






在一套完整的自动驾驶系统中,如果将感知模块比作人的眼睛和耳朵,那么决策规划就是自动驾驶的大脑。大脑在接收到传感器的各种感知信息之后,对当前环境作出分析,然后对底层控制模块下达指令,这一过程就是决策规划模块的主要任务。同时,决策规划模块可以处理多么复杂的场景,也是衡量和评价自动驾驶能力最核心的指标之一。下图第一行功能模块便是自动驾驶中决策与规控部分。
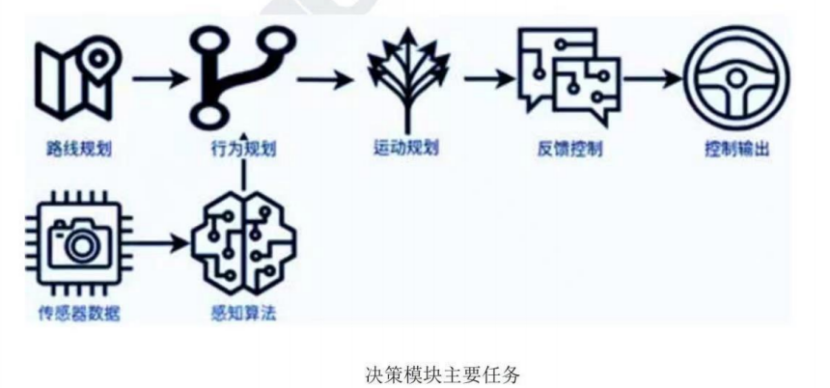
车辆的决策以横纵向驾驶行为可分为:驾驶行为推理问题,如停车、避让和车道保持等;速度决策问题,如加速、减速或保持速度等。也可根据车辆驾驶行为将问题分为车辆控制行为、基本行车行为、基本交通行为高级行车行为、高级交通行为。
而实现自动驾驶关键在于车辆的行为决策是否合理可行。如何综合车辆运行环境及车辆信息,结合行驶目的做出具有安全性可靠性以及合理性的驾驶行为是决策控制的难点亦是实现自动驾驶的难点。
应对环境多变性检测不准确性交通复杂性交规约束性等诸多车辆行驶不利因素,如何降低或消除其产生的不利影响是行为决策模块的研究重点。此前已有研究人员提出了许多应对不同环境的决策方法,可分为基于规则的行为决策方法和基于统计的行为决策方法。但其中仍有许多亟待解决的问题。这里分别对两种方法中应用较广的模型及基于有限状态机模型和深度强化学习模型的自动驾驶决策方法进行探讨,对其适用性可靠性及实现原理进行对比分析。提出行为决策方法的发展趋势,为自动驾驶车辆行为决策方法的研究提供参考。
(1)基于有限状态机的行为决策模型
有限状态机模型作为经典的智能车辆驾驶行为决策方法,因其结构简单、控制逻辑清晰,多应用于园区港口等封闭场景。在这些封闭场景中道路具有固定的路线和节点,因此可预先设计行驶规则。这种预先设计行驶规则的方法将特定场景的车辆决策描述为离散事件,在不同场景通过不同事件触发相应的驾驶行为。这种基于事件响应的模型称为有限状杰机决策模型。有限状态机(ESMFinite-State Machine是对特定目标在有限个状态中由特定事件触发使状杰相互转移并执行相应动作的数学模型。已经被广泛应用在特定场景无人驾驶车辆、机器人系统等领域。车辆根据当前环境选择合适的驾驶行为,如停车、换道超车避让、缓慢行驶等模式,状态机模型通过构建有限的有向连通图来描述不同的驾驶状态以及状态之间的转移关系,从而根据驾驶状态的迁移反应式地生成驾驶动作。
下图为有限状态机模型在车辆决策中的应用Junior车队在2007年的DAPRA比赛中使用并联结构有限状态机模型实现了包括初始状态车道跟随等多种行驶状态的相互切换。
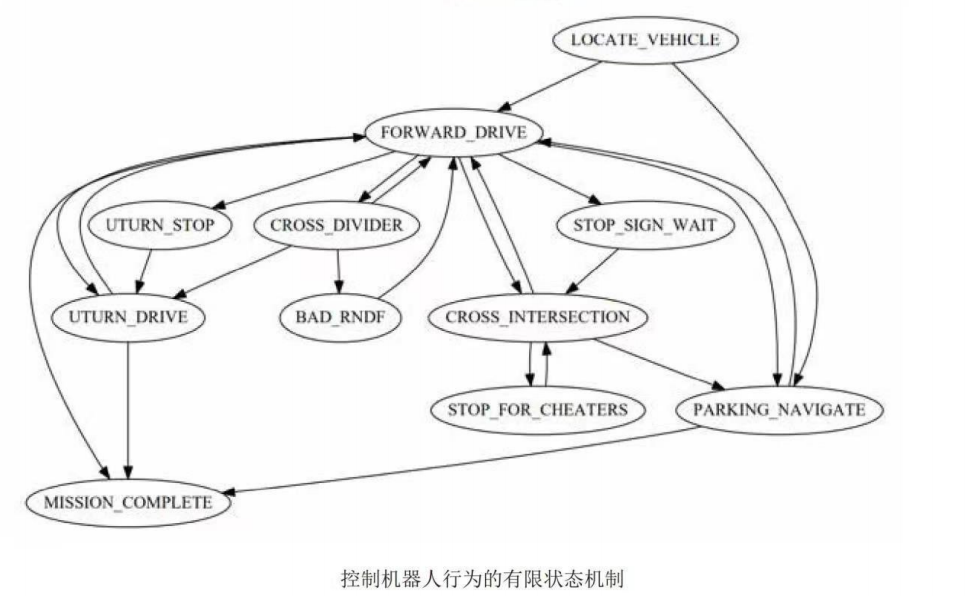
之后还发展出决策树等模型,和状态机模型类似,也是通过当前驾驶状态的属性值反应式地选择不同的驾驶动作,但不同的是该类模型将驾驶状态和控制逻辑固化到了树形结构中,通过自顶向下的“轮询机制进行驾驶策略搜索。总的来说基于状态机模型及其拓展模型的决策系统其结构相对简单、框架清晰应用较为广泛,是无人驾驶领域目前最广泛的行为决策模型。但是当智能车辆行驶环境比较复杂时,其状态集和输入集大量增加,结构变得复杂且场景划分比较困难。因此此方法适用于简单场景时具有较高可靠性,很难胜任具有丰富结构化特征的城区道路环境下的行为决策任务。
