







主要内容如下:
1、LEVIR-CD数据集介绍及下载
2、运行环境安装
3、Tinycd模型训练与预测
4、Onnx运行及可视化
运行环境:Python=3.8,torch1.12.0+cu113,onnxruntime-gpu=1.12.0
likyoo变化检测源码:https://github.com/likyoo/open-cd
使用情况:代码风格属于openmmlab那套,通过修改配置文件config进行模型选择和训练、环境配置简单、训练速度一般。
训练资源消耗:默认参数配置,且batch_size为8时,显存占用6G左右,RTX4080迭代40000大概1.5小时。
ONNX推理:显存占用3G左右,RTX4080推理耗时约85ms。
1 LEVIR-CD数据集介绍
1.1 简介
LEVIR-CD 由 637 个超高分辨率(VHR,0.5m/像素)谷歌地球(GE)图像块对组成,大小为 1024 × 1024 像素。这些时间跨度为 5 到 14 年的双时态图像具有显着的土地利用变化,尤其是建筑增长。LEVIR-CD涵盖别墅住宅、高层公寓、小型车库、大型仓库等各类建筑。在这里,我们关注与建筑相关的变化,包括建筑增长(从土壤/草地/硬化地面或在建建筑到新的建筑区域的变化)和建筑衰退。这些双时态图像由遥感图像解释专家使用二进制标签(1 表示变化,0 表示不变)进行注释。我们数据集中的每个样本都由一个注释者进行注释,然后由另一个进行双重检查以生成高质量的注释。
数据来源:https://justchenhao.github.io/LEVIR/
论文地址:https://www.mdpi.com/2072-4292/12/10/1662
快速下载链接:https://aistudio.baidu.com/datasetdetail/104390/1
1.2 示例

2 运行环境安装
2.1 基础环境安装
【超详细】跑通YOLOv8之深度学习环境配置1-Anaconda安装
【超详细】跑通YOLOv8之深度学习环境配置2-CUDA安装
创建Python环境及换源可借鉴如下:
【超详细】跑通YOLOv8之深度学习环境配置3-YOLOv8安装
2.2 likyoo变化检测代码环境安装
2.2.1 代码下载
Git:git clone https://github.com/likyoo/open-cd.git

2.2.2 环境安装
# 1 创建环境
conda create -n likyoo python=3.8
conda activate likyoo
# 2 安装torch
# 方式1:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
# 方式2:
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
# 3 验证torch安装是否为gpu版
import torch
print(torch.__version__) # 打印torch版本
print(torch.cuda.is_available()) # True即为成功
print(torch.version.cuda)
print(torch.backends.cudnn.version())
# 4 安装其他依赖库
cd ./open-cd-main
# 4.1 安装 OpenMMLab 相关工具
pip install -U openmim
mim install mmengine
mim install "mmcv==2.0.0"
mim install "mmpretrain>=1.0.0rc7" # (本地安装版本为1.2.0)
pip install "mmsegmentation==1.2.2"
pip install "mmdet==3.0.0"
# 4.2 编译安装open-cd
pip install -v -e .
# 5 可能缺少的库
pip install ftfy
3 Tinycd模型训练与预测
3.1 Tinycd模型介绍
3.1.1 简介

摘要:在本文中,我们提出了一种轻量级且有效的变化检测模型,称为TinyCD。该模型的设计目的是比当前工业需求下的最先进变化检测模型更快、更小。尽管与比较模型相比,TinyCD的大小减少了13至140倍,但其计算复杂度至少减少了四分之一。在LEVIR-CD数据集上的F1分数和IoU上,TinyCD至少比当前最先进的模型提高了1%,而在WHU-CD数据集上的提高超过了8%。为了达到这些结果,TinyCD使用了Siamese U-Net架构,在全局时间和局部空间上利用了低级特征。道路。此外,它采用了一种新的策略,在空间-时间域中混合特征,以融合来自孪生后端的嵌入,并结合一个MLP块,形成了一种新颖的空间语义注意力机制,即混合与注意力掩码块(MAMB)。源代码、模型和结果可在以下网址获取:<https://github.com/AndreaCodegoni/Tiny_model_4_CD>
论文地址:https://arxiv.org/pdf/2207.13159
主要贡献包括:
(1)探索了在图像比较问题中使用低级特征的有效性,结果表明低级特征在这种情况下具有足够的表达能力,并且可以显著限制模型参数的数量。
(2)提出了一种新的特征混合策略,允许在保持低计算复杂性的同时,计算输入图像之间的时空相关性。
(3)引入了一种快速的注意力机制,通过 MAMB 块使用空间定位的特征来计算上采样阶段所需的注意力掩码,以细化低分辨率结果。
(4)提出了使用像素级分类器生成最终掩码的方法,在测试中证明非常有效。
3.1.2 模型结构

