






VFS部分是2.6.11的代码,内存部分是2.6.11领略四级页表和虚存,进程部分是0.11
socket最大可连接的端口数是65535吗
不是的,虽然创建socket连接的时候端口字段只有12位,看起来是65535,然而因为socket或者说tcp连接是一个四元组,只要只要其中一元不同,那么可用端口数又新增65535,而且实际上可用端口号从1000开始,所以其实又小于65535
elf文件以及segment和section
下面是elf文件的结构
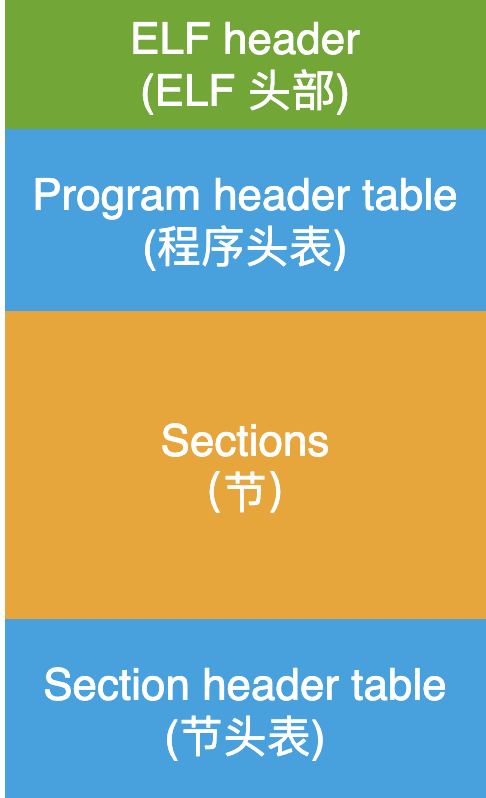 关键点:若干个读写类型相同的section(即汇编用.section或者segment分的段)会被合并成一个segment,在虚拟地址空间一起占某有个区域
关键点:若干个读写类型相同的section(即汇编用.section或者segment分的段)会被合并成一个segment,在虚拟地址空间一起占某有个区域
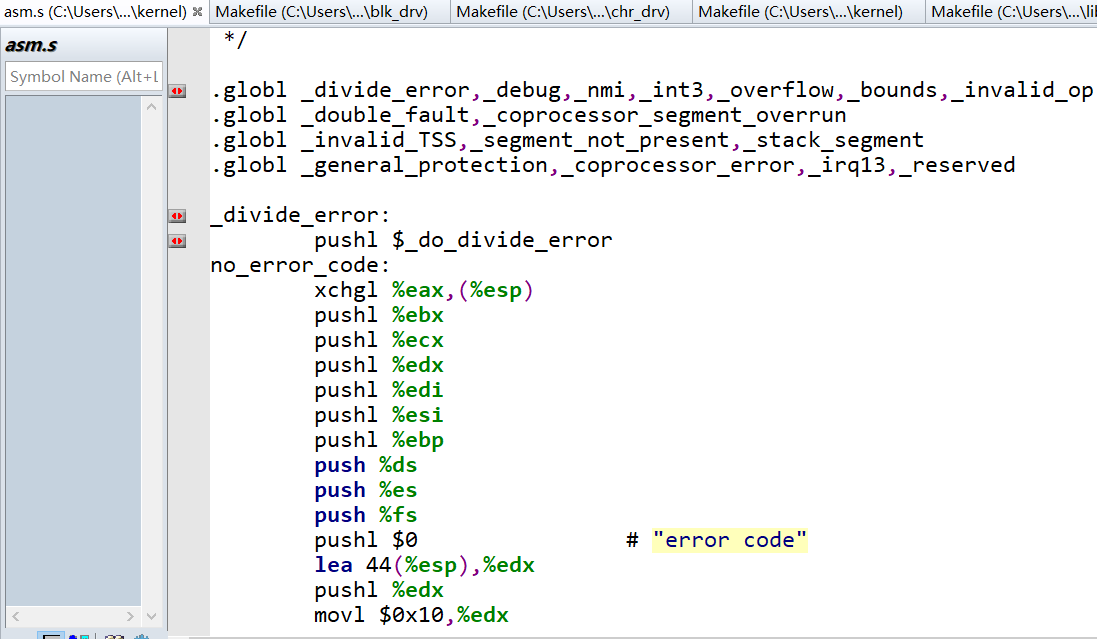
linux0.11下C语言被编译后其函数和全局变量的名字最前面会被添加_下划线
因为那时候的gcc编译器版本比较旧,现在的gcc已经不会这样干了。这是我研究中断源码的时候发现的,/kernel/traps.c下定义了如下几个中断函数而没有具体填写其内容:
void divide_error(void);
void debug(void);
void nmi(void);
倒是具体定义了do_XXX函数:
void do_divide_error(long esp, long error_code);
void do_debug(long esp, long error_code);
void do_nmi(long esp, long error_code);
而trap_init函数中(如下),直接利用了上面定义的函数:
set_trap_gate(0,÷_error);
set_trap_gate(1,&debug);
set_trap_gate(2,&nmi);
我在哪都没找到,只在asm.s中看到有类似名字的,即_divide_error,_debug,_nmi,按照开头说的,traps.c文件被编译后其trap_init函数中的divide_error等价于_divide_error,而_divide_error又会回来调用traps.c中的do_divide_error()(如下图可以看到_divide_error处将_do_divide_error()函数地址push入栈了)
但我还有疑问,为什么traps.c调用汇编的全局变量divide_error时不需要用extern来定义void divide_error(void);
即extern void divide_error(void);
linux开机全流程
内存映射
CPU 地址总线的宽度决定了可访问的内存空间的大小。比如 16 位的 CPU 地址总线宽度为 20 位,地址范围是 1M。可访问的内存地址空间并非全部分给内存,一些外设如显存,硬盘控制器等也是通过内存地址来访问,即我们可以在指定内存地址读写,这将会等价于在外设上读写,这由内存控制器硬件实现,将部分内存地址映射到外设上。
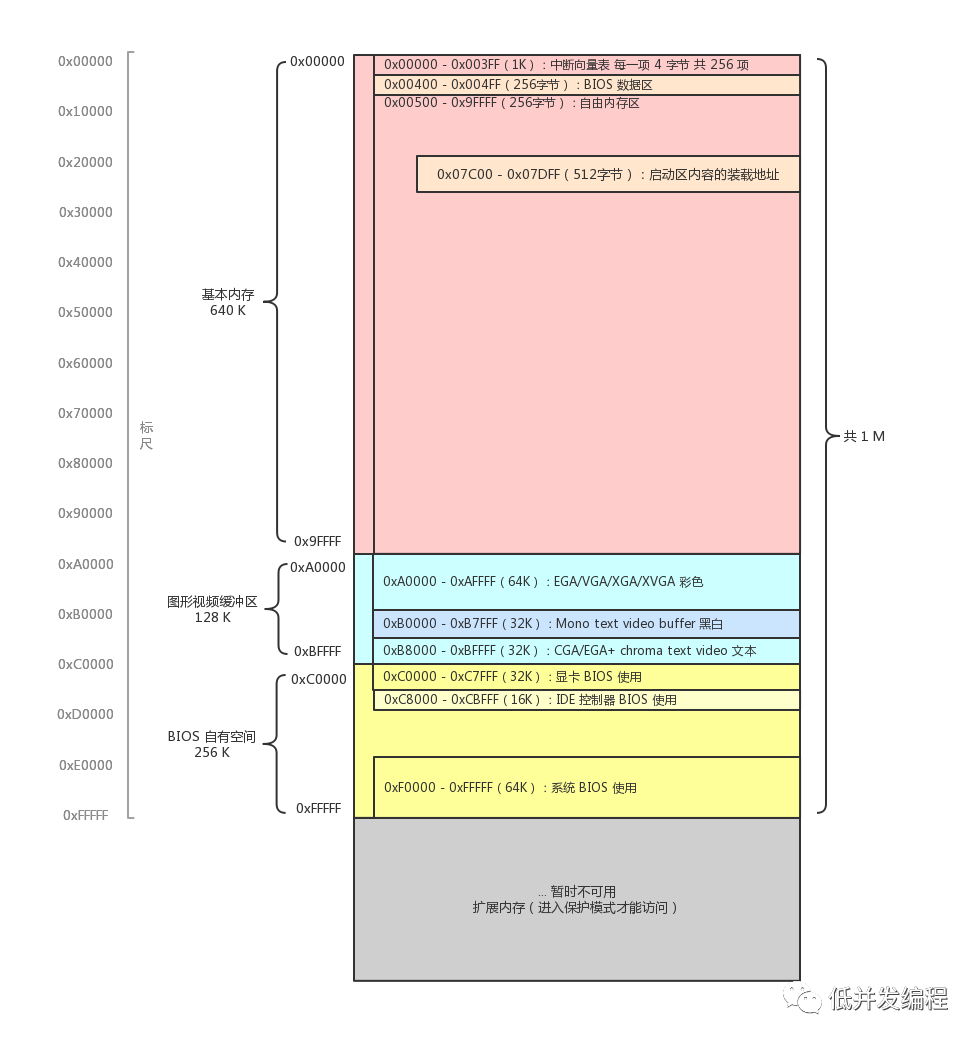
实模式下的内存分布
电脑刚开机默认就是实模式,此时CPU地址总线被限制为20位,即只能访问1M的内存
从bios里的程序开始运行
如上图可知BIOS里的信息被映射到了内存 0xC0000 - 0xFFFFF。其中最为关键的系统 BIOS 被映射到了 0xF0000 - 0xFFFFF。开机的一瞬间,CPU 的 PC 寄存器被强制初始化为 0xFFFF0(段基址寄存器 cs 初始化为 0xF000,将偏移地址寄存器 IP 初始化为 0xFFF0即实模式的寻址)。而实模式下内存的下边界就是 0xFFFFF,也就是只剩下 16 个字节的空间可以写代码了,所以必然是一条跳转指令,即jmp far f000:e05b(的机器码),意思是跳转到物理地址 0xfe05b 处开始执行(即一开始在很后面,执行了一条跳转指令,于是又跳去了前面执行),这块代码会检测一些外设信息,并初始化好硬件,在内存的0地址开始建立中断向量表并填写中断处理程序(准确说是地址,具体的中断处理程序存储在bios中)。然后开始加载启动区。
加载启动区
BIOS 会按照启动顺序(可以自行设置启动优先级如U 盘启动、硬盘启动、软盘启动、光盘启动等),读取启动盘中第 0 盘 0 道 1 扇区(512字节),只要该扇区末尾的两个字节分别是 0x55 和 0xaa,那么bios认为这个分区含有引导程序,即启动区(活动分区),如果不是,那么按顺序继续向下个设备中寻找位于 0 盘 0 道 1 扇区的内容。如果最后发现都没找到符合条件的,那直接报出一个无启动区的错误。
接着bios将该扇区的内容复制到内存的0x7c00这个位置(通过指令集的 in 和 out),再执行一条跳转指令使pc寄存器变为 0x7c00。综上,BIOS 把控制权转交给排在第一位的存储设备。
如下是一段简化的启动区代码(对应Linux0.11的\boot\bootsect.s),可以发现最后有一句DB 0x55, 0xaa,还有开头的ORG 0x7c00,这代表为程序中的地址都加一个绝对偏移量0x7c00,比如下面代码中有一句MOV AL,[SI],SI是代码段中的相对偏移,但因为启动区不是放在内存为0的地方,所以需要加上绝对偏移量才会访问到正确的内存
; hello-os
; TAB=4
ORG 0x7c00 ;
;程序主体
entry:
MOV AX,0 ;初始化寄存器
MOV SS,AX
MOV SP,0x7c00
MOV DS,AX ;段寄存器初始化为 0
MOV ES,AX
MOV SI,msg
putloop:
MOV AL,[SI]
ADD SI,1
CMP AL,0 ;如果遇到 0 结尾的,就跳出循环不再打印新字符
JE fin
MOV AH,0x0e ;指定文字
MOV BX,15 ;指定颜色
INT 0x10 ;调用 BIOS 显示字符函数
JMP putloop
fin:
HLT
JMP fin
msg:
DB 0x0a,0x0a ;换行、换行
DB "hello-os"
DB 0x0a ;换行
DB 0 ;0 结尾
RESB 0x7dfe-$ ;填充0到512字节
DB 0x55, 0xaa ;可启动设备标识
综上,BIOS 负责加载了启动区,而启动区又负责加载真正的操作系统内核
总结
- 按下开机键,CPU 将 PC 寄存器的值强制初始化为 0xffff0,这个位置是 BIOS 程序的入口地址(一跳)
- 该入口地址处是一个跳转指令,跳转到 0xfe05b 位置,开始执行(二跳)
- 执行了一些硬件检测工作后,最后一步将启动区内容加载到内存 0x7c00,并跳转到这里(三跳)
- 启动区代码主要是加载操作系统内核,并跳转到加载处(四跳)
linux中断机制
硬件中断和软件中断
硬件中断:通过中断控制器(8259A)给 CPU 的 INTR 引脚发送信号、CPU 执行某条指令发现了异常(除0),即中断和异常都属于硬件中断,因为由硬件自动触发
软件中断:执行 INT n 指令,由软件程序主动触发(事实上还有一种叫软中断,完全通过软件模拟实现中断机制???),比如 INT 0x80,就是告诉 CPU 中断号是 0x80。(Linux系统调用)
硬件中断也有获取中断号
软件中断直接给出了中断号,而硬件中断也有获取中断号的方式
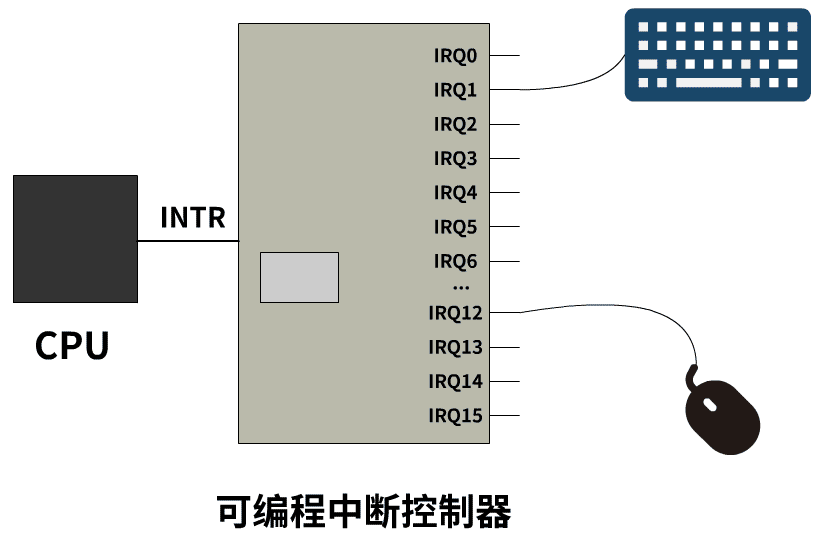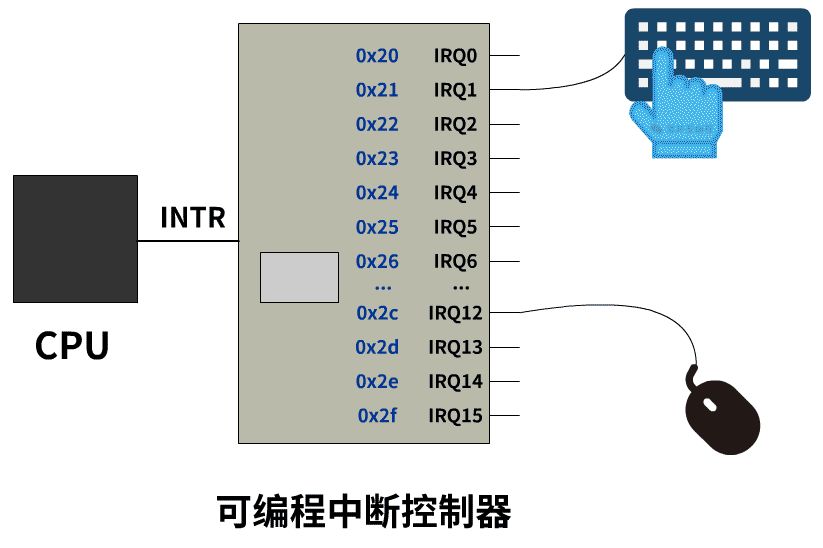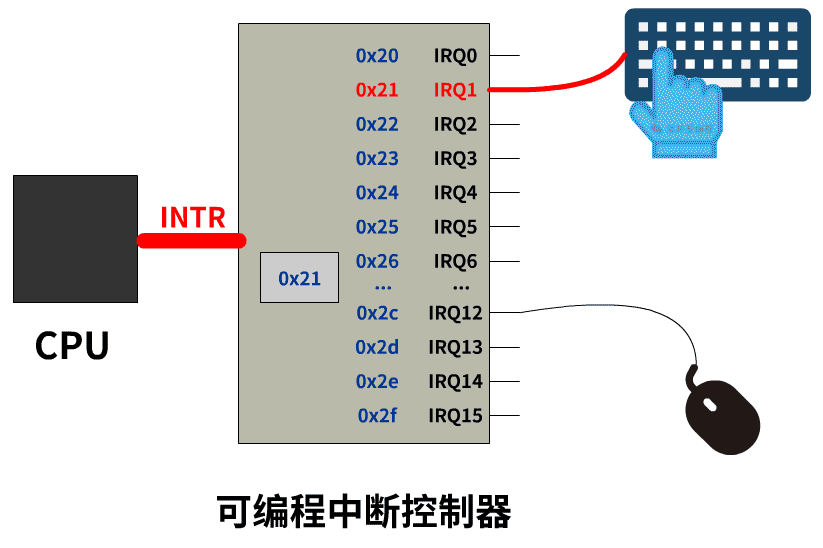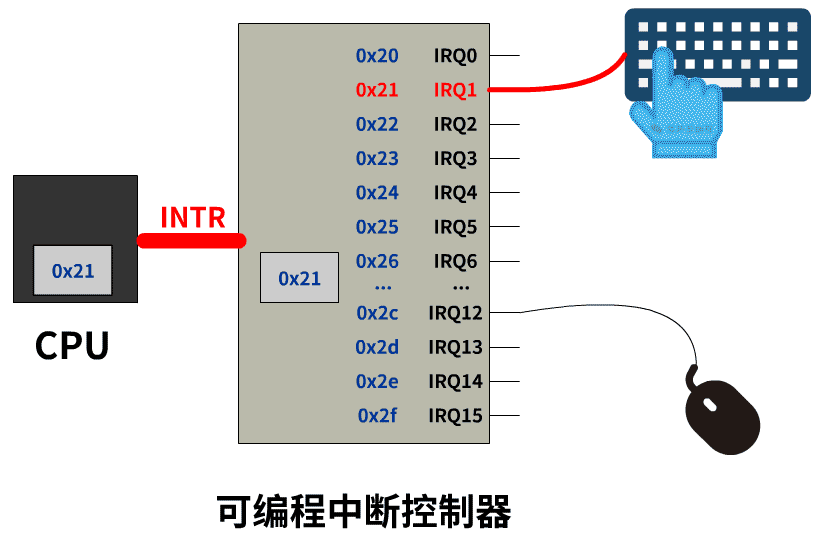
可编程中断控制器8259A
有一个设备叫做可编程中断控制器,它有很多的 IRQ 引脚线,接入了一堆能发出中断请求的硬件设备,并且可编程中断控制器提前通过in out指令(在linux的setup.s实现)被设置好了 IRQ 与中断号的对应关系。当这些硬件设备给 IRQ 引脚线发一个信号时,8259A接收到该信号并给 CPU 的 INTR 引脚也发送一个信号,CPU 收到信号后去固定端口读取到这个中断号的值。
中断向量表和中断描述符表
首先要知道linux(进入保护模式后)会将开机时(实模式下)bios建立的中断向量表完全清空(不同于DOS),另外自己写一个中断描述符表,作用和中断向量表相似,都是一个数组,然后填写对应中断处理程序的地址,通过中断号作为下标索引。中断描述符表通过设置idtr寄存器让CPU发现该表在内存中的起始地址(而中断向量表必须在0地址)
而DOS操作系统(windows前身)是运行在实模式下的,故其建立的中断调用也建立在中断向量表中,只不过其中断向量号和BIOS的不能冲突(即DOS操作系统不会覆盖掉bios初始化建立的中断向量表,而是在表后面继续添加)。其中0x20~0x27是DOS中断。因为DOS在实模式下运行,故其可以调用BIOS中断。其中0x21是DOS的系统调用号(linux的是0x80),其中的系统调用都是对bios中断的封装组合成更丰富的功能
收到中断号之后 CPU 干嘛?
