







 本文对比了XGBoost和LightGBM在算法原理和建模场景中的应用特点,包括数据处理效率、模型训练速度和过拟合控制。LightGBM在内存消耗和训练速度上优于XGBoost,支持直接处理类别型特征,并采用更高效的分裂策略。通过信贷A卡建模案例,展示了两者在模型训练和评估上的差异,结果显示LightGBM在保持类似精度的同时,训练效率更高。
本文对比了XGBoost和LightGBM在算法原理和建模场景中的应用特点,包括数据处理效率、模型训练速度和过拟合控制。LightGBM在内存消耗和训练速度上优于XGBoost,支持直接处理类别型特征,并采用更高效的分裂策略。通过信贷A卡建模案例,展示了两者在模型训练和评估上的差异,结果显示LightGBM在保持类似精度的同时,训练效率更高。
XGBoost与LightGBM在树模型中算是一对“明星”算法,在建模场景中经常得到使用,无论是模型训练的学习效果,还是模型应用的广泛程度,二者都有不错的表现。但是,同属于集成学习树模型的boosting类算法,XGBoost与LightGBM在数据处理的原理逻辑上还是有着明显区别,使得模型算法在实际应用的学习效率存在较大差异。因此,明确XGBoost与LightGBM的原理逻辑与特征对比,对我们在实际建模过程中针对算法选择、模型优化、效率提升等方面,有着重要的指导意义。
本文围绕XGBoost与LightGBM算法,给大家介绍下二者在算法原理上的主要区别,以及在实际建模场景中的应用特点。同时,我们结合信贷A卡建模场景案例,采用XGBoost与LightGBM来分别建立模型,对比分析这两种树模型算法在数据处理、模型训练、模型评估等环节的特点。
1、XGBoost与LightGBM对比
XGBoost与LightGBM都属于集成学习树模型的boosting算法,且根据GBDT算法框架逐渐发展而来的,XGBoost在前,LightGBM在后,可以理解为LightGBM是XGBoost的一种优化算法,二者区别主要包括以下几点:
(1)XGBoost是使用基于特征预排序(pre-sorted)方法的决策树算法预排序算法,每次根据单个特征算分裂增益时,需要遍历所有样本的特征取值,时间效率复杂度为datafeatures;而LightGBM是使用基于特征直方图(histogram)方法的决策树算法,只需要遍历特征直方图分桶数n次,时间效率复杂度为nfeatures。从内存消耗与时间效率上对比,LightGBM明显优于XGBoost。
XGBoost采用的是level-wise的分裂策略,对树的每一层所有节点无论增益大小都会进行无差别分裂,这样使得某些增益非常小的节点,虽然对结果影响不大,但还是强制分裂给算法效率带来了不必要的开销;而LightGBM是采用了leaf-wise的分裂策略,即在当前树的所有叶子节点中,通过选择分裂收益最大的节点进行分裂。在这种情况下,当树节点的分裂次数相同时,leaf-wise方法相比level-wise方法可以
(1)降低更多误差,得到较高的精度。但是,leaf-wise方法很容易促使树的深度过大,导致模型出现过拟合现象。一般情况下,采用LightGBM构建模型时,需要重点对参数树的深度进行限制,以避免模型过拟合。
(2)LightGBM直接支持类别型特征进行模型拟合,而XGBoost需要将类别型特征通过one-hot编码、label编码等方式处理为数值型才能使用。在原始类型特征的信息保持度,以及避免特征经one-hot编码转换后生成高维数据等方面,LightGBM比XGBoost更为方便和实用。
(3)LightGBM采用基于梯度的单边采样机制,来减少模型训练样本量并保持数据分布形态不变,从而有效降低模型因数据分布发生变化而造成的模型精度下降幅度,在模型结果准确度方面相比XGBoost有一定优化。
(4)LightGBM优化了特征并行和数据并行的算法过程,此外还添加了投票并行方案,这在算法效率方面明显优于XGBoost。
综上所述,LightGBM在模型精度方面与XGBoost相似或者略高,具体需要结合实际样本数据,但在模型训练的速度效率方面明显优于XGBoost,这也是LightGBM中“light”(轻)的核心意义。
2、建模样本分析
通过以上关于XGBoost与LightGBM算法的原理逻辑对比,下面我们结合具体的样本数据来进行建模实操分析,即根据同一份建模样本数据,分别采用XGBoost与LightGBM算法来训练、评估模型。场景案例的样本数据样例如图1所示,共包含1000条样本与22个特征,其中ID为样本主键,X01X20为特征变量(X03、X06为字符型特征),Y为目标变量,取值二分类1和0,分别代表用户是否流失。本案例的建模场景需求为构建客户流失预测模型,也就是通过特征变量池X01X20,针对目标变量Y进行模型训练。

图1 建模样本数据
针对样本数据特征的分布情况,我们对连续数值型与离散类别型变量分别做简单描述性探索分析,结果分别如图2、3所示。
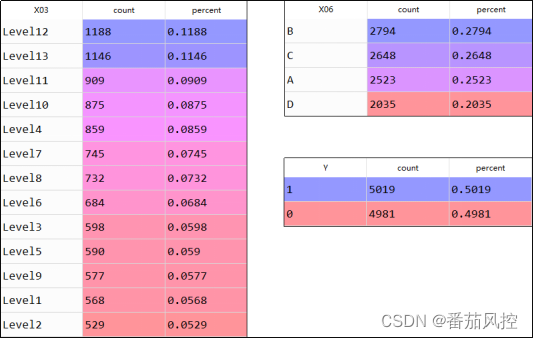
图2 离散型特征分布