3.1.3 实验结果


3.2 模型训练与预测
3.2.1 修改训练配置文件
(1)修改configs\tinycd\tinycd_256x256_40k_levircd.py
crop_size输入大小,默认256*256,可以自行设置其他值,如512;
num_classes默认为2【不变】;

(2)修改configs\common\standard_256x256_40k_levircd.py
关键修改:输入数据集路径data_root一定要对!!!
batch_size和迭代数量等按自己需要调整,预测为1024大小。

(3)configs_base_\models\tinycd.py
模型结构修改:【默认不变】
主干默认为efficientnet_b4,可以自行调整更换;

训练资源消耗:默认参数配置,且batch_size为8时,显存占用6G左右,RTX4080迭代40000次大概1.5小时。
3.2.2 模型训练与测试
# 训练,--config配置文件+保存文件夹名
python tools/train.py configs/tinycd/tinycd_256x256_40k_levircd.py --work-dir ./tinycd
# 测试==》得到评价指标
python tools/test.py configs/tinycd/tinycd_256x256_40k_levircd.py tinycd/iter_40000.pth

3.2.3 结果显示
# 测试==》得到结果图
python tools/test.py configs/tinycd/tinycd_256x256_40k_levircd.py tinycd/iter_40000.pth --show-dir tmp_infer

4 Onnx运行及可视化
4.1 Onnx导出静态和动态文件
(1)修改tools/export.py脚本,导出onnx,复制如下内容【修改了输入尺寸和增加一个动态onnx导出】:
# Copyright (c) Open-CD. All rights reserved.
import argparse
import logging
import torch
from mmengine import Config
from mmengine.registry import MODELS, init_default_scope
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger('opencd')
def main(args):
# must be called before using opencd
init_default_scope('opencd')
config_path = args.config
checkpoint_path = args.checkpoint
inputs = args.inputs
model_name = args.model_name
model_name_dy = args.model_name_dy
config = Config.fromfile(config_path, import_custom_modules=True)
model = MODELS.build(config.model)
ckpt = torch.load(checkpoint_path)
state_dict = ckpt['state_dict']
model.load_state_dict(state_dict, strict=True)
model.eval()
input_shape0 = tuple(map(int, inputs[0].split(',')))
input_shape1 = tuple(map(int, inputs[1].split(',')))
input0 = torch.rand(input_shape0)
input1 = torch.rand(input_shape1)
images = torch.concat((input0, input1), dim=1).to(args.device)
model.to(args.device)
# 导出静态onnx
torch.onnx.export(
model,
(images),
model_name,
input_names=['images'],
output_names=['output'],
verbose=False,
opset_version=11,
)
# 导出动态onnx
torch.onnx.export(
model,
(images),
model_name_dy,
input_names=['images'],
output_names=['output'],
verbose=False,
opset_version=11,
dynamic_axes={
"images": {0 :"batch_size", 2: "input_height", 3: "input_width"},
"output": {0 :"batch_size", 2: "output_height", 3: "output_width"}
}
)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--config', '-c', type=str, default='')
parser.add_argument('--checkpoint', '-m', type=str, default='')
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument(
'--inputs',
'-i',
type=str,
nargs='+',
default=['1,3,1024,1024', '1,3,1024,1024'])
parser.add_argument('--model-name', '-mn', type=str, default='model.onnx')
parser.add_argument('--model-name_dy', '-mndy', type=str, default='model_dy.onnx')
args = parser.parse_args()
logger.info(args)
main(args)
运行命令如下【结果生成两个onnx文件】:
python tools/export.py --config configs/tinycd/tinycd_256x256_40k_levircd.py --checkpoint tinycd/iter_40000.pth
(2)查看模型结构
https://netron.app/
静态onnx:
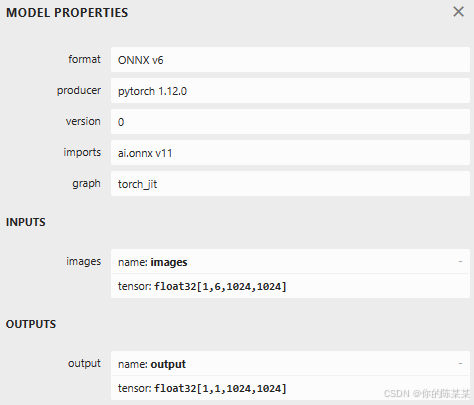
动态onnx:

