







本文刊载于《大数据》2024年第5期“战略研究”
郑纬民
中国工程院院士,清华大学计算机科学与技术系教授,中国计算机学会第十届理事长,数博会专家咨询委员会委员,何梁何利科学与技术进步奖获得者,中国存储终身成就奖获得者,享受国务院政府特殊津贴,《大数据》主编。获北京市优秀教师奖和北京市教学名师称号,获国家科技进步奖一等奖1项、二等奖2项,国家技术发明奖二等奖1项,2016年获ACM戈登·贝尔奖。2019年当选中国工程院院士。主要研究方向为网络存储系统,长期从事网络存储系统科学研究、工程建设和人才培养,在存储系统扩展性、可靠性和集约性等科学问题和工程技术方面,取得了国内外同行认可的创新性成果;研制的网络存储系统、容灾系统和自维护存储系统在多个重大工程中发挥了重要作用。教学方面长期讲授计算机系统结构课程,2008年被评为国家级精品课程;已编写和出版计算机系统结构教材和专著10本,与合作者一起发表论文530余篇。
doi: 10/11959/j.issn.2096-0271.2024056
郑纬民. 分布式技术在大模型训练和推理中的应用[J]. 大数据, 2024, 10(5): 1-10.


大模型与分布式技术


近几年,人工智能被广泛应用于多个领域,例如具身智能、自动驾驶、公共安全、科学计算等。人工智能经历了符号学习、统计 学习、深度学习的阶段,如今进入大模型时代。大模型的“预训练-微调”成为人工智能的最新范式,基础模型支持众多领域任务。大模型包含4个环节,分别是数据获取、数据预处理、模型训练、模型推理,每个环节都与分布式技术紧密相关。
01
在数据获取环节,需要获取并存储不同类型的原始数据,海量小文件的存储对文件系统提出了新的要求。
在数据预处理环节,需要对抓取的海量数据进行删冗等预处理,而海量数据处理对底层大数据处理框架来说是一个新的挑战。
02
03
在模型训练环节,模型训练任务负载重,硬件出错概率高,需要检查点操作,如何解决大模型检查点文件的读写问题是存储系统的一个难点。
在模型推理环节,需要加载庞大的模型参数以及保存中间结果,这是存储系统需要解决的问题。
04


01
数/据/获/取
大模型训练需要收集海量多模态数据,这些数据呈现两个特点:
多模态,数据的类型包括文本、图像、音频、视频等;
小文件非常多,任一模态的数据集包含数亿甚至数百亿个小文件。
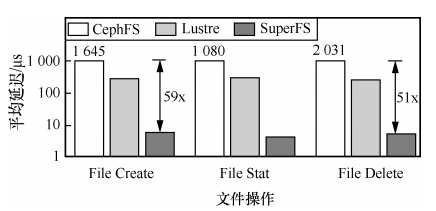
小文件的数量越多,元数据的管理就越困难。存储100亿的小文件需要管理7 TB的元数据。海量小文件的元数据处理时间长,这就要求文件系统一方面扩展性要好,另一方面读取速度要快。
清华大学计算机科学与技术系高性能计算研究所自主研发了高性能文件系统SuperFS。SuperFS采取解耦合的目录树存储策略,即解耦目录元数据和文件元数据,能够同时满足低延迟要求和可扩展要求。
实验结果表明,相比CephFS和Lustre文件系统,SuperFS的延迟能降低为现有文件系统的1/60~1/52。

02
数/据/预/处/理
据谷歌数据中心统计,30%的训练时间用于数据预处理。数据预处理需要先从分布式文件系统读取数据,然后再处理数据,开销非常大。已有的方法通常以计算为中心,将需要处理的数据转移到进行计算任务的节点,但是待处理的数据可能分散在多个节点上, 读取远端节点的数据会引入极大的网络开销。
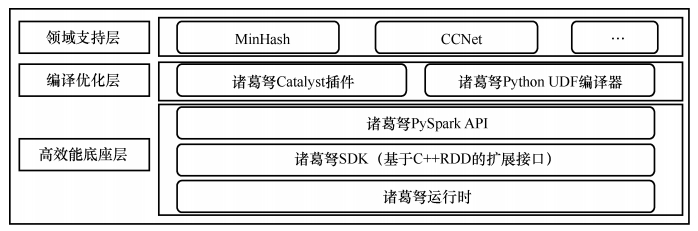
“诸葛弩” (Chukonu)是清华大学高性能计算研究所自主研发的高性能计算引擎,应用了以数据为中心的理念,即将计算任务动态地调度到所需数据所在的节点上,从分布式系统读取数据转换为从本地文件系统读取数据。“诸葛弩”在大数据处理方面表现优异,其架构如下图所示。

