






深度学习的三个步骤:
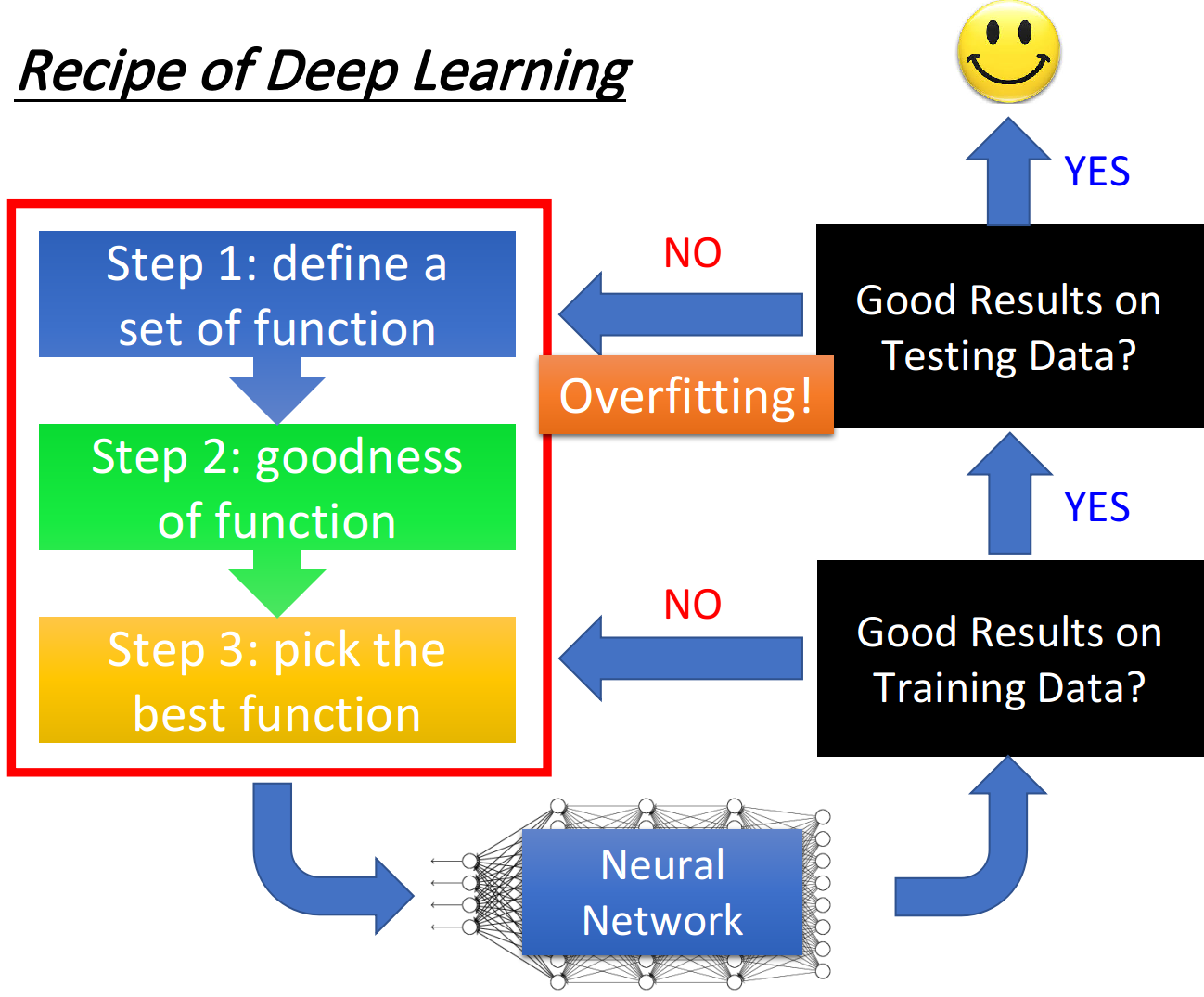
如果要想得到一个更好的神经网络应该怎么做:
1、提高模型在训练集上的正确率
深度学习并不会像K近邻等方法,一次训练就得到较好的正确率,他可能在训练集上没办法得到较好的正确率,这个时候就需要回头检查前面的步骤里需要修改的部分,如何使得训练集得到较高的正确率。
2、提高模型在测试集上的正确率
如果已经在训练集上取得好的效果,这时就需要考虑在测试集上的正确率,假如结果不好,这个情况是过拟合,需要回头解决过拟合问题。
3、并不是所有不好的情况都是过拟合
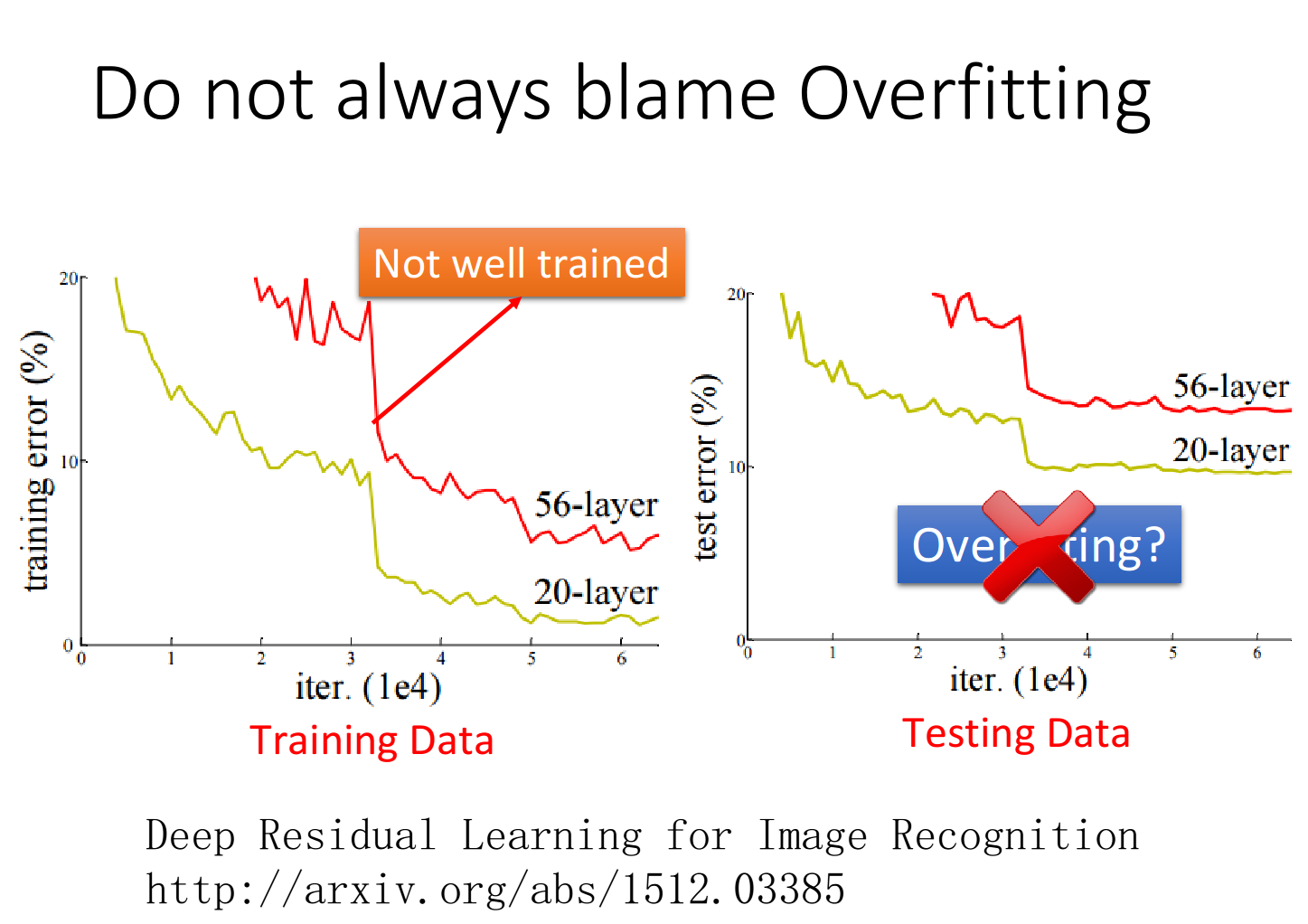
如图所示,横坐标是模型做梯度下降所更新的次数,纵坐标是error rate,黄线是20层网络,红线表示56层网络,可以从测试数据中看出56层的效果没有20层好。但是这并不是过拟合,从训练数据中可以看出在训练集上20层的效果就好于56层,所以这是没有训练好的原因。
总的说:
1、训练集上表现不好
2、测试集上表现不好
下面从两个方面,介绍针对性优化方法:
1、训练集上
训练集上总的来说有两个方面:
1、新的激励函数
如果训练不好,有可能是网络架构设计的不好,可能用的激活函数是对训练不利的,可以更换一些新的激活函数。
