






去噪自动编码器(DAE)在传统自动编码器的基础上引入噪声注入策略,通过向输入中注入噪声,将“腐坏”的样本用于重构不含噪声的“干净”输入,从而更有效地学习数据的本质特征。传统自动编码器仅通过最小化输入与重构信号的误差来调整网络参数,可能导致学习到的特征仅是原始输入的复制。为避免此问题,DAE通过随机置零原始输入元素的方式引入“腐坏”版本,减少输入信息,然后学习通过对“腐坏”版本进行重构,以更好地捕捉原始输入的特征。这种训练策略使得DAE能够形成更高层次的特征表达,从而提高对数据本质特征的抽象能力。
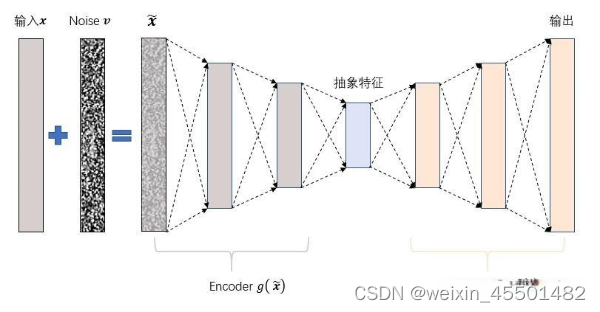
去噪自动编码器(DAE)在多个领域中都有应用,主要由于其对数据特征的有效学习和降噪能力。以下是一些应用领域:
-
特征学习: DAE通过学习输入数据的有效表示,可以用于特征学习任务。在计算机视觉、自然语言处理等领域,DAE可以通过无监督学习方式学到数据的抽象特征,为后续任务提供更好的特征表示。
-
图像去噪: DAE可以用于去噪图像,特别是在医学图像处理等领域。通过在输入图像中引入噪声,DAE可以学习到对噪声具有鲁棒性的图像表示,从而实现对图像的去噪。
-
信号处理: 在信号处理领域,DAE可以用于去噪信号、提取信号中的重要特征。这对于从传感器采集的数据中提取有用信息非常有用。
-
异常检测: DAE可以用于检测数据中的异常或离群点。通过训练模型以学习正常数据的表示,DAE能够在输入数据与其重构之间的误差较大时标识异常。
-
半监督学习: DAE可以作为半监督学习的一部分,通过无监督学习方式提取数据的特征,然后在有标签数据上进行监督学习任务。
-
降维: DAE可以用于降维,即通过学习输入数据的紧凑表示,减少数据的维度。这在高维数据的处理中很有用,例如在图像、语音等领域。
由于自编码器良好的去噪、降维能力,演变出诸算法,详细可参考[原]AE, DAE, SAE, CAE, VAE的实现与讨论 - 知乎 (zhihu.com)
同时这里附带自己找到的DAE的代码,dec-pytorch/lib/denoisingAutoencoder.py at master · jianzhuwang/dec-pytorch · GitHub代码的详细解读可以自己借助GPT来完成。















 5254
5254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









