







有效调整大型语言模型提升基础化和引文生成质量
Xi Ye ♢∗ Ruoxi Sun ♠ Sercan Ö. Arık ♠ Tomas Pfister ♠
♢The University of Texas at Austin ♠Google Cloud AI
♢ xiye@cs.utexas.edu
♠ {ruoxis,soarik,tpfister}@google.com
摘要
大型语言模型(LLMs)在自然语言理解和生成方面取得了显著进展。然而,在现实世界中广泛应用的一个主要问题是,它们可能会生成非事实的“虚幻”答案。为此,本文重点研究通过检索段落和提供引用来改善LLMs的基础,从而提高其准确性。我们提出了一个新的框架AGREE,即适应增强基础(Adaptation for GRounding EnhancEment),从整体角度改进基础。我们的框架调整了LLMs,使其在响应中自我基础化声明,并为检索到的文档提供准确的引用。这种在预训练LLMs基础上的调整需要为配对查询提供有根据的响应(带有引用),为此我们引入了一种方法,可以从未标记查询中自动构建此类数据。调整后的LLMs的自我基础化能力进一步赋予了它们测试时适应(TTA: test-time adaptation)能力,可以积极检索支持未基础化声明的段落,从而迭代改进LLMs的响应。在五个数据集和两个LLMs上,我们的结果表明,与基于提示的方法和基于后验引用的方法相比,我们提出的基于调整的AGREE框架生成了具有更准确引用的优质基础响应。
1. 引言
近年来,大型语言模型(LLMs)的进步在自然语言处理(NLP)领域展现出了显著的能力。这些模型以前所未有的规模和深度理解、生成和操纵文本的能力,使它们成为人工智能领域蓬勃发展中的一股变革力量,并有望对我们日益数据驱动的世界产生重大影响。尽管LLMs被广泛采用,但一个突出问题是在某些情况下它们会产生虚幻信息:即生成听起来合理但非事实的信息,这限制了它们在现实世界设置中的应用。为了减轻这种虚幻性,解决方案通常依赖于将LLM生成的响应中的声明与支持的段落相结合,通过提供归因报告或向声明中添加引文。
使LLM生成的响应更加可信,通过提供支持和添加引文,已经引起了越来越多的兴趣。一方面的工作是使用指令调整或上下文学习来指导LLMs生成有根据的响应,并引用检索到的段落,遵循检索增强的生成框架。由于LLMs需要从仅有的指令和少量样本演示中执行这项具有挑战性的任务,这样的方向往往导致平庸的基础质量。另一方面的工作是后验引用,它使用自然语言推理(NLI)模型将支持段落与响应中的声明联系起来。这种范式严重依赖于LLMs的参数知识,并且可能无法很好地扩展到较少为人所知的知识。
