







论文链接:https://arxiv.org/pdf/1909.12605.pdf
代码链接:https://github.com/Zhongdao/Towards-Realtime-MOT
文章目录
一、实验环境搭建
1. 从github网址下载项目,打开README.md文件
git clone https://github.com/Zhongdao/Towards-Realtime-MOT
2. 基本环境安装
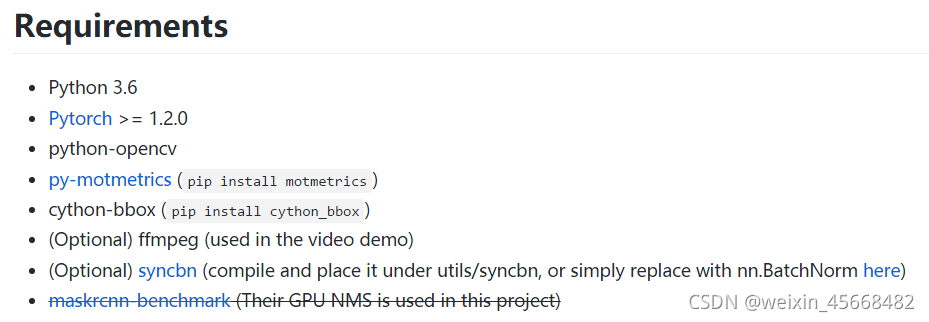
实验环境啥的自行安装,pytorch从官网找,注意与cuda版本对应,其他的一路傻瓜式安装就行,大不了运行时缺啥装啥。ffmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,可以从这里安装。在window下可以直接从网上复制静态文件。
3. 下载权重文件
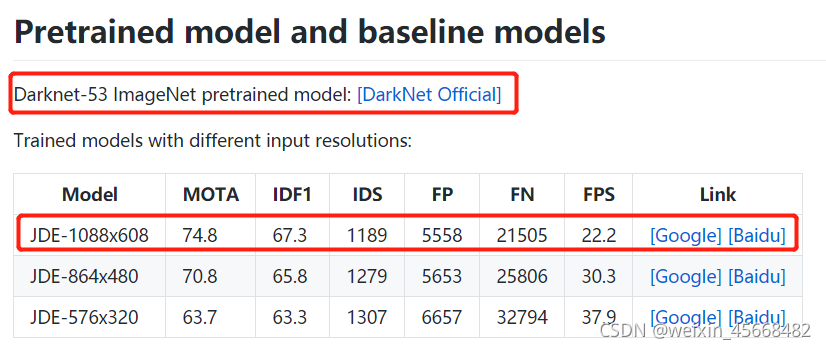
在根项目下新建weights文件夹,将这两个模型放入其中

4. 修改demo.py
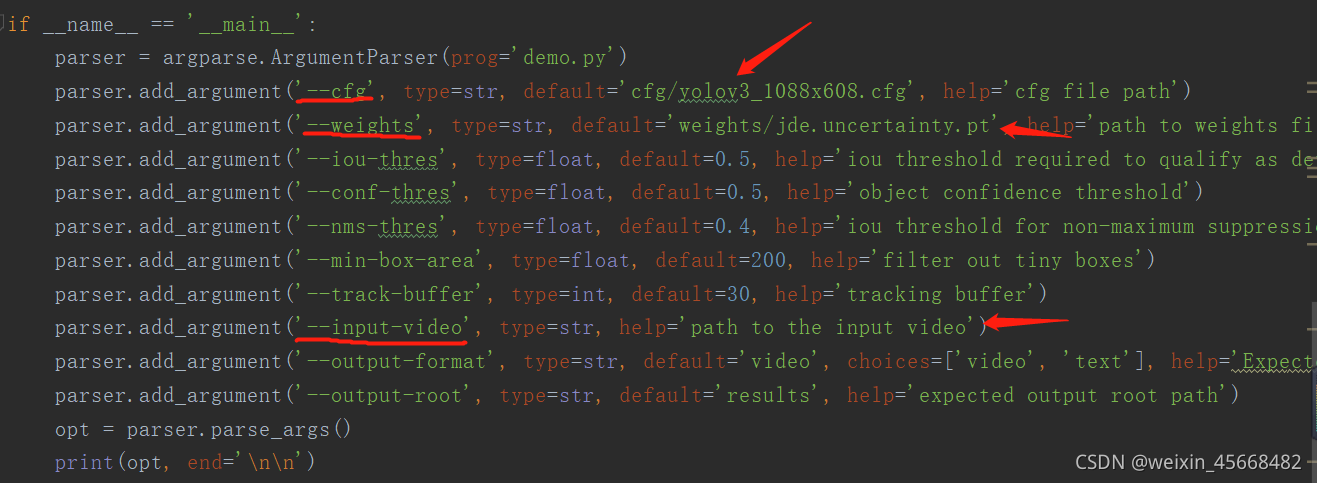
cfg可以自行选择,weights放置权重文件,input-video可以指定检测视频。
大概60行处修改ffmpeg命令:
if opt.output_format == 'video':
output_video_path = osp.join(result_root, 'result.mp4')
cmd_str = 'ffmpeg -f image2 -i {}/%05d.jpg -vcodec libx264 -r 25 {}'.format(osp.join(result_root, 'frame'), output_video_path)
os.system(cmd_str)
5. 运行demo.py文件
视频demo自行准备,以我这里的路径为例:
运行下面命令(注意路径)
python demo.py --input-video path/to/your/input/p7.mp4--output-root path/to/output/root
这里看不了视频,就贴上某一帧吧