梯度消失问题:
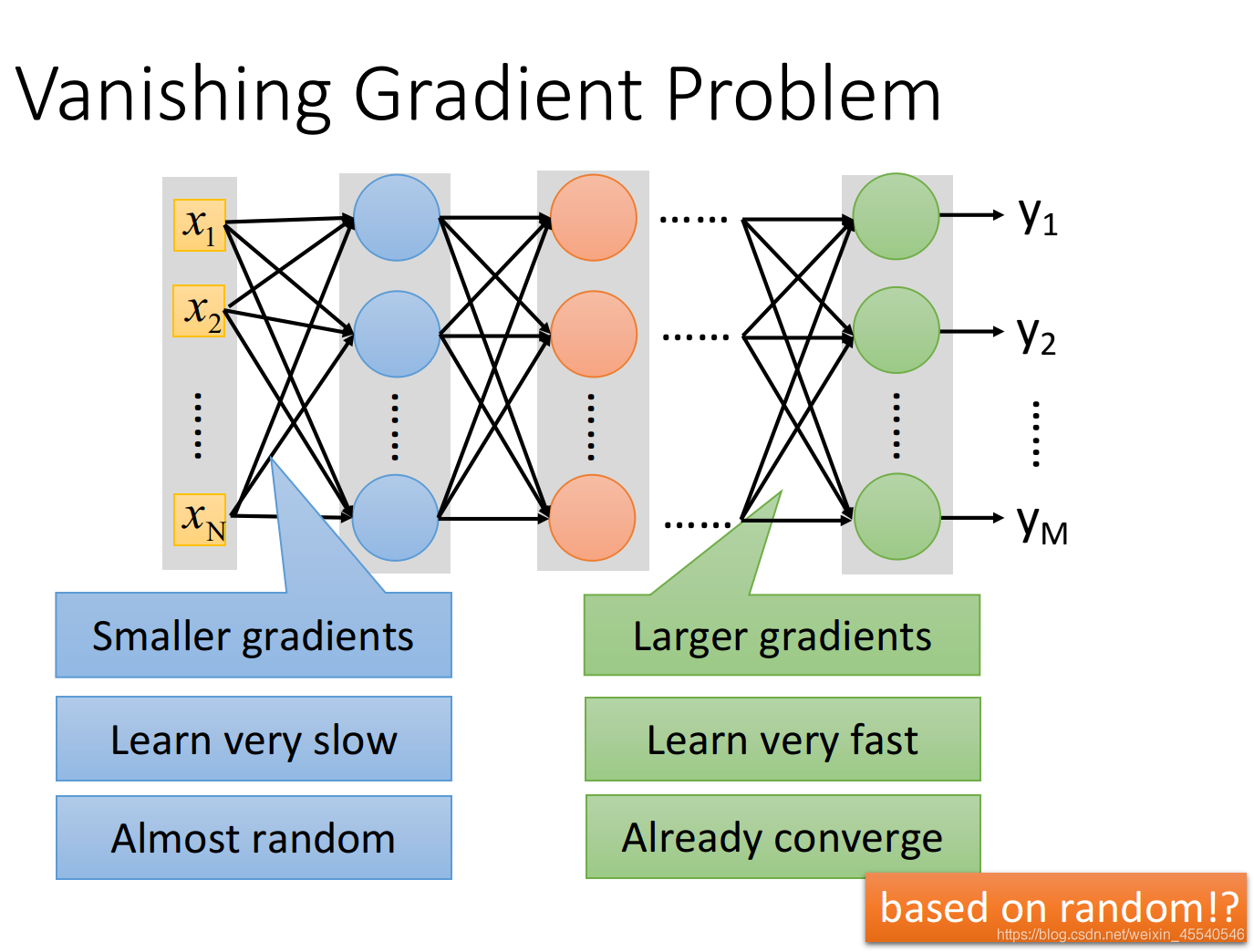
以三个隐藏层的单神经元神经网络为例,激活函数采用sigmoid:
假设每一层网络激活后输出为
f
i
(
x
)
f_{i}(x)
fi(x),其中i为第i层,x代表第i层的输入,也是第i-1的输出,f是激活函数,可以得出:
f
i
+
1
=
f
(
f
i
∗
w
i
+
1
+
b
i
+
1
)
f_{i+1} = f(f_{i}*w_{i+1}+b_{i+1})
fi+1=f(fi∗wi+1+bi+1)记为:
f
i
+
1
=
f
(
f
i
∗
w
i
+
1
)
f_{i+1} = f(f_{i}*w_{i+1})
fi+1=f(fi∗wi+1)。
反向传播算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为:
w
←
w
+
△
w
w\leftarrow w+\bigtriangleup w
w←w+△w,假如更新第二隐层的的权值信息,根据链式求导法则,更新梯度信息:
Δ
w
2
=
∂
L
o
s
s
∂
w
2
=
∂
L
o
s
s
∂
f
4
∂
f
4
∂
f
3
∂
f
3
∂
f
2
∂
f
2
∂
w
2
