







1. 背景
学习深度学习框架Tensorflow的Keras框架进行图像分类,按照网上的教程一步步来,记录要点和总结
2. 要点
1. 准备本地数据集
2. 使用Keras加载本地数据集,分为训练集和测试集,并进行磁盘读取优化
3. 手动创建网络,添加自定义层
4. 针对过拟合的处理
5. 性能调优
总结
本程序的目的是利用tensorflow框架进行图像分类
要点:
1. 本地准备数据集
2. 利用tensorflow tf.keras.utils.image_dataset_from_directory将本地文件生成Dataset对象
3. 利用Dataset.to_numpy()将验证数据集的images和labels转换成numpy数组,以便验证预测的正确性
4. 使用自定义优化器在训练过程中随训练次数降低学习率,防止过拟合
5. 使用数据集中的充分打乱和重复数据,防止过拟合
6. 使用在神经网络中添加数据增强层(随机旋转,随机缩放,随机翻转)防止过拟合
7. 使用在神经网络中添加Dropout层,(目的是在网络的输出中随机丢弃一定比率的数据,防止过拟合
8. 在训练完成后,使用plt生成准确率和损失值的趋势图,方便分析和调整
3.1 准备本地数据集
准备图片目录结构如下
-DataSet
-Daisy
-XXX.jpg
-YYY.jpg
-...
-Sunflowers
-XXX.jpg
-YYY.jpg
...
-...
要点就是文件夹里面放同一类型的图片,文件夹名称就是这些图片的标签
3.2 加载数据集
train_ds = tf.keras.utils.image_dataset_from_directory(
train_data_dir,
seed=123, #将样本打乱的随机数种子
image_size=(image_height, image_width),
batch_size=batch_size #批次大小,受制于系统性能
).shuffle(32) #使用shuffle将图片打乱
# single_data = list(train_ds.as_numpy_iterator())
# label = single_data[0]
val_ds = tf.keras.utils.image_dataset_from_directory(
test_data_dir,
seed=123,
image_size=(image_height, image_width),
batch_size=1
)3.3 手动创建网络,添加自定义层
# 定义一个序贯模型
model = tf.keras.Sequential(
[
# 归一化层,通常用于加速模型的训练并提高其性能 【0~255】 -> 【0~1】
normalization_layer,
# 接下来是三个卷积层,每个卷积层后都接一个ReLU激活函数
tf.keras.layers.Conv2D(
16, 3, activation='relu'),
# 接下来是一个最大池化层,用于降低特征图的尺寸,从而减少计算复杂度
tf.keras.layers.MaxPool2D(),
# 第二个卷积层和最大池化层
tf.keras.layers.Conv2D(
32, 3, activation='relu'),
tf.keras.layers.MaxPool2D(),
# 第三个卷积层和最大池化层
tf.keras.layers.Conv2D(
64, 3, activation='relu'),
tf.keras.layers.MaxPool2D(),
# Flatten层将卷积层的输出拉平,为全连接层做准备
tf.keras.layers.Flatten(),
# 第一个全连接层,128个神经元,激活函数为ReLU
tf.keras.layers.Dense(128, activation='relu'),
# 最后一个全连接层,numclasss个神经元,用于分类任务,不使用激活函数
tf.keras.layers.Dense(numclasss)
)
)4 针对过拟合的处理
上面的网络训练小样本数据集会出现明显的过拟合,验证集的准确率只有大约50%,大约当epoch 大于3的时候就开始出现过拟合,我现在没有结果截图了,有兴趣的可以尝试
4.1 过拟合发生的原因
1. 训练数据集太小或缺乏代表性。如果训练集数据量太小,模型可能会在训练过程中过于拟合训练数据,导致在新的、未见过的数据上表现不佳。同时,如果训练数据缺乏代表性,模型可能无法泛化到所有可能的情况,从而产生过拟合。