先用一句不太准确的话总结,CPU 收到一个中断号 n 后,会去中断向量表中寻找第 n 个中断描述符,从中断描述符中找到中断处理程序的地址,然后跳过去执行。
为什么说不准确呢?因为从中断描述符中找到的,并不直接是程序的地址,而是段选择子和段内偏移地址。于是段选择子又会去全局描述符表中寻找段描述符,从中取出段基址。之后段基址 + 段内偏移地址,才是最终处理程序的入口地址。
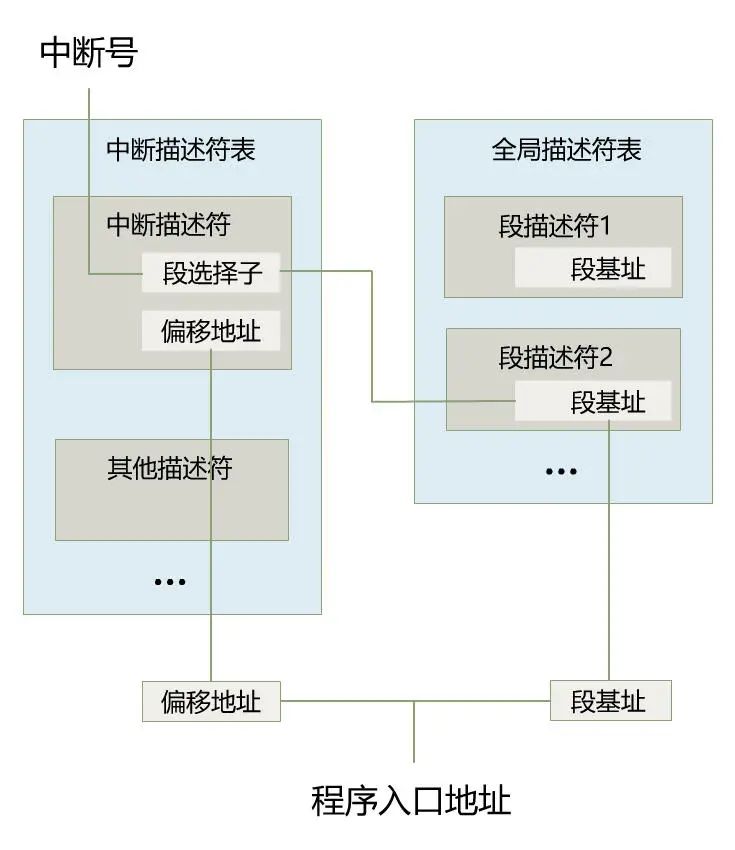
当然这个入口地址,还不是最终的物理地址,如果开启了分页,又要经历分页机制的转换,就像下面这样。
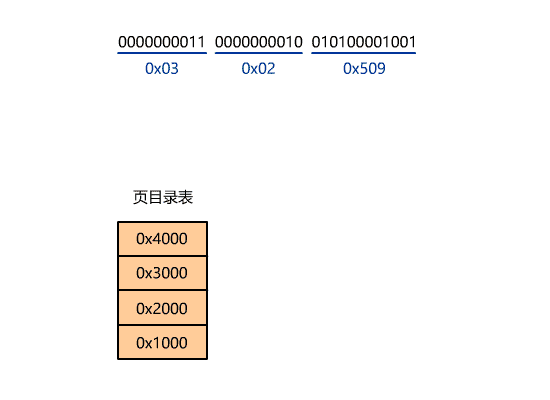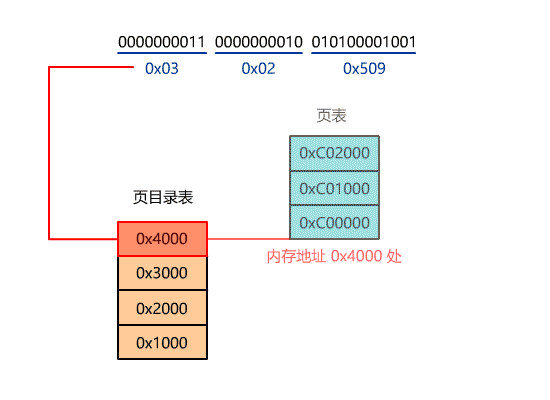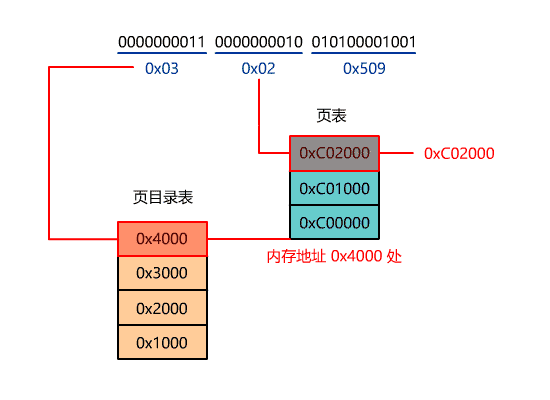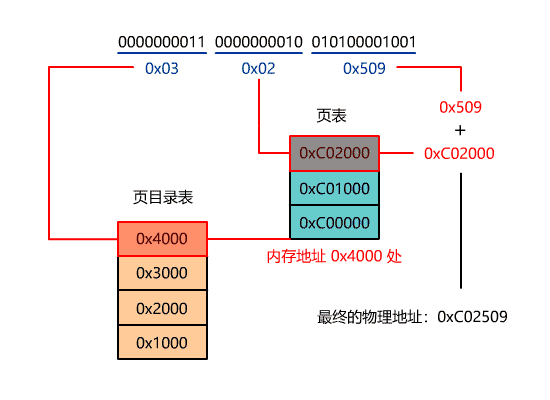
系统调用-DOS 0x21,Linux 0x80
DOS中断调用中那么多功能是如何实现的?是通过先往ah寄存器中写好子功能号,再执行int 0x21。这时在中断向量表中第0x21个表项,即物理地址0x21*4处中的中断处理程序开始根据寄存器ah中的值来调用相应的子功能。
Linux的系统调用和DOS中断调用类似,不过Linux是通过int 0x80指令进入一个中断程序后再根据eax寄存器的值来调用不同的子功能函数的。再补充一句:如果在实模式下执行int指令,会自动去访问中断向量表。如果在保护模式下执行int指令,则会自动访问中断描述符表。
linux -int 0x80系统调用全流程
用户代码写了int 0x80,并在eax寄存器写了功能号->0x80的中断处理程序地址为\kernel\system_call.s中的_system_call->_system_call中call _sys_call_table(,%eax,4)即根据4*eax作为偏移索引到表中对应位置,该表在\include\linux\sys.h定义即fn_ptr sys_call_table[] = { sys_setup, …},这些sys_XXX定义在各个c文件中
符号链接
又名软链接(windows的快捷方式),符号链接文件直接将链接的路径存放在文件中,访问该文件时会先读取该文件中存储的路径然后访问该路径
文件系统在磁盘中的体现
下面是磁盘的内容,其中i节点就是一个inode数组,逻辑块就是数据块可用于存放数据
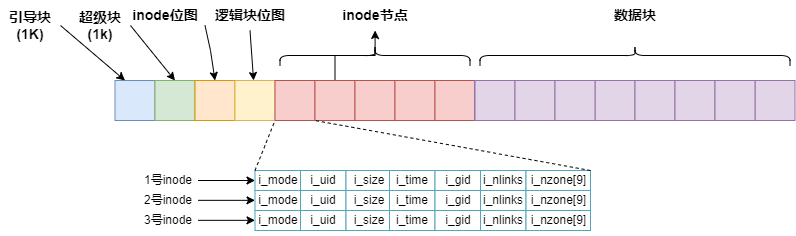
操作系统通过将磁盘数据读入到内存中指定的缓冲区块来与磁盘交互,对内存中的缓冲区块修改后写回磁盘。
进程(task_struct * task[NR_TASKS] = {&(init_task.task), }; )、
系统打开文件表(file file_table[NR_FILE])、
超级块、
inode
等等在linux中都有唯一且有限的全局数组,比如创建新进程或者打开新的文件时就需要在这个数组中找到一个空位(槽)填写相应内容否则不允许进行,因为这些都是系统资源,你可以理解为os只能管理有限的资源
bread(int dev,int block)函数返回一个缓冲区块的头部(用于解释缓冲区,其内部有指针指向具体缓冲区块的地址)的地址,作用是从设备号为dev的设备中读取第block块数据块,缓冲区块和文件系统的了逻辑块大小一样!
若干个扇区作为一个逻辑块(linux0.11中1个逻辑块是两个扇区即1MB),若干个逻辑块作为一个簇,因为随着磁盘容量增大,如果分配空间的单位不增大会导致数据块位图增大从而又浪费了磁盘空间。其中,逻辑块是逻辑上的,也就是通过软件实现的,具体到读写底层(即利用汇编提供的读写磁盘中断)时,仍然是以扇区为单位读写
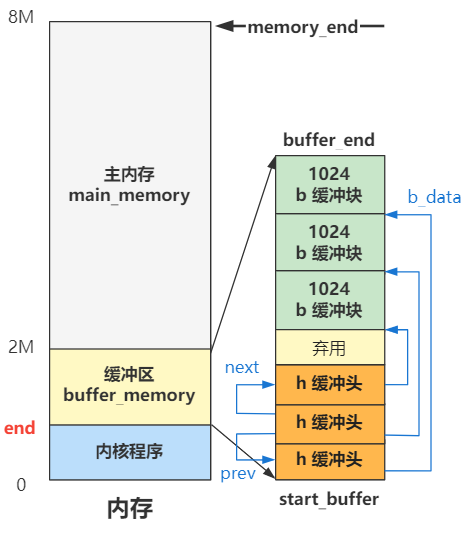
缓冲区
准确地说下图的缓冲区之间通过buffer_head的b_next_free、b_prev_free指针连接而成,在系统初始化的buffer_init中完成这些连接
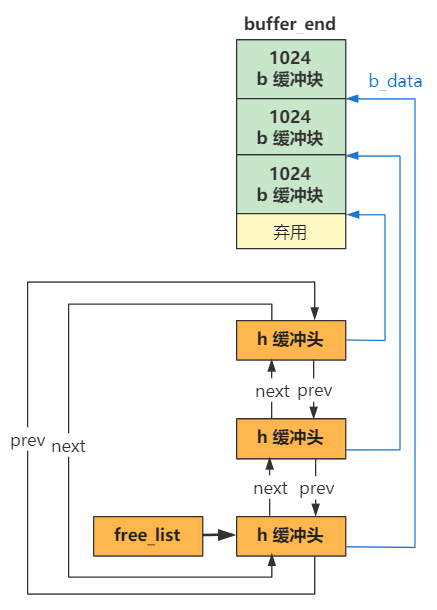 除此以外,还有一个哈希链表数组hash_table(一开始空,当某个缓冲区被用到了才会加入到该数组),根据设备号和块号哈希映射到数组的某个索引,冲突则通过链表连接起来(buffer_head的b_prev和b_next)
除此以外,还有一个哈希链表数组hash_table(一开始空,当某个缓冲区被用到了才会加入到该数组),根据设备号和块号哈希映射到数组的某个索引,冲突则通过链表连接起来(buffer_head的b_prev和b_next)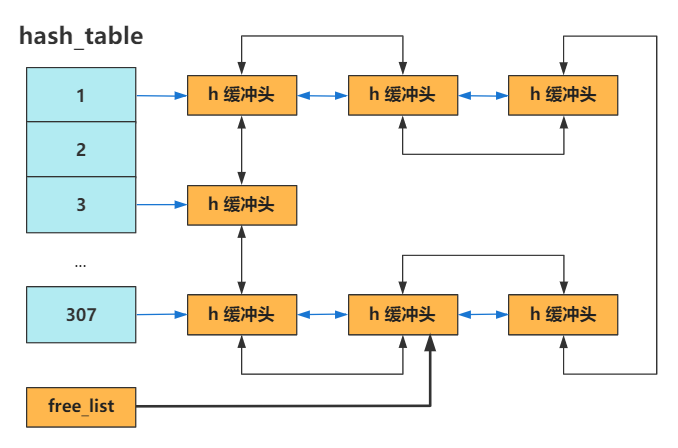
暂时发现只有在读写缓冲区的时候缓冲区才会被上锁,
uptodate针对读,为1的时候表示缓冲区内容和磁盘中的一致;dirt针对写,为1的时候表示缓冲区被更新了,需要同步到磁盘
inode的i_count和file的f_count区别
inode的i_count:
file的f_count:
磁盘上的inode表并不会被加载到OS
只有当具体某个文件被读或写时,其inode才会被加载到内存的inode缓存表中,即inode_table[NR_INODE],每个inode元素都被初始化为0了,相当于提前先生成inode对象,使得内存中常驻NR_INODE个inode可被使用,而不必临时new一个,只需要直接初始化空闲inode的每个属性,这会快很多
linux0.11需要手动将脏缓冲区同步到磁盘上
除了少数条件会自动触发自动同步之外,码农需要手动调用sys_sync系统调用使得刚刚写的文件会立刻同步到磁盘上,否则你得等。linux0.11做的仅仅是标记该缓冲区为脏。在2.6版本,linux会专门有个pdflush线程周期性地检查是否有脏缓冲区并且自动同步到磁盘
linux0.11下设备文件的inode->i_zone[0]是设备号,而0.11后用inode->rdev代表设备号
多个空闲缓冲区是资源,共用一个等待队列,当没有空闲缓冲区时,申请空闲缓冲区的进程加入到该等待队列并阻塞,但每个缓冲区自身还有一个等待队列用于互斥,比如这时候突然有一个空闲缓冲区了,那么申请空闲缓冲区的队列中的所有进程都被唤醒,全部(n)去争夺这个新的空闲缓冲区,于是(n-1)都加入到该缓冲区的等待队列
这样设计是可理解的,没有空闲缓冲区的时候,申请该资源的进程没有可以加入的队列(不知道加入到哪个缓冲区),现在专门用一个队列来让他们排队,同时也能阻塞他们了
linux下的五种进程状态
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 3
#define TASK_STOPPED 4
1.TASK_RUNNING:可运行状态,处于该状态的进程可以被调度执行而成为当前进程.
2.TASK_INTERRUPTIBLE:可中断睡眠状态,处于该状态的进程在所需资源有效时被唤醒,也可以通过信号或者定时中断唤醒.
3.TASK_UNINTERRUPTIBLE:不可中断睡眠状态,处于该状态的进程仅当所需资源有效时被唤醒.
4.TASK_ZOMBLE:僵尸状态,表示进程结束且释放资源.但其task_struct仍未释放.
5.TASK_STOPPED:暂停状态.处于该状态的进程通过其他进程的信号才能被唤醒
switch_to
作用:根据某个调度算法选出轮换的进程后将会调用此函数,进行进程的上下文切换(保存和恢复各类寄存器,特别是ip寄存器)。比如发生时钟中断时,
实现:
GDT即全局描述符表,里面为每个进程装着三种东西如下图
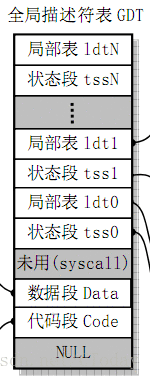
显然第一个状态段tss0(保存着cpu上下文即对应进程的寄存器状态)在第4个位置(从0开始算),如果想访问第n个进程的tss,则需要将DS段寄存器中的段描述符索引设置为4+n*2(可以对应上图试试),
下图是段选择子,即段寄存器所装内容,段选择子包括三部分:描述符索引(index)、TI、请求特权级(RPL)。它的index(描述符索引)部分表示所需要的段的描述符在描述符表的位置,由这个位置再根据在GDTR中存储的全局描述符表基址(或者LDTR存储的局部描述符表基址)就可以找到相应的描述符。然后用描述符表中的段基址加上偏移地址(SEG:OFFSET)就可以转换成线性地址(即只经过段式的地址变换,还没进行页式转换),段选择子中的TI值只有一位0或1,0代表选择子是在GDT选择,1代表选择子是在LDT选择。请求特权级(RPL)则代表选择子的特权级,共有4个特权级(0级、1级、2级、3级)。

而这里linux的实现是先让4左移3位,再加上n左移4位的值,其实就是实现了我们上面说的话(跳过前面的012位,准确说是令前3位为0)。
#define FIRST_TSS_ENTRY 4
#define _TSS(n) ((((unsigned long) n)<<4)+(FIRST_TSS_ENTRY<<3))
下面开始分析switch_to
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__(
/*ecx寄存器存放着目标进程task[n]
即调度算法选出的进程的task_struct结构体地址,
这里将目标进程与当前进程比较,
如果一样就不必切换上下文了*/
"cmpl %%ecx,_current\n\t"
//接着上面,进程一样,所以跳到1:即什么都不用干
"je 1f\n\t"
/*dx寄存器装着目标进程在gdt的16位的段描述符索引即_TSS(n),
其低3为为0,然后将dx传送给__tmp的成员b*/
"movw %%dx,%1\n\t"
//将目标进程的task_struct结构体地址赋给current变量
"xchgl %%ecx,_current\n\t"
/*%0就是_tmp的a,ljmp会访问48位地址,
因此32位全0的a作为了偏移地址,
因为a,b在同一个结构体,所以在内存中相邻,
于是剩下16位就是b即目标进程的tss段描述符,
根据该描述符硬件发现是TSS(描述符的标志位),
于是将当前进程的cpu上下文保存到其TSS,并
切换到目标进程的TSS
*/
"ljmp %0\n\t"
/*不用具体看,于是这里的代码不会被执行,
因为上面的TSS切换导致ip寄存器被切换到目标进程的执行,
所以直到该进程被重新调度便会从这里开始执行*/
"cmpl %%ecx,_last_task_used_math\n\t"
"jne 1f\n\t"
"clts\n"
"1:"
::"m" (*&__tmp.a),"m" (*&__tmp.b),
"d" (_TSS(n)),"c" ((long) task[n]));
}
_timer_interrupt 时钟中断
作用:下面的_timer_interrupt函数被注册到中断处理函数中,时钟中断发生时会被调用,最关键的是调用了_do_timer和jmp ret_from_sys_call
实现:
_timer_interrupt:
push %ds # save ds,es and put kernel data space
push %es # into them. %fs is used by _system_call
push %fs
pushl %edx # we save %eax,%ecx,%edx as gcc doesn't
pushl %ecx # save those across function calls. %ebx
pushl %ebx # is saved as we use that in ret_sys_call
pushl %eax
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
movl $0x17,%eax
mov %ax,%fs
incl _jiffies
movb $0x20,%al # EOI to interrupt controller #1
outb %al,$0x20
movl CS(%esp),%eax
andl $3,%eax # %eax is CPL (0 or 3, 0=supervisor)
pushl %eax
call _do_timer # 'do_timer(long CPL)' does everything from
/*前两行为了调用C语言函数,
输入了参数long CPL即pushl %eax,
最后执行完就回到4个字节前的栈即long的长度*/
addl $4,%esp # task switching to accounting ...
jmp ret_from_sys_call
do_timer(long cpl)
作用:减少当前进程时间片,如果当前进程时间片没了就调用schedule()进行进程调度,否则直接返回
实现:
void do_timer(long cpl) //current priority level
{
extern int beepcount; // 扬声器发声时间滴答数
extern void sysbeepstop(void); //关闭扬声器
if (beepcount)
if (!--beepcount)
sysbeepstop();
if (cpl)
current->utime++;
else
current->stime++;
// 如果有用户的定时器存在,则将链表第 1 个定时器的值减 1。如果已等于 0,则调用相应的处理
// 程序,并将该处理程序指针置为空。然后去掉该项定时器
if (next_timer) {
next_timer->jiffies--;
while (next_timer && next_timer->jiffies <= 0) {
void (*fn)(void);
fn = next_timer->fn;
next_timer->fn = NULL;
next_timer = next_timer->next;
(fn)();
}
}
if (current_DOR & 0xf0)
do_floppy_timer();
if ((--current->counter)>0) return; // 当前线程还有剩余时间片,直接返回
current->counter=0;
if (!cpl) return; // 对于超级用户程序,不依赖 counter 值进行调度
schedule();
}
schedule()
作用:按照某个算法以选出新的进程来执行,并且调用switch_to(next)转到新进程执行
实现:
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->timeout && (*p)->timeout < jiffies) {
(*p)->timeout = 0;
if ((*p)->state == TASK_INTERRUPTIBLE)
(*p)->state = TASK_RUNNING;
}
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(*p)->blocked) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
捋一下时钟中断
时钟中断发生
->_timer_interrupt
->do_timer
->schedule
->switch_to
->新进程执行
->重新调度到本进程
->继续执行完switch_to剩下的
“cmpl %%ecx,_last_task_used_math\n\t”
“jne 1f\n\t”
“clts\n”
->继续执行完_timer_interrupt的addl $4,%esp和jmp ret_from_sys_call
->执行ret_from_sys_call,里面会检查本进程的信号然后调用_do_signal进行信号处理
->最后回到ret_from_sys_call执行剩下的,即恢复到本进程发生时钟中断那一刻执行的代码及其cpu上下文
即
popl %eax
3:
popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret(等价于pop栈中内容到IP、CS 以及 EFLAGS寄存器)
ret_from_sys_call:
movl _current,%eax # task[0] cannot have signals
cmpl _task,%eax
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
//最关键
call _do_signal
popl %eax
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
linux信号机制
对进程的信号属性的对应比特位置位,每个时钟中断时OS都会检查进程的信号属性,如果发现被置位则根据进程的信号处理函数属性调用对应的处理函数,如果没有对应处理函数则do_exit()即释放当前进程的各种资源
(信号量,内存,打开的文件,进程的代码段和数据段占用的内存等等,如果当前要销毁的进程有子进程,那么就让1号进程作为新的父进程(init进程),如果当前进程是一个会话头进程,则会终止会话中的所有进程)
然后将当前进程设置为僵死状态即current->state = TASK_ZOMBIE;,最后调度别的进程即schedule();
下面是具体代码分析:
键盘中断处理函数会走到处理字符的 copy_to_cooked 函数里,如下
#define INTMASK (1<<(SIGINT-1))
// kernel/chr_drv/tty_io.c
void copy_to_cooked (struct tty_struct *tty) {
...
if (c == INTR_CHAR (tty)) {
tty_intr (tty, INTMASK);
continue;
}
...
}
当 INTR_CHAR 发现字符为中断字符时(其实就是 CTRL+C),就调用 tty_intr 给进程发送信号。
tty_intr 函数很简单,就是给所有组号等于 tty 组号的进程,发送信号。
// kernel/chr_drv/tty_io.c
void tty_intr (struct tty_struct *tty, int mask) {
int i;
...
for (i = 0; i < NR_TASKS; i++) {
if (task[i] && task[i]->pgrp == tty->pgrp) {
task[i]->signal |= mask;
}
}
}
发送信号就是给进程 task_struct 结构中的 signal 的相应比特位置 1 而已。
发送什么信号,在上面的宏定义中也可以看出,就是 SIGINT 信号。
SIGINT 就是个数字,它是几呢?它就定义在 signal.h 这个头文件里。
// signal.h
#define SIGHUP 1 /* hangup */
#define SIGINT 2 /* interrupt */
#define SIGQUIT 3 /* quit */
#define SIGILL 4 /* illegal instruction (not reset when caught) */
#define SIGTRAP 5 /* trace trap (not reset when caught) */
#define SIGABRT 6 /* abort() */
#define SIGPOLL 7 /* pollable event ([XSR] generated, not supported) */
#define SIGIOT SIGABRT /* compatibility */
#define SIGEMT 7 /* EMT instruction */
#define SIGFPE 8 /* floating point exception */
#define SIGKILL 9 /* kill (cannot be caught or ignored) */
#define SIGBUS 10 /* bus error */
#define SIGSEGV 11 /* segmentation violation */
#define SIGSYS 12 /* bad argument to system call */
#define SIGPIPE 13 /* write on a pipe with no one to read it */
#define SIGALRM 14 /* alarm clock */
#define SIGTERM 15 /* software termination signal from kill */
#define SIGURG 16 /* urgent condition on IO channel */
#define SIGSTOP 17 /* sendable stop signal not from tty */
#define SIGTSTP 18 /* stop signal from tty */
#define SIGCONT 19 /* continue a stopped process */
#define SIGCHLD 20 /* to parent on child stop or exit */
#define SIGTTIN 21 /* to readers pgrp upon background tty read */
#define SIGTTOU 22 /* like TTIN for output if (tp->t_local<OSTOP) */
#define SIGIO 23 /* input/output possible signal */
#define SIGXCPU 24 /* exceeded CPU time limit */
#define SIGXFSZ 25 /* exceeded file size limit */
#define SIGVTALRM 26 /* virtual time alarm */
#define SIGPROF 27 /* profiling time alarm */
#define SIGWINCH 28 /* window size changes */
#define SIGINFO 29 /* information request */
#define SIGUSR1 30 /* user defined signal 1 */
#define SIGUSR2 31 /* user defined signal 2 */
所有 Linux 0.11 支持的信号都放在这了,有我们熟悉的按下 CTRL+C 时的信号 SIGINT,有我们通常杀死进程时 kill -9 的信号 SIGKILL,还有 core dump 内存访问出错时经常遇到的 SIGSEGV。
现在这个进程的 tast_struct 结构中的 signal 就有了对应信号位的值,那么在下次时钟中断到来时,便会因为timer_interrupt 这个时钟中断处理函数处理完成后收尾从而调用(中断处理收尾)汇编函数ret_from_sys_call(即所有中断处理函数完成后都会调用的函数),再调用到 do_signal 方法,从而检查当前进程的signal情况
// kernel/signal.c
void do_signal (long signr ...) {
...
//以信号的号码作为偏移,在当前进程的sigaction数组中索引到对应信号处理函数
struct sigaction *sa = current->sigaction + signr - 1;
sa_handler = (unsigned long) sa->sa_handler;
// 如果信号处理函数为空,则直接退出
if (!sa_handler) {
...
do_exit (1 << (signr - 1));
...
}
// 否则就跳转到信号处理函数的地方运行
*(&eip) = sa_handler;
...
}
进入 do_signal 函数后,如果当前信号 signr 对应的信号处理函数 sa_handler 为空时,就直接调用 do_exit 函数退出,也就是我们看到的按下 CTRL+C 之后退出的样子了。
但是,如果信号处理函数不为空,那么就通过将 sa_handler 赋值给 eip 寄存器,也就是指令寄存器的方式,跳转到相应信号处理函数处运行。
信号处理函数注册在每个进程 task_struct 中的 sigaction 数组中。只需要给 sigaction 对应位置处填写上信号处理函数即可。
// signal.h
struct sigaction {
union __sigaction_u __sigaction_u; /* signal handler */
sigset_t sa_mask; /* signal mask to apply */
int sa_flags; /* see signal options below */
};
/* union for signal handlers */
union __sigaction_u {
void (*__sa_handler)(int);
void (*__sa_sigaction)(int, struct __siginfo *,
void *);
};
// sched.h
struct task_struct {
...
struct sigaction sigaction[32];
...