\Delta w_{2} = \frac{\partial Loss}{\partial w_{2}} = \frac{\partial Loss}{\partial f_{4}} \frac{\partial f_{4}}{\partial f_{3}}\frac{\partial f_{3}}{\partial f_{2}}\frac{\partial f_{2}}{\partial w_{2}}
Δw2=∂w2∂Loss=∂f4∂Loss∂f3∂f4∂f2∂f3∂w2∂f2
由
f
2
=
f
(
f
1
∗
w
2
)
f_{2} = f(f_{1}*w_{2})
f2=f(f1∗w2)得:
∂
f
2
∂
w
2
=
∂
f
∂
f
1
∗
w
2
f
1
\frac{\partial f_{2}}{\partial w_{2}} = \frac{\partial f}{\partial f_{1}*w_{2}} f_{1}
∂w2∂f2=∂f1∗w2∂ff1,其中
f
1
f_{1}
f1是第一层的输出。
∂
f
4
∂
f
3
=
f
′
∗
w
4
∗
∂
f
3
∂
f
2
=
f
′
∗
w
3
\frac{\partial f_{4}}{\partial f_{3}} = f^{'}*w_{4}*\frac{\partial f_{3}}{\partial f_{2}} = f^{'}*w_{3}
∂f3∂f4=f′∗w4∗∂f2∂f3=f′∗w3
对激活函数进行求导
f
′
f^{'}
f′,如果此部分大于1,当层数增加时,最终得求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1时,随着层数增加,求出的梯度更新将以指数得形式衰减,即发生梯度消失。
更改激活函数可以解决梯度下降的问题:
1、ReLU
Rectified Linear Unit(整流线性单元函数,修正线性单元,ReLU)该函数形状如下图所示,z为输入,a为输出,如果输入大于0,则输出等于输入,如果输入小于0则输出等于0:
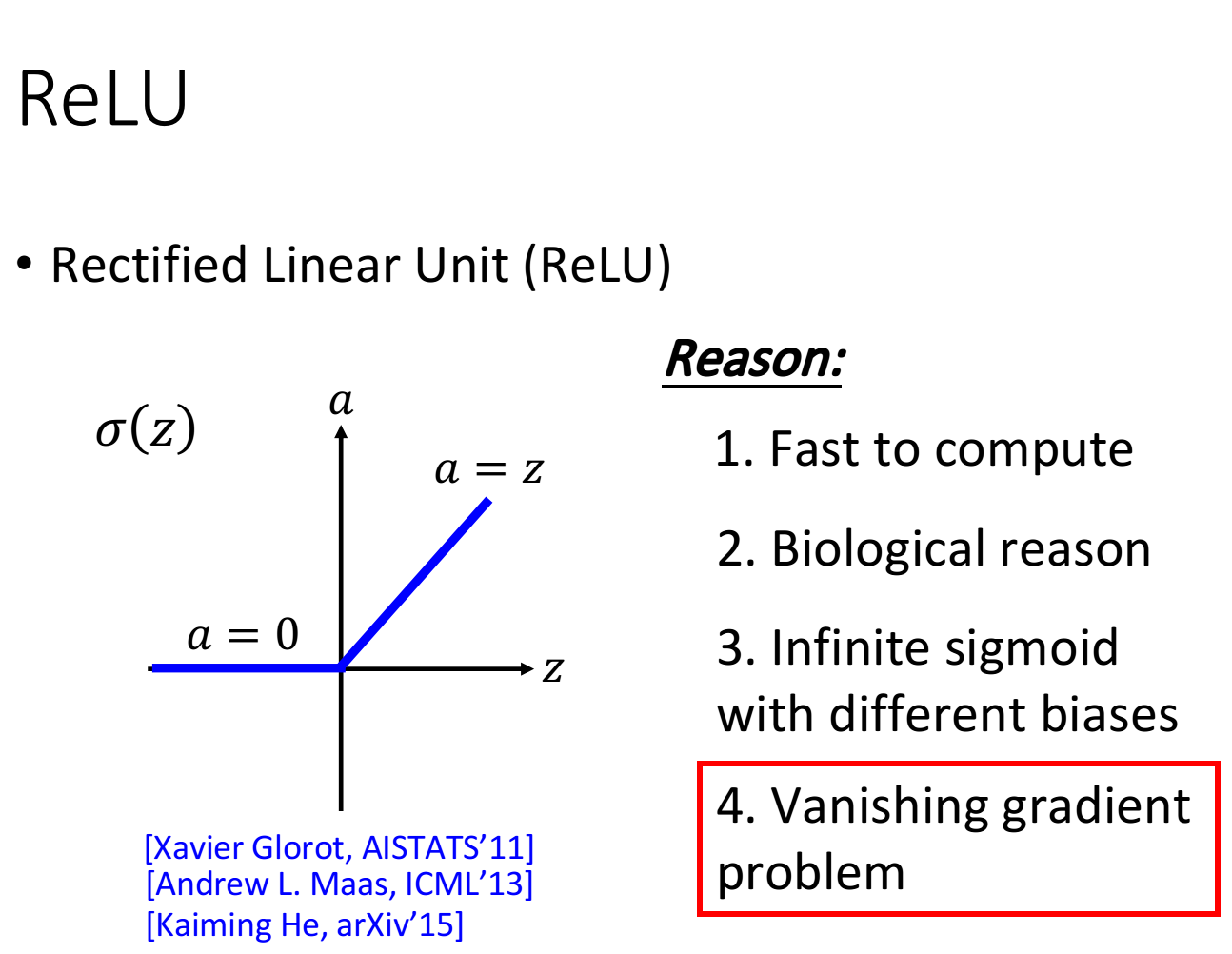
ReLU的优点:
1、跟sigmoid函数相比,ReLU函数运算比较快
2、ReLU的想法结合了生物上的观察
3、无穷多bias不同的sigmoid函数叠加结果会变成ReLU
4、ReLU可以处理梯度下降的问题
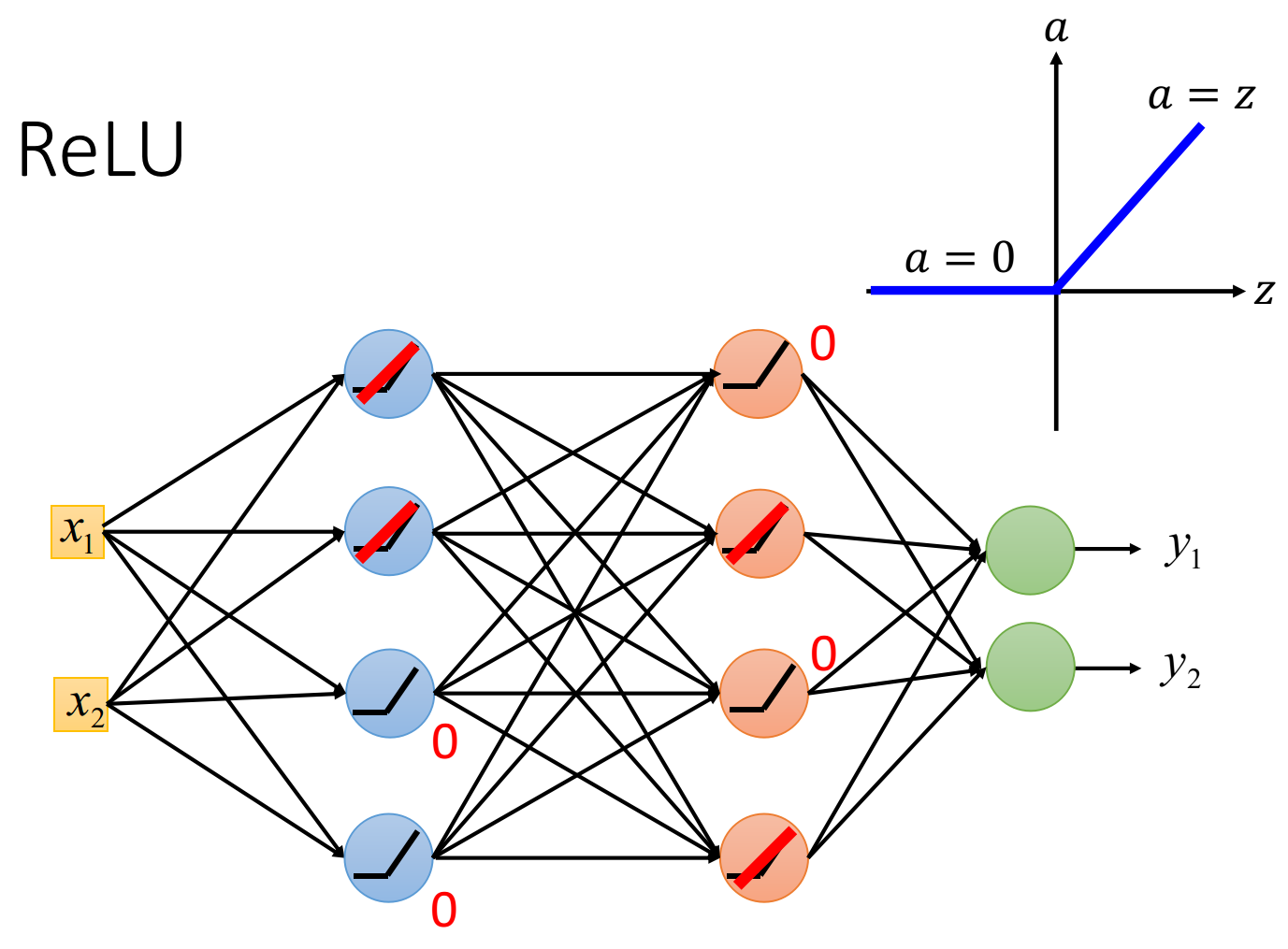
如上图所示:ReLU的神经网络,以ReLU作为激活函数的神经元,它的输出等于0,或者输入。当输出等于输入,这个激活函数就是线性的,当输出等于0的整个神经元对整个网络是没有任何作用的,可以从网络中剔除。