2. 训练集样本存在的噪音干扰过大。如果训练样本中存在大量噪声,模型可能会过度关注这些噪声,从而忽略真实的输入输出关系,导致过拟合。
3. 模型复杂度过高。如果所使用的模型复杂度超过训练数据的复杂性,模型可能会过度拟合训练数据,产生过拟合现象。
4. 训练过程中的优化方法不当。例如,如果使用了过于复杂的优化算法(如过多的迭代次数),可能会使模型在训练过程中过于追求最小化损失函数,从而产生过拟合。
5. 验证集和测试集与训练集分布不一致。如果验证集和测试集的数据分布与训练集的数据分布相差太大,那么模型在这些数据集上的表现可能不佳,导致过拟合。
6. 数据集中的类别不平衡。如果数据集中某些类别的样本数量远大于其他类别,模型可能会过度关注数量较多的类别,从而忽略数量较少的类别,导致过拟合。
7. 特征选择不当。如果所选特征与预测目标无关或相关性不大,那么模型在这些特征上的学习就可能是无效的,甚至可能导致过拟合。
8. 超参数调整不当。模型的超参数如学习率、批次大小、正则化参数等调整不当,也可能导致过拟合。
4.2 减少过拟合的方法
为了防止过拟合,可以采取以下措施:
1. 增加训练数据集的数量和多样性,使其更具代表性。
对训练数据进行预处理,如去噪、归一化等,以减少噪声对模型的影响。
2. 选择合适的模型复杂度,避免过于复杂的模型。
3. 选择合适的优化算法和参数,避免过度优化。
4. 验证集和测试集应该与训练集保持一致的数据分布。
5. 对于类别不平衡的数据集,可以采用重采样、生成合成样本等方法来平衡类别分布。
6. 选择与预测目标高度相关的特征,并删除无关或相关性不大的特征。
7. 调整超参数以优化模型的性能,例如通过交叉验证等方法来寻找最佳的超参数组合。
4.3 代码调整
1. 逐渐降低的学习率
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=500,
decay_rate=1,
staircase=False)
'''
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(: 这一行代码是创建了一个名为InverseTimeDecay的学习率调度器实例,这个实例被赋值给了变量lr_schedule。这个调度器在Tensorflow的优化器库中定义。
0.001: 这是初始学习率,即在开始训练时使用的学习率。
decay_steps=500: 这是指在训练过程中,学习率会在每500步进行一次衰减。
decay_rate=1: 这是指学习率的衰减比例。一个衰减率值为1的学习率调度器意味着学习率会在每个decay_steps步长后减半。
staircase=False: 这表示当进行学习率衰减时,不是按照阶梯式(staircase)方式进行,而是连续平滑地衰减。
'''这段代码是用来创建一个学习率调度器(Learning Rate Scheduler)的,该调度器使用了一种叫做"Inverse Time Decay"的策略。这种策略基本上是说,随着时间的推移,学习率会以一种倒数的方式进行衰减。在实践中,这种学习率调度器通常用于深度学习模型训练中,因为随着训练的进行,模型可能会逐渐适应训练数据,因此需要逐渐降低学习率以避免过拟合。通过这种方式,可以在训练初期使用较高的学习率进行模型训练,然后在训练过程中逐渐降低学习率,从而使得模型能够在保持良好泛化性能的同时,更好地优化模型参数。
2. 降低卷积核过高的权重
将上面的网络定义修改如下
# 定义一个序贯模型
model = tf.keras.Sequential(
[
# 归一化层,通常用于加速模型的训练并提高其性能
normalization_layer,
# 接下来是三个卷积层,每个卷积层后都接一个ReLU激活函数和L2正则化,用于防止过拟合
tf.keras.layers.Conv2D(
16, 3, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
# 接下来是一个最大池化层,用于降低特征图的尺寸,从而减少计算复杂度
tf.keras.layers.MaxPool2D(),
# 第二个卷积层和最大池化层
tf.keras.layers.Conv2D(
32, 3, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.MaxPool2D(),
# 第三个卷积层和最大池化层
tf.keras.layers.Conv2D(
