







总述:该论文在RNN模型上使用了attention机制来进行图像分类
Model
1.Sensor部分
在每个步骤t,从输入xt中提取感兴趣的部分(给定一个location坐标lt-1周围处提取部分图像信息)
对l更远处的信息采用低分辨率,使图像维度降低
使用glimpse network fg产生向量gt
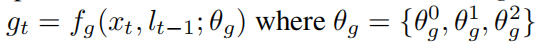
三个θg分别是给定一个坐标提取的n个子图下采样后的表达p(xt,lt-1)线性回归后所得;lt-1由fg(θg)线性回归所得;前两个θ总和。


2.Internal state
由RNN的隐含单元ht组成,随时间由核心网络更新
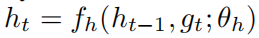
外部输入是gt
3.Action(操作)
有location action 和environment action,前者由位置网络fl(ht, θt)在t时刻的参数化的分布随机所选择(后者类似)(使用softmax函数)
4.Reward
Action后得到一个新的xt和响应信号rt+1,目标是使r总和最大,因为例如rT=1表示在T步之后对象被正确分类,否则为0。

共有三个网络:Glimpse network, Location network, Core network
(1)Glimpse network:
有两个全连接层,Linear(x) 表示向量x的线性变换,Linear(x)=Wx+b,Rect(x)=max(x,0) 为整流器非线性。输出g=Rect(Linear(hg)+Linear(hl)),其中hg=Rect(Linear(ρ(x,l))),hl=Rect(Linear(l))
hg 和hl的维度为128,文中训练的所有注意模型的维度为256
(2)Location network:
fl(h) = Linear(h) (h为RNN或核心网络)
(3)Core network:
ht = fh(ht-1) = Rect(Linear(ht-1) + Linear(gt))
实验使用了LSTM单元的核心















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