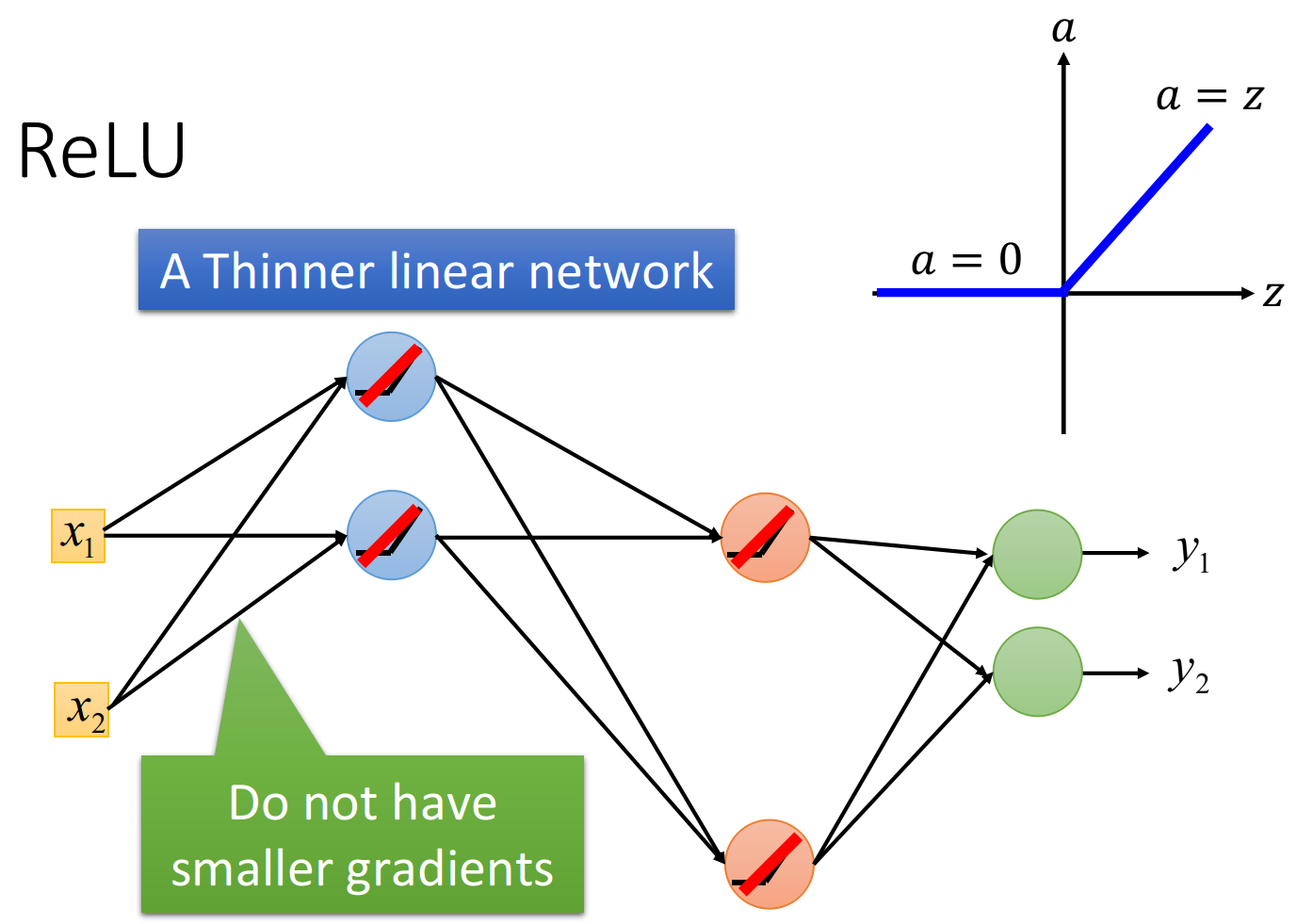
如下图所示,拿掉所有输出为0 的神经元,此时整个网络变成了一个瘦长的线性网络,线性的好处是,输出等于输入不会像sigmoid函数使得输入产生的影响逐层递减。
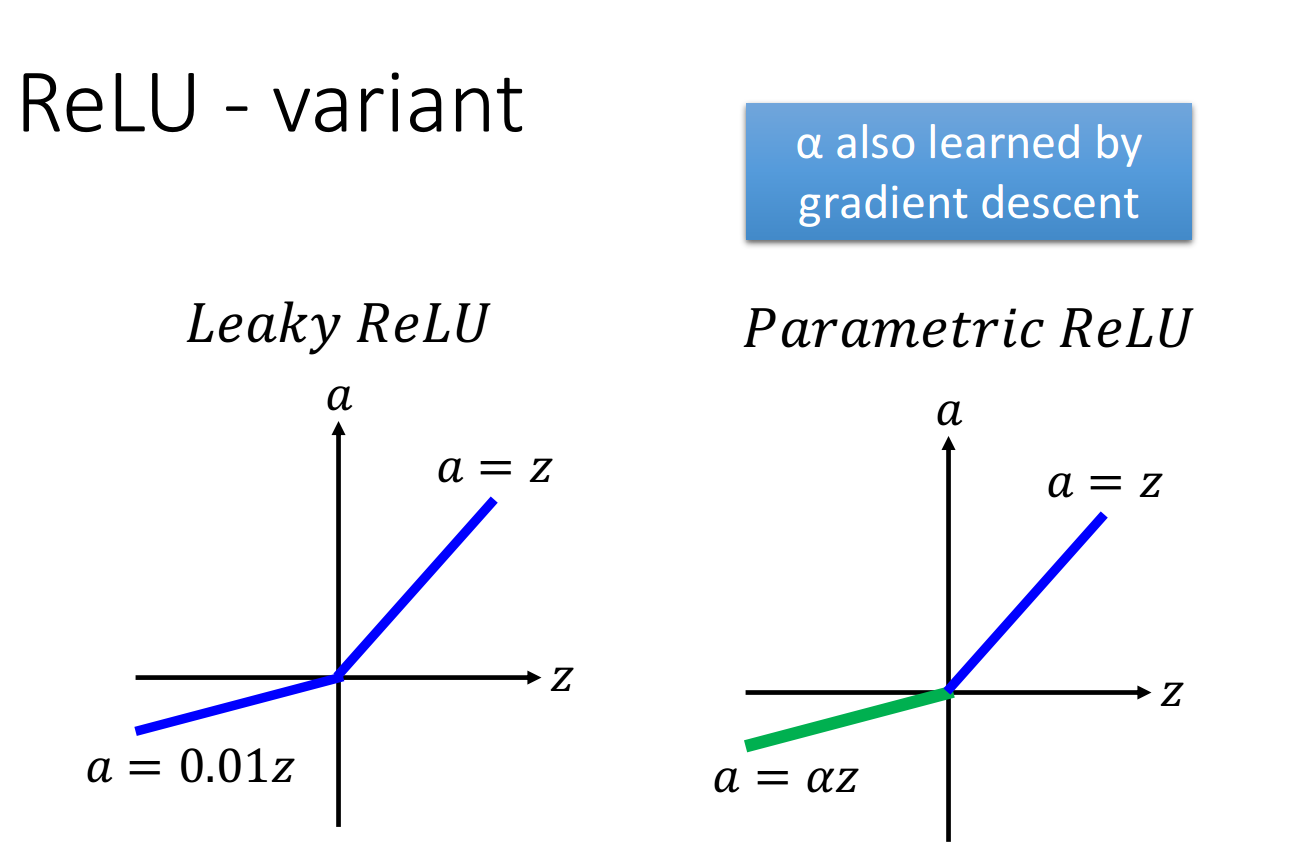
2、Leaky ReLU
ReLU存在的问题:当输入小于0的时候,输出为0,此时微分值梯度也是0,就没有办法更新参数,所以Leaky ReLU为此做了调整:令a = 0.01z。
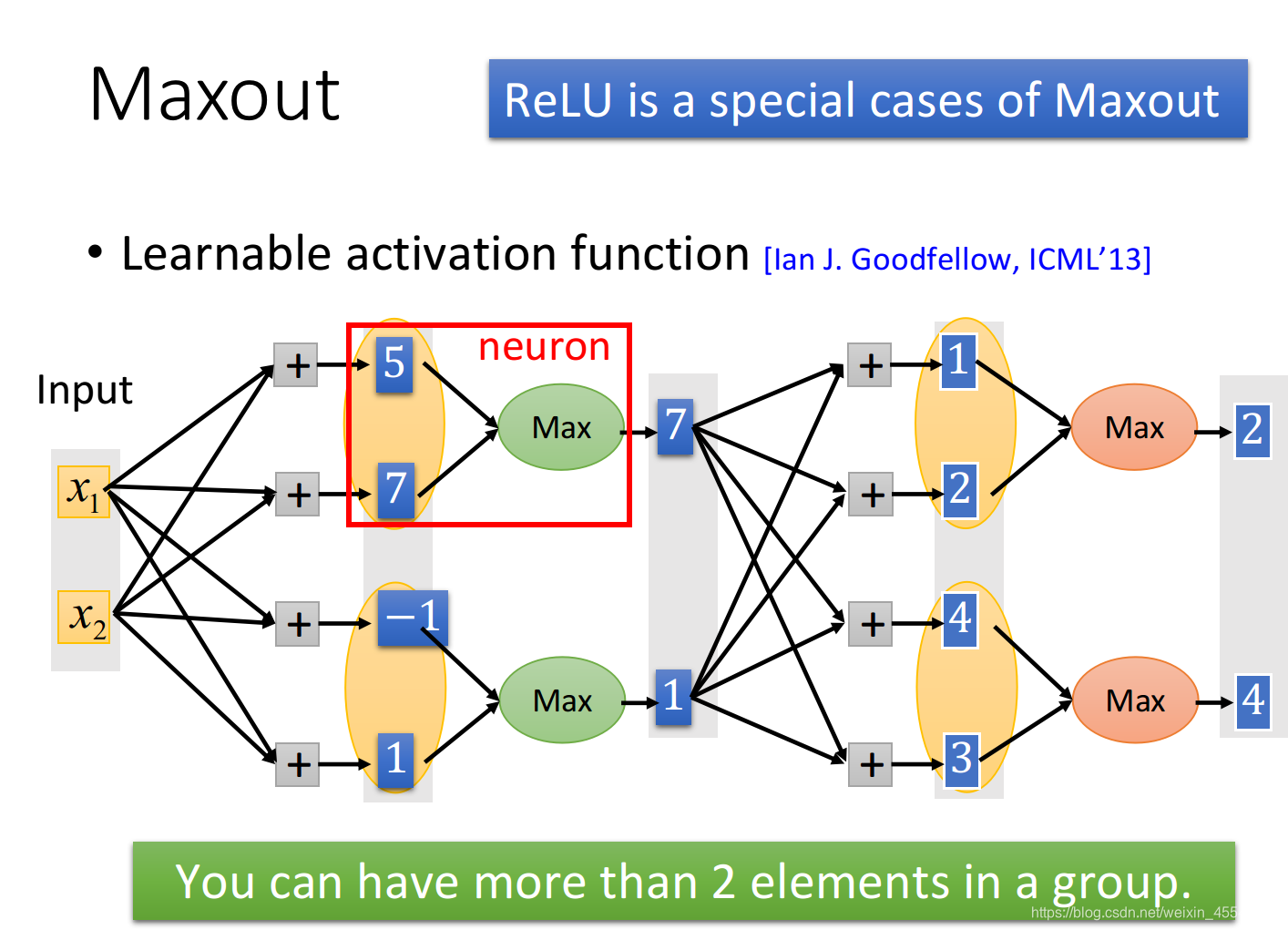
3、Maxout
Maxout的想法是,让网络自动的去学习激活函数,激活函数是由其训练集决定的。
假设有输入
x
1
,
x
2
x_{1},x_{2}
x1,x2,他们乘上几组不同的权重分别得到5,7,-1,1,他们通过激活函数变成神经元的输出,在Maxout中,事先决定好某几个神经元的输入分为一个组,如5,7为一个组,-1,1为一个组,然后在这些组里面选取最大值,7,1作为暑促,相当于在layer上做了Max pooling。
Maxout如何模仿ReLU:
如图为ReLU的神经元,它的输入x会乘上神经元的权重,再加上bias,b然后通过ReLU激活函数得到输出a.
