







一、Kafka数据写入流程
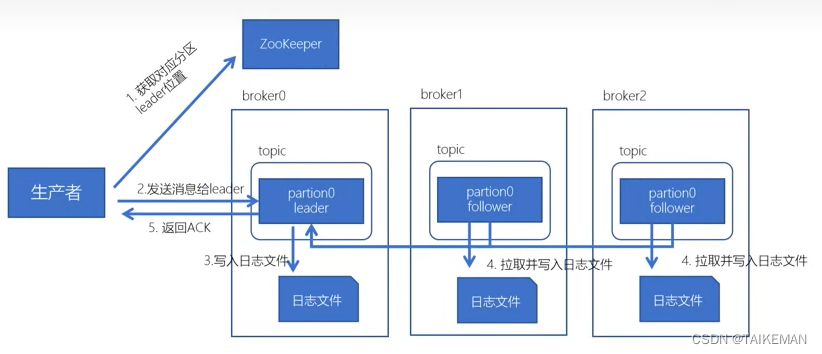
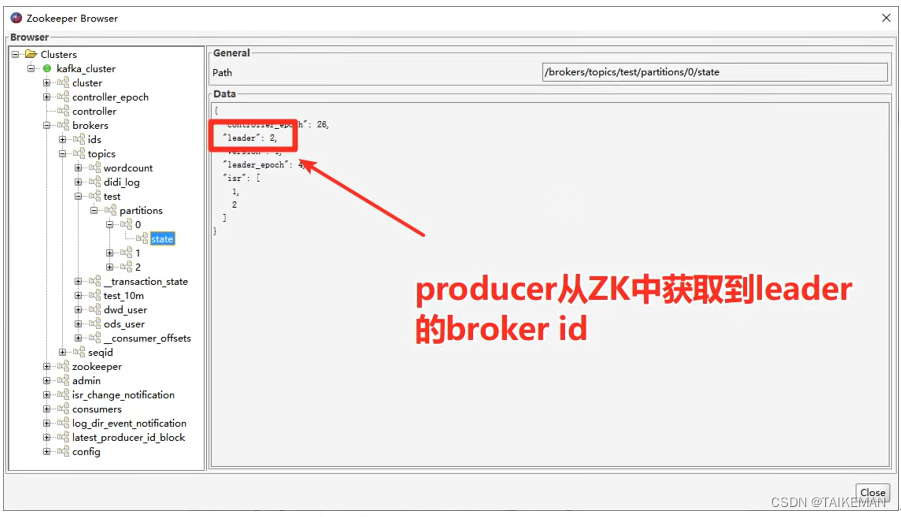
- 获取对应分区leader的位置:生产者先从zookeeper的“/brokers/topics/主题名称/partitions/分区名称/state”节点找到该分区的leader位置
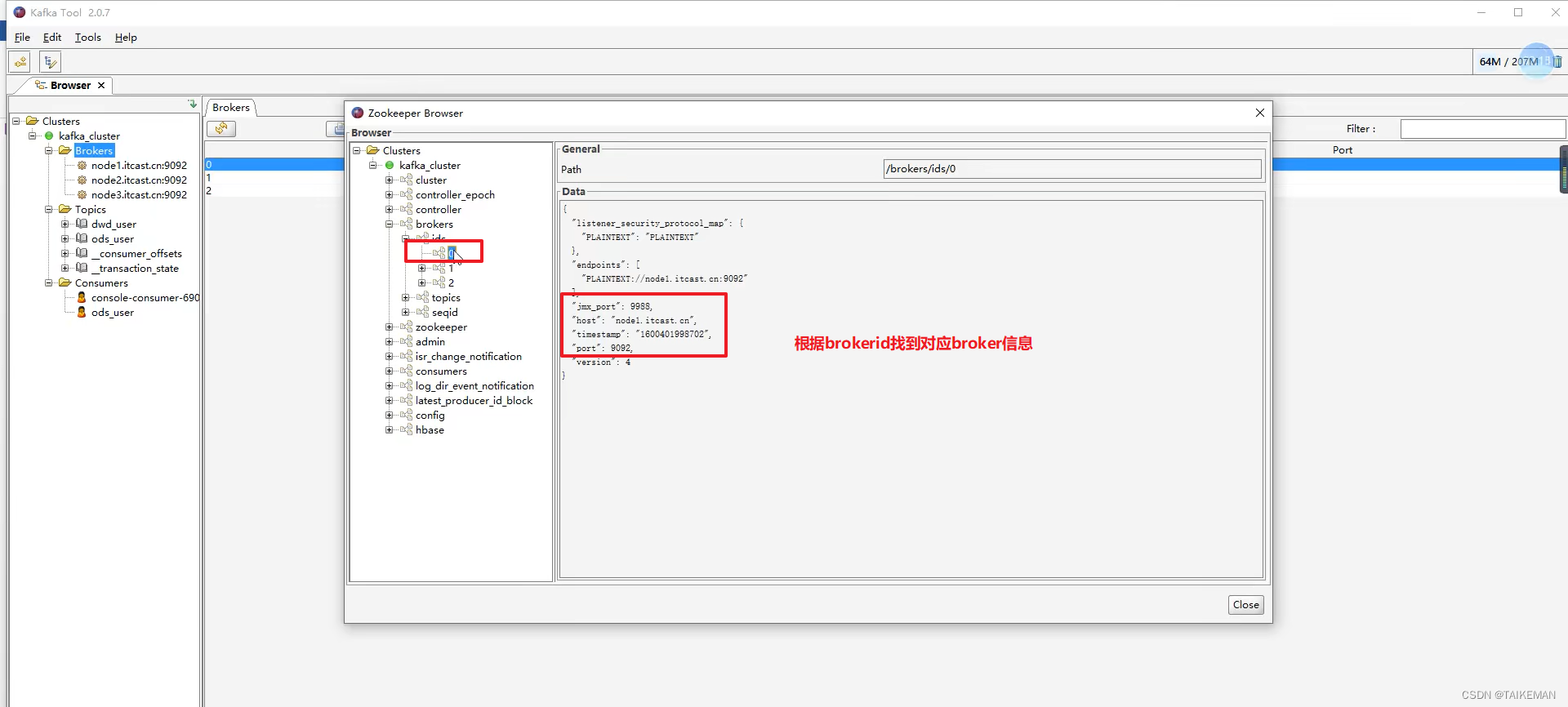
- 获取对应的broker信息:生产者在zookeeper中找到该id对应的broker
- broker进程上的leader将消息写入到本地log中
- follower从leader上拉取消息,写入本地log,并向leader发送ack
- leader接收到所有的ISR中的replica的ack后,并向生产者返回ack
二、Kafka数据消费流程
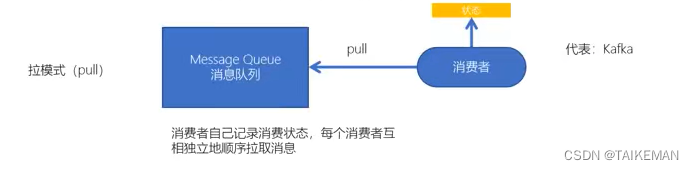
- Kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地、有顺序地拉取每个分区的消息
- 消费者可以按照任意的顺序消费消息。比如:消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费

- 每个消费者都可以根据分配策略(默认:RangeAssignor),获取消费的分区
- 获取到消费者对应的offset(默认从zk中获取上一次消费的offset)
- 找到该分区的leader,拉取数据
- 消费者提交offset
三、小结
















 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