注意:其中的[1,6,1024,1024]表示两个[1,3,1024,1024]堆叠一起输入。
4.2 Onnx运行及可视化
4.2.1 Onnx推理运行
注意:由于LEVIR-CD图像为1024*1024大小,输入改成1024输入。
import os
import cv2
import time
import argparse
import numpy as np
import onnxruntime as ort # 使用onnxruntime推理用上,pip install onnxruntime-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
class CD(object):
def __init__(self, onnx_model, in_shape=1024):
self.in_shape = in_shape # 图像输入尺度
self.mean = [0.406, 0.456, 0.485] # 定义均值和标准差(确保它们与图像数据的范围相匹配)
self.std = [0.225, 0.224, 0.229] # 基于BGR范围的
# 构建onnxruntime推理引擎
self.ort_session = ort.InferenceSession(onnx_model,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
if ort.get_device() == 'GPU' else ['CPUExecutionProvider'])
# 归一化
def normalize(self, image, mean, std):
# 如果均值和标准差是基于0-255范围的图像计算的,那么需要先将图像转换为0-1范围
image = image / 255.0
image = image.astype(np.float32)
image_normalized = np.zeros_like(image)
for i in range(3): # 对于 BGR 的每个通道
image_normalized[:, :, i] = (image[:, :, i] - mean[i]) / std[i]
return image_normalized
def preprocess(self, img_a, img_b):
# resize为1024大小
if img_a.shape[0] != self.in_shape and img_a.shape[1] != self.in_shape:
img_a = cv2.resize(img_a, (self.in_shape, self.in_shape), interpolation=cv2.INTER_LINEAR)
if img_b.shape[0] != self.in_shape and img_b.shape[1] != self.in_shape:
img_b = cv2.resize(img_b, (self.in_shape, self.in_shape), interpolation=cv2.INTER_LINEAR)
# 应用归一化
img_a = self.normalize(img_a, self.mean, self.std)
img_b = self.normalize(img_b, self.mean, self.std)
img_a = np.ascontiguousarray(np.einsum('HWC->CHW', img_a)[::-1], dtype=np.single) # (1024, 1024, 3)-->(3, 1024, 1024), BGR-->RGB
img_b = np.ascontiguousarray(np.einsum('HWC->CHW', img_b)[::-1], dtype=np.single) # np.single 和 np.float32 是等价的
img_a = img_a[None] if len(img_a.shape) == 3 else img_a # (1, 3, 1024, 1024)
img_b = img_b[None] if len(img_b.shape) == 3 else img_b
concat_img = np.concatenate((img_a, img_b), axis=1)
return concat_img
# 推理
def infer(self, img_a, img_b):
concat_img = self.preprocess(img_a, img_b) # (1024, 1024, 3)+(1024, 1024, 3) --> (1, 6, 1024, 1024)
preds = self.ort_session.run(None, {self.ort_session.get_inputs()[0].name: concat_img})[0] # (1, n, 1024, 1024)
if preds.shape[1] == 1:
out_img = (np.clip(preds[0][0], 0, 1) * 255).astype("uint8")
else:
out_img = (np.argmax(preds, axis=1)[0] * 255).astype("uint8")
return out_img
if __name__ == '__main__':
# Create an argument parser to handle command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='weights/model_dy.onnx', help='Path to ONNX model')
parser.add_argument('--source_A', type=str, default=str('E:/datasets/LEVIR-CD/test/A/test_7.png'), help='A期图像')
parser.add_argument('--source_B', type=str, default=str('E:/datasets/LEVIR-CD/test/B/test_7.png'), help='B期图像')
parser.add_argument('--in_shape', type=int, default=1024, help='输入模型图像尺度')
args = parser.parse_args()
# 实例化变化检测模型
cd= CD(args.model, args.in_shape)
# Read image by OpenCV
img_a = cv2.imread(args.source_A)
img_b = cv2.imread(args.source_B)
# 推理+输出
t1 = time.time()
out = cd.infer(img_a, img_b)
print('推理耗时:{}'.format(time.time() - t1))
# 保存结果
cv2.imwrite('./result/test_7_res.png', out)
4.2.2 结果可视化
显存:占用3G左右,推理速度:85ms左右(RTX4080)

4.2.3 进一步处理:
(1)可加入腐蚀膨胀处理,消除一些小白点等区域;
(2)将变化区域绘制在第二期图上,便于观察;


















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