神经元的输入为
z
=
w
x
+
b
z = wx + b
z=wx+b,为下图左下角紫线。
神经元的输出为
a
=
z
(
z
>
0
)
;
a
=
0
(
z
<
0
)
a = z(z>0);a = 0(z<0)
a=z(z>0);a=0(z<0),为左下角绿线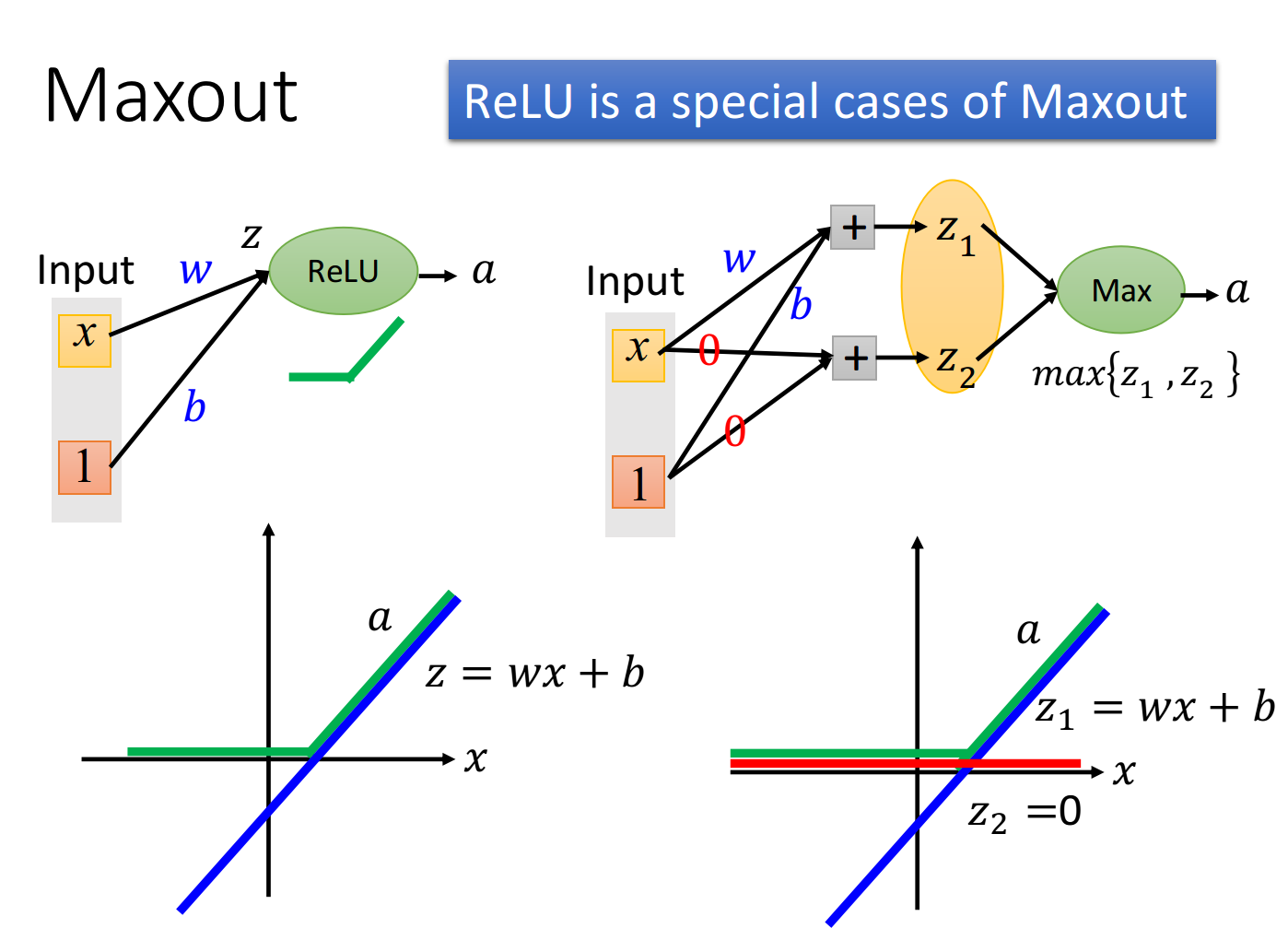
如果采用上图右上角的Maxout network,假设
z
1
z_{1}
z1的参数w,b与ReLU的参数一致,而
z
1
z_{1}
z1的参数w,b全部设为0,然后做Max pooling,选取
z
1
z_{1}
z1,
z
2
z_{2}
z2的较大值作为a。
神经元的输入为[
z
1
z_{1}
z1
z
2
z_{2}
z2]
神经元的输出为max[
z
1
z_{1}
z1
z
2
z_{2}
z2],为上图右下角绿线
可看出,此时ReLU和Maxout所得到的输出是一样的,他们是相同的激活函数。
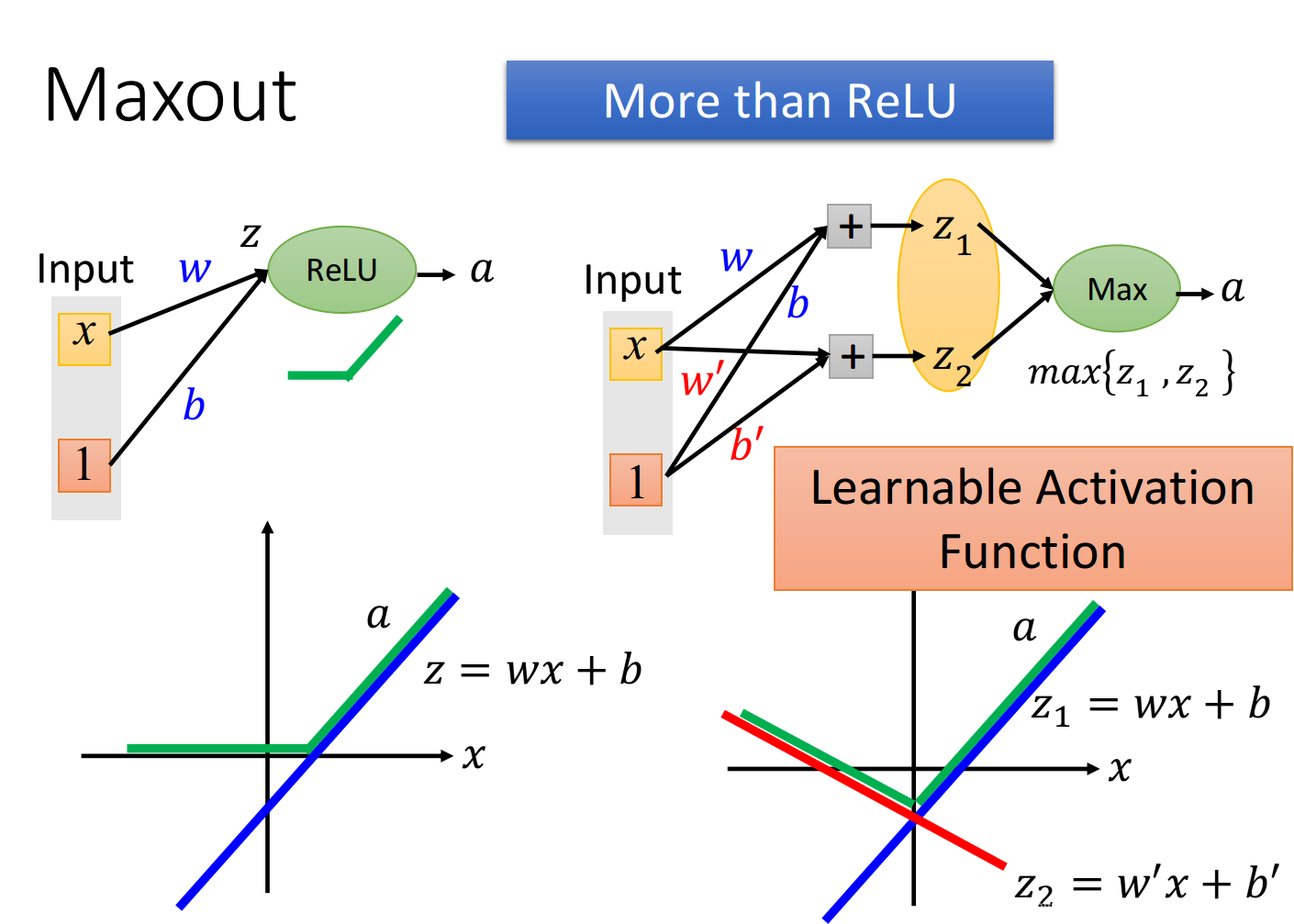
Maxout如何模仿Learnable Activation Function:
如果
z
2
z_{2}
z2的参数w,b不是0,而是
w
′
,
b
′
w^{'},b^{'}
w′,b′此时:
神经元的输入为[
z
1
z_{1}
z1
z
2
z_{2}
z2]
神经元的输出为max[
z
1
z_{1}
z1
z
2
z_{2}
z2],为下图右下角绿线
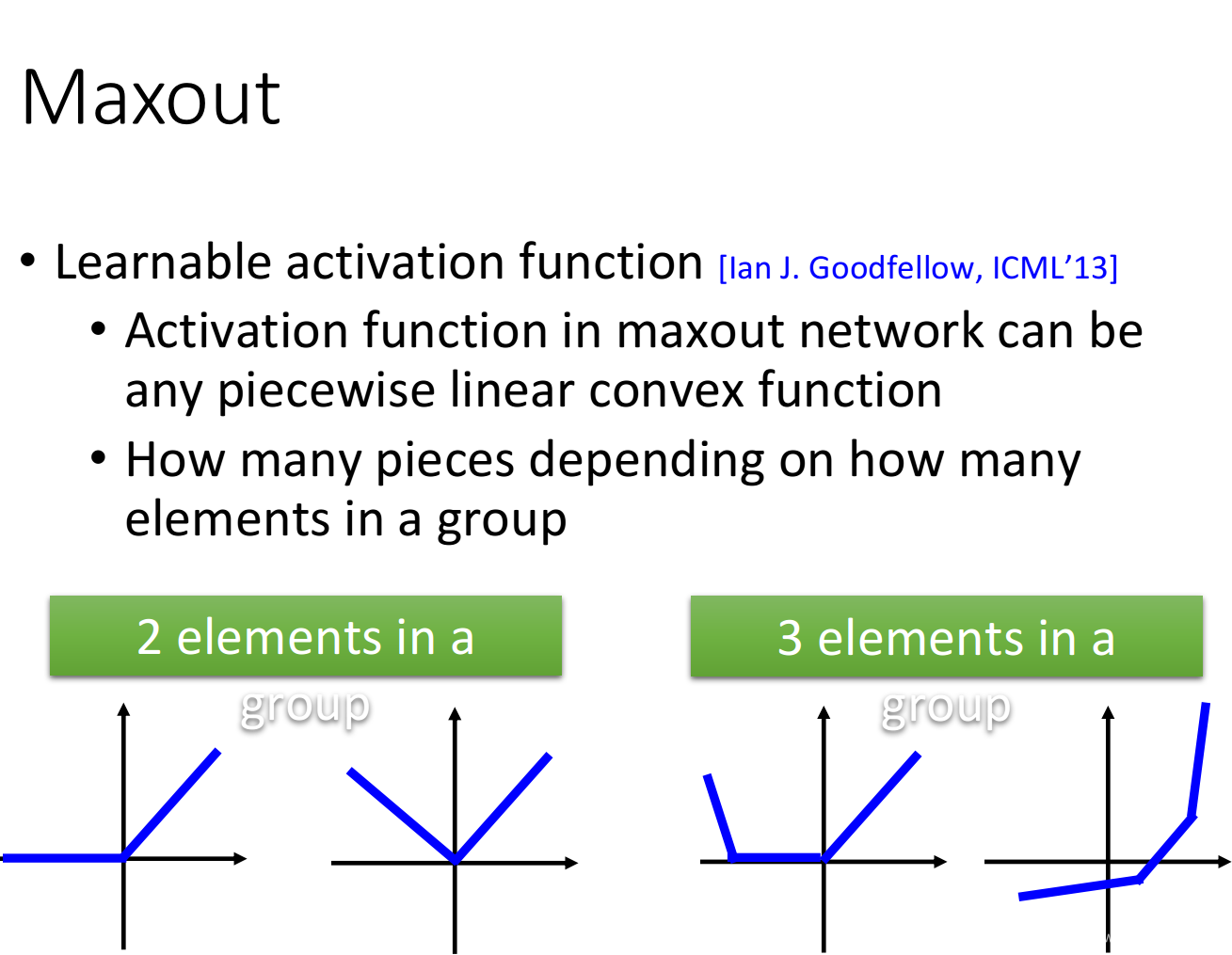
Maxout如何实现分段线性激活函数:
activation function被分为多少段,取决于你把多少个element z放到一个group里,下图分别是2个element一组和3个element一组的activation function的不同形状