}
那么如何注册这个信号处理函数呢,通过调用 signal 这个库函数即可。
#include <stdio.h>
#include <signal.h>
void int_handler(int signal_num) {
printf("signal receive %d\n", signal_num);
}
int main(int argc, char ** argv) {
signal(SIGINT, int_handler);
for(;;)
pause();
return 0;
}
这是个死循环的 main 函数,只不过,通过 signal 注册了 SIGINT 的信号处理函数,里面做的事情仅仅是打印一下信号值。
编译并运行它,我们会发现在按下 CTRL+C 之后程序不再退出,而是输出了我们 printf 的话。
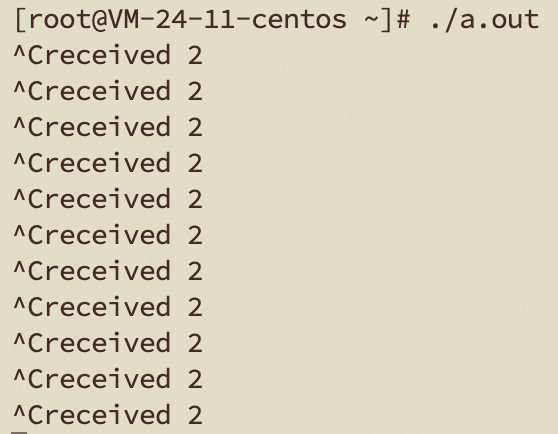
do_exit(long code)
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f)); /*释放ldt段*/
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
for (i=0 ; i<NR_TASKS ; i++)
if (task[i] && task[i]->father == current->pid) {
task[i]->father = 1; /*如果当前要销毁的进程有子进程,那么就让1号进程作为新的父进程(init进程*/
if (task[i]->state == TASK_ZOMBIE)/*如果进程僵死,则让发送信号给其父进程1号进程*/
/* assumption task[1] is always init */
(void) send_sig(SIGCHLD, task[1], 1);
}
for (i=0 ; i<NR_OPEN ; i++) /*每个进程能打开的最大文件数是NR_OPEN*/
if (current->filp[i])/*如果当前进程有打开的文件,则关闭*/
sys_close(i);
/*对当前的目录和i节点进行同步(文件操作)*/
iput(current->pwd);
current->pwd=NULL;
iput(current->root);
current->root=NULL;
iput(current->executable);
current->executable=NULL;
if (current->leader && current->tty >= 0) /*如果进程打开了控制台*/
tty_table[current->tty].pgrp = 0; /*将控制台清空*/
if (last_task_used_math == current) /*使用了协处理器*/
last_task_used_math = NULL; /*将协处理器清空*/
if (current->leader) /*如果进程时会话头进程,则关闭会话*/
kill_session();
current->state = TASK_ZOMBIE; /*当前进程设置为僵死状态*/
current->exit_code = code; /* 设置任务执行停止的退出码,其父进程会取。*/
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}
软中断
软中断是纯软件实现的,宏观效果看上去和中断差不多的一种方式。
什么叫宏观效果呢?意思就是说,中断在宏观层面看来,就是打断当前正在运行的程序,转而去执行中断处理程序,执行完之后再返回原程序。
从这个层面看,硬中断可以达到这个效果,软中断也可以达到这个效果,所以说宏观效果一样。
那微观层面呢?就是我们需要了解的原理啦。
硬中断的微观层面,就是 CPU 在每一个指令周期的最后,都会留一个 CPU 周期去查看是否有中断,如果有,就把中断号取出,去中断向量表中寻找中断处理程序,然后跳过去。
软中断的微观层面,简单说就是有一个单独的守护进程,不断轮询一组标志位,如果哪个标志位有值了,那去这个标志位对应的软中断向量表数组的相应位置,找到软中断处理函数,然后跳过去。
 接下来看这个入口方法。
接下来看这个入口方法。
asmlinkage void __init start_kernel(void) {
...
trap_init();
sched_init();
time_init();
...
rest_init();
}
省略了很多部分,但可以看出这个方法里就是各种初始化。
接着看 rest_init() 这个方法。
static void rest_init(void) {
kernel_thread(init, NULL, CLONE_KERNEL);
}
static int init(void * unused) {
do_pre_smp_initcalls();
}
static void do_pre_smp_initcalls(void) {
spawn_ksoftirqd();
}
看到一个 spawn_ksoftirqd(),翻译过来就是 spawn kernel soft irt daemon,开启内核软中断守护进程,
__init int spawn_ksoftirqd(void) {
cpu_callback(&cpu_nfb, CPU_ONLINE, (void *)(long)smp_processor_id());
register_cpu_notifier(&cpu_nfb);
return 0;
}
static int __devinit cpu_callback(...) {
kernel_thread(ksoftirqd, hcpu, CLONE_KERNEL);
}
static int ksoftirqd(void * __bind_cpu) {
for (;;) {
while (local_softirq_pending()) {
do_softirq();
cond_resched();
}
}
}
asmlinkage void do_softirq(void) {
h = softirq_vec;
pending = local_softirq_pending();
do {
if (pending & 1) {
h->action(h);
h++;
pending >>= 1;
} while (pending);
}
前面的不用管,直接看最后一个方法,do_softirq(),这个方法展示了软中断处理守护进程所做的事情的精髓
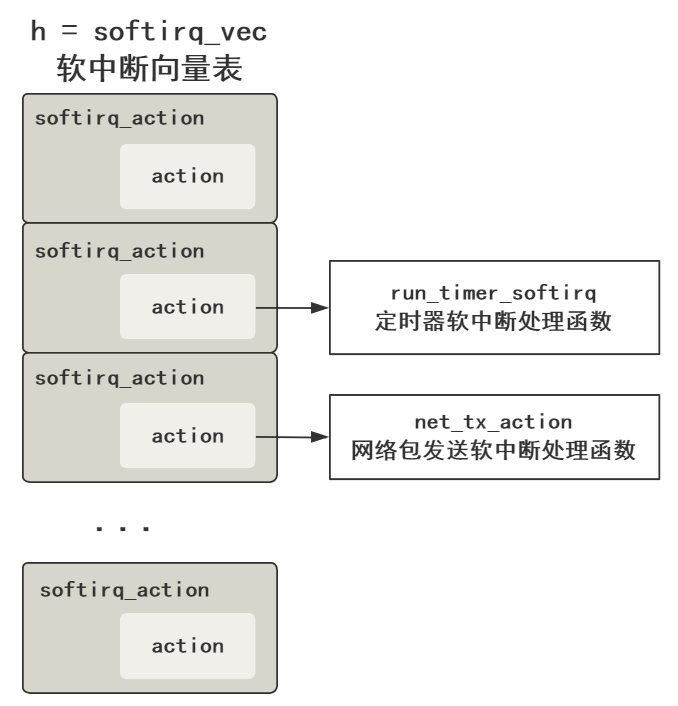
// 这就是软中断处理函数表(软中断向量表)
// 和硬中断的中断向量表一样
static struct softirq_action softirq_vec[32];
asmlinkage void do_softirq(void) {
// h = 软中断向量表起始地址指针
h = softirq_vec;
/* 这个是软中断标志位们,
一次性拿到所有的软中断标志位,
local_softirq_pending()获取到
当前CPU的__softirq_pending值*/
pending = local_softirq_pending();
do {
// 此时的软中断标志位有值(说明有软中断)
if (pending & 1) {
// 去对应的软中断向量表执行对应的处理函数
h->action(h);
// 软中断向量表指针向后移动
h++;
// 同时软中断处理标志位也向后移动
pending >>= 1;
} while (pending);
}
首先 h 代表软中断向量表 softirq_vec,和硬中断的中断向量表的存在是一个目的,就是个数组嘛,然后里面的元素存储着软中断处理程序的地址指针,在 action 中。
 然后 pending 代表软中断标志位(们)。
然后 pending 代表软中断标志位(们)。
这里完全由于 Linux 里用了好多 C 语言的宏定义搞得很绕,我先放出来,别担心。
typedef struct {
unsigned int __softirq_pending;
unsigned long idle_timestamp;
unsigned int __nmi_count; /* arch dependent */
unsigned int apic_timer_irqs; /* arch dependent */
} irq_cpustat_t;
extern irq_cpustat_t irq_stat[]; /* defined in asm/hardirq.h */
#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member)
#define __IRQ_STAT(cpu, member) ((void)(cpu), irq_stat[0].member)
#define softirq_pending(cpu) __IRQ_STAT((cpu), __softirq_pending)
#define local_softirq_pending() softirq_pending(smp_processor_id())
pending = local_softirq_pending();
把这些宏定义都翻译过来,再去掉多处理器的逻辑,就当只有一个核心,就变得很简单了。
pending = irq_stat[0].__softirq_pending;
它就是个 int 值而已,32 位。
回过头看之前的,pending(软中断标志位)与 h(软中断向量表)的向后移动的步长。
// 软中断向量表指针向后移动
h++;
// 同时软中断处理标志位也向后移动
pending >>= 1;
可以看出软中断标志位的一位对应着软中断向量表中的一个元素,这就不难理解为什么中断向量表这个数组大小是 32 位了。
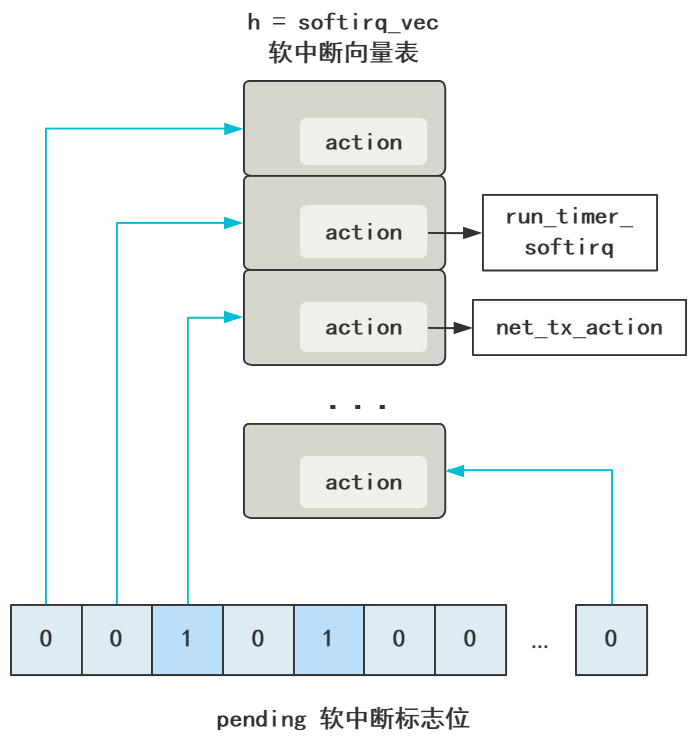 不断遍历 pending 这个软中断标志位的每一位,如果是 0 就忽略,如果是 1,那从上面的 h 软中断向量表中找到对应的元素,然后执行 action 方法,action 就对应着不同的软中断处理函数。
不断遍历 pending 这个软中断标志位的每一位,如果是 0 就忽略,如果是 1,那从上面的 h 软中断向量表中找到对应的元素,然后执行 action 方法,action 就对应着不同的软中断处理函数。
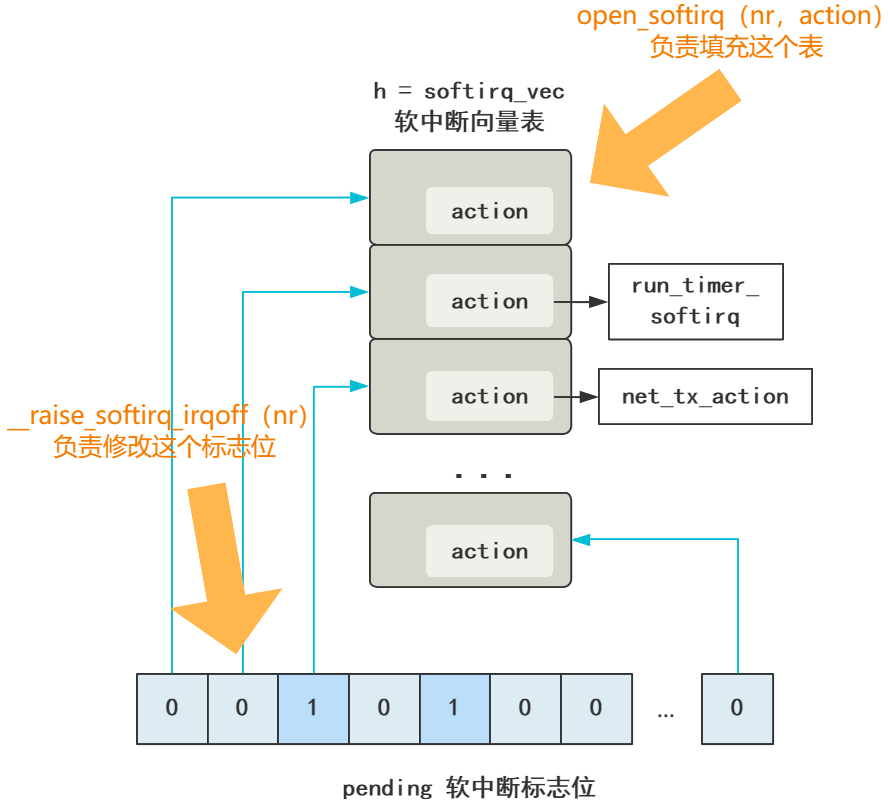
注册软中断向量表:
softirq_vec[0].action = NULL;
softirq_vec[1].action = run_timer_softirq;
softirq_vec[2].action = net_tx_action;
...
softirq_vec[31].action = xxx;
比如,网络子系统的初始化,有一步就需要注册网络的软中断处理函数。
subsys_initcall(net_dev_init);
static int __init net_dev_init(void) {
...
// 网络发包的处理函数
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
// 网络收包的处理函数
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
...
}
void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
{
softirq_vec[nr].data = data;
// 简直完全一样
softirq_vec[nr].action = action;
}
NET_TX_SOFTIRQ 这些是枚举值,具体看这些枚举也会发现 Linux-2.6.0 中也不多。
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
SCSI_SOFTIRQ,
TASKLET_SOFTIRQ
};
触发软中断:
我们看网络数据包到来之后,有一段代码。
#define __raise_softirq_irqoff(nr) \
do { local_softirq_pending() |= 1UL << (nr); } while (0)
static inline void __netif_rx_schedule(struct net_device *dev) {
list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
// 发出软中断
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
完全可以等价为下面的代码
static inline void __netif_rx_schedule(struct net_device *dev) {
list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
// 发出软中断
local_softirq_pending() |= 1UL << (NET_RX_SOFTIRQ)
}
软中断没什么神奇的骚操作,就是一组一位一位的软中断标志位,对应着软中断向量表中一个一个的中断处理函数,然后有个内核守护进程不断去循环判断调用,而已。
然后,由各个子系统调用 open_softirq 负责把软中断向量表附上值。
再由各个需要触发软中断的地方调用 raise_softirq_irqoff 修改中断标志位的值。
后面的工作就交给内核那个软中断守护进程,去触发这个软中断了,其实就是个遍历并查找对应函数的简单过程。
软中断是 Linux 处理一个中断的下半部的主要方式,比如 Linux 某网卡接收了一个数据包,此时会触发一个硬中断,由于处理数据包的过程比较耗时,而硬中断资源又非常宝贵,如果占着硬中断函数不返回,会影响到其他硬中断的相应速度,比如点击鼠标、按下键盘等。
所以一般 Linux 会把中断分成上下两半部分执行,上半部分处理最简单的逻辑,下半部分直接丢给一个软中断异步处理。
比如网卡收到了一个数据包,假如这个网卡型号是 e1000,那对应的硬中断处理函数是,e1000_intr,我们看看它做了什么事情。
static irqreturn_t e1000_intr(int irq, void *data, struct pt_regs *regs) {
__netif_rx_schedule(netdev);
}
static inline void __netif_rx_schedule(struct net_device *dev) {
list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
看到没,后面直接 __raise_softirq_irqoff 丢给软中断就不管了。这个会在后面讲内核接受网络包的全过程中详细讲解
为什么linux挂载完成后不直接让设备文件变成目录
这是为了让设备和设备的文件系统及其内容区分开,否则很难去展示一个设备
挂载的本质
拿到设备的根目录dentry和超级块,至于设备所属的(linux所支持的)文件系统(如inode、dentry创建删除以及write、open等等)的相关操作(相当于驱动,无非就是读写设备的具体函数)已经提前写在linux源码中(看OS支持的一些文件系统)。设备挂载在挂载点后,访问挂载点等价于访问设备的根目录,访问挂载点下的文件等价于访问设备的文件,因为已经有了设备文件系统的根目录dentry和超级块,自然就可以随心所欲地读写创建删除文件了
vfsmount和mount结构体区别
linux旧版本是没有mount的只有vfsmount,后来从vfsmount拆分,使得二者同时存在。一次真正挂载对应一个mount实例,其中struct vfsmount定义的mnt成员是它最核心的部分,记录了此次挂载的外部文件系统的根目录dentry和超级块,而mount额外负责记录挂载点及其所属文件系统即父挂载mount以及mnt_devname即外部文件系统所在块设备的设备文件的路径,如:/dev/dsk/hda1
根文件系统
BootLoader(引导加载程序,uboot比较常见,等价于PC的BIOS)是在操作系统内核运行之前运行。在嵌入式系统中,通常并没有像BIOS那样的固件程序,因此整个系统的加载启动任务就完全由BootLoader来完成,它主要用来初始化处理器及外设,然后把Linux内核加载到内存。Linux内核在完成系统的初始化之后需要挂载根文件系统,然后加载必要的内核模块,启动应用程序。这就是嵌入式Linux系统启动过程Linux引导的整个过程。
根文件系统挂载流程:
- 在内存中创建rootfs超级块,根inode以及名为"/“的dentry结构体(就是熟知的根目录)并进行挂载即结构体之间相互关联(需要注意,rootfs超级块的挂载点mnt_mountpoint即和根即mnt_root都指向刚创建的”/“dentry,这和其他文件系统很不同,虽然一般其他文件系统也都会先创建名为”/"的dentry以作为自己的根目录并读取其所在存储设备的根inode以填充内存中的inode,但是会在后面将mnt_mountpoint重新修改为具体挂载点,而不是文件系统自身的根目录)
- 填充扩充rootfs的文件树,有的人又称为过渡根文件系统或者其他,但本质上还是基于1创建好的根目录,往里面添加一些文件而已(因为没有发生挂载的行为),一般就是通过initramfs和cpio-initrd(cpio格式的包)或者image-initrd镜像装着要添加的文件,然后bootloader将kernel加载到内存时也会把包加载到内存指定位置。一般就是添加下面这些文件:/bin(里面全是shell命令的c语言实现)、/sbin、/init、/dev( 这是rootfs的一大意义,为后面挂载的位于存储设备的真正的文件系统提供了设备文件的概念,这样才有设备文件的驱动,才能使用mount命令因为它需要设备文件的路径作为参数。上面我说真正的文件系统是因为在PC上除了填充文件树之外通常还需要将磁盘或SSD中的ext4等文件系统挂载到rootfs中的某个目录来使用,而在嵌入式中rootfs则有可能是最终(真实)的文件系统,因为没有那么多也不需要那么多资源存放文件,通常会使用busybox等工具将必需和常用的shell命令((资源更节约且实现上更精简,比如不支持一些参数))和文件等打成一个cpio包或者image镜像,然后通过OS解包将包里的这些文件释放到rootfs,本质上就是通过sys_read从指定内存位置读取包内的文件名和目录名和文件内容然后mkdir创建目录和sys_create创建文件,然后sys_write写入到创建的文件中。最后通过启动一个用户级程序init的方式,完成引导进程,代码来自/init。所以,init始终是第一个进程(其进程编号始终为1),而且init进程会调用到/etc/rc.d/rc.local即需要自启动命令的脚本 )、/etc、/lib(放共享库和可加载驱动程序以运行根文件系统中的可执行程序即/bin和/sbin)、/mnt、/proc(为下面提到的proc文件系统提供挂载点,因为下面的proc文件系统虽然在kernel初始化时被初始化了,但是还没有mount的动作将其挂载上去,于是proc超级块的挂载点属性暂时还是指向proc文件系统的根目录,所以此时该目录为空,也无法使用proc文件系统)等
- PC就挂载真正的文件系统,嵌入式就可以停止了
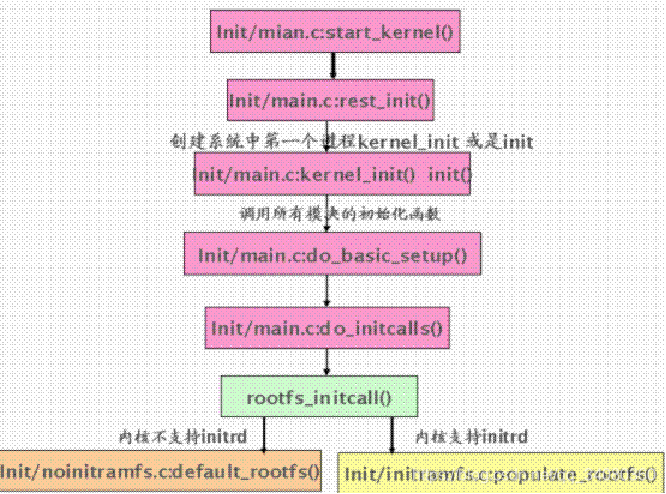
函数调用顺序
start_kernel()->vfs_caches_init() ->mnt_init()
mnt_init()挂载了一个空的rootfs文件系统,并把它的根目录作为内核当前进程的根目录,从而使得这个rootfs的根目录就是./。注:此时是虚拟的rootfs,后面还会指向具体的根文件系统。
mnt_init()源代码如下:
void __init mnt_init(void)
{
...........
init_rootfs(); //向内核注册rootfs
init_mount_tree();//rootfs文件系统的挂载;设置系统current根目录和根文件系统为rootfs, 也就是./挂载点的形成
}
intrid 的常见两种格式处理流程

 cpio-initrd使用根文件系统下的/init来作为init进程
cpio-initrd使用根文件系统下的/init来作为init进程
image-initrd使用根文件系统下的/linuxrc来作为init进程
populate_rootfs函数负责加载initramfs(cpio-initrd) 到根文件系统rootfs,若不是将其释放到/initrd.image.。注:rootfs_initcall(populate_rootfs)
 尝试访问ramdisk_execute_command,默认为/init,如果访问失败,说明根目录上不存在这个文件,则调用prepare_namespace() 。对于initramdisk(image-initrd)和cpio-initrd的情况,都会将虚拟根文件系统释放到根目录。
尝试访问ramdisk_execute_command,默认为/init,如果访问失败,说明根目录上不存在这个文件,则调用prepare_namespace() 。对于initramdisk(image-initrd)和cpio-initrd的情况,都会将虚拟根文件系统释放到根目录。
如果这些虚拟文件系统里有/init这个文件。就会转入到init_post()。
对于image-initrd或者是虚拟文件系统中没有包含 /init的情况,会由prepare_namespace()处理。

prepare_namespace():
用户可以用root=来指定根文件系统,它的值保存在saved_root_name中。
- 如果用户指定了以mtd(内存技术设备)开始的字串做为它的根文件系统。就会直接去挂载。这个文件是mtdblock的设备文件。
- 如果指定的根文件系统是 initrd其本身,直接挂载为根文件系统
- 如果不是进一步处理:调用initrd_load()
initrd_load():
- 建立一个(ROOT_RAM)的设备节点,并将/initrd/.image释放到这个节点中,/initrd.image的内容,就是我们之前分析的image-initrd。
- 如果根文件设备号不是ROOT_RAM0( 用户指定的根文件系统不是/dev/ram0就会转入到handle_initrd()
- 如果当前根文件系统是/dev/ram0. 直接退出。
handle_initrd()先将/dev/ram0挂载,而后执行/linuxrc.等其执行完后,再挂载具体的根文件系统.。
proc伪(内存)文件系统
下面是proc文件系统的inode,可以看出跟常规的inode不同,pid、fd、pde等这些inode不该有的他全有,并且最后面带了一个inode(建立proc的数据与VFS层之间的联系???类似于继承)
struct proc_inode {
struct pid *pid;
int fd;
union proc_op op;
struct proc_dir_entry *pde;
struct inode vfs_inode;
};
union proc_op {
int (*proc_get_link)(struct inode *, struct dentry **,
struct vfsmount **);
int (*proc_read)(struct task_struct *task, char *page);
};
在使用proc之前,我们必须首先初始化并挂载proc
初始化的流程图如下:
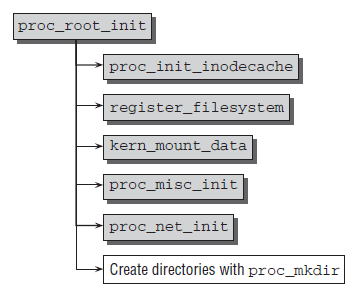
proc_root_init在内核启动初始化时就被调用
void __init proc_root_init(void)
{
proc_init_inodecache();
register_filesystem(&proc_fs_type);
proc_mnt = kern_mount(&proc_fs_type);
proc_misc_init();
proc_net = proc_mkdir("net", NULL);
proc_net_stat = proc_mkdir("net/stat", NULL);
//实现上:创建proc_dir_entry结构体
//并根据"fs"作为名字初始化即proc_dir_entry->name
//并且为该proc_dir_entry分配一个未被使用的inode号!!!!
proc_root_fs = proc_mkdir("fs", NULL);
proc_root_driver = proc_mkdir("driver", NULL);
proc_mkdir("fs/nfsd", NULL);
proc_tty_init();
proc_bus = proc_mkdir("bus", NULL);
}
proc_init_inodecache():为proc_inode创建slab cache,这是proc文件系统的主要部分,通常需要快速创建或销毁(???)