(2)基于深度强化学习的行为决策模型
人工智能自诞生以来经过六十多年的发展,已经成为一门具有日臻完善的理论基础、日益广泛的应用领域的交叉学科。近年来,对深度强化学习算法的进一步认识和挖掘,是人工智能实现应用的重要研究方向。深度强化学习技术方法越来越广泛的应用于智能车辆的环境感知与决策系统。
深度学习(DeepLearningDL)作为机器学习研究方向之一,发展令人感到惊喜和意外,深度学习在图像处理语音识别自然语言处理和视频分析分类等方面的应用取得了巨大的成功。所谓深度学习是指通过多层的神经网络和多种非线性变换函数,以组合低层特征的方式描述更加抽象的高层表示,这样便可以发现数据的分布式特征,因此深度学习是来源于人们对于人工神经网络的深入研究。人们在日常生活,学习等各种活动中每时每刻都需要感知大量数据。但是人类总是能从这些庞大的数据中以一种无法解释的方式获得有用的数据,这种方式正是人脑思维方式导致的,并且脑力思维至今为止还没有一种科学的方法来解释。
强化学习的主要特点是通过自我试错来获得能力,谷歌团队DeepMind提出的深度强化学习(Deep Reinforcement LearningDRL)是结合深度学习的“感知能力”和强化学习的“决策能力",从而成为人工智能领域的重要研究方向之一。
深度强化学习是一种端到端的系统,端到端是指这个整个系统直接从感知到控制,并且深度强化学习中的智能体在强化学习大框架下并不需要人类专家经验,也不需要人工编码,智能体全部依靠自身学习和环境交互信号,智能体通过深度强化学习可以实现多方智能化学习,为复杂驾驶场景的感知决策问题提供解决方案。
深度强化学习的学习过程为:
1)智能体从环境中观测到高维观测测状态,并利用深度学习识别观测信息的特征:2)通过设定的回报函数评估状态-动作值函数,并把当前策略反馈到环境中去;
3)随动作变化而导致智能体与环境交互得到的观测信息发生变化,进入三者的循环最终得出目标的最优策略。
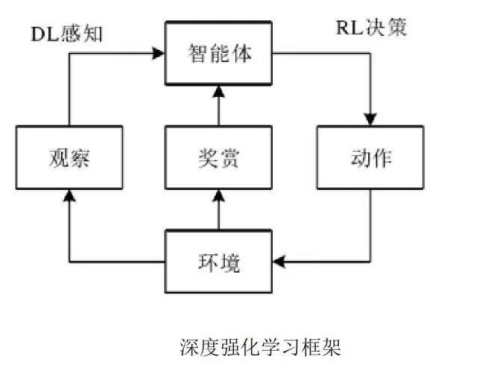
深度强化学习与强化学习的过程上基本一致,只是对于从环境中获得的观测状态更高维,和对状态进行处理的方式不一样。
基于深度学习的方法通常需要大量人工标记的数据来训练模型,再以此深度网络实现自动驾驶决策对于车辆这个动态对象来说这是不现实的。而基于强化学习的方法则具有一定的自主决策能力,符合车辆行驶的动态特性。但强化学习方法是将所有的状态-动作映射的评价值储存为一个列表,这对于车辆的复杂工况很难实现,因此基于强化学习的自动驾驶决策算法没有广泛应用。
本文节选自中国汽车基础软件生态委员会(AUTOSEMO)本月发中国汽车基础软件发展白皮书2.0》,如需获得完整报告,请下载。资料下载链接:https://pan.baidu.com/s/1rOTeFu4oJVRNjIzTcIOaVQ 提取码:d72b
原文链接:https://bbs.z-onesoft.com/omp/community/front/api/page/mainTz?articleId=7589

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









