







论文信息
题目:Meta-Learning with Implicit Gradients
作者:
期刊会议:
年份:2019
基础补充
内容
动机
动机:
- Recent work has studied how meta-learning algorithms can acquire such a capability by learning to efficiently learn a range of tasks, thereby enabling learning of a
new task with as little as a single example. We focus on this class of optimization-based methods, and in particular themodel-agnostic meta-learning(MAML) formulation. MAML has been shown to be as ex- pressive as black-box approaches, is applicable to a broad range of settings, and recovers a convergent and consistent optimization procedure - Despite its appealing properties, meta-learning an initialization
requires backpropagationthrough the inner optimization process. As a result, the meta-learning processrequires higher-order derivatives, imposes a non-trivial computational andmemory burden, and can suffer fromvanishing gradients.
创新: - Our approach is agnostic to the choice of inner loop optimizer and can gracefully handle many gradient steps without vanishing gradients or memory constraints
- These limitations make it harder to scale optimization-based meta learning methods to tasks involving medium or large datasets, or those that require
many inner-loop optimization steps. Our goal is to develop an algorithm thataddresses these limitations
Our approach of decoupling of meta-gradient computation and choice of inner level optimizer has a number of appealing properties.
- First, the inner optimization path need
not be stored nor differentiatedthrough, thereby making implicit MAMLmemory efficientandscalable to a large number of inner optimization steps. - Second, implicit MAML is
agnostic to the inner optimization methodused, as long as it can find an approximate solution to the inner-level optimization problem. Thispermitsthe use ofhigher-order methods, and in principle evennon-differentiable optimization methodsor components like sample- based optimization, line-search, or those provided by proprietary software - Finally, we also provide the first (to our knowledge)
non-asymptotic theoretical analysis of bi-level optimization.
方法
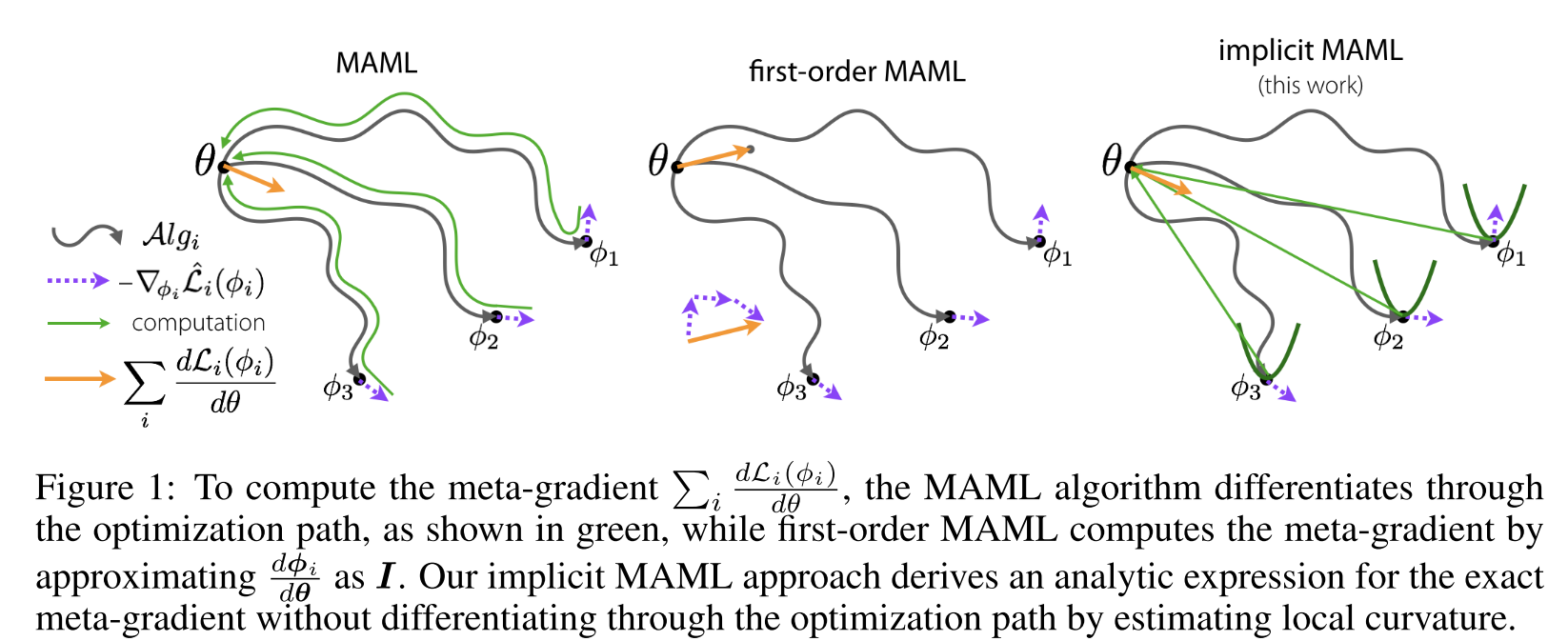
- Our algorithm aims to learn a set of parameters such that an optimization algorithm that is initialized at and regularized to this parameter vector leads to good generalization for a variety of learning tasks. By leveraging the implicit differentiation approach, we derive an analytical expression for the meta (or outer level) gradient that depends only
on the solution to the inner optimizationandnot the path taken by the inner optimization algorithm, as depicted in Figure 1.
















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