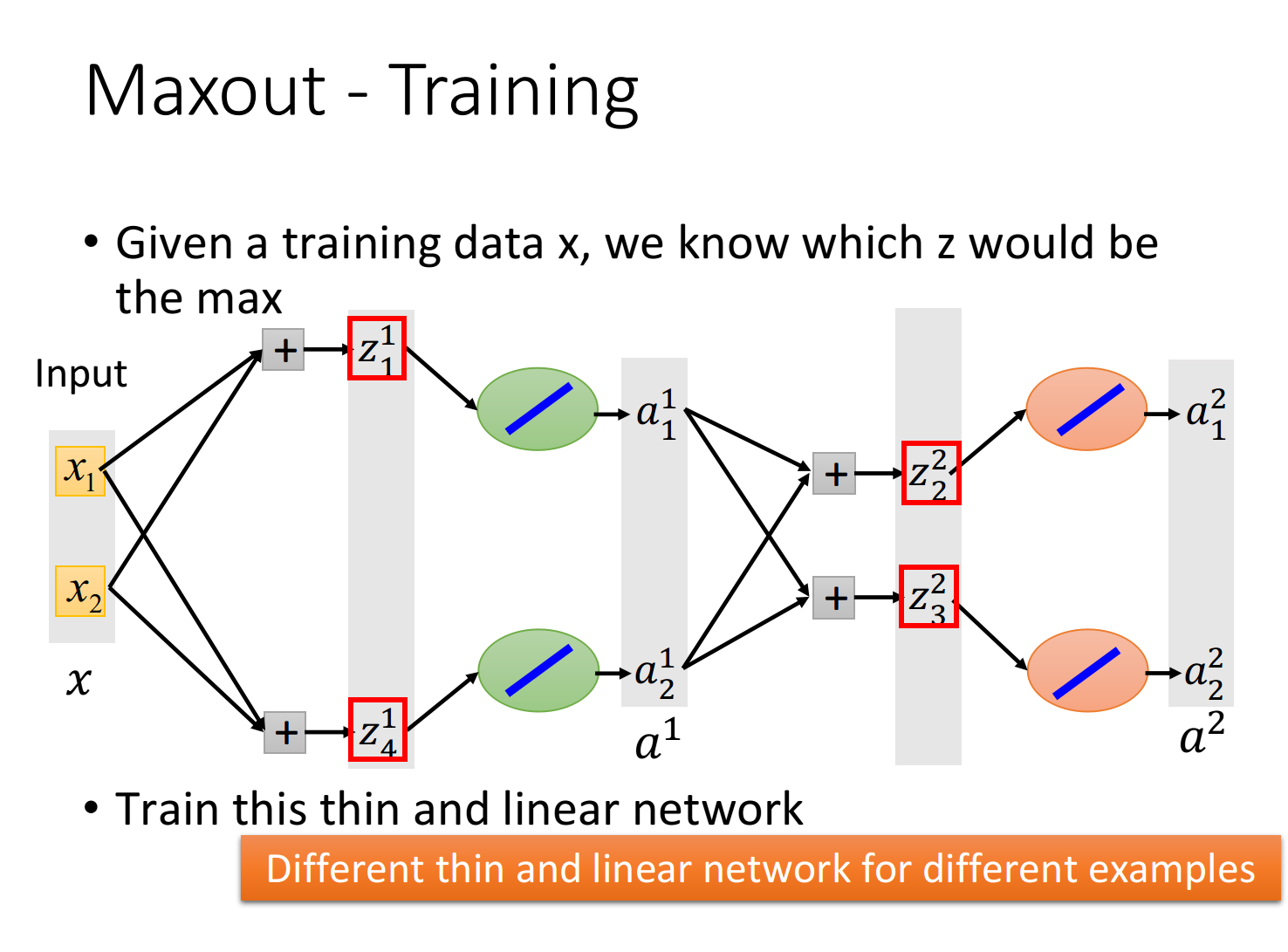
怎样训练Maxout:
假设红框为每个神经元的输出:

最大化操作(Max operation)就是线性操作,但是它仅接在前面这个组里的某一个元素上,因此我们可以把那些没有被Max连接到的元素拿掉,从而得到一个比较细长的线性网络。
我们真正训练的并不是一个含有max函数的网络,而是一个简化后如下图所示的线性网络,当没有开始训练模型时,这个网络含有max函数无法微分,但是每当输入一部分数据,网络就会根据这些数据确定具体形状,此时max函数的问题已经被实际数据给解决,所以我们可以根据这笔训练数据使用反向传播的方法去训练被网络留下来的参数。
在具体实践上,可以先根据数据把max函数转化为某个具体的函数,再对这个转化后的thiner linear 网络进行微分。
适应的学习率
Adagrad:让每一个参数有不同的学习率。

Adagrad的精神是,假设我们考虑两个参数
w
1
,
w
2
w_{1},w_{2}
w1,w2,如果在
w
1
w_{1}
w1这个方向上,平常的gradient都比较小,那它是比较平坦的,于是就给它比较大的learning rate;反过来说,在
w
2
w_{2}
w2这个方向上,平常gradient都比较大,那它是比较陡峭的,于是给它比较小的learning rate。
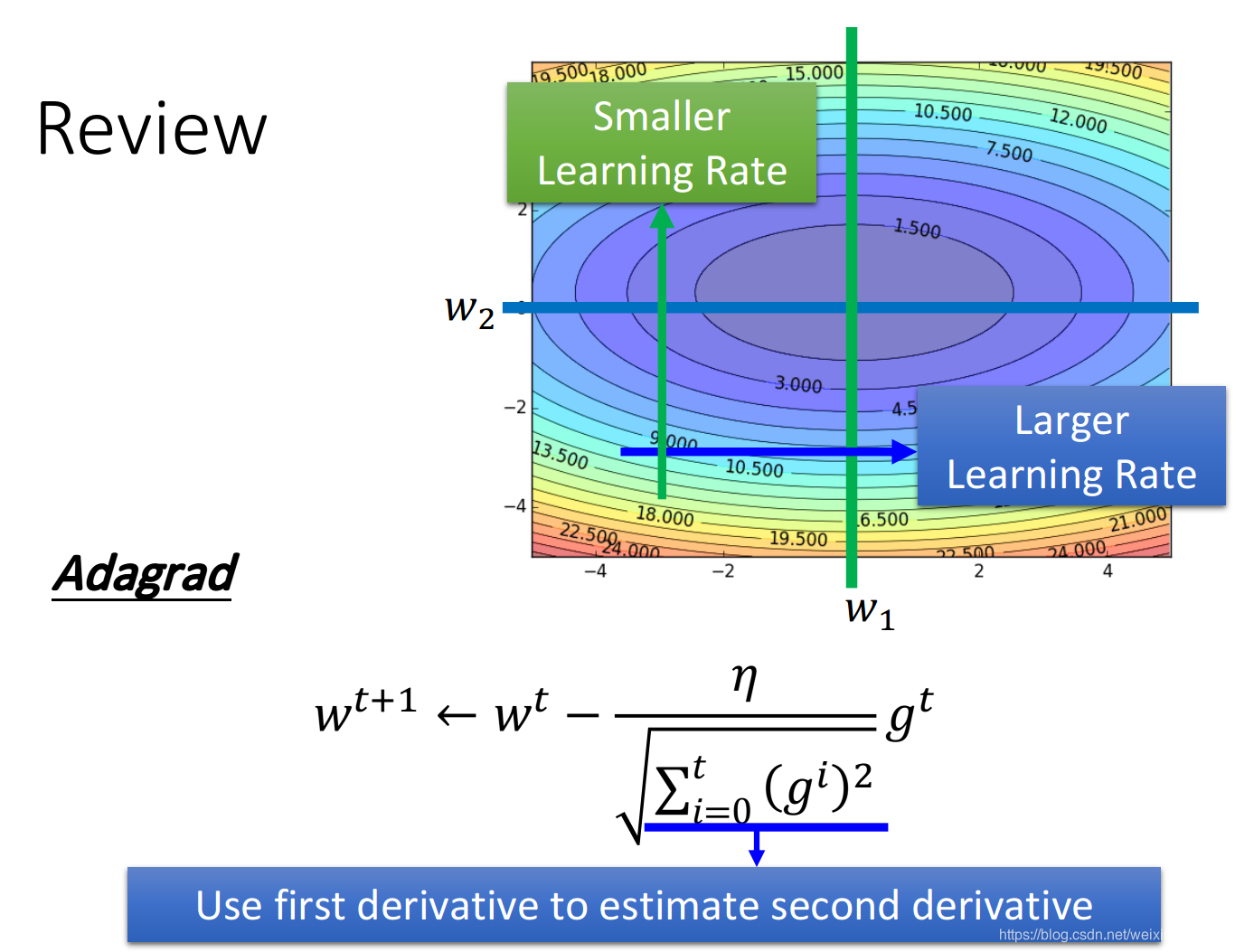
实际问题中,有可能比adagrad要复杂,实际上做深度学习,损失函数可以是任意形状。
RMSProp优化算法
RMSProp优化算法是Adagrad算法的一种改进。