运行时出现下面代码就成功了:
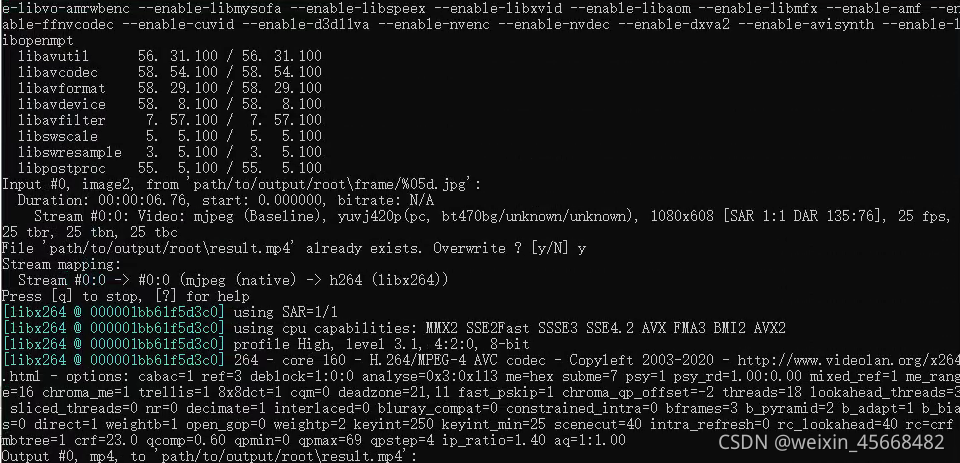
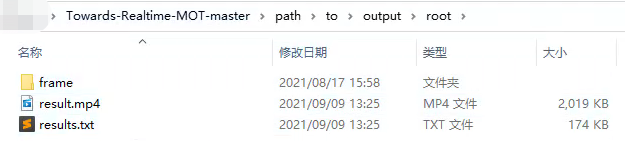
最后的demo结果保存在 根目录/path/to/output/root/下,视频结果为result.mp4
二、环境搭建时容易出现的问题
1. pip install cython_bbox报错
这种一般都是编译问题,需要注意自己的vs环境。这里可以参考这篇文章Window环境下复现 MOT《Towards Real-Time Multi-Object Tracking》代码
2. ffmpeg问题
从这里下载静态文件

直接解压到软件文件夹中就行了,我这里放在D盘的Program Files中,这是我专门放软件的地方。
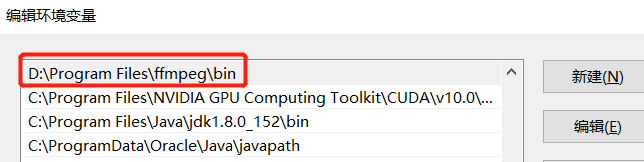
此时系统肯定还是无法识别ffmpeg的,需要配置环境变量
打开cmd输入ffmpeg命令就可以了
注意运行demo.py时最好以命令行的方式进行,不然可能会报ffmpeg的错误。
三、实验复现
1. 准备数据集
这个算法的数据格式比较特殊,我们需要从官网上了解。
一般github项目中作者都会说明数据集的格式,我们可以找到DATASET_ZOO.md这个文件。

上图是该算法的数据集目录结构。Caltech代表放置数据集的目录,下面包括图像集和标签集。注意labels_with_ids不能写错,因为作者在代码中已经将这标签文件夹名称写死在了代码中。
我们可以这样做:
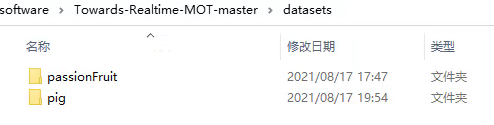
在项目根目录下新建一个datasets文件夹,我打算跑百香果和猪的模型,因此我分为了百香果数据集和猪数据集。
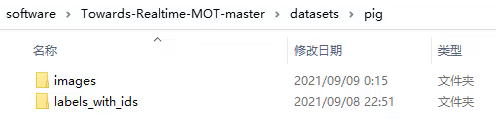
以猪数据集为例,分为图像集和标签集(注意标签文件夹名称一定不能写错),这也是我们上面讲述的数据目录。
images文件夹内容如下:

labels_with_ids文件夹内容如下:
txt文件内容样式如下:

class:表示目标的类别,比如人、车、猫等。如果只用检测一类目标,这里可以置为0;
identity:目标的细分类(标识),如张三、李四、王五等。没有指定标识则为-1;
[x_center] [y_center] [width] [height]:目标的坐标信息(经过归一化处理)
某个txt文件如下所示:

