







Xgboost 应用
- xgboost 二分类
- 图形化方式分析训练结果
1. xgboost 二分类
二分类介绍
本文以经典的乳腺癌数据集,演示如何使用xgboost做二分类。本文仅仅是使用xgboost开发模型的一个开胃菜。
代码
from sklearn import datasets
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn import metrics
import pickle
# 加载示例数据
dbunch = datasets.load_breast_cancer(as_frame=True)
df = dbunch.frame
features = dbunch.feature_names
target_names = dbunch.target_names
target = 'target'
n_valid = 50
train_df, valid_df = train_test_split(df, test_size=n_valid, random_state=42)
# 设置模型超参数
params = {
'tree_method': 'exact',
'objective': 'binary:logistic',
'n_estimators': 50,
'eval_metric': ['error', 'logloss'],
}
# 使用xgboost提供的兼容sklearn接口的方式创建一个分类器
clf = xgb.XGBClassifier(**params)
clf.fit(train_df[features], train_df[target],
eval_set=[(train_df[features], train_df[target]), (valid_df[features], valid_df[target])],
verbose=10)
y_true = valid_df[target]
y_pred = clf.predict(valid_df[features])
print(metrics.classification_report(y_true, y_pred, target_names=target_names))
# 如果模型训练达到期望的指标,以xgboost提供的格式保存模型
clf.save_model('breast_cancer_best_model.ubj')
# 由于在下一篇技术文章分析模型效果时,需要用到训练过程中的损失函数值,下面以pickle方式保存模型
with open('breast_cancer_best_model.pkl', 'wb') as f:
pickle.dump(clf, f)
结果展示
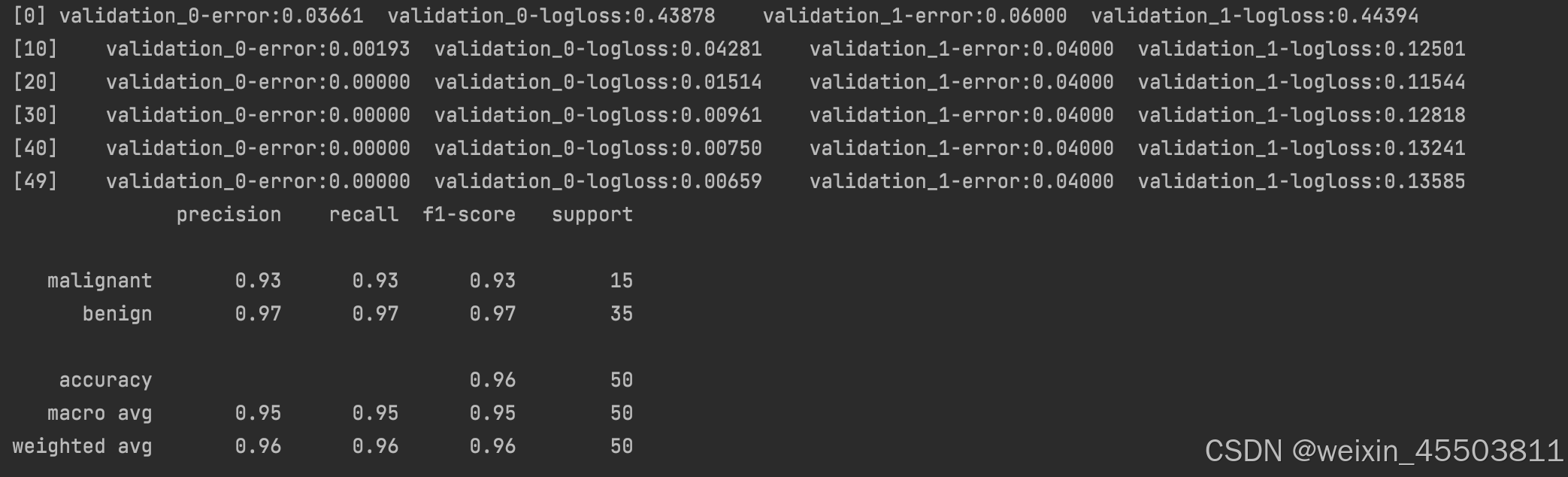
下一篇
xgboost 二分类训练效果图示

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