下面是proc_fs_type
static struct file_system_type proc_fs_type = {
.name = "proc",
.get_sb = proc_get_sb,
.kill_sb = kill_anon_super,
};
register_filesystem(struct file_system_type * fs):注册文件系统类型proc,主要是其中调用的find_filesystem(fs->name),原理很简单,就是根据文件系统的类型名,遍历全局文件系统类型链表,如果发现存在相同的文件系统类型名的链表节点就返回该文件系统类型,否则返回全局文件系统类型链表最后一个节点的next空指针
register_filesystem根据find_filesystem(fs->name)的返回值即p,如果p非空即文件系统已存在,则报错,如果p空,说明全局文件系统类型链表中还没有该文件系统类型,于是令当前注册的文件系统类型成为全局文件系统类型链表的最后一个节点
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
p = find_filesystem(fs->name);
if (*p)
res = -EBUSY;
else
*p = fs;
return res;
}
static struct file_system_type **find_filesystem(const char *name)
{
struct file_system_type **p;
for (p=&file_systems; *p; p=&(*p)->next)
if (strcmp((*p)->name,name) == 0)
break;
return p;
}
这时候再看proc_root_init的kern_mount(&proc_fs_type);
struct vfsmount *kern_mount(struct file_system_type *type)
{
return do_kern_mount(type->name, 0, type->name, NULL);
}
所以相当于把字符串"proc"传给了fstype和name,data为NULL
struct vfsmount *
do_kern_mount(const char *fstype, int flags, const char *name, void *data)
{
/*get_fs_type本质还是调用find_filesystem,
根据文件系统类型名返回对应的file_system_type结构体*/
struct file_system_type *type = get_fs_type(fstype);
struct super_block *sb = ERR_PTR(-ENOMEM);
struct vfsmount *mnt;
int error;
char *secdata = NULL;
/*分配一个vfsmount结构体,且根据文件系统类型名初始化mnt_devname即外部文件系统所在块设备的设备文件的路径,在这里可以看成proc文件系统所在块设备的设备文件的路径就是proc*/
mnt = alloc_vfsmnt(name);
/*因为对于proc文件系统的get_sb = proc_get_sb,所以看到
static struct super_block *proc_get_sb(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return get_sb_single(fs_type, flags, data, proc_fill_super);
}
其中proc_fill_super专用于初始化proc文件系统的超级块,将其中的成员属性填充
int proc_fill_super(struct super_block *s, void *data, int silent)
{
struct inode * root_inode;
s->s_flags |= MS_NODIRATIME;
s->s_blocksize = 1024;
s->s_blocksize_bits = 10;
s->s_magic = PROC_SUPER_MAGIC;
s->s_op = &proc_sops;
其中proc_sops是:
---------------------------------------------------------------------
static struct super_operations proc_sops = {
.alloc_inode = proc_alloc_inode,
.destroy_inode = proc_destroy_inode,
.read_inode = proc_read_inode,
.drop_inode = generic_delete_inode,
.delete_inode = proc_delete_inode,
.statfs = simple_statfs,
.remount_fs = proc_remount,
};
---------------------------------------------------------------------
root_inode = proc_get_inode(s, PROC_ROOT_INO, &proc_root);
其中PROC_ROOT_INO为1,proc_root即proc文件系统的根目录如果用proc_dir_entry结构体表示如下:
---------------------------------------------------------------------
struct proc_dir_entry proc_root = {
.low_ino = PROC_ROOT_INO,
.namelen = 5,
.name = "/proc",
.mode = S_IFDIR | S_IRUGO | S_IXUGO,
.nlink = 2,
.proc_iops = &proc_root_inode_operations,
.proc_fops = &proc_root_operations,
.parent = &proc_root,
};
---------------------------------------------------------------------
而proc_get_inode函数就是根据proc的超级块
获取proc文件系统的第ino个inode并利用proc_dir_entry初始化该inode
struct inode *proc_get_inode(struct super_block *sb, unsigned int ino,
struct proc_dir_entry *de)
{
struct inode * inode;
de_get(de);//令de的引用计数即count属性自增
//根据超级块获取第ino个inode,
//实现上:先通过哈希缓存查找是否存在,不在则根据sb和ino分配且初始化一个新的inode
inode = iget(sb, ino);
//PROC_I宏根据结构体proc_inode的成员inode获取到proc_inode本身的起始地址,
//再将proc的根目录de赋值给第1个inode的目录属性
PROC_I(inode)->pde = de;
//利用proc_dir_entry来初始化proc_inode的inode的各种属性
if (de) {
if (de->mode) {
inode->i_mode = de->mode;
inode->i_uid = de->uid;
inode->i_gid = de->gid;
}
if (de->size)
inode->i_size = de->size;
if (de->nlink)
inode->i_nlink = de->nlink;
if (!try_module_get(de->owner))
goto out_fail;
if (de->proc_iops)
inode->i_op = de->proc_iops;
if (de->proc_fops)
inode->i_fop = de->proc_fops;
}
out:
return inode;
}
---------------------------------------------------------------------
root_inode->i_nlink += nr_processes();
//分配且用"/"目录名初始化一个dentry作为根目录,且令根目录的父目录指向自己,
//还要将proc文件系统超级块赋值给根目录的超级块属性,
//然后将根目录的inode指针指向root_inode
s->s_root = d_alloc_root(root_inode);
return 0;
}*/
sb = type->get_sb(type, flags, name, data);
/*接着来看get_sb_single
struct super_block *get_sb_single(struct file_system_type *fs_type,
int flags, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct super_block *s;
int error;
---------------------------------------------------------------------
sget函数:获取到fs_type文件系统类型的且满足需求的超级块。
实现是:遍历文件系统类型的超级块链表(里面都是同一文件系统类型的超级块),
如果匹配到想要的超级块(根据第二个参数即比较函数进行匹配,
这里的proc文件系统只会有一个,超级块也是,
所以compare_single就是简单的return true;,
即遇到proc文件系统类型的超级块链表的第一个超级块就算匹配成功了;
如果没有匹配到,说明处于proc文件系统的初始化阶段,连超级块都还没创建,
因此会分配一个空的超级块结构体并根据你提供的第三个参数即初始化函数进行初始化,
这里set_anon_super就是分配设备号给超级块,
其中主设备号为0(当然也是因为proc文件系统不可能真的来自于外部设备,所以才给一个0的主设备号))
当然每次都会把新创建的超级块挂到对应文件系统类型的链表中
---------------------------------------------------------------------
s = sget(fs_type, compare_single, set_anon_super, NULL);
//如果外部文件系统的超级块指向的根目录还没被创建则使用fill_super为其创建
if (!s->s_root) {
error = fill_super(s, data, flags & MS_VERBOSE ? 1 : 0);
}
//do_remount_sb就是调用超级块s的remount_fs
//但对于proc文件系统的super_operations的remount_fs可以看成直接return没做什么事情
do_remount_sb(s, flags, data, 0);
return s;
}
*/
mnt->mnt_sb = sb;
mnt->mnt_root = dget(sb->s_root);
mnt->mnt_mountpoint = sb->s_root;
mnt->mnt_parent = mnt;
mnt->mnt_namespace = current->namespace;
up_write(&sb->s_umount);
put_filesystem(type);
return mnt;
}
c语言进程虚拟地址空间
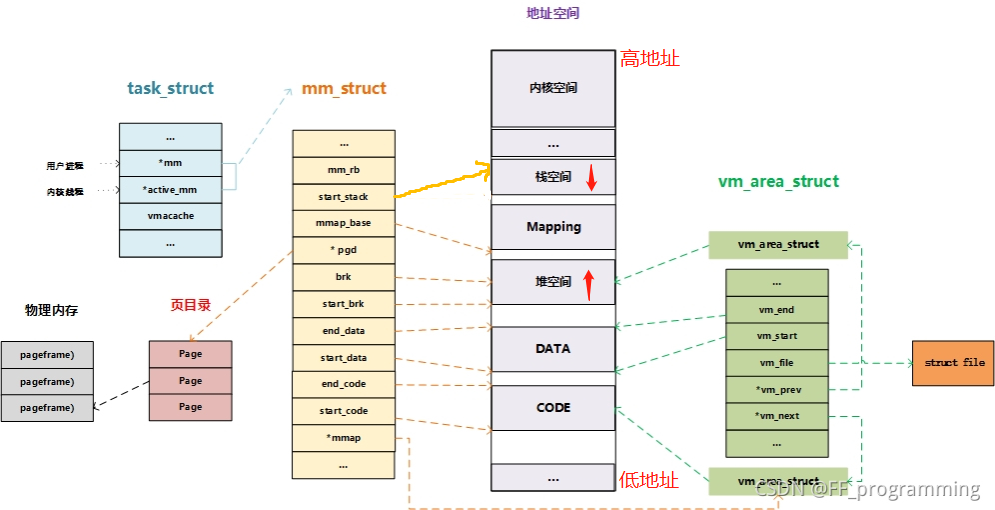 内核代码通过linux链接的文件指定虚拟起始地址0XC0000000即3G,使得内核代码的虚拟地址都大于3G
内核代码通过linux链接的文件指定虚拟起始地址0XC0000000即3G,使得内核代码的虚拟地址都大于3G
所以如果用户态下访问了不属于进程地址空间的内存如下则会爆segmentation fault
#include <stdio.h>
#include <stdlib.h>
int main(){
int* p = (int*)0xC0000fff;
*p = 10;
}
栈帧
每个函数都有专属的栈帧,即栈里面的一段空间。rsp是栈顶寄存器
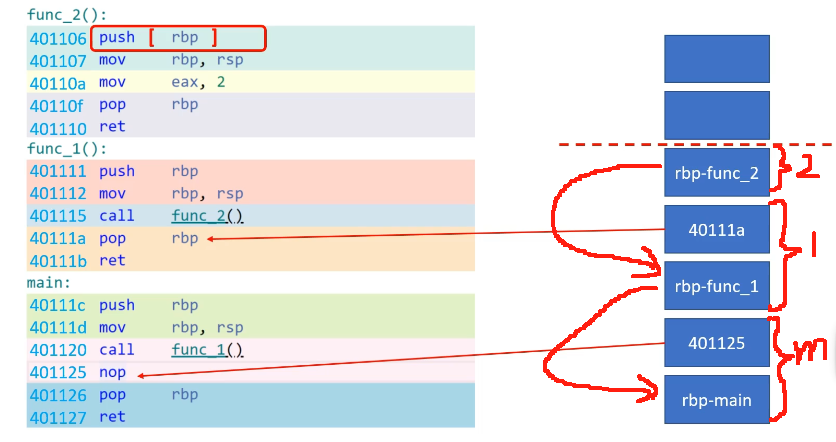
可以看到main的汇编第一句是push rbp,就是调用main函数的函数的栈帧底部,每一个函数的开头都是这一句,意思是将调用本函数的函数的栈帧底部放入栈中。call指令则会将下一个地址压栈然后ip设置为新函数的起始地址然后跳转执行,ret则是将栈顶元素弹出到ip。mov是后方地址的数据送到前方地址
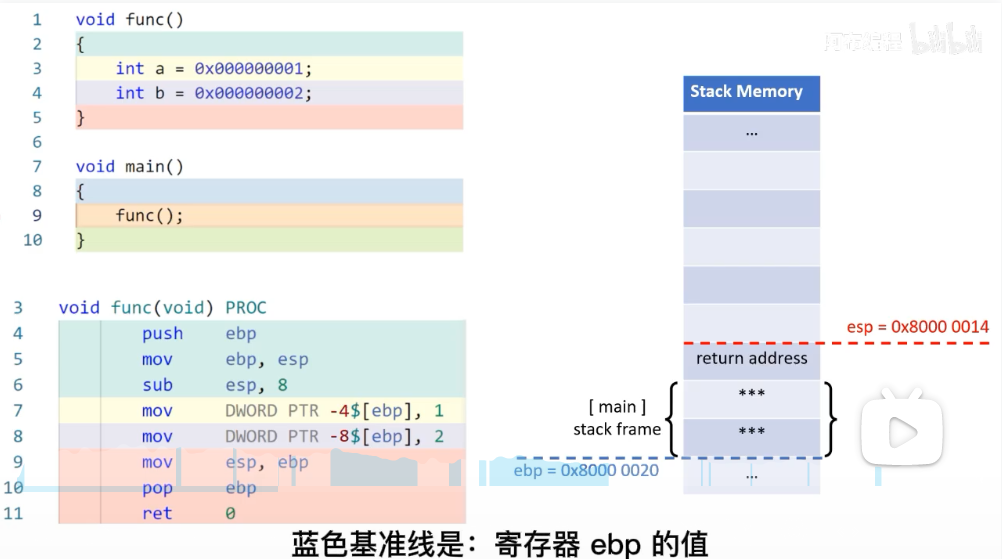
下面这个是函数带有变量的例子,显然栈帧还可以存储当前函数声明的变量,像malloc或new申请的动态变量的内存位于堆而非栈
缺页中断原因
-
导致缺页异常的虚拟地址根本不在进程的“虚存区间”中,段错误。(栈扩展是一种例外情况)
-
地址在“虚存区间”中,但“虚存区间”的访问权限不够;例如“区间”是只读的,而你想写,段错误
-
映射关系没建立
-
映射关系也建立了,但是页面不在内存中。肯定是换出到交换分区中了,换进来再说
-
页面也在内存中。但页面的访问权限不够。例如页面是只读的,而你想写。这通常就是 “写时拷贝COW” 的情况。
-
缺页异常发生在“内核动态映射空间”。这是由于进程进入内核后,访问一个通过 vmalloc() 获得线性地址而引起的异常。对这种情况,需要将内核页目录表、页表中对应的映射关系拷贝到进程的页目录表和页表中。
traps.c—kernel/traps.c
trap_init(void)
作用:
实现:
1.
2.
sched.c
sleep_on(struct task_struct **p)
作用:将当前执行该函数的进程即CURRENT插入到等待队列的队首并阻塞,其中p是等待某个资源的队列的队首的pcb的指针的指针
实现:
- 调用__sleep_on(p,TASK_UNINTERRUPTIBLE);
__sleep_on(struct task_struct **p, int state)
作用:将当前进程插入到等待进程队列的队首指针p(头插),并将队首指针指向当前进程
实现:
- 如果进程0尝试阻塞即if (current == &(init_task.task))则直接报错
- 将当前进程CURRENT插入到等待队列(千万注意!这里的队列其实是栈,只是我们很少说等待栈,反正就是后到的进程先出)的队首p即tmp = *p; *p = current; current->state = state; 这三行代码隐含了一个等待队列(而不是显式),实现十分巧妙,因为当前进程CURRENT执行__sleep_on这种内核函数会专门有自己的内核栈来保存临时变量,因此tmp被保存在CURRENT的内核栈中,于是CURRENT通过tmp能够找到等待队列中的前一个等待进程,此时队首指针p指向当前进程(其中p永远指向队首进程),然后将当前进程状态设置为阻塞态
- 打开中断即汇编sti指令
- 调度其他进程运行即schedule(),这时同样需要该资源的新进程就可以开始执行__sleep_on函数(通常,参考),经历多轮时钟中断和调度后,阻塞事件完成或资源空闲了(会主动调用释放解锁了,比如读写块到缓冲区函数ll_rw_block底层在一开始上锁,当且仅当读写完成才解锁),当等待队列的队首进程被唤醒即wake_up后(唤醒前也是卡在schedule()),继续向下执行,令队首进程的下一个等待进程作为队首即*p = tmp,并且将新的队首进程唤醒即tmp->state=0,依次进行下去,即旧队首唤醒新队首,最后整个等待队列都被唤醒重新一起争夺资源(资源一旦空闲,所有等待进程被唤醒)
wake_up(struct task_struct **p)
作用:将传入的进程p唤醒
实现:
- 将传入的进程p的状态修改为就绪态即(**p).state=0;
sys_pause()
返回值:int
作用:
实现:
- 将当前进程设为可中断的阻塞态即current->state = TASK_INTERRUPTIBLE,意味着当前进程恢复(收到信号)之前不会给调度(对于进程0而言是意外即不受阻塞态影响,依然可以被调度(相当于只有schedule()起作用),因为当没有进程需要运行时,进程0会被调度,于是被称为idle进程,一直执行for(;😉 pause(),相当于不断地找进程来运行尽管可能没有)
- 调度其他程序即schedule()
super.c
超级块全局数组super_block super_block[NR_SUPER]
 设备号为0==空闲超级块槽
设备号为0==空闲超级块槽
get_super(int dev)
返回值: super_block *
作用:从超级块全局数组中获取设备号对应设备的超级块
实现:遍历超级块全局数组,直到当前被遍历超级块的设备号与dev相等
put_super(int dev)
作用:释放(即清空、初始化)超级块全局数组中设备号所对应设备的超级块
实现:
- 对该超级块上锁
- 该超级块的设备号设置为0(作为空闲超级块槽的依据)
- 释放(brelse)i节点位图和逻辑块位图所占用的缓冲区块
- 解锁该超级块,并唤醒等待超级块全局数组空槽的进程
read_super(int dev)
返回值:super_block *
作用:找到超级块全局数组空槽并从该设备读取超级块到空槽中
实现:
- 遍历超级块全局数组(缓存)查找是否已经有此超级块,有则直接返回
- 遍历超级块全局数组找到dev==0的空槽
- 读取即bh = bread(dev,1)超级块并对超级块上锁
- 初始化空槽
- 释放该缓冲区块
- 根据刚才读取的超级块确定i节点位图和逻辑块位图
- 分别读取两个位图到超级块结构体中的s_imap数组和s_zmap数组(每次读一块并且将缓冲头地址赋给数组当前元素)
- 将i节点位图和逻辑块位图中第一个数据块设置为已被占用(不许用,为了后面方便)
- 解锁超级块
sys_umount(char * dev_name)
返回值:int
作用:根据设备名(即dev_name,准确说是全路径名)卸载指定设备。注意!对于设备文件,其inode的i_zone[0]是设备号
实现:
- 根据dev_name全路径名获取(namei)到该设备的inode
- 判断如果不是块设备则释放(iput)设备inode并返回错误
- 释放设备inode
- 判断如果设备号是根设备的则返回错误
- 判断如果读取超级块(get_super)失败或者设备未挂载(super_block->s_imount==0)则返回错误
- 判断如果挂载的节点的挂载数为0(super_block->s_imount->i_mount==0)则返回错误(你说你挂载在某个inode,但是这个inode根本就没有表明自己被挂载了)
namei(char * pathname)
返回值:inode *
作用:根据全路径名获取到该文件的inode
实现:
set_bit(bitnr,addr)
返回值:register int
作用:返回起始于addr内存段中的第bitnr位的值
实现:
register int __res __asm__("ax");
__asm__("bt %2,%3;setb %%al":
"=a" (__res):"a" (0),
"r" (bitnr),"m" (*(addr)));
__res;
内联汇编的输入。
"a"(0), eax = 0;
"r"(bitnr), 任意空闲寄存器(假设为ebx), ebx=bitnr;
"m"(*(addr)), 内存变量*(addr);
内联汇编语句。
bt %2, %3 -> bt ebx, *addr,
检测*addr的ebx位是否为1, 为1则eflag.CF=1, 否则eflag.CF=0;
setb %%al, al=CF;
内联汇编输出。
__res = eax。
__res作为set_bit(bitnr, addr)宏代表表达式的最终值。*/
mount_root()
作用:开始加载文件系统
实现:
- 初始化全局文件打开表的每个元素的引用数为0(file_table[i].f_count=0,文件每被open一次f_count加1)
- 初始化全局超级块数组
- 读取根设备的超级块(p=read_super(ROOT_DEV))
- 从根设备上读取第ROOT_INO个inode(mi=iget(ROOT_DEV,ROOT_INO),其中ROOT_INO==1即根inode)
- ????(mi->i_count += 3)
- p->s_isup = p->s_imount = mi(分别是当前文件系统的根inode以及挂载点的inode,比如现在有根文件系统,插入u盘后需要挂载到根文件系统中,因此此时u盘的超级块中的s_isup是u盘的根inode,s_imount是位于根文件系统的挂载点的inode)
- 将当前进程的当前工作目录和根目录均设置为根inode(current->pwd = mi;current->root = mi)
- 利用位图统计空闲inode数和空闲数据块数
free=0;
i=p->s_nzones;
/*p->s_nzones是当前文件系统的总数据块数
即图中的蓝色部分。
i是int类型,16位*/
while (-- i >= 0)
if (!set_bit(i&8191,p->s_zmap[i>>13]->b_data))
free++;
/*i是当前数据块的序号,8191的二进制是连续13个1,即i&8191取低13位即求出当前数据块在缓冲区块中的偏移,i>>13即求出当前数据块属于第几个缓冲区块,i>>13的值在0~8之间,因为i是16位*/
printk("%d/%d free blocks\n\r",free,p->s_nzones);
free=0;
i=p->s_ninodes+1;
while (-- i >= 0)
if (!set_bit(i&8191,p->s_imap[i>>13]->b_data))
free++;
printk("%d/%d free inodes\n\r",free,p->s_ninodes);
调用链:init.c->sys_setup->mount_root
inode.c
iget(int dev,int nr)
返回值:inode *
作用:从设备号为dev的设备上读取第nr个inode
实现:
_bmap(struct inode * inode,int block,int create)
返回值:int
作用:根据inode的i_data得到该文件逻辑块号为block的全局物理块号。create=1时,如果逻辑块block还未被分配全局物理块号,则按照分配算法分配给该逻辑块,将该逻辑块映射到物理块。create=0时即使未被分配也不管,直接返回初始值。
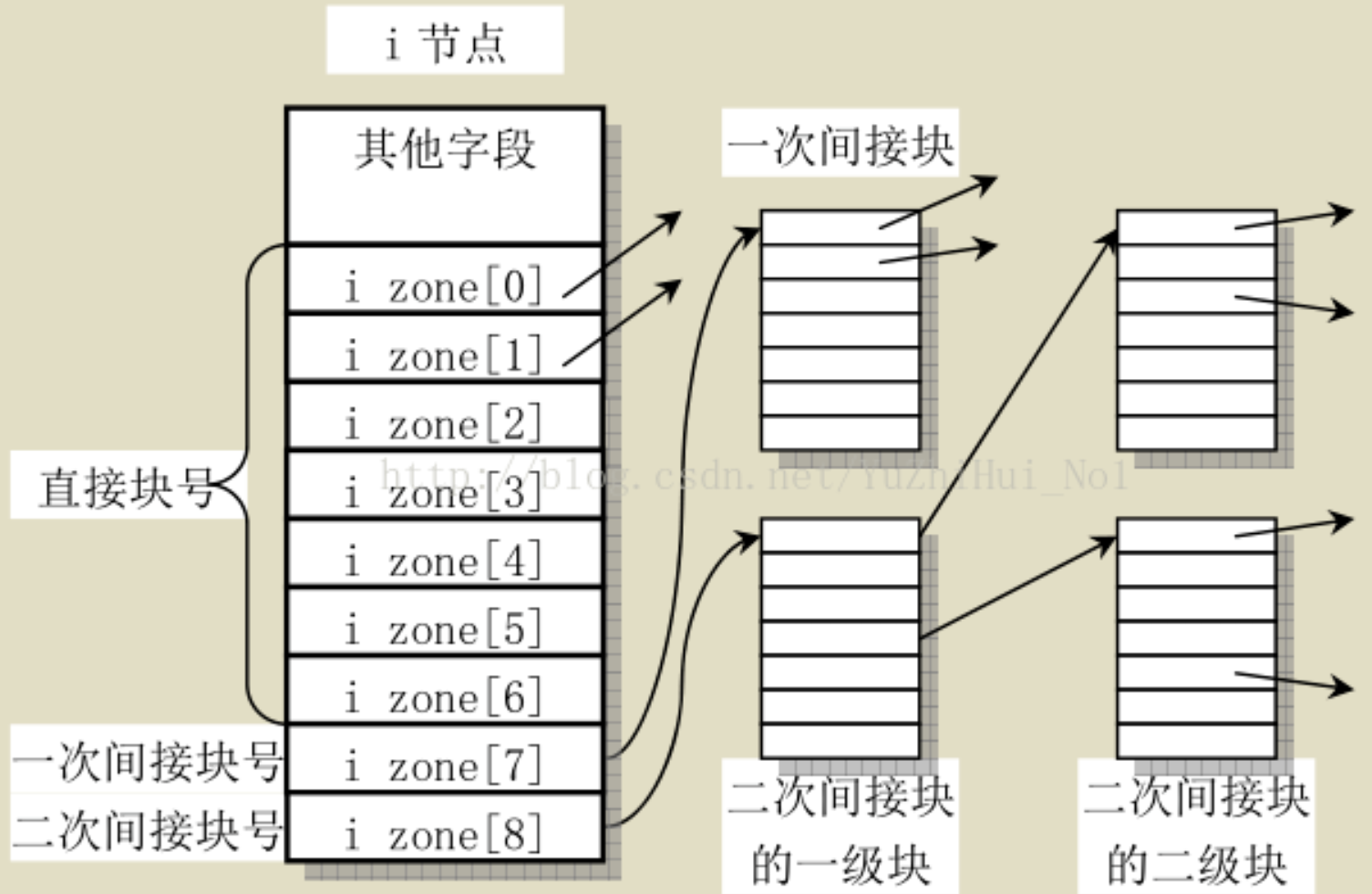
实现:
- 若block在直接寻址的范围内,则直接返回inode->i_data[block]
- 若block在一次寻址的范围内,则先读取一次间址块bh=bread(inode->i_dev,inode->i_data[7]),获取对应全局物理块号i = ((unsigned short *) (bh->b_data))[block];,然后释放缓冲区,最后返回块号i
- 同理若block在二次寻址的范围内,则需要读两次间址块最后返回块号
- 如果create=1且以上过程中发现逻辑块block没有对应的全局物理块号即初始值0(或-1???)则调用minix_new_block(int dev)通过分配算法分配块,然后inode设置为脏
get_empty_inode()
返回值:inode *
作用:从inode缓存表中找到空闲的inode节点并初始化
实现:
- 遍历inode_table,如果当前inode引用计数i_count==0,则符合最低条件(还不是最优),然后继续循环,只有当前inode引用计数i_count==0并且该文件未被修改过即i_dirt以及未被上锁即i_lock,则立即跳出循环,该inode为最优
- 如果找到的空闲inode符合最低条件,但该inode被修改过,则需要先把inode写回磁盘(write_inode(inode)->minix_write_inode(inode)),然后该inode才可以被使用
- 初始化得到的空闲inode即memset(inode,0,sizeof(*inode));
- 将inode引用计数设置为1即inode->i_count = 1;
namei.c—/fs/minix/namei.c
minix_mknod(struct inode * dir, const char * name, int len, int mode, int rdev)
返回值:int
作用:在minix文件系统下创建设备文件。
实现:
- 根据basename在dir中检查该设备文件是否已经存在bh = minix_find_entry(&dir,basename,namelen,&de),已存在则直接返回 文件已存在错误
- 在dir所在设备中找到一个空闲的inode即inode = minix_new_inode(dir->i_dev);,并将inode的idev初始化为所在目录inode的设备号即inode->i_dev = dev;
- 根据传入的mode初始化该inode即inode->i_mode = mode;
- 根据mode判断如果是设备文件(块设备文件或者字符设备文件)则用rdev初始化inode所代表的设备的设备号即inode->i_rdev = rdev;
- 将该inode设为脏即inode->i_dirt = 1;
- 在dir的目录文件中找到空闲目录项并将其目录项名设置name即bh = minix_add_entry(dir,name,len,&de),这里的传入的de被设置为空闲目录项的地址
- 将空闲目录项的inode编号设置为在2所找到的空闲inode即de->inode = inode->i_ino,并将该目录项所在缓冲区设脏即bh->b_dirt = 1;
minix_add_entry(struct inode * dir,const char * name, int namelen, struct minix_dir_entry ** res_dir)
返回值:buffer_head *
作用:在minix文件系统下,只把name加入目录文件dir的目录即minix_dir_entry数组,inode统一被初始化为0
实现:
- 先获取首个(直接索引)逻辑块的物理块号block = dir->i_data[0]
- 读入首个逻辑块即bh = bread(dir->i_dev,block)
- 开始遍历目录文件dir的目录(读入目录文件的内容即minix_dir_entry数组到缓冲区),直到de->inode==0即目录项空闲(如果遍历到最后一个目录项仍不空闲,则选择最后一个目录项的下一个目录项(且修改dir的文件大小和设脏,因为新增了目录项),并且如果目录项的数目刚好占用一个块,则申请一个新的物理块并建立好逻辑块与物理块的映射即block = minix_create_block(dir,i/DIR_ENTRIES_PER_BLOCK),然后读入该新物理块即
