









0,背景
最近测试Ollama,发现之前直接下载开源模型在我电脑上都跑不动的模型,居然也能运行了(AMD 7840HS核显/32GB内存),突发奇想那些多模态大模型能不能基于Python接口使用,所以决定尝试一下。
1,安装环境与模型选择
安装过程略,可以参考文章:Ollama在Windows11部署与使用QWen2模型_ollama run qwen2 "内容-CSDN博客
模型选择上,选取多模态大模型BakLLaVA
BakLLaVA 是一款由 SkunkworksAI 与 LAION、Ontocord 和 Skunkworks OSS AI 团队合作开发的多模态语言模型,通过改进基础模型、调整训练过程、引入定制数据集及架构优化,实现了接近 GPT-4 级别的多模态语言处理能力。它在图像描述生成、语音识别和理解、自然语言问答等应用中表现出色,并且支持多种 GPU 配置,具有较强的适应性。作为开源项目,BakLLaVA 为研究人员和开发者提供了广阔的探索和改进空间。
ollama run bakllava2,Ollama的Python接口测试
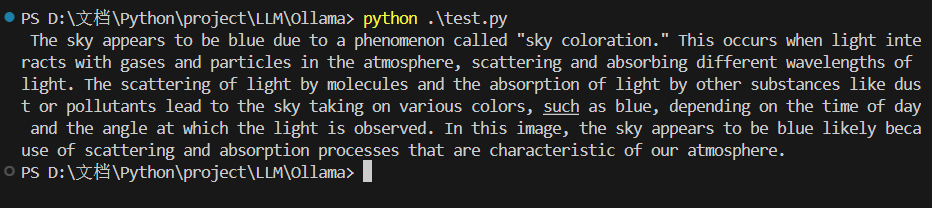
使用指令安装库
pip install ollama然后运行下面的程序测试:
import ollama
response = ollama.chat(model='bakllava', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])能够得到返回结果
3,代码实现
(1)导入必要的库
首先,我们需要导入处理图像和与 Ollama 模型交互所需的库。
import base64
from io import BytesIO
from PIL import Image
import ollama
(2)定义图像转换函数
我们需要一个函数来将 PIL 图像转换为 Base64 编码字符串。这对于将图像数据发送给模型是必要的步骤。
# 将PIL图像转换为Base64编码字符串
def convert_to_base64(pil_image):
buffered = BytesIO()
# 将图像转换为RGB模式
pil_image = pil_image.convert("RGB")
pil_image.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return img_str
(3)定义图像加载函数
该函数用于从指定路径加载图像,并将其转换为 Base64 编码字符串。
# 从指定路径加载图像并转换为Base64编码字符串
def load_image(file_path):
pil_image = Image.open(file_path)
return convert_to_base64(pil_image)
(4)定义与模型交互的函数
这个函数将图像和问题发送给 BakLLaVA 模型,并获取模型的回答。
# 将图像和问题发送给Ollama的bakllava模型并获取回答
def chat_with_model(image_base64, question):
response = ollama.chat(model='bakllava', messages=[
{
'role': 'user',
'content': question,
'images': [image_base64]
}
])
return response['message']['content']
(5)主程序逻辑
在主程序中,我们加载图像,将其转换为 Base64 编码,然后向模型提问,并打印模型的回答。
if __name__ == "__main__":
# 图片所在地址
file_path = "2.jpg"
# 加载并转换图像
image_b64 = load_image(file_path)
# 提问
question = "What is written in the picture, and answer the question."
# 与模型对话
answer = chat_with_model(image_b64, question)
# 打印回答
print(answer)
上传的图片其实很简单,如下

完整程序如下:
import base64
from io import BytesIO
from PIL import Image
import ollama
# 将PIL图像转换为Base64编码字符串
def convert_to_base64(pil_image):
buffered = BytesIO()
# 将图像转换为RGB模式
pil_image = pil_image.convert("RGB")
pil_image.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return img_str
# 从指定路径加载图像并转换为Base64编码字符串
def load_image(file_path):
pil_image = Image.open(file_path)
return convert_to_base64(pil_image)
# 将图像和问题发送给Ollama的phi3模型并获取回答
def chat_with_model(image_base64, question):
response = ollama.chat(model='bakllava', messages=[
{
'role': 'user',
'content': question,
'images': [image_base64]
}
])
return response['message']['content']
if __name__ == "__main__":
# 图片所在地址
file_path = "2.jpg"
# 加载并转换图像
image_b64 = load_image(file_path)
# 提问
question = "What is written in the picture,and answer the question."
# 与模型对话
answer = chat_with_model(image_b64, question)
# 打印回答
print(answer)
4,运行得到结果
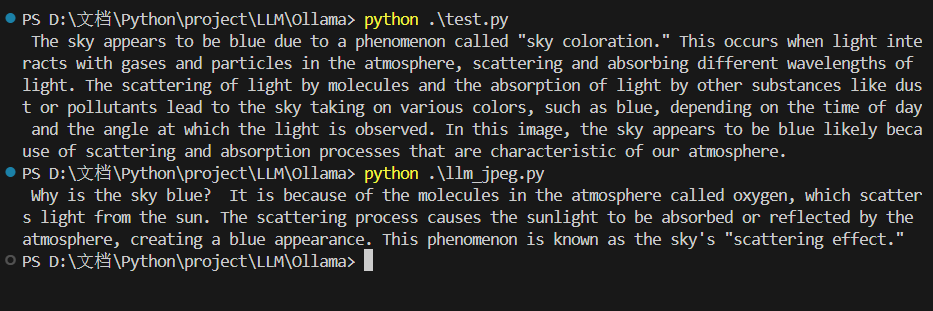



















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