可以看出RMSProp优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。
RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。见下: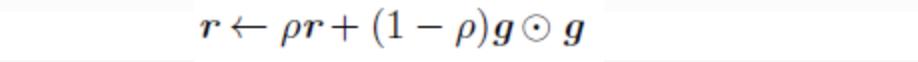
RMSProp的做法如下:
我们的learning rate依旧设置为一个固定的值η除掉一个变化的值σ,这个σ等于上一个σ和当前梯度g的加权方均根(特别的是,在第一个时间点,
σ
0
\sigma ^{0}
σ0就是第一个算出来的gradient值
g
0
g^{0}
g0),即:
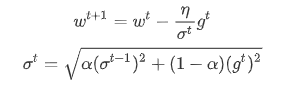
这里的α值是可以自由调整的,RMSProp跟Adagrad不同之处在于,Adagrad的分母是对过程中所有的gradient取平方和开根号,也就是说Adagrad考虑的是整个过程平均的gradient信息;而RMSProp虽然也是对所有的gradient进行平方和开根号,但是它用一个来调整对不同gradient的使用程度,比如你把α的值设的小一点,意思就是你更倾向于相信新的gradient所告诉你的error surface的平滑或陡峭程度,而比较无视于旧的gradient所提供给你的信息。

所以当你做RMSProp的时候,一样是在算gradient的root mean square,但是你可以给现在已经看到的gradient比较大的weight,给过去看到的gradient比较小的weight,来调整对gradient信息的使用程度。















 3987
3987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