bh = bread(dir->i_dev,block)),则把name填入到de->name[]中且缓冲区设脏,minix文件系统对文件名长度进行了限制即MINIX_NAME_LEN=14,如果name的长度超出则截断,没超出则填充0即
for (i=0; i < MINIX_NAME_LEN ; i++)
de->name[i]=(i<namelen)?get_fs_byte(name+i):0; - 将新目录项de(是地址)赋值给res_dir即*res_dir = de;
- 返回空闲目录项所在缓冲区的头部bh
dir_namei(const char * pathname,int * namelen, const char ** name)
返回值:inode *
作用:获取pathname中最底层目录的inode,并且用户传入的name会被赋值为最底层的目录名或者文件名(如/a/b/c得到c)
实现:
- 调用get_dir()获取目录pathname的inode
- 循环遍历pathname,每遇到“/”就令name指向/的下一个字符的地址,最后会得到最底层的目录名(如/a/b/c得到c)
get_dir(const char * pathname)
返回值:inode *
作用:获取目录pathname最底层目录的inode。比如/var/log/httpd,将只返回 log/目录的inode,/var/log/httpd/则返回httpd/的目录
实现:
- 判断pathname第一个字符是否为/,是则代表pathname为绝对路径,令临时变量
inode = current->root,pathname++。否则
inode = current->pwd; - 目录引用数加1即inode->i_count++;
- 依次遍历pathname中的每一个目录,即依次获得两个/之间夹住的目录名,根据该名字thisname和当前父目录的inode有
bh = find_entry(&inode,thisname,namelen,&de)找到该子目录项de即dir_entry类型
释放高速缓冲区bh即brelse()以及inode节点iput()
根据de获得该子目录inode的编号即
inr = de->inode,又根据当前父目录获得设备号idev = inode->i_dev,于是得到该子目录inode即inode = iget(idev,inr),回到3
minix_find_entry(struct inode * dir,const char * name, int namelen, struct minix_dir_entry ** res_dir)
返回值:buffer_head *
作用:根据目录dir的inode找到其下名为name的目录项。其中res_dir存放该目录项,而返回值是该目录项所在高速缓冲区的头部。
实现:
- 根据entries =
(*dir)->i_size / (sizeof (struct minix_dir_entry));得到该目录下目录项的数目 - 先得到第一个逻辑块的对应物理块号
block = (*dir)->i_zone[0] - 读取第一个逻辑块bh = bread((*dir)->i_dev,block)
- 使数据块可以按目录项来遍历de = (struct minix_dir_entry *) bh->b_data;,此时的de是第一个目录项的地址
- 利用目录项的数目entries开始遍历第一个数据块的目录项,如果当前目录项de对应名字和name匹配即minix_match(namelen,name,de),则返回该目录项所在高速缓冲区的头部,以及将de赋值给res_dir。如果不匹配,则de++,并且如果de已经超出当前逻辑块,则根据当前已遍历的目录项数目i求得新的逻辑块号然后根据bmap得到该逻辑块号对应物理块号block = bmap(*dir,i/DIR_ENTRIES_PER_BLOCK),然后读入该物理块并且使数据块可以按目录项来遍历。
open.c—/fs/open.c
sys_open(const char __user * filename, int flags, int mode)
返回值
namei.c—/fs/namei.c
返回值:long
作用:打开文件
实现:
- 从当前进程的文件描述符数组中找到空闲的描述符项并标记为忙即fd = get_unused_fd();
- 调用filp_open函数获取该路径对应文件的file结构体(内部是先获取到inode然后利用inode初始化file结构体)struct file *f = filp_open(tmp, flags, mode);其中filp_open函数本质是依次调用open_namei(filename, namei_flags, mode, &nd);和dentry_open(nd.dentry, nd.mnt, flags);
- 将1.获得空闲的描述符项指向2.获得的file结构体即调用函数fd_install(fd, f);本质是current->files->->fd[fd] = f
dentry_open(struct dentry *dentry, struct vfsmount *mnt, int flags)
返回值:file *
作用: 向内存申请一个file结构体并根据入参初始化
实现:
- 通过slab向内存申请一个file结构体f = get_empty_filp();
- 为其打开文件的方式和???赋值f->f_flags = flags; f->f_mode = ((flags+1) & O_ACCMODE) | FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE; 并令inode = dentry->d_inode;
- 初始化file结构体f即
f->f_mapping = inode->i_mapping;
f->f_dentry = dentry;
f->f_vfsmnt = mnt;
f->f_pos = 0;
f->f_op = fops_get(inode->i_fop);在未来的 sys_read 函数中将会调用 file->f_op 中的成员 read(可见每打开一次文件就有一个file 结构被创建而无论这个文件有多少个进程打开打都指向同一个inode) - 如果f->f_op && f->f_op->open非空,则f->f_op->open(inode,f);
- f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
open_namei(const char * pathname, int flag, int mode, struct nameidata *nd)
返回值:int
作用:根据flag选择将文件路径名代表的文件或其所在的目录填充nd(特别是dentry成员)。作为open打开文件系统调用的关键函数
flags 所能使用的旗标:
1.O_RDONLY 只读打开。
2.O_WRONLY 只写打开。
3.O_RDWR 读、写打开。
4.O_APPEND 每次写时都加到文件的尾端。
5.O_CREAT 若此文件不存在则创建它。使用此选择项时,需同时说明第三个参数mode,用其说明该新文件的存取许可权位。
6.O_EXCL 如果同时指定了O_CREAT,而文件已经存在,则出错。这可测试一个文件是否存在,如果不存在则创建此文件成为一个原子操作。
7.O_TRUNC 如果此文件存在,而且为只读或只写成功打开,则将其长度截短为0。
8.O_NOCTTY 如果pathname指的是终端设备,则不将此设备分配作为此进程的控制终端。
9.O_NONBLOCK 如果pathname指的是一个F I F O、一个块特殊文件或一个字符特殊文件,则此选择项为此文件的本次打开操作和后续的I / O操作设置非阻塞方式。
10.O_NDELAY所产生的结果使I/O变成非阻塞模式(non-blocking),在读取不到数据或是写入缓冲区已满会马上return,而不会阻塞等待。
11.O_SYNC 使每次w r i t e都等到物理I / O操作完成。
12.O_APPEND 当读写文件时会从文件尾开始移动,也就是所写入的数据会以附加的方式加入到文件后面。
13.O_NOFOLLOW 如果参数pathname 所指的文件为一符号连接,则会令打开文件失败。
14.O_DIRECTORY 如果参数pathname 所指的文件并非为一目录,则会令打开文件失败。
实现:
- 如果flag代表了仅打开文件,则调用path_lookup(pathname,lookup_flags(flag)|LOOKUP_OPEN, nd)来让文件路径名代表的文件填充nd(主要是dentry成员),其中lookup_flags(flag)默认返回LOOKUP_FOLLOW。然后跳到ok:即
- 如果flag代表了创建文件,则调用path_lookup(pathname,LOOKUP_PARENT|LOOKUP_OPEN|LOOKUP_CREATE, nd)来让文件路径名对应文件所在的目录填充nd,(暂未发现LOOKUP_OPEN和LOOKUP_CREATE的作用????)
- 到这里说明是要创建文件的,这里通过检查路径名最后分量来确保要创建的是文件而不是目录即if (nd->last_type != LAST_NORM || nd->last.name[nd->last.len]) goto exit;即直接结束。其中nameidata结构体的last成员代表路径最后分量字符串,last_type代表路径最后分量的文件类型如目录或文件等。因为如果要创建目录一般用mkdir而不是open。在正常的路径名中,路径的终点是一个文件名,此时nameidata结构中的last_type由path_lookup设置成LAST_NORM表示最后分量的名字属于文件。但是,也有可能路径名的终点为’.’,"…",也就是说路径的终点实际上是一个目录,此时path_lookup将last_type设置成LAST_DOT、LAST_DOTDO。
- 令dir = nd->dentry即要创建的文件所在的目录,然后尝试在内存散列表以及在其目录nd下寻找该文件是否已存在即dentry = __lookup_hash(&nd->last, nd->dentry, nd),如果不存在那么该函数还会根据入参nd->dentry(作为d_parent成员)和nd->last(作为dentry的名字即文件名)初始化一个新的dentry,但其d_inode为空(相当于在内存创建了dentry但磁盘上还没有任何该dentry的相关信息)。综上dentry必非空
- 如果该文件不存在于目录中即!dentry->d_inode即新建的dentry,则调用vfs_create(dir->d_inode, dentry, mode, nd),该函数主要是调用inode->i_op->create(dir, dentry, mode, nd);跳转到ok即
- 到这里说明文件已存在,检查该文件是否为挂载点即if (d_mountpoint(dentry)),其中d_mountpoint函数就是直接返回dentry->d_mounted(大于0即为挂载点),如果是挂载点但flag为O_NOFOLLOW那也要直接结束,否则不断地循环调用__follow_down(&nd->mnt,&dentry)找到最终的文件(即直到当前dentry不是挂载点),其中__follow_down函数主要是调用mounted = lookup_mnt(*mnt, *dentry);即在mount_hashtable全局挂载数组(记录了所有挂载及其相关信息)找到直接父挂载为mnt且挂载点为dentry的挂载,如果找到则修改mnt和dentry的值为该挂载以及对该挂载的文件系统的根目录引用计数自增,否则不做修改
- 判断上面刚获得的文件是否为符号链接文件即if (dentry->d_inode->i_op && dentry->d_inode->i_op->follow_link)是则跳转到do_link即10.
- 到这里说明不是符号链接文件,可以令nd->dentry = dentry;,然后如果发现该dentry是目录(因为open一般就是打开文件而不是目录)也直接报错结束即if (dentry->d_inode && S_ISDIR(dentry->d_inode->i_mode))
- ok对刚刚获得的nd(打开文件则为路径名对应文件,创建文件则为路径最后分量所在目录下新建的文件,文件名为路径名最后分量)进行权限检查即调用may_open(nd, acc_mode, flag),然后结束
- do_link主要是调用__do_follow_link(dentry, nd);
path_lookup(const char *name, unsigned int flags, struct nameidata *nd)
返回值:int
作用:根据flag选择将文件路径名name代表的文件或其所在的目录填充nd
实现:
- 如果文件路径名name是绝对路径(即’/'开头),则将当前进程使用的文件系统的vfsmount即rootmnt及其根目录即root赋值给nd即nd->mnt = mntget(current->fs->rootmnt);nd->dentry = dget(current->fs->root),其中mntget和dget仅仅是将入参的成员属性count引用计数自增然后返回入参,当然此时nd的值是临时的,用于方便找到目标文件,nd应当代表最后要找的文件或其目录的信息
- 如果name是相对路径,则将当前进程使用的文件系统的当前目录即pwd的信息赋值给nd即nd->mnt =mntget(current->fs->pwdmnt);nd->dentry = dget(current->fs->pwd);
- 将当前进程的总链接发生次数设为0即current->total_link_count = 0
- 调用link_path_walk(name, nd);
link_path_walk(const char * name, struct nameidata *nd)
返回值:int
作用:从nd代表的目录开始寻找文件路径名name对应的文件并将其填充到nd
实现:
- 令unsigned int lookup_flags = nd->flags;然后忽略路径名第一个分量前的任何斜杠即while (*name==’/’) name++;即此时name指向第一个分量字符串的开头
- 获取nd指向的dentry的inode即inode = nd->dentry->d_inode,根据调用该函数的path_lookup函数可知一开始nd指向的dentry是当前进程使用的文件系统的根目录或者其当前工作目录
- 按照逐个字符的方式遍历文件路径名name,在遇到’/‘字符后停止(相当于获取路径中两个’/‘之间的路径分量),用this.name = name记录当前分量(this是qstr结构体的实例,qstr用于记录当前分量的信息),同时可以记录下当前分量的长度即this.len
如果一直向后遍历都没有遇到’/'且下一个字符为空,则说明到达了要找的文件,于是跳到goto last_component;(将flag变成不继续即nd->flags &= ~LOOKUP_CONTINUE,如果lookup_flags没有LOOKUP_PARENT标记,则按照5.处理;否则) - name继续指向下一个分量的首地址即while (*++name == ‘/’)为下一次处理分量做准备。如果文件路径名最后一个字符为’/’,则跳到goto last_with_slashes;即9.
- 能到这里,说明是全路径中间的分量,如果当前分量this.name是’.‘即当前目录,则回到3. 检索下一个路径分量
如果当前分量this.name是’…'即父目录,则调用follow_dotdot(&nd->mnt, &nd->dentry)查找入参nd->dentry目录的父目录并将其修改指向父目录 - 根据this当前路径分量(作为文件名)和其目录nd找到该文件,并将该文件的信息赋值到传入的path结构体next即do_lookup(nd, &this, &next);(仅针对某个目录下寻找文件)
- 检查刚找到的文件是否被其他设备挂载了,是则修改next的mnt成员和dentry为此处最新一次挂载的vfsmount和其根目录即follow_mount(&next.mnt, &next.dentry);
- 如果刚得到的next是符号链接(即inode->i_op->follow_link非空,其中inode = next.dentry->d_inode;),则调用do_follow_link(next.dentry, nd),即返回链接的最终目标的dentry,将next.dentry修改为此dentry(比如/home/xpl/link -> /mnt/disk,则返回/mnt/disk);否则,将nd修改为next指向的dentry作为下一次遍历的目录并原dentry引用计数自减即dput(nd->dentry); nd->mnt = next.mnt;nd->dentry = next.dentry;然后回到2.
- last_with_slashes即路径名最后一个字符为’/’:令lookup_flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY,其中如果最后一个分量对应文件是符号链接文件则LOOKUP_FOLLOW表示前往获取其最终链接的文件;LOOKUP_DIRECTORY帮忙检查刚才获得的文件(即最后分量对应文件)是否为目录即!inode->i_op || !inode->i_op->lookup其中inode = next.dentry->d_inode;,如果不是目录却又以’/'结尾则报错,可以自行ls命令尝试;否则正常返回最后的文件;
- last_component即到达最后一个分量,令路径查找停止(暂未发现哪里用到该标记???)即nd->flags &= ~LOOKUP_CONTINUE;。如果有LOOKUP_PARENT标记,直接跳到11. ,否则根据上面5.6.7.执行,且令inode = next.dentry->d_inode;即最后一个分量对应文件的inode,若此时有LOOKUP_FOLLOW标记且该inode确实为符号链接文件(inode->i_op->follow_link非空)则前往获取其最终链接的文件,没有该标记则令nd指向最后分量对应文件即nd->mnt = next.mnt;nd->dentry = next.dentry;,如果此时有LOOKUP_DIRECTORY标记则检查刚刚的inode即最后分量对应文件是否为目录文件(inode->i_op->lookup非空),不是则报错,否则直接结束该函数
- lookup_parent即要求返回路径名最后分量所在目录,通过忽略跳过10.的操作使得nd->mnt和nd->dentry仍是路径名最后分量所在目录对应的信息,然后直接结束该函数
follow_dotdot(struct vfsmount **mnt, struct dentry **dentry)
作用:查找入参dentry目录的父目录并将其修改为父目录
实现:
1.
2.
do_lookup(struct nameidata *nd, struct qstr *name, struct path *path)
返回值:int
作用:根据入参目录nd,找到其下名为name的文件,并赋值给path(这里的nd代表了名为name的文件所在的目录)
实现:
- 根据dentry哈希值从内存中的dentry哈希表中查找name对应文件是否已存在即struct dentry *dentry = __d_lookup(nd->dentry, name);
- 如果哈希表中没有该文件,则dentry = real_lookup(nd->dentry, name, nd);
- 为入参path赋值为当前nd下的name文件的信息即path->mnt = mnt; path->dentry = dentry;
real_lookup(struct dentry * parent, struct qstr * name, struct nameidata *nd)
返回值:struct dentry *
作用:
实现:
- 根据目录parent尝试在哈希缓存中获取到name文件的目录项即result = d_lookup(parent, name),如果能找到直接返回。其中d_lookup底层调用__d_lookup
- 如果缓存中没有找到,于是先创建dentry结构体并分配内存和初始化即struct dentry * dentry = d_alloc(parent, name);
- 调用具体文件系统的lookup函数查找该dentry即result = dir->i_op->lookup(dir, dentry, nd);
follow_mount(struct vfsmount **mnt, struct dentry **dentry)
返回值:int
作用:寻找最顶层父挂载为mnt,挂载点为dentry的最底层挂载。即寻找某个dentry下最近的一个挂载(即挂载多次中最新的一次挂载),然后将入参mnt和dentry都修改为该最新挂载的vfsmnt和根目录。
比如/mnt/sda挂载一个minix文件系统的设备dev1,/mnt/sda1/home/mnt相当于进入到dev1的/home/mnt下,此时在/mnt/sda1/home/mnt再先后分别挂载一个fat32文件系统的设备dev2和一个ext4文件系统的设备dev3,那么dev1的挂载就是dev2的父挂载,且dev2挂载点是/mnt/sda1/home/mnt即dev1的/home/mnt目录,注意了!!!此时dev2的挂载就是dev3的父挂载,且dev3挂载点是dev2的根目录,即同一个挂载点连续挂载两次,则前者是后者的父挂载,后者挂载点指向前者根目录
实现:
- 检查dentry的d_mounted成员是否大于0,是则代表该文件被其他设备挂载了,不是则直接结束返回
- 递归地查找以当前mnt为父挂载且挂载点在当前dentry的挂载(最多只能有1个)(即struct vfsmount *mounted = lookup_mnt(*mnt, *dentry))直到当前当前dentry没有被挂载(即dentry的d_mounted成员小于等于0),其中如果当前mnt和dentry下没有挂载即mounted空则直接结束返回,否则当前mnt和dentry引用计数自减即mntput(*mnt)和dput(*dentry),且分别修改为刚才得到的mounted和mounted->mnt_root,然后继续查找以当前mnt为父挂载且挂载点在当前dentry的挂载(综上即在入参mnt和dentry下找到最新的一次挂载)
lookup_mnt(struct vfsmount *mnt, struct dentry *dentry)
返回值:vfsmount *
作用:先介绍mount_hashtable数组,该数组每个元素指向一个head,其中每个head指向代表某个哈希值的双向循环链表(不同head代表不同哈希值的链表),该链表每个节点都是vfsmount结构体,它们根据父挂载的vfsmount和自己的挂载点dentry得到哈希值相同(根据某个算法得到,不同的vfsmount和dentry可能哈希值相同即在一个链表上,但其中最多只有一个vfsmount的mnt_parent为mnt且mnt_mountpoint为dentry)。综上,该函数作用就是返回一个mnt_parent为mnt且mnt_mountpoint为dentry的vfsmount。即直接父挂载为mnt且挂载点为dentry的挂载
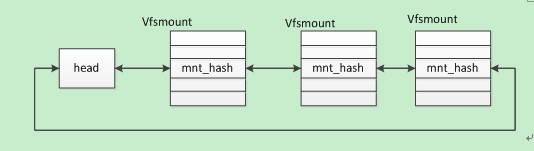
实现:
- 根据入参父挂载mnt和挂载点dentry和某个哈希算法求得哈希值,再根据该哈希值在mount_hashtable找到head即struct list_head * head = mount_hashtable + hash(mnt, dentry);
- 根据head遍历链表直到找到一个mnt_parent为mnt且mnt_mountpoint为dentry的vfsmount,为其引用计数自增即mntget§且将其返回
do_follow_link(struct dentry *dentry, struct nameidata *nd)
返回值:int
作用:入参dentry指向当前路径分量对应文件(一般是一个符号链接文件即i_op->follow_link非空),nd指向该分量所在目录。作用是找到dentry链接的文件。
实现:
- 如果当前进程嵌套链接(链接后的文件还是符号链接文件)深度太深即current->link_count >= MAX_NESTED_LINKS(为5)则直接退出报错
- 如果当前进程总共发生过的链接次数过多也直接推出报错,即current->total_link_count >= 40
- 当前进程link_count、total_link_count、nd的depth自增,紧接着调用__do_follow_link(dentry, nd);再令link_count、nd的depth自减,这么先加后减是为了记录递归深度,因为有如下调用链__do_follow_link->__vfs_follow_link->link_path_walk->do_follow_link即回到本函数,也就是会发生递归链接。最终dentry链接的文件存放在nd中
__do_follow_link(struct dentry *dentry, struct nameidata *nd)
返回值:int
作用:入参dentry指向当前路径分量对应文件(一般是一个符号链接文件即i_op->follow_link非空),nd指向该分量所在目录。作用是找到dentry链接的文件并存放在nd中。
实现:
- 更新与要解析的符号链接关联的索引节点的访问时间
- 调用dentry所属具体文件系统的follow_link函数即dentry->d_inode->i_op->follow_link(dentry, nd);其中follow_link函数读取符号链接文件存储的路径字符串并存放到dentry所属目录nd的saved_names成员中即nd->saved_names[nd->depth]
- 获取该路径字符串即char *s = nd_get_link(nd);并调用__vfs_follow_link(nd, s);即根据该新路径找到其对应文件并存放在nd中
__vfs_follow_link(struct nameidata *nd, const char *link)
返回值:int
作用:入参nd是符号链接文件所在目录,link是符号链接文件存放的路径。比如符号链接文件/home/tmp/kjl中存放着路径/root/bin,则nd是tmp目录,link是/root/bin。作用是(尽量利用nd加速)找到新路径link对应文件。在这里nd相当于缓存
实现:
- 如果新路径link是绝对路径,则说明和nd毫无关系,无法利用nd加速寻找路径,于是直接释放该nd内的成员变量即path_release(nd)该函数就是dput(nd->dentry);mntput(nd->mnt),然后将当前进程使用的文件系统的vfsmount即rootmnt及其根目录即root赋值给nd即nd->mnt = mntget(current->fs->rootmnt);nd->dentry = dget(current->fs->root),其中mntget和dget仅仅是将入参的成员属性count引用计数自增然后返回入参,当然此时nd的值是临时的,用于方便找到目标文件,nd应当代表最后要找的文件或其目录的信息(这里相当于path_lookup的1.)