03
模/型/训/练
大模型检查点文件的读写对存储系统来说是一个新的挑战。以神威平台10万卡规模万亿参数量检查点的读写为例,默认策略是在每个专家的0号进程上写数据。
单超节点写,容易出现负载不均的问题,所需时间超过10 h;
跨超节点写,其进程数少,所需时间为3 h左右。
由以上两个方案可知,默认读写策略性能差有两个原因,一是进程数不足,无法充分利用网络链路带宽;二是负载不均,即进程分布不均匀,无法利用所有交换机资源。
针对以上问题,提出分布式检查点策略,即数据均匀分布在所有参与并行计算的节点上。
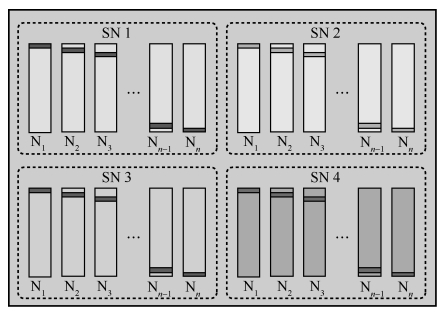
为适应神威平台的存储架构特点,分布式检查点策略进行了如下调整。采用分布式检查点策略,10万亿参数量模型的检查点读写只需花费10 min左右。

调整

每个节点只需要写自己分配的一部分数据;
在每个超节点交换机上有足够的I/O进程数;
不同超节点的I/O请求被均匀划分。

04
模/型/推/理
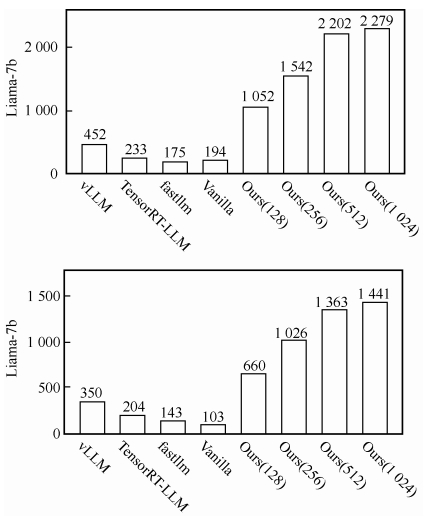
在模型推理过程中,需要在推理卡上存储模型参数以及模型推理的中间结果KVCache。复用KVCache将极大地节省算力, 是大模型推理优化的关键。以万亿模型为例,模型大小为2 TB,需26个GPU存储参数,但KVCache大小为7 TB,需要86个GPU存储。
针对上述问题,提出了一种高吞吐推理方案FastDecode。FastDecode有两个显著优势,一是batch size不再受到KVCache显存占用限制,GPU利用率显著提升;二是聚合存储带宽高,KVCache处理吞吐量提升,成本降低。实验结果表明,相比广泛使用的大模型推理系统vLLM等,在使用单GPU进行推理时,FastDecode可将KVCache的可用存储容量提升100倍以上,大模型推理GPU吞吐量提升1.8~14倍。
Mooncake
Mooncake是以KVCache为中心的大模型推理架构。国产大模型Kimi使用的就是Mooncake推理架构,Kimi的底层推理架构承载其80%以上的流量。
Mooncake通过以存换算,将Kimi的吞吐量提升了75%以上,并采用以超大规模分离式内存池为中心的KVCache缓存和调度,强调用户体验优先,面向过载场景进行调度。

结束语
基于“预训练-微调”的大模型技术成为当前人工智能领域的典型范式。分布式技术被广泛应用于大模型的整个生命周期(即数据获取、数据预处理、模型训练、模型推理),是大模型发展的关键技术之一。本文总结了大模型生命周期每个环节面临的主要系统挑战,并针对这些挑战,提出一些初步的解决思路和方案,希望给大模型的发展和应用提供一定的参考。
联系我们:
Tel:010-53879208
010-53859533
E-mail:bdr@bjxintong.com.cn
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
转载、合作:010-53878078
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中国科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,以及信息通信领域高质量科技期刊分级目录、计算领域高质量科技期刊分级目录,并多次被评为国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。

关注《大数据》期刊微信公众号,获取更多内容

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









