






笔记
redis
一、redis
1.string
键值对的形式,每个key对应一个value,string类型为二进制,可以包含任何类型的数据
2.hash
键值对的集合,是一个string类型的key、value的映射表
3.list
一个字符串列表,按照插入顺序排序
4.set
string类型的无序集合
5.zset
string类型的有序集合
决策树的构建原理
1.ID3决策树
信息增益最大原则构建决策树
2.C4.5决策树
信息增益比最大原则构建决策树
3.CART决策树
基尼系数最小原则构建决策树
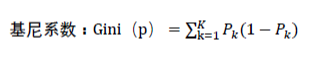
排序算法
稳定性:经过某种排序后,如果两个记录序号相同,且两者在原无记录中的先后秩序依然保持不变,则使用的排序方法是稳定的,繁殖是不稳定的
1.冒泡排序
思想:把第一个元素与第二个元素进行比较,若第一个元素比第二个元素大,则交换位置。继续比较第二个元素与第三个元素的大小,若第二个元素比第三个元素大,则交换位置。依次类推,一次比较滞后,最右端的元素则为最大的元素。重复进行这项工作,直到排序完成。
python实现
def bubblr_sort(li):
for i in range(1,len(li)-1):#表示趟数
change = True
for j in range(len(li)-i): #表示无序区,无序区的范围为0,len(li)-i
if li[j] > li[j+1]:
li[j],li[j+1] = li[j+1],li[j]
change = True
if not change:
return
li = list(range(10))
import random
random.shuffle(li)
print(li)
bubblr_sort(li)
print(li)`
2.选择排序
首先,找到数组中最小的那个元素,其次,将它和数组的第一个元素交换位置(如果第一个元素就是最小元素那么它就和自己交换)。其次,在剩下的元素中找到最小的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。这种方法我们称之为选择排序。
python实现
import random
def select_sort(li):
for i in range(len(li)-1):
#i 表示躺数,也表示无序区开始的位置
min_loc = i #最小数的位置
for j in range(i+1,len(li)): #i ,i+1,就是后一个位置的范围
# [9, 2, 1, 6, 5, 8, 3, 0, 7, 4]
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
if li[j] <li[min_loc]: #两个位置进行比较,如果后面的一个比最小的那个位置还小,说明就找到最小的了
min_loc = j #找到最小的位置
li[i],li[min_loc] = li[min_loc],li[i] #吧找到的两个值进行互换位置
li = list(range(10))
random.shuffle(li)
print(li)
select_sort(li)
print(li)
MySQL与Redis的区别
MySQL
MySQL是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
Redis
Redis是非关系型数据库,即NoSQL。Redis将数据存储在缓存中,读取速度较快,能大大提升运行效率,但是保存时间有限。
MySQL的索引
优点
1.所有的MySQL字段类型都可以被索引
2.能够大大提高数据的查询速度
缺点
1.创建和维护索引要耗费时间,随着数据量的增加,耗费的时间也会增加
2.索引也需要占空间,若有大量的索引,索引文件可能会比数据文件更快达到数据表的数据上线
3.当对表中数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度
使用原则
1.对经常更新的表避免进行的过多的索引,对于经常用于查询的字段应该创建索引。
2.数据量小的表最好不要使用索引。当数据量较小时,用于查询全部数据花费的时间可能比遍历索引的时间还要少。
3.在同一值少的列(字段)上不要建立索引(男,女)。
机器学习数据处理时数据量太大,怎么处理?内存都装不下时怎么处理
1.分配更多内存
2.用更小的样本
3.更多内存
4.出纳换数据格式
5.流式处理数据,或渐进式的数据加载
6.使用关系数据库
7.使用大数据平台
python中‘_’和‘__’的区别
单下划线(_):Python中没有真正的私有属性或方法,可以在你想生命私有的方法和属性前加上单下划线,以提示该属性和方法不应在外部调用。
双下划线(__):双下划线开头是为了不让子类重写该属性方法,通过类的实例化时自动转换。在类中的双下划线开的属性方法前加上__类名实现
MySQL中的truncate、delete和drop的区别
truncate tabel和delete只删除记录不删除表结构,drop将删除表的结构以来的约束(constrain)、触发器(trigger)、索引(index)。同时,truncate之后的自增字段开始从头计数,delete仍然保留在原来的数值















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