- 如果新路径link是相对路径,比如’./tmp/bin’,则此时’.'代表着符号链接文件所在目录即nd,此时nd相当于缓存使得不必重新再去找nd,可以为后面寻找新路径文件实现加速,所以nd也就不必清空了
- 调用link_path_walk(link, nd);获取新路径对应文件且存放在nd中
sys_mknod(const char * filename, int mode, int dev)
返回值:int
作用:可以基于任意文件系统创建设备文件(体现VFS)。与sys_creat(创建普通文件,底层调用的是sys_open)差不多,不同在于sys_mknod可以填写设备号参数即dev。
实现:
- 判断是否为超级用户suser(),不是则不执行直接返回
- 获取最底层目录的inode即
dir = dir_namei(filename,&namelen,&basename),
basename被赋值为最底层的目录名或者文件名(比如filename是/dev/usb,则dir是dev/目录的inode,basename是usb) - 判断dir的写权限,无则不执行直接返回
- 判断dir是否有mknod的函数指针即
if (!dir->i_op || !dir->i_op->mknod),无则不执行直接返回 - 调用dir的mknod函数(体现VFS)即dir->i_op->mknod(dir,basename,namelen,mode,dev);(假如磁盘是minix文件系统,那么dir->i_op->mknod就是minix_mknod)
bitmap.c—/fs/minix/bitmap.c
minix_new_block(int dev)
返回值:int
作用:从设备号为dev的设备中找到空闲的数据块并返回该块在整个设备的块号
实现:
- 从dev设备中获取超级块即sb = get_super(dev)
- 通过遍历dev设备的数据块位图,找到空闲的数据块即j=find_first_zero(bh->b_data)然后置为占用(且缓冲区设为脏)
- 获取空闲数据块在整个设备中的全局编号j += i*8192 + sb->s_firstdatazone-1;
- 读入该空闲数据块即bh=getblk(dev,j)
- 将缓冲区的空闲数据块清0即clear_block(bh->b_data),并将缓冲区设为脏
- 返回空闲数据块在整个设备中的全局编号j
minix_new_inode(int dev)
返回值:inode *
作用:在minix文件系统下,在磁盘找到空闲的inode并初始化
实现:
- 从inode缓冲表中获得一个空闲inode即inode=get_empty_inode()
- 根据参数dev即设备号初始化得到的inode的超级块指针即
inode->i_sb = get_super(dev) - 根据刚刚得到的超级块指针可以得到8个inode位图的缓冲区地址(minix文件系统的磁盘的inode位图和数据块位图均占用8个缓冲块即8M),依次遍历这8个缓冲区,对于每个缓冲区遍历每个位 直到找到第一个为0的位即find_first_zero(bh->b_data)相当于找到磁盘中空闲的inode
- 将刚刚在inode位图中找到的空闲位设置为1,即被占用
- 将缓冲区设置为脏使得刚刚在缓冲区的inode位图的空闲位设置为1能写回磁盘即bh->b_dirt = 1;
- 初始化该inode,inode设置为脏,inode的全局编号(即在磁盘的inode数组的第几个)根据3也可以确定下来,其中最重要的是将minix文件系统对inode的操作函数指针赋值给该inode,即inode->i_op = &minix_inode_operations;
inode.c
minix_write_inode(struct inode * inode)
返回值:inode *
作用:将传入的minix文件系统的inode标记为脏
实现:
- 找到传入的inode所在的物理磁盘块(
block =
2 +
inode->i_sb->s_imap_blocks + inode->i_sb->s_zmap_blocks +
(inode->i_ino-1)/
MINIX_INODES_PER_BLOCK;)
并且通过bh=bread(inode->i_dev,block)读入这个块,然后根据bh->data得到该minix_inode即(raw_inode =
((struct minix_inode *)bh->b_data) +
(inode->i_ino-1)%MINIX_INODES_PER_BLOCK;)
这里必须要先把inode所在块读入而不是直接写inode到磁盘,因为内存与磁盘的交互是缓冲块,只有inode这一小部分的内容(还不够一个块的大小)那直接写回就会丧失了其余部分 - 将传入的通用inode中的属性赋值给minix_inode的对应属性(由于raw_inode是bh->b_data的地址,所以raw_inode被赋值的时候缓冲区内容也被修改了)
- 如果传入的inode是设备文件的(块设备文件或者字符设备文件),则只需要赋值首个块号即raw_inode->i_zone[0] = inode->i_rdev;(inode有i_dev和i_rdev,对于普通文件的i_dev表明该文件所在磁盘的设备号,对于设备文件的i_rdev表明该设备的设备号)。否则(普通文件的inode)需要赋值每个索引块指明文件所在物理块的位置。
- 将缓冲区设置为脏即bh->b_dirt=1(原因如第2点),将inode设置为未修改即inode->i_dirt=0(因为已经为该inode修改完成)
minix_create_block(struct inode * inode, int block)
返回值:int
作用:在inode中获取第block个逻辑块的物理块,如果发现该逻辑块还没有被分配物理块,则通过遍历数据块位图找到空闲的物理块分配给该逻辑块
实现:
- 调用_bmap(inode,block,1);
buffer.c
brelse(struct buffer_head * buf)
作用:当前进程释放对缓冲区的引用
实现:
- 等待缓冲区解锁即wait_on_buffer(buf);
- 引用数减1即buf->b_count–
- 唤醒缓冲区等待队列的首进程wake_up(&buffer_wait);
wait_on_buffer(struct buffer_head * bh)
作用:令当前进程等待缓冲区资源。如果缓冲区无人占用则无需等待,否则将当前进程加入到该资源的等待队列并阻塞
实现:
- 关中断,确保执行2的时候只有一个进程访问资源的锁,否则一旦锁空闲,所有进程都不阻塞了
- 循环判断资源是否被上锁占用了,是则将当前进程加入到该资源的等待队列并阻塞即
while (bh->b_lock) sleep_on(&bh->b_wait); - 开中断
bread(int dev,int block)
返回值:buffer_head *
作用:将设备号为dev的设备中的第block块数据读入到缓冲区并返回该缓冲区
实现:
- 若指定块之前已经被读入到某个缓冲区,则直接返回;否则找到一个空闲缓冲区并用dev和block初始化即bh=getblk(dev,block)
- 如果bh->b_uptodate==1表明缓冲区中的内容是最新的,则直接返回
- 否则读入该块以更新缓冲区的内容即ll_rw_block(READ,bh);
- 等待缓冲区解锁即wait_on_buffer(bh);
- 返回缓冲区
BADNESS宏定义
定义:BADNESS(bh) (((bh)->b_dirt<<1)+(bh)->b_lock)
返回值:char(但是数字)
作用:分配空闲缓冲区时衡量缓冲区的好坏(空闲)程度。同样没上锁的两个缓冲区,被修改过的那个是更坏的缓冲区(2)。同样没被修改过的两个缓冲区,上锁的那个是更坏的缓冲区(1)。既被上锁还被修改过则是最坏的缓冲区(3),既没被上锁也没被修改过则是最好的缓冲区(0)(b_dirt和b_lock的值只会为0或1)。
getblk(int dev,int block)
返回值:buffer_head *
作用:返回装有设备号为dev的设备中块号为block的内容的缓冲区
实现:
- 通过哈希值看指定块是否已存在即
bh = get_hash_table(dev,block),bh是最终要返回的缓冲区 - 循环遍历空闲缓冲区链表(双向链表)free_list,如果当前缓冲区的被引用数b_count>0,则说明缓冲区正在被使用(???那为什么还把它放进空闲缓冲区链表???),看下一个空闲缓冲区。如果当前缓冲区空闲且在此之前未找到空闲缓冲区即bh==NULL,或者当前缓冲区比已找到的空闲缓冲区bh好(BADNESS(tmp)<BADNESS(bh)),则令当前缓冲区作为已找到的空闲缓冲区即bh = tmp,如果当前缓冲区不仅比已找到的空闲缓冲区bh好而且是完全空闲即BADNESS(tmp)==0,则直接退出循环,否则一直遍历到表尾
- 如果遍历完后bh仍为空,说明没有空闲缓冲区或者所有缓冲区的引用数都>0,则当前进程阻塞等待即加入到空闲缓冲区资源的等待队列的队首sleep_on(&buffer_wait),直到被唤醒(有空闲缓冲区了),则再次回到2执行(goto语句)
- 到了这里说明已经找到空闲缓冲区了即bh!=NULL,开始等待缓冲区解锁即wait_on_buffer(bh)(???我对这里的空闲的定义很模糊???我猜测free_list链表不一定全是空闲缓冲区,甚至所有缓冲区都一直在free_list中,只是被占用会改变它在链表中的位置,比如会靠后一些)
- 如果被唤醒后缓冲区引用数>0,则再次回到2执行
- 循环检查缓冲区是否被修改过,是则将其写回设备,并再次等待缓冲区解锁,然后执行5,然后再次检查
- 执行到这里的时间已经过去很久,可以通过遍历检查是否其他进程已经读入了find_buffer(dev,block),是则返回
- 初始化得到的空闲缓冲区。占用该缓冲区即bh->b_count=1,不必写回磁盘即bh->b_dirt=0,未更新bh->b_uptodate=0;
- 从缓冲区哈希链表数组hash_table和空闲链表freelist中移除该缓冲区(二者都是链表移除节点的方式)即remove_from_queues(bh);
- 初始化缓冲区对应的设备号和块号即bh->b_dev=dev;bh->b_blocknr=block;
- 将该缓冲区重新插入到空闲链表的尾部以及哈希链表数组的头部
ll_rw_block.c
ll_rw_block(int rw, struct buffer_head * bh)
作用:根据读写标记rw在缓冲区和块设备之间进行读或写(一个缓冲区的内容)
实现:
- 检查主设备号是否超出系统自带的块设备管理数目即NR_BLK_DEV,是则直接返回
- 根据主设备号检查当前设备在系统自带的块设备管理数组中是否有对应请求函数即request_fn,是则直接返回
- 向设备发起请求即make_request(major,rw,bh);
make_request(int major,int rw, struct buffer_head * bh)
作用:从全局request数组找到空闲项然后创建设备读写请求项并插入设备请求队列
实现:
- 对缓冲区上锁即lock_buffer(bh);
- 如果读写标记rw为写而缓冲区未被修改过(即rw == WRITE && !bh->b_dirt)则直接解锁返回
- 如果读写标记rw为读而缓冲区与磁盘同步(即rw == READ && bh->b_uptodate)则直接解锁返回
- 若rw是读,则将临时请求指针变量req指向全局request数组的末尾即req = request+NR_REQUEST,若rw是写,则指向3分之2处即req = request+((NR_REQUEST*2)/3),用于等一下的自后向前遍历(对于全局request数组即struct request request[NR_REQUEST],后3分之1属于读请求,前面的3分之2属于写请求)
- 自后向前遍历request数组即while (–req >= request),找到空闲的request项即req->dev<0则break(因为读请求从最后一项开始遍历,因此体现出读优先,更容易找到空闲项)
- 如果没找到空闲request项即req < request则当前进程阻塞并加入到等待队列(本质是栈)即sleep_on(&wait_for_request),阻塞完成后才回到2重新继续向下执行
- 找到空闲request项后开始根据缓冲区进行初始化即req->dev = bh->b_dev,req->cmd = rw,req->buffer = bh->b_data,req->waiting = NULL,req->bh = bh,
req->next = NULL,因为linux中1个逻辑块等于2个扇区即req->nr_sectors = 2,所以当前逻辑块所在块号乘2等于所在扇区即req->sector = bh->b_blocknr<<1 - 将读写请求项插入到设备请求队列即add_request(major+blk_dev,req)
add_request(struct blk_dev_struct * dev, struct request * req)
作用:使用C-SCAN电梯算法将当前请求req请求插入到请求队列
实现:
- 关中断,保证读写请求队列的互斥
- 将对应缓冲区的脏位清空即req->bh->b_dirt = 0;
- 判断当前要使用的设备是否已经有请求了即
if (!(tmp = dev->current_request)),没有则令当前请求作为设备的当前请求(第一个请求)即dev->current_request = req,然后开中断,调用块设备的具体的请求处理函数(dev->request_fn)(),linux0.95提前为硬盘、软盘、虚拟硬盘、tty提供了请求处理函数和驱动(比如硬盘的则在系统初始化的时候调用hd_init将本就写好的请求处理函数注册到blk_dev数组的硬盘项) - 如果目前该设备已经有请求项在等待,则tmp相当于第一个请求项,从tmp开始向后遍历,如果req->sector < tmp->next->sector < tmp->sector
(sector是扇区号)或者
tmp->sector < req->sector < tmp->next->sector,则直接跳出循环然后插入到tmp和tmp->next之间。
核心思想是:如果当前遍历到的tmp的下一步在向小的方向(temp->next)移动且req的比它们两都更小,则tmp下一步去req,req下一步才去next; 如果当前遍历到的tmp的下一步在向大的方向移动且req的恰好在它们两的之间,则tmp下一步去req,req下一步去next
磁臂初始移动方向(教科书通常说规定为某某方向)在linux的实现中由磁臂当前停留的磁道和进来的第一个请求决定 - 开中断
read_write.c
sys_write(unsigned int fd,char * buf,unsigned int count)
返回值:int
作用:
实现:
1.
2.
hd.c
hd_init()
作用:系统初始化时初始化硬盘相关的内容
实现:
- 向内存中的块设备数组注册硬盘的请求处理函数即blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST该宏定义即do_hd_request(),MAJOR_NR在hd.c中是3(在ramdisk.c虚拟硬盘是1,floppy.c软盘是2),DEVICE_REQUEST也是同理
- 设置磁盘中断号及其处理函数set_intr_gate(0x2E,&hd_interrupt);
- 往几个 IO 端口上读写即outb,允许硬盘控制器发送中断请求信号
do_hd_request()
作用:处理硬盘读写请求队列中的当前(首个)请求
实现:
- 检查当前要处理的第一个请求合法性,比如检查主设备号是否为硬盘主设备号3,检查请求对应的缓冲区是否上好锁了,没锁旧调用panic使之死机
- 获取当前请求的次设备号即dev = MINOR(CURRENT->dev),以及请求的扇区号即block = CURRENT->sector(这里的block可能会有误解,把它理解为扇区号就是了)
- 判断次设备号是否超出分区数,以及扇区号是否超出倒数第二个扇区(因为linux按块为单位读取,而一个块是两个扇区大小,所以不能超过倒数第二个扇区)即if (dev >= 5*NR_HD || block+2 > hd[dev].nr_sects),超出则终止请求即end_request(0);
(在系统初始化时会调用sys_setup(void * BIOS),其中会根据硬件检测来初始化硬盘数目即NR_HD以及各硬盘的分区情况即struct hd_struct hd[5*MAX_HD],其中MAX_HD为2,每块磁盘占用5个项,其中的第1项代表整个硬盘的物理起始扇区号、分区扇区总数(物理磁盘),2~5项代表各个分区的物理起始扇区号、分区扇区总数(可以理解为4个逻辑磁盘),一个硬盘的各个分区分别使用不同的次设备号,整个硬盘也要单独占用一个次设备号,linux0.95最多允许使用两个硬盘,它们的主设备号相同(3)) - 将当前请求的扇区号加上dev对应分区的起始扇区号即block += hd[dev].start_sect;
- 根据次设备号求得其属于第几块硬盘即dev /= 5,根据3的判断可知次设备号的范围是0~9,其中0~4分配给第二块硬盘及其分区,5~9分配给第二块硬盘及其分区
- 请求所在扇区号block除以每磁道扇区数hd_info[dev].sect,得到商放回block,余数放在sec;再将刚才的block除以硬盘磁头数hd_info[dev].head,得到商放在cyl,余数放在head。
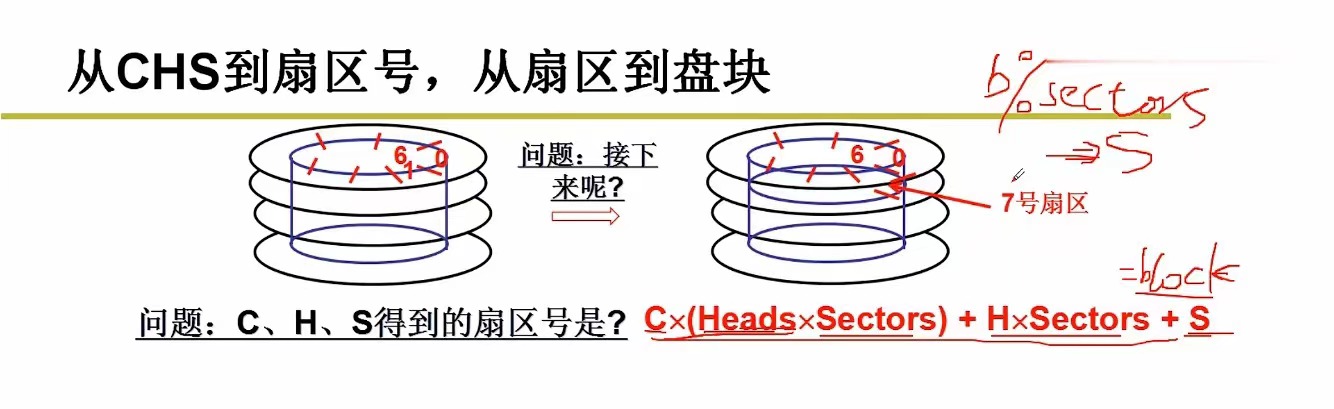
(我们只需要给出磁头号,柱面号以及所在柱面的扇区号,磁盘控制器即可帮助我们找到指定扇区,需要注意,这里的所在柱面的 扇区 和指定 扇区 不同,指定扇区的编号由请求的块号乘2得来,所在柱面的扇区号在1~hd_info[dev].sect,即不同盘面的扇区号都是从1~hd_info[dev].sect编号。我们之前在操作系统层面上将磁盘抽象为多个逻辑块,直觉上相邻的逻辑块(扇区)也应该快速地访问到,于是我们想到以下的全局编号(相对于磁盘每个盘面局部地为扇区编号)方式,将逻辑上的n个块即2n个扇区的逻辑扇区号0~2n-1映射到磁盘上的扇区
 假设先使用完里面的柱面,再使用外面的。
假设先使用完里面的柱面,再使用外面的。
每个盘面都分别有磁头
如上图,0到6号扇区是连续的,这无需寻道的开销,6到7号扇区也是连续的,即比如要同时访问6和7号扇区,刚访问完6号,只需继续旋转,仍不需要寻道,只是此时由第二个(自上而下数)磁头读取内容
根据这种编号方式,我们可以得到上图中的红色公式(其中Heads是磁头数目,Sectors是每磁道扇区数),即假设已知磁盘原生访问方式的柱面号C(磁道号)、磁头号H、扇区号S,如何求出逻辑扇区号(逻辑块号×2),这样通过倒推,我们又可以知道如何通过逻辑扇区号知道柱面号、磁头号、扇区号。
比如对于扇区号,
因为
b
l
o
c
k
=
(
C
×
H
e
a
d
s
+
H
)
×
S
e
c
t
o
r
s
+
S
block=(C \times Heads + H) \times Sectors + S
block=(C×Heads+H)×Sectors+S
于是有
S
=
b
l
o
c
k
%
S
e
c
t
o
r
s
S=block \% Sectors
S=block%Sectors
这里需要注意,S<Sectors(因为S值域是[0,Sectors-1]),于是才能有上式,否则不严谨
此时令
b
l
o
c
k
=
b
l
o
c
k
/
S
e
c
t
o
r
s
=
C
×
H
e
a
d
s
+
H
block=block/Sectors=C \times Heads + H
block=block/Sectors=C×Heads+H
于是有
C
=
b
l
o
c
k
/
h
e
a
d
s
C=block/heads
C=block/heads
又有
H
=
b
l
o
c
k
%
h
e
a
d
s
H=block\%heads
H=block%heads
同理前提是H<Heads
)
7. 实际上磁盘原生访问方式的扇区号从1开始,所以求得的扇区号最后要加1
8. 要读写的扇区数nsect = CURRENT->nr_sectors,其实就是2
9. 如果是写请求即CURRENT->cmd == WRITE,向硬盘控制器端口发送写命令即hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr),其实就是根据寄存器所在地址以及要填充的内容来调用outb,其中&write_intr是执行完写操作后发生中断,然后中断处理函数内调用的函数的地址(反正就是中断后会被执行的函数)。然后循环3000次不断读入硬盘的状态位,等待硬盘准备好接收数据即
for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++),如果r一直为0,表明在规定时间内磁盘仍未准备好,则调用读写硬盘失败处理函数即bad_rw_intr。准备好则在汇编层面循环(rep)不断地向同一个数据端口HD_DATA输出缓冲区的内容(????),每次输出2个字节(outsw),重复256次就刚好是512字节即半个缓冲区一个扇区的大小即port_write(HD_DATA,CURRENT->buffer,256)的底层实现,处理完一个扇区后发起中断间接调用到write_intr,于是会再一次调用port_write,直至–CURRENT->nr_sectors=0为止
10. 如果是读请求则只需要向硬盘控制器端口发送读命令即hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);然后等着中断到来就好了,届时会进入到read_intr函数处理
write_intr
作用:每写完一个扇区后的中断处理函数(确切地说是中断处理函数调用到了这个函数,磁盘中断发生并不是直接调用该函数的,而是通过一些分支间接调用到了)
实现:
- 检查硬盘执行命令后的状态,0为ok,1为出错并return
- 判断是否还有要写的扇区即if (–CURRENT->nr_sectors),由于一个块=一个缓冲区=2个扇区,所以通常这个if成立,于是进行第二次读写扇区,先修改当前请求的信息即CURRENT->sector++;CURRENT->buffer += 512,然后再一次发送写命令port_write(HD_DATA,CURRENT->buffer,256)并return
- 如果当前请求已经处理完,没有还要写的扇区,则为当前请求善后即end_request(1),将请求对应的缓冲区的更新位置为1,然后解锁该缓冲区,唤醒等待该请求项的进程队列即wake_up(&CURRENT->waiting)以及等待空闲请求项的进程队列即wake_up(&wait_for_request);,将当前请求项的dev设为-1表示请求项空闲,并且更新当前块设备的当前请求即CURRENT = CURRENT->next;
- 处理新请求即do_hd_request();
read_intr
作用:每读完一个扇区后的中断处理函数,具体地说,是发送读命令给磁盘控制器后,磁盘会将一个扇区的数据送到它自己的缓冲区,并发起一次中断然后调用到read_intr
实现:
- 检查硬盘执行命令后的状态,0为ok,1为出错并return
- 将磁盘缓冲区中的一个扇区(512字节)的内容读到buffer中即port_read(HD_DATA,CURRENT->buffer,256);
- 缓冲区偏移为下次磁盘缓冲区数据到达而读数据作准备即CURRENT->buffer += 512; 扇区号加1即CURRENT->sector++,使得即使当前读扇区发生错误,重试的时候还可以继续(有重试次数限制)
- 判断是否还有要写的扇区即if (–CURRENT->nr_sectors)
sys_setup(void * BIOS)
返回值:int
作用:
实现:
- 根据系统提供的BIOS地址(里面是通过检测得到的各种硬件参数)读入其中硬盘的参数到hd_info全局硬盘参数数组(只有2项)中,比如
hd_info[drive].cyl = *(unsigned short *) BIOS。如果只有一个硬盘,那么第二个硬盘的参数全设0
(理论上可以直接修改config.h头文件,在其中指明所使用的硬盘参数,比如定义两个硬盘的参数#define HD_TYPE { h,s,c,wpcom,lz,ctl },{ h,s,c,wpcom,lz,ctl },那么全局硬盘参数数组struct hd_i_struct hd_info[] = { HD_TYPE }被修改为我们定义的参数,不必由系统来检测了) - 根据(1)第二个硬盘参数是否为0可知电脑中的硬盘个数即NR_HD
- 分别初始化NR_HD个硬盘的物理盘的起始扇区号(均设0)和扇区总数即hd[i*5].nr_sects =
hd_info[i].head*hd_info[i].sect*hd_info[i].cyl,每个硬盘占用5项,第一项是物理盘的参数,二~五项是逻辑盘的参数
struct hd_struct {
long start_sect;
long nr_sects;
} hd[5*MAX_HD]={{0,0},}; - 读取(bh = bread(0x300 + drive*5,0))每一个硬盘上第 1 块数据(要用其中的第 1 个扇区),判断第一个扇区的0x1fe 处的两个字节是否为’55AA’作为分区表是否正常的依据即if(bh->b_data[510] != 0x55||
bh->b_data[511] != 0xAA)
然后指向扇区中0x1BE开始的分区表.
