






在当今数字化时代,自然语言处理(NLP)技术已经被广泛应用于金融领域,帮助用户更便捷地获取信息。今天,我们将通过一个实战项目,介绍如何利用 LangGraph Agent 实现股票信息的自然语言查询。我们将从股票信息的获取、工具的设计,到最终的代码实现,一步步展开。
一、股票信息的获取
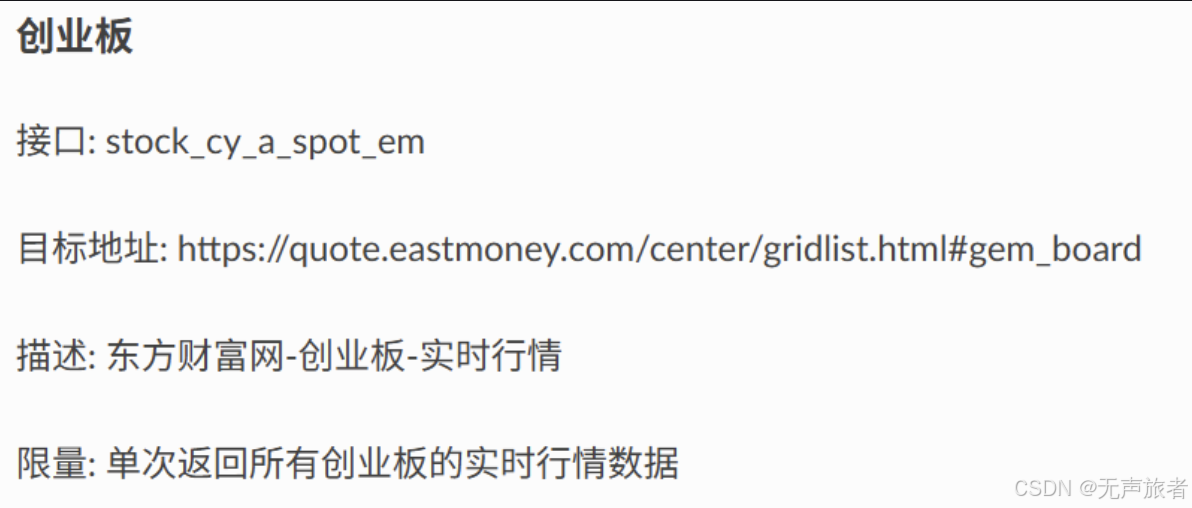
在金融领域,获取实时股票信息是开发相关应用的基础。我们可以通过调用第三方数据接口来实现这一目标。在本实战中,我们选择了东方财富网提供的接口,用于获取创业板的实时股票数据。
1.1 数据接口介绍
东方财富网提供了丰富的股票数据接口,其中 stock_cy_a_spot_em 接口可以抓取创业板的实时数据。通过调用该接口,我们可以获取包括股票代码、名称、当前价格、涨跌幅等在内的详细信息。以下是接口返回的数据示例:
| 字段 | 说明 |
|---|---|
| 代码 | 股票代码 |
| 名称 | 股票代码 |
| 当前价格 | 实时价格 |
| 涨跌幅 | 涨跌幅度 |
| 成交量 | 当日成交量 |
| 成交额 | 当日成交额 |
1.2 数据获取代码
为了获取数据,我们需要使用 Python 的 akshare 库。以下是获取创业板实时数据的代码:
import akshare as ak
def get_stock_data():
# 调用东方财富网接口获取创业板实时数据
data = ak.stock_cy_a_spot_em()
return data
运行上述代码后, data 将是一个包含实时股票信息的 DataFrame,如下图所示:
二、股票信息查询工具的设计
获取到股票数据后,我们需要设计一个工具,用于根据用户输入的股票代码或名称查询相关信息。这个工具将作为 LangGraph Agent 的一部分,实现自然语言查询的功能。
2.1 工具设计思路
我们的工具需要实现以下功能:
- 接收用户输入的股票代码或名称。
- 在获取到的股票数据中筛选匹配的记录。
- 返回查询结果。
2.2 查询工具代码实现
以下是查询工具的代码实现:
from langchain_core.tools import tool
from llm import DeepSeek
@tool
def get_stock_info(code: str, name: str) -> str:
"""
根据传入的股票代码或股票名称获取股票信息
Args:
code: 股票代码
name: 股票名称
"""
# 检查输入是否为空或过短
code_is_empty = (code == "" or len(code) <= 2)
name_is_empty = (name == "" or len(name) <= 2)
if code_is_empty and name_is_empty:
return []
# 获取创业板实时数据
df = ak.stock_cy_a_spot_em()
# 根据输入条件筛选数据
if code_is_empty and not name_is_empty:
ret = df[df['名称'].str.contains(name)]
elif not code_is_empty and name_is_empty:
ret = df[df['代码'].str.contains(code)]
else:
ret = df[df['代码'].str.contains(code) & df['名称'].str.contains(name)]
# 返回查询结果
return ret.to_dict(orient='records')
2.3 查询工具的使用示例
假设用户输入股票代码“300059”或股票名称“东方财富”,调用 get_stock_info 函数后,将返回匹配的股票信息
三、LangGraph Agent 的实现
LangGraph Agent 是一个强大的自然语言处理框架,可以将普通方法转换为工具方法,并绑定到大模型中。通过 LangGraph Agent,我们可以实现自然语言查询股票信息的功能。
3.1 工具方法的绑定
我们将 get_stock_info 函数转换为工具方法,并绑定到 LangGraph Agent 中。以下是绑定代码:
from langchain_core.tools import tool
from llm import DeepSeek
# 绑定工具方法
agent = DeepSeek()
agent.bind_tool(get_stock_info)
3.2 查询流程设计
在 LangGraph Agent 中,我们需要设计查询流程,包括大模型选择工具和执行工具的节点。以下是查询流程的代码实现:
def query_stock_info(user_input: str):
"""
根据用户输入的自然语言查询股票信息
Args:
user_input: 用户输入的自然语言
"""
# 大模型解析用户输入
parsed_input = agent.parse(user_input)
# 根据解析结果选择工具
if "股票代码" in parsed_input:
code = parsed_input["股票代码"]
result = agent.run_tool("get_stock_info", code=code, name="")
elif "股票名称" in parsed_input:
name = parsed_input["股票名称"]
result = agent.run_tool("get_stock_info", code="", name=name)
else:
result = "无法识别的输入"
return result
3.3 测试查询流程
假设用户输入“查询股票代码为 300059 的股票信息”,调用 query_stock_info 函数后,LangGraph Agent 将解析用户输入,调用 get_stock_info 工具方法,并返回查询结果。以下是测试代码:
user_input = "查询股票代码为 300059 的股票信息"
result = query_stock_info(user_input)
print(result)
四、总结
通过本实战项目,我们介绍了如何利用 LangGraph Agent 实现股票信息的自然语言查询。我们从股票数据的获取、查询工具的设计,到 LangGraph Agent 的实现,一步步完成了整个流程。希望本文能帮助你更好地理解和应用自然语言处理技术。
往期回顾
如何抓取金融市场数据:使用AKShare进行股票数据抓取
使用LangGraph定制编写Web后端项目:以生成Golang代码为例
API文档教程

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









