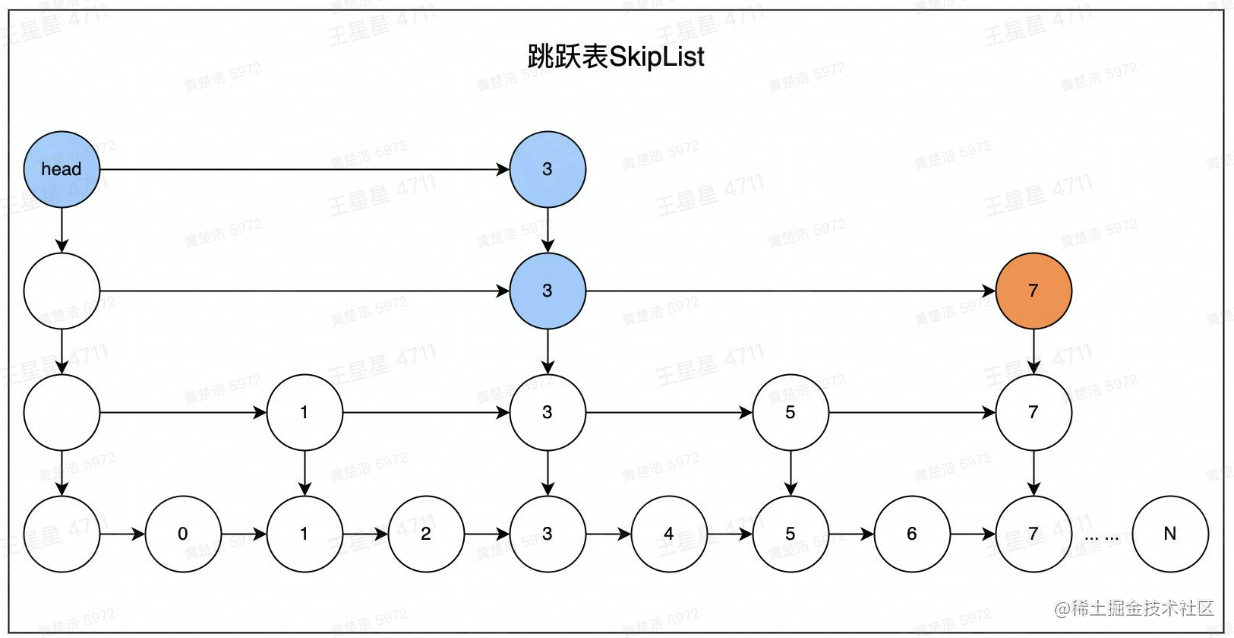
跳跃表就是将一个单向链表之上设置几个查询点,比如查询4号元素的时候,先查询到3号元素,发现4号在三号右边,则再往下查询一个元素便可
Redis的ZSet是一个跳跃表加上哈希的集合

结合了dict之后,可以实现通过key操作跳表的功能。
在企业场景中使用Redis需要注意的点
大Key
对于String类型,value字节数大于10KB则为大Key;对于Hash、Set等复杂数据结构类型,大于5000个或value总字节数超过10MB则为大Key
大Key的危害:
- 读取成本高
- 容易导致慢查询(过期)
- 主从复制异常,服务阻塞无法响应正常请求
- 业务侧请求Redis超时报错
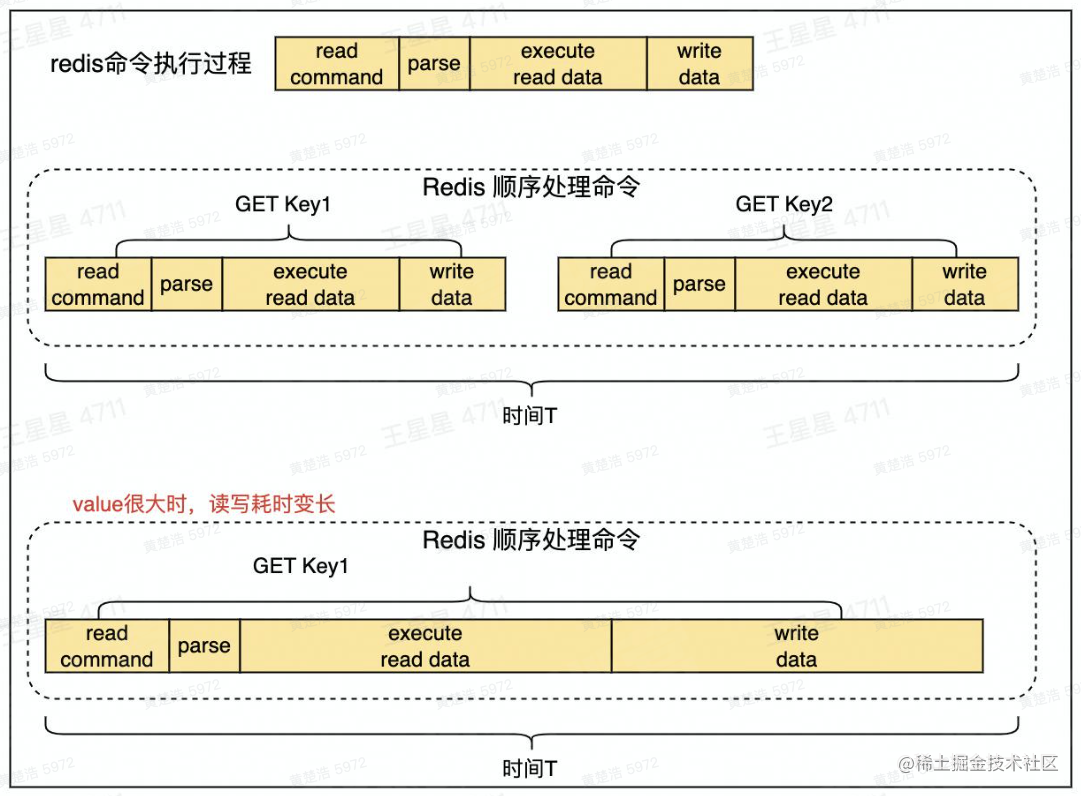
消除大Key的方法:
- 在业务上避免出现大Key
- 拆分:将大Key拆分为小Key,比如一个String拆分为多个String
- 压缩:将value 压缩后写入redis,读取时解压后再使用,可以使用gzip、snappy等算法,如果存储的是JSON字符串,可以考虑使用MessagePack进行序列化
- 区分冷热:如榜单列表场景使用zset,只缓存10页数据,后续数据走db
热Key
用户访问一个Key的QPS特别高,告知Server实例出现CPU负载陡增或者不均匀的情况。热Key没有明确标准,超过500都可以被识别为热Key。
解决热Key的方法:
- 设置LocalCache:在访问Redis之前,在业务侧设置LocalCache,降低访问Redis的QPS。LocalCache缓存过期或者未命中,则从Redis中将数据更新到LocalCache。在Java中有Guava,GoLand中有BigCache