即p = 0x1BE + (void *)bh->b_data,用来填充hd数组的4项(每个分区相当于一个逻辑盘)即各分区起始扇区及扇区数
(因为硬盘主设备号都是3,放在3、4字节,所以是0x300,物理盘和4个逻辑盘各占一个次设备号,所以第二个硬盘的物理盘的次设备号是5(因为0~4被第一块硬盘占用)) - 加载(创建)虚拟硬盘RAMDISK即rd_load();
- 安装根文件系统即mount_root()
fault.c—mm/fault.c—缺页中断
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,struct task_struct *tsk)
返回值:int
作用:处理缺页中断
实现:
- 根据给定虚拟地址addr(计算完分段后的地址)查找刚好满足vma->vm_end>addr的VMA(VMA同时存在两种组织形式,双向链表和红黑树,在这里是通过红黑树来查找的即O(logN)),如下图
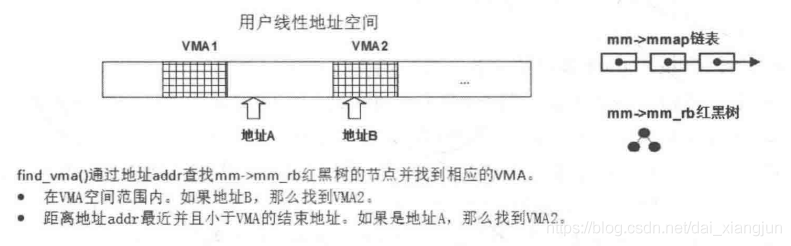
即vma = find_vma(mm, addr),如果find_vma()找不到vma,说明addr地址还没有在进程地址空间中,返回VM_FAULT_BADMAP错误,再上一层函数即do_page_fault()收到这个错误码会将进程终止 - 到这里说明给出的addr小于某个vma的end,如果进一步发现addr < vma->vm_start,则说明addr可能处于栈的虚拟空间下面的空洞(即上图中A的情况,vma2可看成栈的vma,即函数中的局部变量在被定义后的第一次使用所触发的缺页中断)(需要注意,和其他vma一样,栈的vma的end是高地址,start是低地址,从高往低开辟空间即所谓向下增长,通过移动start实现),则以页为单位开辟新的栈的虚拟空间即expand_stack(vma, addr),expand_stack只是更改了堆栈区的vm_area_struct结构,没有建立物理内存映射
- 能到这一步的,说明addr在某个段的虚拟空间中,或者在栈的虚拟空间附近并且刚刚在2完成了栈的扩充,此时通过access_error()判断VMA是否具备可写或可执行即参数fsr要求的权限,不具备则直接返回VM_FAULT_BADACCESS错误
- 此时排除了权限导致的缺页中断,调用handle_mm_fault(mm, vma, addr & PAGE_MASK, flags)处理各级页表未建立映射关系以及页面在交换分区导致的缺页中断
static int
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct task_struct *tsk)
{
struct vm_area_struct *vma;
int fault, mask;
vma = find_vma(mm, addr);
fault = VM_FAULT_BADMAP;
if (!vma)
goto out;
if (vma->vm_start > addr)
goto check_stack;
/*
* Ok, we have a good vm_area for this
* memory access, so we can handle it.
*/
good_area:
if (fsr & (1 << 11)) /* write? */
mask = VM_WRITE;
else
mask = VM_READ|VM_EXEC;
fault = VM_FAULT_BADACCESS;
if (!(vma->vm_flags & mask))
goto out;
/*
* If for any reason at all we couldn't handle
* the fault, make sure we exit gracefully rather
* than endlessly redo the fault.
*/
survive:
fault = handle_mm_fault(mm, vma, addr & PAGE_MASK, fsr & (1 << 11));
/*
* Handle the "normal" cases first - successful and sigbus
*/
switch (fault) {
case VM_FAULT_MAJOR:
tsk->maj_flt++;
return fault;
case VM_FAULT_MINOR:
tsk->min_flt++;
case VM_FAULT_SIGBUS:
return fault;
}
if (tsk->pid != 1)
goto out;
/*
* If we are out of memory for pid1,
* sleep for a while and retry
*/
yield();
goto survive;
check_stack:
if (vma->vm_flags & VM_GROWSDOWN && !expand_stack(vma, addr))
goto good_area;
out:
return fault;
}
mmap.c—mm/mmap.c
expand_stack(struct vm_area_struct *vma, unsigned long address)
返回值:int
作用:开辟进程的栈的虚拟空间,但影响不到具体的物理空间,只有进程真的访问时触发缺页中断才真正分配物理空间
/*
* vma is the first one with address < vma->vm_start. Have to extend vma.
*/
int expand_stack(struct vm_area_struct *vma, unsigned long address)
{
int error;
/*
* We must make sure the anon_vma is allocated
* so that the anon_vma locking is not a noop.
*/
if (unlikely(anon_vma_prepare(vma)))
return -ENOMEM;
anon_vma_lock(vma);
/*
* vma->vm_start/vm_end cannot change under us because the caller
* is required to hold the mmap_sem in read mode. We need the
* anon_vma lock to serialize against concurrent expand_stacks.
*/
//获取到新地址的整个各级页号部分
//比如单级页表这里address就是页号了,
//两级页表则address就是二级页号-一级页号拼在一起
//但一般只需要看成全部是一级页号就可以了
address &= PAGE_MASK;
error = 0;
// 关键来了!!!!!!!!!!!!!!!!!!!!!!!!!
/* Somebody else might have raced and expanded it already */
if (address < vma->vm_start) {
unsigned long size, grow;
// size是假设address为栈的新start的虚拟空间大小
// 即siez=多少个页再拼接上PAGE_MASK即页大小个0,
// 栈虚拟空间有上限,所以后面会有检验即acct_stack_growth
size = vma->vm_end - address;
// grow是需要新开辟多少个页,相比于size还做了>> PAGE_SHIFT即右移掉页大小个0这一步,grow通常是1
grow = (vma->vm_start - address) >> PAGE_SHIFT;
// 检验size
// 1. 地址空间限制测试:首先检查了地址空间限制,确保增长后的总虚拟内存不会超出进程的地址空间限制。
// 2. 堆栈限制测试:接着检查堆栈大小是否超出了堆栈资源限制。
// 更新增加总的虚拟空间大小mm->total_vm
// 如果虚拟内存区域vma在这里即栈被锁定,就将进程的锁定虚拟内存总量增加 grow,锁定意思是该区域不会被移动到交换空间而是驻留
error = acct_stack_growth(vma, size, grow);
if (!error) {
vma->vm_start = address;//更新栈的新起始地址
vma->vm_pgoff -= grow;
/*vm_pgoff属性表示该vma所在区域的第一页在当前进程整个虚拟地址空间的第几页,
因为增长了grow页,所以第一页也是下降了grow页,
可执行的elf文件加载到内存时,
会调用insert_vm_struct插入各个vma,
此时会将vma->vm_pgoff初始化
为vma->vm_start >> PAGE_SHIFT,即vma的start所在页号*/
}
}
anon_vma_unlock(vma);
return error;
}
memory.c—mm/memory.c
handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,unsigned long address, int write_access)
返回值:int
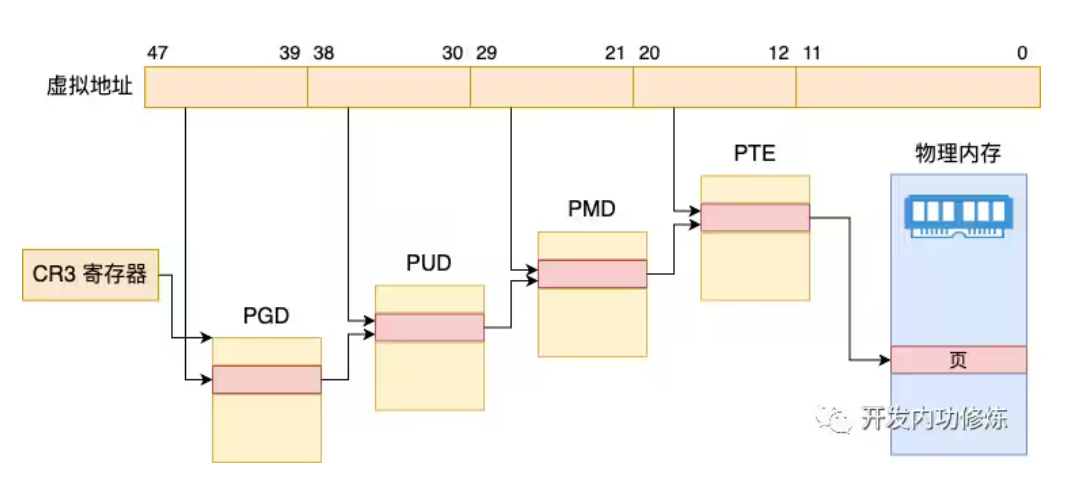
作用:处理各级页表未建立映射关系以及页面在交换分区导致的缺页中断。此处应该是四级(个)页表,五次映射运算。注意,每个页表的项放的都是物理地址
实现:
- 根据虚拟地址address以及当前进程的内存描述符,在顶级页目录获取该虚拟地址对应的二级页目录的虚拟地址即pgd = pgd_offset(mm, address),如果pgd为空,则返回VM_FAULT_OOM错误
- 在二级页目录获取该虚拟地址对应的三级页目录的虚拟地址即pud = pud_alloc(mm, pgd, address),如果pgd为空,则先为pgd申请分配一个内容全0的页然后指向该页地址(即二级页目录,分配不成功返回VM_FAULT_OOM错误,因为这表示没内存分配新页),然后再根据address返回在新二级页目录中的三级页目录的虚拟地址(得到的三级页目录必然为0,即三级页目录物理地址为0,不过要求的是其虚拟地址,所以会加上一个偏移量,因为虚拟地址空间的内核空间和物理地址空间的内核空间位置正好相反,即一个在顶着高地址,一个顶着低地址0,只需要加偏移量就可以完成 物理地址->虚拟地址,总之得到的虚拟地址不等于0)。如果pgd非空则直接根据address返回在新二级页目录中的三级页目录的虚拟地址
- 在三级页目录获取该虚拟地址对应的四级页目录地址即pud = pud_alloc(mm, pgd, address),如果pmd为空或者非空,则都和2的处理一样
- 获取该虚拟地址对应的最底层页表的项的地址即pte = pte_alloc_map(mm, pmd, address),如果pte为空或者非空,则都和2的处理一样(pmd变量指向最低层的页表即pte,pte每一项指的都是物理页的地址pte了,确切地说,pte一部分bit是地址,另一部分bit是权限属性)
- 到了这里,已经得到了该虚拟地址的对应物理页的地址和一些属性权限信息,各级页表的映射大致完成,需要注意,该物理页的地址可能是全0虚拟化后的地址(即物理页未分配),在handle_pte_fault(mm, vma, address, write_access, pte, pmd)中会进一步处理
因为程序都是虚拟地址,都要进行页表映射才能找到物理地址,要想修改页表则程序中仍需要用虚拟地址。所有页表都存放在物理内存的内核空间中,
handle_pte_fault(struct mm_struct *mm,struct vm_area_struct * vma, unsigned long address,int write_access, pte_t *pte, pmd_t *pmd)
返回值:int
作用:
实现:
- 首先判断当前页表项的present位,如果为0,则表明未分配物理页或者分配了物理页但存在于磁盘的交换分区,其中未分配物理页分为两种情况,分别是平常的未分配物理页(如malloc,由do_no_page(mm, vma, address, write_access, pte, pmd)进一步处理,不到2)和与文件关联的未分配物理页(如mmap,由do_file_page(mm, vma, address, write_access, pte, pmd)进一步处理,不到2),如果是物理页存在于磁盘的交换分区,则由do_swap_page(mm, vma, address, pte, pmd, entry, write_access)进一步处理,不到2
- 到这里说明页表项是正常的,即物理页已分配且就在物理内存中,此时如果发生缺页中断的指令为写指令且页表项指向的页不允许写,则由do_wp_page(mm, vma, address, pte, pmd, entry)进一步处理(wp是write on copy写时拷贝,比如fork的时候子进程会复制父进程的页表并且把父进程的物理页都修改成只读,本质上二者在共享一片物理内存,直到父或子写某个物理页A则会触发这个缺页中断,do_wp_page重新申请一个物理页B然后复制A的内容并把新写的内容更新上去,此时开始父子页表开始有一点不同,),不到3。如果发生缺页中断的指令为写指令而页表项指向的页允许写,则将该页修改为脏页即entry = pte_mkdirty(entry)
- 修改为最近被读写过(因为马上就要被读写,用于LRU算法对内存页的换入换出)entry = pte_mkyoung(entry),(什么样的缺页中断会执行到这里?????)
do_no_page(struct mm_struct *mm, struct vm_area_struct *vma,unsigned long address, int write_access, pte_t *page_table, pmd_t *pmd)
返回值:int
作用:为读写某个虚拟地址而其未被分配对应物理页而产生的缺页中断分配物理页
实现:
- 所有请求分配物理页的进程都会先指向同一个写保护(只读)的全零页(即empty_zero_page,该页存在于内核空间)即entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr), vma->vm_page_prot));
- 如果是未分配物理页且尝试读而触发的缺页中断(比如刚malloc了一个变量i然后立刻访问i),则直接返回1得到的全零页,(那i的值为0才对呀但为什么不是????)。如果是未分配物理页且尝试写而触发的缺页中断,则申请一个新的物理页
namespace.c—fs/namespace.c
sys_mount(char __user * dev_name, char __user * dir_name, char __user * type, unsigned long flags,void __user * data)
返回值:long
作用:挂载外部存储设备的文件系统到根文件系统中,
mount -t ext4 /dev/cdrom /mnt将文件系统已被格式化为ext4的设备/dev/cdrom挂载到/mnt目录下
(通常挂载之前都要先格式化外部存储设备的文件系统为当前os支持的文件系统,即命令mkfs -t ext4 /dev/sdb1)
实现:
- (1)将dev_name即块设备文件所在路径,dir_name即挂载点所在路径,type即文件系统类型三个参数拷贝到内核空间
(2)调用do_mount函数,传入上述三个参数以及flags挂载标志,data挂载选项
sys_mount(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
int ret;
char *kernel_type;
char *kernel_dev;
void *options;
/*1 拷贝文件系统类型名到内核空间 */
kernel_type = copy_mount_string(type);
ret = PTR_ERR(kernel_type);
if (IS_ERR(kernel_type))
goto out_type;
/*2 拷贝块设备路径名到内核空间 */
kernel_dev = copy_mount_string(dev_name);
ret = PTR_ERR(kernel_dev);
if (IS_ERR(kernel_dev))
goto out_dev;
/*3 拷贝挂载选项到内核空间 */
options = copy_mount_options(data);
ret = PTR_ERR(options);
if (IS_ERR(options))
goto out_data;
/*4 挂载委托do_mount,最重要的接口实现 */
ret = do_mount(kernel_dev, dir_name, kernel_type, flags, options);
kfree(options);
out_data:
kfree(kernel_dev);
out_dev:
kfree(kernel_type);
out_type:
return ret;
}
- (1)根据挂载点路径查找挂载点信息从而解析成该挂载点对应的path结构体
(2)然后通常调用的是do_new_mount(因为通常某个挂载点都是第一次被挂载,如果是重新挂载或者其他情况则调用其他函数)
do_mount
long do_mount(const char *dev_name, const char __user *dir_name,
const char *type_page, unsigned long flags, void *data_page)
{
struct path path; //path结构体实例
int retval = 0;
int mnt_flags = 0; //挂载标记
//去掉标记参数中的魔数
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* 安全性检查 */
if (data_page)
((char *)data_page)[PAGE_SIZE - 1] = 0;
/*1 根据挂载点路径查找挂载点信息, 把挂载点解析成path结构体 */
retval = user_path(dir_name, &path); //path保存path结构体信息
if (retval)
return retval;
retval = security_sb_mount(dev_name, &path,
type_page, flags, data_page);
if (!retval && !may_mount())
retval = -EPERM;
if (!retval && (flags & MS_MANDLOCK) && !may_mandlock())
retval = -EPERM;
if (retval)
goto dput_out;
/* Default to relatime unless overriden */
if (!(flags & MS_NOATIME))
mnt_flags |= MNT_RELATIME;
/*挂载标记参数转成内核内部标记, 分割每个挂载点的挂载标志 */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY;
/* 默认的重新挂载时间是保存时间 */
if ((flags & MS_REMOUNT) &&
((flags & (MS_NOATIME | MS_NODIRATIME | MS_RELATIME |
MS_STRICTATIME)) == 0)) {
mnt_flags &= ~MNT_ATIME_MASK;
mnt_flags |= path.mnt->mnt_flags & MNT_ATIME_MASK;
}
flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN |
MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT |
MS_STRICTATIME | MS_NOREMOTELOCK | MS_SUBMOUNT);
if (flags & MS_REMOUNT) // 如果标志位是重新挂载
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags,
data_page);
else if (flags & MS_BIND) // 通过环回接口挂载一个文件系统
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags); // 处理共享、从属和不可绑定挂载操作
else if (flags & MS_MOVE) //移动一个已经挂载的文件系统
retval = do_move_mount(&path, dev_name);
/*2 为该挂载点执行新的挂载操作*/
else
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}
- (1)根据文件系统类型名在file_system_type类型的全局链表遍历查找对应file_system_type实例
(2)然后根据得到的file_system_type实例调用vfs_kern_mount函数(主要完成创建和初始化该文件系统对应的超级块super_block、根目录项dentry和inode结构体实例,创建mount结构体实例并建立各结构体实例之间的关联即指针指向),其底层是调用具体文件系统的mount函数
(3)调用关联挂载点函数do_add_mount()建立mount和挂载点mountpoint实例、挂载点dentry实例之间的关联,并将mount实例插入全局散列链表头部,挂载操作完成
do_new_mount
static int do_new_mount(struct path *path, const char *fstype, int flags,
int mnt_flags, const char *name, void *data)
{
struct file_system_type *type; //文件系统类型
struct vfsmount *mnt;
int err;
if (!fstype)
return -EINVAL;
/*1 根据文件系统类型名在file_system_type类型的全局链表遍历查找对应file_system_type实例 */
type = get_fs_type(fstype);
if (!type)
return -ENODEV;
/*2 根据文件系统类型即刚才1得到的file_system_type实例调用具体文件系统的mount函数 */
mnt = vfs_kern_mount(type, flags, name, data);
if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) &&
!mnt->mnt_sb->s_subtype)
mnt = fs_set_subtype(mnt, fstype);
put_filesystem(type);
if (IS_ERR(mnt))
return PTR_ERR(mnt);
if (mount_too_revealing(mnt, &mnt_flags)) {
mntput(mnt);
return -EPERM;
}
/*3 关联挂载点 */
err = do_add_mount(real_mount(mnt), path, mnt_flags);
if (err)
mntput(mnt);
return err;
}
vfs_kern_mount
(1)根据设备文件名name从缓存分配mount实例并初始化各成员
(2)调用具体文件系统类型定义的挂载函数并返回该具体外部文件系统的根目录的dentry项root
(3)建立mount实例与super_block、dentry实例之间的关联
(4)返回mount实例的vfsmount结构体
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);//
/*1 从slab缓存分配mount实例,分配ID号,并初始化各成员 */
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & MS_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
/*2 调用具体文件系统类型定义的挂载函数 */
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
mnt_free_id(mnt);
free_vfsmnt(mnt);
return ERR_CAST(root);
}
/*3 建立mount实例与super_block、dentry实例之间的关联 */
mnt->mnt.mnt_root = root; //mount内部的vfsmount的mnt_root指向挂载的外部文件系统根目录项dentry实例
mnt->mnt.mnt_sb = root->d_sb; //指向外部文件系统超级块实例
mnt->mnt_mountpoint = mnt->mnt.mnt_root; //指向挂载的外部文件系统根目录项dentry实例,在关联挂载点时将重新赋值,指向内核根文件系统中挂载点dentry实例
mnt->mnt_parent = mnt; //父mount实例指向自身
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts); //插入超级块中链表的末尾
unlock_mount_hash();
return &mnt->mnt; //返回mount实例mnt成员指针,vfsmount结构体成员
}
vfs_kern_mount()函数创建的数据结构实例组织关系如下图所示:
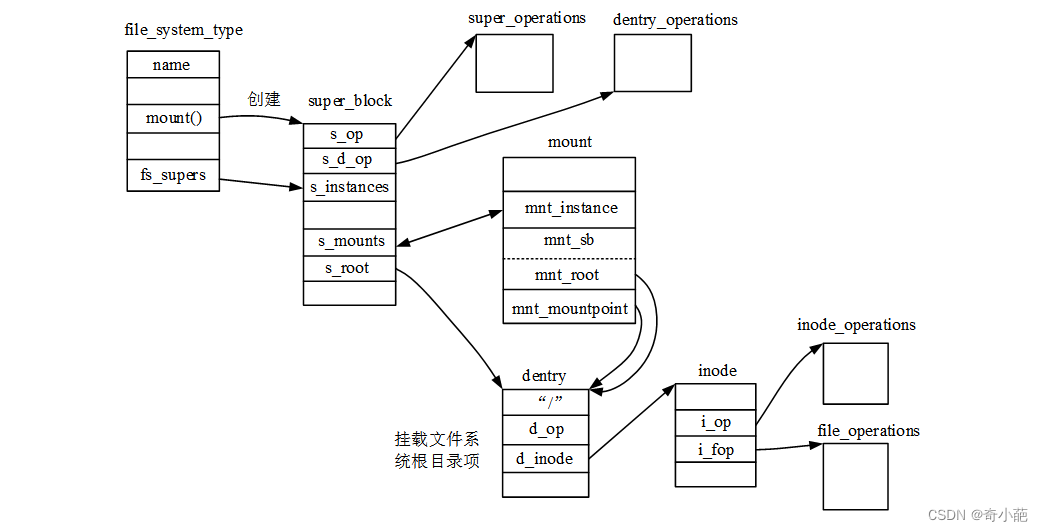
mount_fs
(1)调用具体文件系统类型定义的mount()函数,创建并初始化文件系统超级块super_block、根目录项dentry和inode结构体实例,返回挂载的外部文件系统根目录项dentry实例指针
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root; //返回值,挂载文件系统根目录项的dentry实例指针
struct super_block *sb;
char *secdata = NULL;
int error = -ENOMEM;
if (data && !(type->fs_flags & FS_BINARY_MOUNTDATA)) {
secdata = alloc_secdata();
if (!secdata)
goto out;
error = security_sb_copy_data(data, secdata);
if (error)
goto out_free_secdata;
}
/*1 调用具体文件系统类型挂载函数,创建各数据结构体实例 */
root = type->mount(type, flags, name, data);
if (IS_ERR(root)) {
error = PTR_ERR(root);
goto out_free_secdata;
}
sb = root->d_sb; /* 文件系统超级块指针 */
BUG_ON(!sb);
WARN_ON(!sb->s_bdi);
sb->s_flags |= MS_BORN;
error = security_sb_kern_mount(sb, flags, secdata);
if (error)
goto out_sb;
/*
* filesystems should never set s_maxbytes larger than MAX_LFS_FILESIZE
* but s_maxbytes was an unsigned long long for many releases. Throw
* this warning for a little while to try and catch filesystems that
* violate this rule.