图像集和标签集不用完全一一对应,下面会说明数据集的加载流程。
2. 创建配置文件
这里官网上描绘的比较隐蔽,需要认真阅读才能发现哦:

我们先来搞定配置文件。
项目根目录下有个cfg文件夹,这里存放数据集的配置文件。这里我们不使用它原来的ccmcpe.json(因为名字嘛),我们直接复制这个文件并重命名,比如我这里复制了两份,分别为百香果和猪的数据集配置文件。
以百香果为例,配置文件内容如下:

注意更改成如图中键值对描绘的一致就可以了。(图中测试集文件写错了哈,应该是.test后缀)
这里有个问题,这些以.train,.val,.test为后缀的文件是什么呢?下面第三部描述。
3. 创建图像集映射文件
项目根路径下有个data目录,里面放置的就是图像映射文件。这里不用管其他文件,以我的百香果为例,直接在data目录下新建三个问价:passionFruit.train,passionFruit.test,passionFruit.val。
这三个文件夹中放置的就是图片名(以train为例):
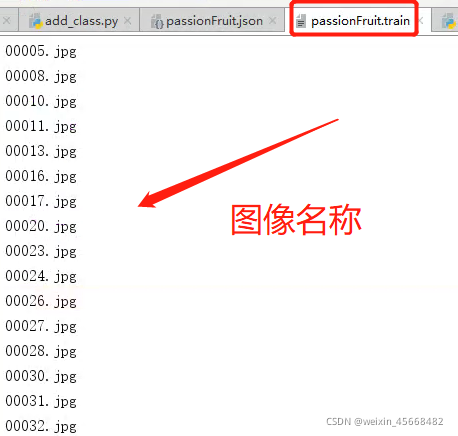
这里用来指定你的哪些图像是用来训练的,另外验证和测试同理。
这里我写了一个简单的代码用来生成这个文件:
# -*- coding: UTF-8 -*-
import os
label_dir = r"H:\software\数据\image"
file_name = "pig.train"
def add_in_each(name):
print(name)
with open(os.path.join(r'H:\software\Towards-Realtime-MOT-master\data', file_name), 'a') as f:
f.writelines(name+'\n')
def main():
names = os.listdir(label_dir)
for name in names:
if os.path.isfile(os.path.join(label_dir, name)):
add_in_each(name)
if __name__ == '__main__':
main()

根据图中的指示改动参数就可以了。
4. 修改train.py文件
OK,数据集工作准备好了,接下来调整一下训练参数了。
首先需要配置参数解析器

data-cfg改成刚刚自定义的数据集配置文件,batch-size建议改为8一下,这个算法容易爆显存;另外,cfg参数也是要制定的,有三个文件可选:cfg目录下的yolov3_…,注意cfg制定哪个文件,下面的img-size也要改为哪个大小,比如我这里就是1088×608,如果电脑配置不是非常好的那种,真心建议选最小的,不然爆显存;其他参数自行配置。
另外,170行左右的这些代码建议隐掉,不然容易报错

OK,现在终于可以开始跑了,输入命令(注意在项目根路径下)
python train.py
出现以下过程就说明正在训练了
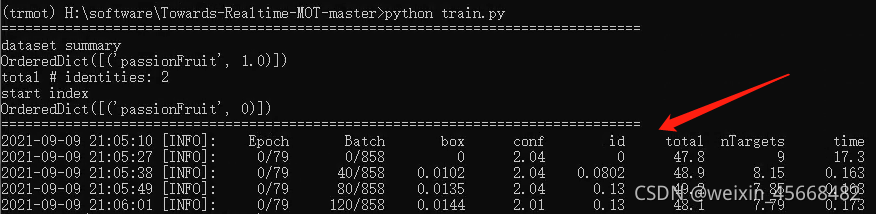
数据集的加载过程
到这里应该明白了数据集是如何加载的吧。
首先DataLoader(数据加载器)会根据数据集配置文件(passionFruit.json)去寻找图像映射文件(passionFruit.train),然后根据文件中指定的文件去寻找图像和对应的标签(因为我们命名时都是对应的嘛)。所以即使图像和标签数量不一致也没问题,只要图像映射文件中的图像名对应的图像和标签存在就可以了。
这也解释了我们为什么一定要用labels_with_ids来命名了,不然程序怎么知道要从哪个地方加载标签,有时我们需要从程序的角度思考问题(化身电脑)。
四、如何有效快速地搭建深度学习环境?
以我个人而言,搭建环境主要有三种方式:
- 参考网上其他人的博客
- 通过视频教学学习,如B站、网易云课堂等
- 最严谨最科学的一种:找到作者在github上发布的项目,通过说明手册安装

















 4520
4520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