- 拆分:将热Key复制写入多人,访问的时候冯文多个key,但是value是同一个,以此将qps分散在不同的实例上,代价是更新时需要更新多个key,而且存在数据短暂不一致的问题
- 以字节跳动为例子,使用Redis代理集成热Key发现和LocalCache功能
慢查询
需要避免慢查询:
- 批量查询一次性传入过多的kv对,如mset/hmest/sadd/zadd等O(n)操作,建议单批次不要超过100
- zset大部分命令是O(long(n)),当大小超过5k,简单的zadd/zrem可能导致慢查询
- 操作的单个value过大,也就是大key
- 对大key的delete和expire也可能导致慢查询
缓存穿透和缓存雪崩
缓存穿透:热点数据查询绕过缓存,直接查询数据库
危害:
查询一个一定不存在的数据:通常不会缓存不存在的数据,但是这类查询请求都会直接打到db,如果由系统bug或者人为攻击,那么容易导致db响应慢或者宕机
应对:
- 缓存空值:如果请求一个不存在的数据,那么可以缓存一个空值,下次再次查询该数据直接返回空值
- 布隆过滤器:通过bloom filter算法来存储合法key,得益于超高压缩率,只需要极小的空间就可以缓存大量的key。
缓存雪崩:大量缓存同时过期:在高并发场景下,一个热key如果过期,会有大量请求同时击穿到db,容易影响db性能和稳定。同一时间有大量key集中过期,也会导致大量请求落到db上,导致查询变慢,甚至db无力响应新的请求
应对:
- 缓存空值:将缓存失效时间分散开,比如不同的key可以设置为10分1秒过期,10分23秒过期等等,这样过期时间就分散了
- 使用缓存集群,避免单机宕机造成缓存雪崩















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