*/
WARN((sb->s_maxbytes < 0), "%s set sb->s_maxbytes to "
"negative value (%lld)\n", type->name, sb->s_maxbytes);
up_write(&sb->s_umount);
free_secdata(secdata);
return root; //返回挂载文件系统根目录项dentry实例指针
out_sb:
dput(root);
deactivate_locked_super(sb);
out_free_secdata:
free_secdata(secdata);
out:
return ERR_PTR(error);
}
例如,ext4文件系统的file_system_type实例定义如下(/fs/ext2/super.c):
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount, //挂载时调用 用于读取创建超级块实例
.kill_sb = kill_block_super, //卸载时调用 用于释放超级块
.fs_flags = FS_REQUIRES_DEV, //文件系统标志为 请求块设备,文件系统在块设备上
};
MODULE_ALIAS_FS("ext4");
文件系统类型挂载函数ext4_mount()调用了通用的mount_bdev()函数,定义如下(/fs/ext4/super.c):
static struct dentry *ext4_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, ext4_fill_super);
}
函数内直接调用通用的mount_bdev()函数,需要注意的是最后一个参数ext4_fill_super是一个函数指针,mount_bdev()函数内会调用此函数完成超级块实例的填充和初始化,包括dentry和inode实例的创建
- ext4_fill_super的一个函数指针作为参数传递给get_sb_bdev。该函数用于填充一个超级块对象,如果内存中没有适当的超级块对象,数据就必须从硬盘读取。
- mount_bdev是个公用的函数,一般磁盘文件系统会使用它来根据具体文件系统的fill_super方法来读取磁盘上的超级块并在创建内存超级块。
我们来看下mount_bdev的实现,它执行完成之后会创建vfs的三大数据结构 super_block、根inode和根dentry
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
if (!(flags & MS_RDONLY))
mode |= FMODE_WRITE;
/* 通过要挂载的块设备路径名 获得它的块设备描述符block_device
(会涉及到路径名查找和通过设备号在bdev文件系统查找block_device,
block_device是添加块设备到系统时创建的) */
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
if (IS_ERR(bdev))
return ERR_CAST(bdev);
/*
* once the super is inserted into the list by sget, s_umount
* will protect the lockfs code from trying to start a snapshot
* while we are mounting
*/
mutex_lock(&bdev->bd_fsfreeze_mutex);
if (bdev->bd_fsfreeze_count > 0) {
mutex_unlock(&bdev->bd_fsfreeze_mutex);
error = -EBUSY;
goto error_bdev;
}
/* 查找或创建vfs的超级 */
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC,
bdev);
mutex_unlock(&bdev->bd_fsfreeze_mutex);
if (IS_ERR(s))
goto error_s;
/*超级块的根dentry是否被赋值*/
if (s->s_root) {
if ((flags ^ s->s_flags) & MS_RDONLY) {
deactivate_locked_super(s);
error = -EBUSY;
goto error_bdev;
}
/*
* s_umount nests inside bd_mutex during
* __invalidate_device(). blkdev_put() acquires
* bd_mutex and can't be called under s_umount. Drop
* s_umount temporarily. This is safe as we're
* holding an active reference.
*/
up_write(&s->s_umount);
blkdev_put(bdev, mode);
down_write(&s->s_umount);
} else { //没有赋值说明时新创建的sb
s->s_mode = mode;
snprintf(s->s_id, sizeof(s->s_id), "%pg", bdev);
sb_set_blocksize(s, block_size(bdev)); // 根据块设备描述符设置文件系统块大小
/* 调用传递的具体文件系统的填充超级块方法读取填充超级块等 如ext4_fill_super */
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
goto error;
}
s->s_flags |= MS_ACTIVE;
bdev->bd_super = s; //块设备bd_super指向sb
}
//返回文件系统的根dentry
return dget(s->s_root);
error_s:
error = PTR_ERR(s);
error_bdev:
blkdev_put(bdev, mode);
error:
return ERR_PTR(error);
}
对于ext4_fill_super主要的工作,如下:
- 读取磁盘上的超级块
- 填充并关联vfs超级块
- 读取块组描述符
- 读取磁盘根inode并建立vfs 根inode
- 创建根dentry关联到根inode
- 接下来的工作就是通过mount实例建立挂载点dentry实例与挂载文件系统根目录项dentry实例之间的关联,并将mount实例添加到全局散列链表头部。以便将挂载的文件系统导入内核根文件系统,使之对用户进程可见。
(1)调用lock_mount(path)函数创建(或查找)挂载点mountpoint实例,建立其与挂载点dentry实例的关联,设置挂载点dentry实例DCACHE_MOUNTED标记位(d_set_mounted(dentry)),并将mountpoint实例添加到全局散列表
(2)调用graft_tree()函数,建立mount实例与mountpoint、挂载点dentry实例之间的关联,并将mount实例插入到全局散列链表的头部,以及加入到内核mount实例的层次(父子关系)结构中
do_add_mount
static int do_add_mount(struct mount *newmnt, struct path *path, int mnt_flags)
{
struct mountpoint *mp;
struct mount *parent;
int err;
mnt_flags &= ~MNT_INTERNAL_FLAGS;
/*1 lock_mount函数创建mountpoint实例,并建立与挂载点dentry关联 */
mp = lock_mount(path);
if (IS_ERR(mp))
return PTR_ERR(mp);
/*2 vfsmount指针转为mount类型实例指针*/
parent = real_mount(path->mnt);
err = -EINVAL;
if (unlikely(!check_mnt(parent))) {
/* that's acceptable only for automounts done in private ns */
if (!(mnt_flags & MNT_SHRINKABLE))
goto unlock;
/* ... and for those we'd better have mountpoint still alive */
if (!parent->mnt_ns)
goto unlock;
}
/*3 避免同一文件系统重复挂载到同一挂载点 */
err = -EBUSY;
if (path->mnt->mnt_sb == newmnt->mnt.mnt_sb &&
path->mnt->mnt_root == path->dentry)
goto unlock;
err = -EINVAL;
if (d_is_symlink(newmnt->mnt.mnt_root))
goto unlock;
/*4 建立mount与mountpoint、挂载点dentry实例关联,并插入散列表*/
newmnt->mnt.mnt_flags = mnt_flags;
err = graft_tree(newmnt, parent, mp);
unlock:
unlock_mount(mp);
return err;
}
do_add_mount()函数创建的数据结构实例及组织关系如下图所示:
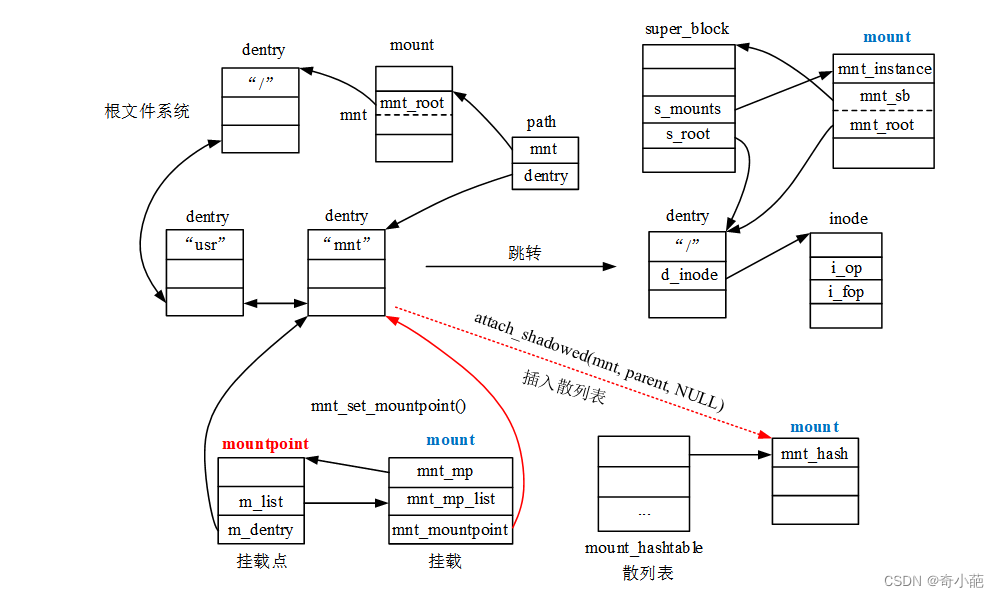
执行内核的挂载函数vfs_kern_mount:该函数主要是创建文件系统超级块super_block、根目录项dentry和inode结构体实例,并创建表示本次挂载操作的mount结构体实例,mount实例添加到超级块实例s_mounts成员链表中,并与挂载文件系统根目录项dentry建立关联
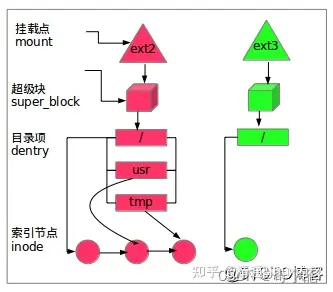 关联挂载点do_add_mount:创建挂载点mountpoint结构体实例,并添加到全局散列表,mountpoint实例关联到挂载点dentry实例(跟文件系统中目录项),并将挂载mount实例添加到Mountpoint实例链表和全局散列表中,建立mount实例与挂载断点dentry之间的关联,一个挂载点可以有多个挂载,因此Mountpoint实例包含一个挂载mount实例的链表
关联挂载点do_add_mount:创建挂载点mountpoint结构体实例,并添加到全局散列表,mountpoint实例关联到挂载点dentry实例(跟文件系统中目录项),并将挂载mount实例添加到Mountpoint实例链表和全局散列表中,建立mount实例与挂载断点dentry之间的关联,一个挂载点可以有多个挂载,因此Mountpoint实例包含一个挂载mount实例的链表
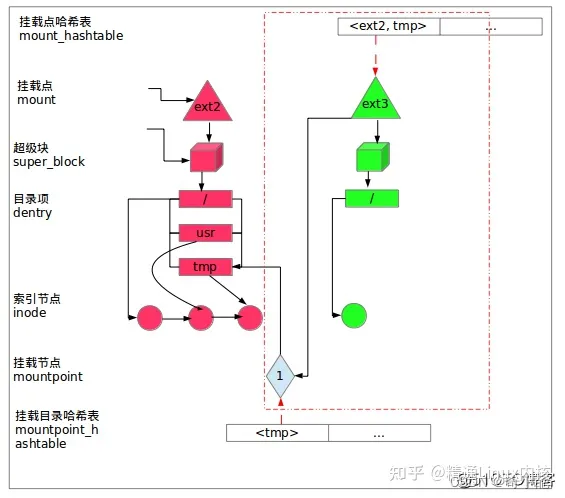
执行完这两步,通过mount实例建立了挂载点dentry实例和挂载文件系统根目录项dentry实例之间的联系。
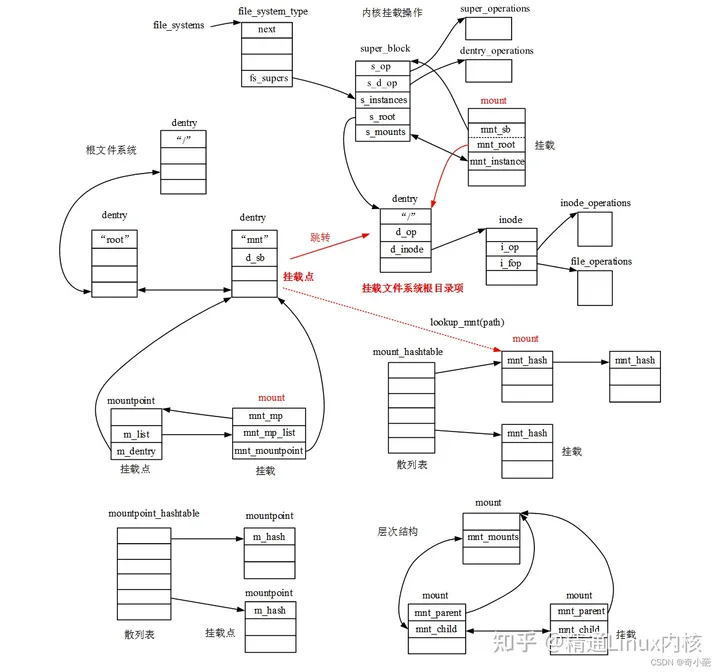 当内核打开文件搜索路径到达挂载点时(挂载点dentry实例设置DCACHE_MOUNTED标记位),将调用函数lookup_mnt(path),在mount实例全局散列表中查找第一个关联到挂载点dentry实例的mount实例,搜索路径随后进入mount实例关联的挂载文件系统根目录项。
当内核打开文件搜索路径到达挂载点时(挂载点dentry实例设置DCACHE_MOUNTED标记位),将调用函数lookup_mnt(path),在mount实例全局散列表中查找第一个关联到挂载点dentry实例的mount实例,搜索路径随后进入mount实例关联的挂载文件系统根目录项。
end
返回值:
作用:
实现:
1.
2.
结构体
struct proc_dir_entry {
unsigned int low_ino;
unsigned short namelen;
const char *name;
mode_t mode;
nlink_t nlink;
uid_t uid;
gid_t gid;
unsigned long size;
struct inode_operations * proc_iops;
struct file_operations * proc_fops;
get_info_t *get_info;
struct module *owner;
struct proc_dir_entry *next, *parent, *subdir;
void *data;
read_proc_t *read_proc;
write_proc_t *write_proc;
atomic_t count; /* use count */
int deleted; /* delete flag */
};
struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;//路径最后分量的字符串相关信息
unsigned int flags;
int last_type;//路径最后分量对应文件的类型,可取值为enum {LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, LAST_BIND};
unsigned depth;
char *saved_names[MAX_NESTED_LINKS + 1];
/* Intent data */
union {
struct open_intent open;
} intent;
};
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
struct thread_info *thread_info;
atomic_t usage;
unsigned long flags; /* per process flags, defined below */
unsigned long ptrace;
int lock_depth; /* Lock depth */
int prio, static_prio;
struct list_head run_list;
prio_array_t *array;
unsigned long sleep_avg;
unsigned long long timestamp, last_ran;
int activated;
unsigned long policy;
cpumask_t cpus_allowed;
unsigned int time_slice, first_time_slice;
#ifdef CONFIG_SCHEDSTATS
struct sched_info sched_info;
#endif
struct list_head tasks;
/*
* ptrace_list/ptrace_children forms the list of my children
* that were stolen by a ptracer.
*/
struct list_head ptrace_children;
struct list_head ptrace_list;
struct mm_struct *mm, *active_mm;
/* task state */
struct linux_binfmt *binfmt;
long exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
unsigned did_exec:1;
pid_t pid;
pid_t tgid;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->parent->pid)
*/
struct task_struct *real_parent; /* real parent process (when being debugged) */
struct task_struct *parent; /* parent process */
/*
* children/sibling forms the list of my children plus the
* tasks I'm ptracing.
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/* PID/PID hash table linkage. */
struct pid pids[PIDTYPE_MAX];
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
unsigned long rt_priority;
unsigned long it_real_value, it_real_incr;
cputime_t it_virt_value, it_virt_incr;
cputime_t it_prof_value, it_prof_incr;
struct timer_list real_timer;
cputime_t utime, stime;
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time;
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
struct group_info *group_info;
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
unsigned keep_capabilities:1;
struct user_struct *user;
#ifdef CONFIG_KEYS
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process (CLONE_THREAD) */
struct key *thread_keyring; /* keyring private to this thread */
#endif
int oomkilladj; /* OOM kill score adjustment (bit shift). */
char comm[TASK_COMM_LEN];
/* file system info */
int link_count, total_link_count;
/* ipc stuff */
struct sysv_sem sysvsem;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
void *security;
struct audit_context *audit_context;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings */
spinlock_t alloc_lock;
/* Protection of proc_dentry: nesting proc_lock, dcache_lock, write_lock_irq(&tasklist_lock); */
spinlock_t proc_lock;
/* context-switch lock */
spinlock_t switch_lock;
/* journalling filesystem info */
void *journal_info;
/* VM state */
struct reclaim_state *reclaim_state;
struct dentry *proc_dentry;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
/*
* current io wait handle: wait queue entry to use for io waits
* If this thread is processing aio, this points at the waitqueue
* inside the currently handled kiocb. It may be NULL (i.e. default
* to a stack based synchronous wait) if its doing sync IO.
*/
wait_queue_t *io_wait;
/* i/o counters(bytes read/written, #syscalls */
u64 rchar, wchar, syscr, syscw;
#if defined(CONFIG_BSD_PROCESS_ACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
clock_t acct_stimexpd; /* clock_t-converted stime since last update */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy;
short il_next;
#endif
};
struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
};
/**/
struct vfsmount {
struct dentry *mnt_root; //指向挂载文件系统根目录项dentry实例
struct super_block *mnt_sb; //指向文件系统超级块实例
int mnt_flags; //内核内部使用的挂载标记
struct user_namespace *mnt_userns;
} __randomize_layout;
/*表示一次挂载操作*/
struct mount {
struct hlist_node mnt_hash; //散列链表节点成员,将实例链入全局散列表
struct mount *mnt_parent; //父mount实例
struct dentry *mnt_mountpoint; //挂载点dentry实例指针(跟文件系统目录项)
struct vfsmount mnt; //vfsmount结构体实例,表示在vfs中的挂载信息
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; // 子mount实例链表头
struct list_head mnt_child; // 链接兄弟mount实例
struct list_head mnt_instance; // 链入超级块中双链表,表头为sb->s_mounts
const char *mnt_devname; // 文件系统所在块设备文件名称,如:/dev/dsk/hda1
struct list_head mnt_list; // 将实例链接到挂载命名空间链表
struct list_head mnt_expire; // 用于特定于文件系统的过期链表
struct list_head mnt_share; // 用于共享挂载的循环链表
struct list_head mnt_slave_list; // 从属挂载链表头
struct list_head mnt_slave; // 用于链入从属挂载链表
struct mount *mnt_master; // 指向包含从属挂载链表头的mount实例
struct mnt_namespace *mnt_ns; // 指向所属挂载命名空间
struct mountpoint *mnt_mp; // 挂载点结构体指针
union {
struct hlist_node mnt_mp_list; //将实例添加到挂载点的mount实例链表
struct hlist_node mnt_umount;
};
struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFY
struct fsnotify_mark_connector __rcu *mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; // ID标记
int mnt_group_id; // 组ID
int mnt_expiry_mark; // 标记挂载时否过期,true表示过期
struct hlist_head mnt_pins;
struct hlist_head mnt_stuck_children;
} __randomize_layout;
/*
mnt_hash: 散列链表节点成员,将实例添加到全局散列表mount_hashtable
mnt_mountpoint:指向挂载点dentry实例
mnt_instance:双链表节点成员,将Mount实例链入超级块的双链表,链表头为sb→s_mounts
mnt_mp:挂载点mountpoint实例
mnt_mp_list:散列链表节点成员,将实例链接到挂载点mountpoint实例的mount实例链表
mnt_list:双链表节点成员,将mount实例链接到挂载命名空间mnt_namespace实例中的双链表
mnt:vfsmount结构体成员,用于建立Mount实例与挂载文件系统的关联
*/
/*表示根文件系统中的挂载点,挂载点对应到跟文件系统中的一个dentry实例,定义了一个mount结构体表示一次挂载操作*/
struct mountpoint {
struct hlist_node m_hash; //将mountpoint实例添加到全局散列表mountpoint_hashtable列链表
struct dentry *m_dentry; // 指向挂载点 dentry 实例(根文件系统中目录项)
struct hlist_head m_list; //挂载点挂载操作链表的头部mount实例
int m_count; //挂载点挂载操作的次数
};
struct path {
/* 指向vfsmount实例,mount.mnt成员(当前挂载点上挂载的文件系统的挂载信息) */
struct vfsmount *mnt;
/*指向挂载点dentry实例(根文件系统中目录项)*/
struct dentry *dentry;
};
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct vm_area_struct *area);
unsigned long mmap_base; /* base of mmap area */
unsigned long free_area_cache; /* first hole */
pgd_t * pgd;/ !!!此处的pgd是虚拟地址,即调用宏__va()
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* Protects page tables, mm->rss, mm->anon_rss */
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, anon_rss, total_vm, locked_vm, shared_vm;
unsigned long exec_vm, stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long saved_auxv[42]; /* for /proc/PID/auxv */
unsigned dumpable:1;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Token based thrashing protection. */
unsigned long swap_token_time;
char recent_pagein;
/* coredumping support */
int core_waiters;
struct completion *core_startup_done, core_done;
/* aio bits */
rwlock_t ioctx_list_lock;
struct kioctx *ioctx_list;
struct kioctx default_kioctx;
unsigned long hiwater_rss; /* High-water RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
};
struct vm_area_struct {
struct mm_struct * vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, listed below. */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
atomic_t vm_usage; /* refcount (VMAs shared if !MMU) */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
struct hd_i_struct {
int head,sect,cyl,wpcom,lzone,ctl;
//各字段分别是磁头数、每磁道扇区数、柱面数、写前预补偿柱面号、磁头着陆区柱面号、控制字节。
};
static struct hd_struct {
long start_sect;
long nr_sects;
} hd[5*MAX_HD]={{0,0},};
struct request {
int dev; /* -1 if no request */
int cmd; /* READ or WRITE */
int errors;
unsigned long sector;
unsigned long nr_sectors;
char * buffer;
struct task_struct * waiting;
struct buffer_head * bh;
struct request * next;
};
struct blk_dev_struct {
void (*request_fn)(void);
struct request * current_request;
};
struct blk_dev_struct blk_dev[NR_BLK_DEV] = {
{ NULL, NULL }, /* no_dev */
{ NULL, NULL }, /* dev mem */
{ NULL, NULL }, /* dev fd */
{ NULL, NULL }, /* dev hd */
{ NULL, NULL }, /* dev ttyx */
{ NULL, NULL }, /* dev tty */
{ NULL, NULL } /* dev lp */
};
struct inode_operations minix_inode_operations = {
minix_create,
minix_lookup,
minix_link,
minix_unlink,
minix_symlink,
minix_mkdir,
minix_rmdir,
minix_mknod,
minix_rename,
minix_readlink,
minix_open,
minix_release,
minix_follow_link
};
struct dir_entry {
unsigned short inode; //inode节点的编号
char name[NAME_LEN]; //文件名
};
struct buffer_head {
char * b_data; /* pointer to data block (1024 bytes) */
unsigned long b_blocknr; /* block number */
unsigned short b_dev; /* device (0 = free) */
unsigned char b_uptodate;
unsigned char b_dirt; /* 0-clean,1-dirty */
unsigned char b_count; /* users using this block */
unsigned char b_lock; /* 0 - ok, 1 -locked */
struct task_struct * b_wait;
struct buffer_head * b_prev;
struct buffer_head * b_next;
struct buffer_head * b_prev_free;
struct buffer_head * b_next_free;
};
struct inode {
dev_t i_dev;
ino_t i_ino;//在磁盘中的inode表排第几个
umode_t i_mode;
/*i_mode一共10位,第一位表明结点文件类型,后9位依次为:
i结点所有者、所属组成员、其他成员的权限
(权限有读写执行三种)*/
nlink_t i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
off_t i_size;//文件大小(字节数)
time_t i_atime;
time_t i_mtime;
time_t i_ctime;
unsigned long i_data[16];
struct inode_operations * i_op;
struct super_block * i_sb;
struct task_struct * i_wait;
struct task_struct * i_wait2; /* for pipes */
unsigned short i_count;//i节点被使用的次数
unsigned char i_lock;
unsigned char i_dirt;
unsigned char i_pipe;
unsigned char i_mount;
unsigned char i_seek;
unsigned char i_update;
};
struct file {
unsigned short f_mode;//用在创建文件时使用,通过FMODE_READ和FMODE_WRITE位来标识文件是否可读或可写
unsigned short f_flags;//用在文件本身已存在,指定打开该文件的方式
unsigned short f_count;
struct inode * f_inode;
struct file_operations * f_op;
off_t f_pos;
};
struct super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
/* These are only in memory */
struct buffer_head * s_imap[8];
struct buffer_head * s_zmap[8];
unsigned short s_dev;
struct inode * s_covered;
struct inode * s_mounted;
unsigned long s_time;
struct task_struct * s_wait;
unsigned char s_lock;
unsigned char s_rd_only;
unsigned char s_dirt;
};
struct file_operations {
int (*lseek) (struct inode *, struct file *, off_t, int);
int (*read) (struct inode *, struct file *, char *, int);
int (*write) (struct inode *, struct file *, char *, int);
};
struct inode_operations {
int (*create) (struct inode *,const char *,int,int,struct inode **);
int (*lookup) (struct inode *,const char *,int,struct inode **);
int (*link) (struct inode *,struct inode *,const char *,int);
int (*unlink) (struct inode *,const char *,int);
int (*symlink) (struct inode *,const char *,int,const char *);
int (*mkdir) (struct inode *,const char *,int,int);
int (*rmdir) (struct inode *,const char *,int);
int (*mknod) (struct inode *,const char *,int,int,int);
int (*rename) (struct inode *,const char *,int,struct inode *,const char *,int);
int (*readlink) (struct inode *,char *,int);
int (*open) (struct inode *, struct file *);
void (*release) (struct inode *, struct file *);
struct inode * (*follow_link) (struct inode *, struct inode *);
};
struct minix_inode {
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size;
unsigned long i_time;
unsigned char i_gid;
unsigned char i_nlinks;
unsigned short i_zone[9];
};
struct minix_super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
};
struct minix_dir_entry {
unsigned short inode;
char name[MINIX_NAME_LEN];
};















 3385
3385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