64, 3, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.MaxPool2D(),
# 接下来是一个Dropout层,用于防止过拟合,随机丢弃一部分神经元
tf.keras.layers.Dropout(0.2),
# Flatten层将卷积层的输出拉平,为全连接层做准备
tf.keras.layers.Flatten(),
# 第一个全连接层,128个神经元,激活函数为ReLU
tf.keras.layers.Dense(128, activation='relu'),
# 最后一个全连接层,numclasss个神经元,用于分类任务,不使用激活函数
tf.keras.layers.Dense(numclasss)
)
)注意,和上面网络的不同点:
kernel_regularizer=tf.keras.regularizers.l2(0.001):这是正则化项,用于控制模型的复杂性以防止过拟合。L2正则化是最常见的正则化方法之一,它通过对卷积核的权重进行惩罚来减少模型的复杂度。这里的参数0.001是 L2 正则化的系数。
3. 数据增强
data_augmentation = tf.keras.Sequential(
[
tf.keras.layers.RandomFlip(
'horizontal', input_shape=(image_height, image_width, 3)),
tf.keras.layers.RandomRotation(0.1),
tf.keras.layers.RandomZoom(0.1)
]
)
'''
tf.keras.Sequential( [...] ):这是创建一个顺序模型(Sequential model)的语句,该模型将按照定义的顺序执行一系列层。
tf.keras.layers.RandomFlip( 'horizontal', input_shape=(image_height, image_width, 3) ):这是一个随机水平翻转层。它将输入图像(预期为彩色图像,具有高度image_height、宽度image_width和3个颜色通道)沿水平方向翻转。这种翻转是随机的,也就是说,翻转操作在每次前向传播时都有可能发生。
tf.keras.layers.RandomRotation(0.1):这是一个随机旋转层。它将输入图像(保持与前面相同的形状)旋转一个随机的角度,角度范围为-0.1到+0.1弧度(约合10度)。这意味着每次前向传播时,图像都可能以不同的角度旋转。
tf.keras.layers.RandomZoom(0.1):这是一个随机缩放层。它将输入图像(保持与前面相同的形状)随机缩放,缩放因子在0.9到1.1之间变化。这意味着每次前向传播时,图像都可能以不同的缩放比例进行缩放。
'''这段代码是使用 TensorFlow 和 Keras 创建的一个数据增强(Data Augmentation)模块。数据增强是一种技术,通过在训练数据周围添加一些小的变化(或扰动)来扩展数据集,从而增加模型的泛化能力。这种方法可以帮助模型更好地理解输入数据的各种变化,并提高其预测的准确性。
然后将数据增强层插入到网络的最前面
# 定义一个序贯模型
model = tf.keras.Sequential(
# 列表中的第一个元素是数据增强层,通常用于提高模型的泛化能力
[
data_augmentation,
# 列表中的第二个元素是归一化层,通常用于加速模型的训练并提高其性能
normalization_layer,
# 接下来是三个卷积层,每个卷积层后都接一个ReLU激活函数和L2正则化,用于防止过拟合
tf.keras.layers.Conv2D(
16, 3, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
...最后,看看结果吧
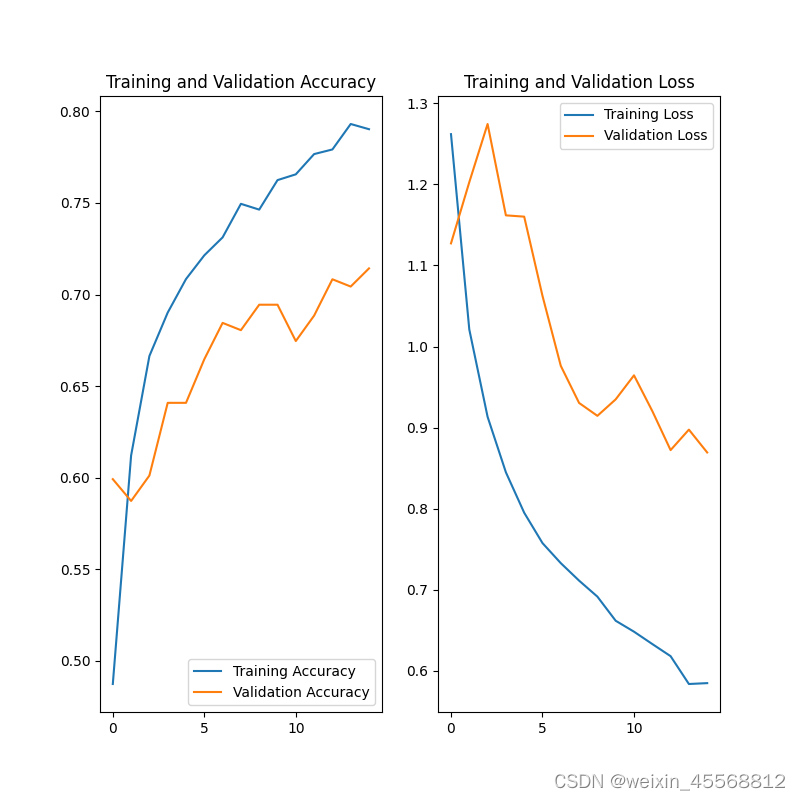
可以看到,当训练轮次达到15轮时,训练还没有发生过拟合(通常表现为”Traning Accuracy“继续提高,但是"Validation Accuracy"停滞不前或开始下降,同时Validation的loss开始上升),而且准确率达到了70%以上

















 157
157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