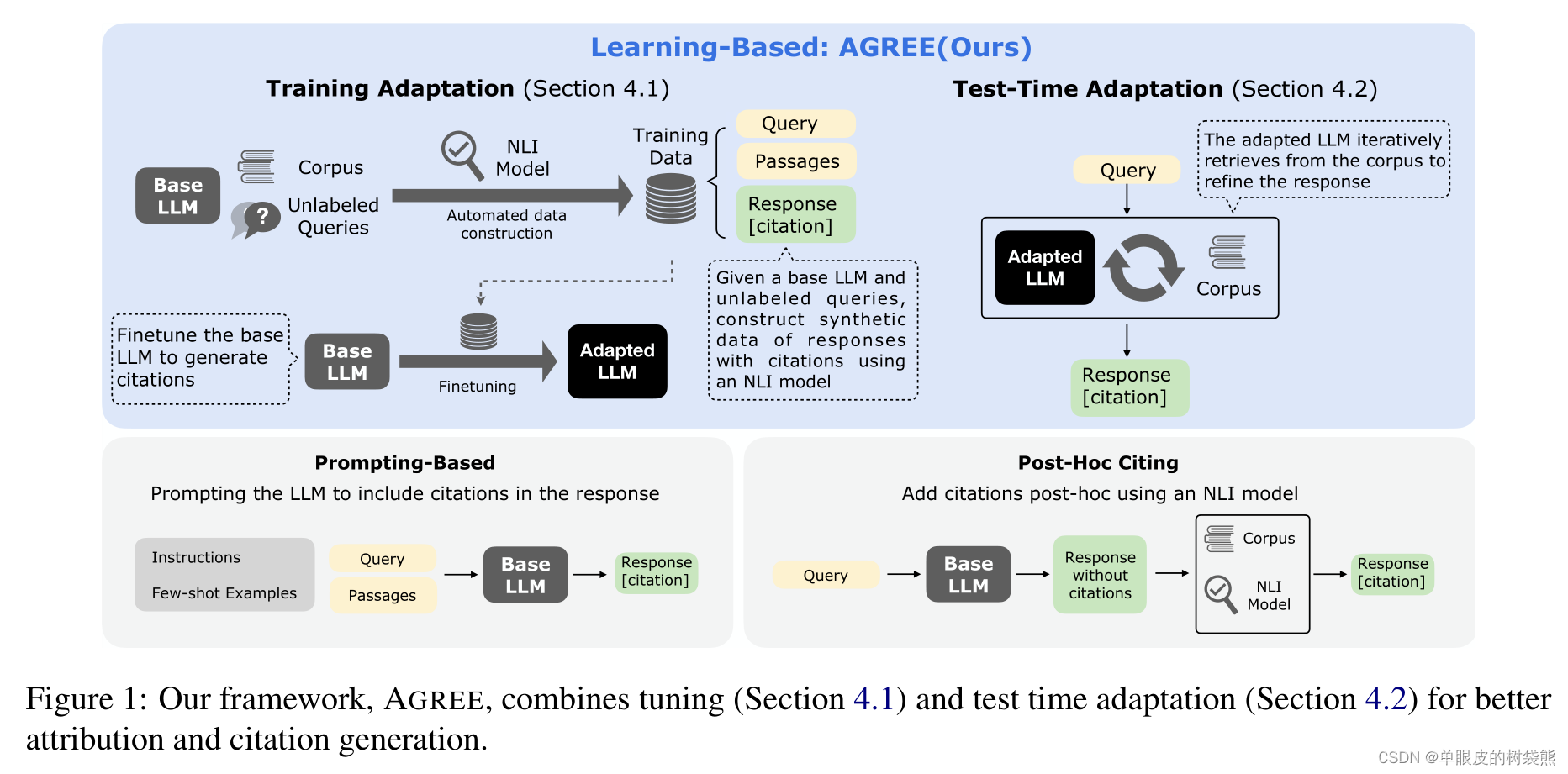
我们提出了一个新的基于学习的框架,AGREE,即大型语言模型(LLMs)的适应性基础增强。如图1所示,我们的框架对LLMs进行了微调,以生成引文,而不是依赖于提示或外部自然语言推理(NLI)模型的后验方式。在训练阶段,AGREE借助NLI模型从基础LLM中自动为未标记的查询收集有根据的响应。接下来,使用收集到的数据来监督LLMs基于检索到的段落生成有根据的响应,并在其响应中包含引文。作为一种测试时方法,我们提出了一种迭代推理策略,允许LLMs基于自我基础评估来寻求额外信息,以细化其响应。微调和测试时适应共同使LLMs能够有效且高效地将它们的响应建立在语料库中。我们将AGREE框架应用于适应基于API的LLM(text-bison)和开放LLM(llama-2-13b),并使用从三个数据集中的未标记查询收集的训练数据。我们在域内和域外数据集上进行评估,将提出的AGREE框架与有竞争力的上下文学习和后验引用基线进行比较。实验结果表明,与基线相比,AGREE框架在引文召回率和精确度方面成功地提高了基础,幅度很大(通常超过20%)。我们发现,通过我们精心设计的调整机制,LLMs可以学习在其响应中添加准确的引文。此外,使用某些数据集进行微调所实现的基础质量改进可以很好地跨领域推广。总之,我们的主要贡献包括:.
- 一种基于学习的方法,利用自动创建的数据,将基础LLM适应为在其响应中包含准确的引文;
- 一种测试时适应(TTA)方法,基于引文信息迭代改进LLMs的响应;
- 在五个数据集上对两个LLMs进行了大量实验,证明了所提出的AGREE框架在提高基础和引文生成方面的有效性。
2 相关工作
幻觉在许多任务中是生成语言模型普遍存在的问题。已经通过不同的方式对其进行了评估,调查了生成响应的基础。已经提出了各种方法来减轻幻觉并改善LLM生成响应的事实性。其中,我们的工作特别关注为可归因的信息源提供引文。与现有的主要依赖零样本提示或少量样本提示或使用额外的NLI模型来添加引文的工作不同,我们提出了一种基于学习的方法来调整LLMs,以生成由引文支持的、基础更好的响应。
更广泛地说,最近的工作还研究了在不使用外部知识的情况下提高大型语言模型事实性的方法,包括推理时间干预、交叉检查、自我验证或强化学习。我们的工作与他们不同,我们在回复中提供了外部知识的引用。此外,过去的工作也使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