图3 连续型特征分布
2、XGBoost模型训练与评估
XGBoost算法在模型训练时不支持字符类别型变量输入,因此需要将样本数据的特征X03与X06进行编码转换,这里采用最常用的one-hot编码方式来处理,实现过程如图4所示,其中特征X03的转换结果如图5所示。

图4 特征one-hot编码过程
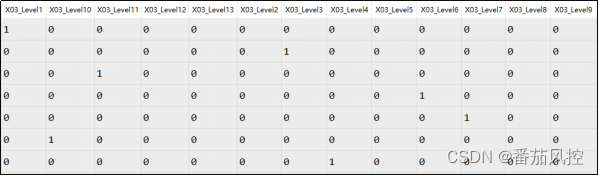
图5 特征one-hot编码结果
现采用XGBoost分类算法来训练模型,为了有效评估模型的学习能力(训练)与泛化能力(预测),将建模样本按照7:3比例拆分为训练样本与测试样本。模型训练实现过程如图6所示,其中XGBoost分类器XGBClassifier()除了参数random_state随机种子指定外(便于数据验证),其余模型参数均保持为默认值(例如树的数量n_estimators=100、树的深度max_depth=6、学习率learning_rate=0.3等)。
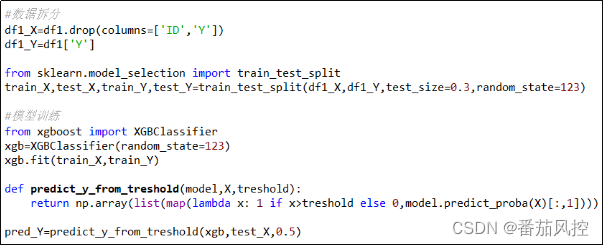
图6 XGBoost模型训练
当模型训练成功后,我们选取分类模型常见重要指标Accuracy、AUC、KS,来评估模型的效果,具体代码如图7所示,输出结果如图8所示。
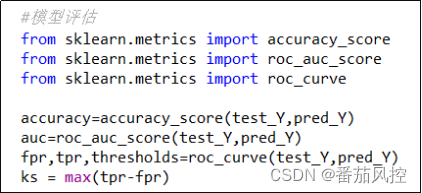
图7 XGBoost模型评估
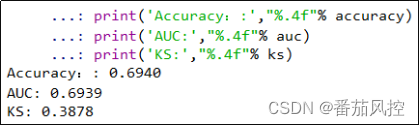
图8 XGBoost模型指标
3、LightGBM模型训练与评估
LightGBM在特征输入方面,与XGBoost最大的不同是可以直接支持字符类别型(category)变量。这里需要注意的是,在样本数据前期导入时,离散字符型特征如果不进行特殊处理时是以object类型储存的,如果直接采用LightGBM算法训练模型,仍然会提示类型错误,因此需要明确的是,LightGBM虽然支持字符型特征输入,但必须是category类型。在样本数据拆分前,我们将字符型特征的格式进行转换,即将object转为category,具体如图9所示。
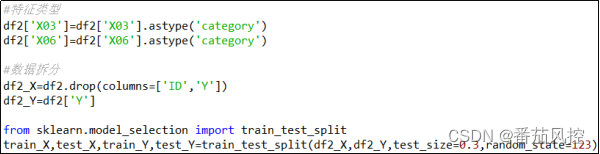
图9 类型转换与数据拆分
接下来采用LightGBM分类算法来训练模型,为了与前边XGBoost分类算法的模型效果进行对比,我们同样对LightGBM模型分类器LGBMClassifier()的参数均保持为默认值(随机种子random_state除外),模型训练过程如图10所示。

图10 LightGBM模型训练
当模型训练成功后,我们同样选取分类模型常见重要指标Accuracy、AUC、KS,来评估模型的效果,具体代码与图7一致,输出结果如图11所示。
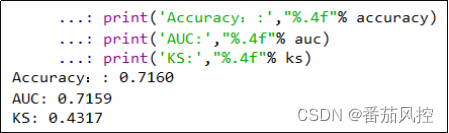
图11 LightGBM模型指标
4、模型性能分析
现将以上XGBoost模型与LightGBM模型在测试集上的性能指标(Accuracy、AUC、KS)结果汇总如图12所示。
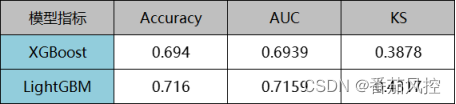
图12 模型指标对比
由以上结果可以看出,针对同一建模样本数据,采用XGBoost与LightGBM算法在保持默认参数的情况下来训练模型,最终的模型性能指标表现是LightGBM比XGBoost相对稍好。当然,这并不是针对所有建模场景,而是在一般情况下,LightGBM可以达到XGBoost的指标性能范围,但是需要特别注意LightGBM模型训练的过拟合程度。此外,LightGBM比XGBoost更为明显的优点在于训练效率很快,这对于样本量较大且特征较多的建模数据场景,LightGBM可以发挥出很大的独特优势。
以上内容便是关于集成学习决策树模型中最常用的两种boosting算法的整体介绍,大家需要明确二者在算法原理逻辑上的主要区别,熟悉在实际业务建模场景中的应用特点。本文围绕具体的A卡建模场景案例,通过必要的特征数据处理,先后采用XGBoost与LightGBM算法实现了模型训练与模型评估,并分析最终模型结果可知,二者都有不错的性能表现。
为了便于大家对XGBoost与LightGBM的进一步熟悉与掌握,我们准备了与本文内容同步的样本数据与ptyhon代码,供大家实操练习,详情请移至知识星球查看相关内容。
…
~原创文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









