







问题描述
读入air_Customer.xls表中航空公司客户乘坐航班记录数据,利用RFM模型和和聚类方法对航空公司的客户价值进行识别,并提出相应的营销方案。
面对激烈的市场竞争,航空公司面临着常旅客流失、竞争力下降和航空资源未充分利用等经营危机。航空公司希望通过建立合理的客户价值评估模型,对客户进行分群,推出了更优惠的营销方式来吸引更多的客户,并制定相应的营销策略,提供个性化的客户服务来改善目前的危机。
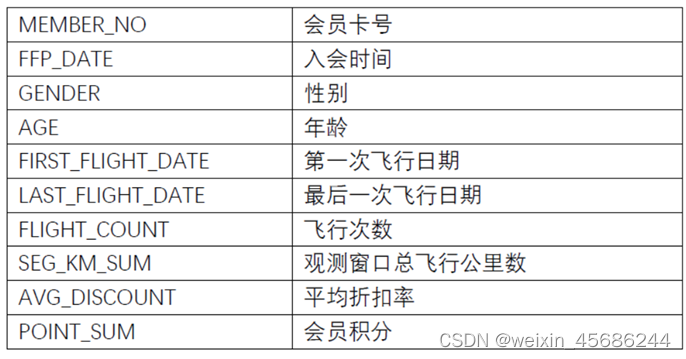
现收集到某航空公司客户乘坐航班记录数据,数据表的字段信息描述如下:
(注:数据表导出日期为2008年4月1日(观测窗口时间))
(1)请根据所给提示结合RFM模型构造新变量LRFMC;
L:会员入会时间距观测窗口结束的月数
R:客户最近一次乘坐公司飞机距观测窗口结束的月数
F:客户在观测窗口内乘坐公司飞机的次数
M:客户在观测窗口内累计的飞行里程
C:客户在观测窗口内乘坐舱位所对应的折扣系数的平均值
(2)在第(1)问的基础上,选择k_means方法对客户进行聚类,选择最优聚类个数,并说明理由。
(3)输出最优聚类的类别特征:各类的类中心点及客户数。
(4)对不同类别的客户进行特征分析,判断不同类别客户的客户价值。
(5)对不同价值的客户类别制定相应的营销策略。
分析
预处理
datafile读文件
resultfile保存这段代码处理后的文件
import pandas as pd
import numpy as np
datafile = 'C:/Users/Administrator/Desktop/dy_homework/air_Customer.csv'
resultfile = 'C:/Users/Administrator/Desktop/dy_homework/explore.xlsx'
data = pd.read_csv(datafile, encoding='utf-8') # 读取原始数据,指定UTF-8编码
explore = data.describe(percentiles=[], include='all').T
# 包括对数据的基本描述,percentiles参数是指定计算多少的分为数表;T是转置,转置后更方便查阅
# print(explore)
explore['null'] = len(data)-explore['count'] # describe函数自动计算非空值数,需要手动计算空值数
explore = explore[['null', 'max', 'min']]
explore.columns = ['空值数', '最大值', '最小值'] # 表头重命名
'''
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、
min(最小值)、50%(中位数)、max(最大值)
'''
explore.to_excel(resultfile)
接下来对异常值进行处理,例如:总飞行公里数要大于0;平均折扣也要在0-1之间;飞行次数也要大于0。
datafile = 'C:/Users/Administrator/Desktop/dy_homework/air_Customer.csv'
cleanedfile = 'C:/Users/Administrator/Desktop/dy_homework/data_cleaned.csv'
data = pd.read_csv(datafile, encoding='utf-8') # 读取原始数据,指定UTF-8编码
# data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] # 票价非空值才保留,SUM_YR是观测窗口的票价收入
data['SEG_KM_SUM(M)'] = data['SEG_KM_SUM(M)'].replace({-1:np.NaN})
data['FLIGHT_COUNT(F)'] = data['FLIGHT_COUNT(F)'].replace({-1:np.NaN})
data['AVG_DISCOUNT(C)'] = data['AVG_DISCOUNT(C)'].replace({0:np.NaN})
# 只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录
# index1 = data['SUM_YR_1'] != 0
# index2 = data['SUM_YR_2'] != 0
index = (data['SEG_KM_SUM(M)'] > 0) & (data['FLIGHT_COUNT(F)'] >0) & (data['AVG_DISCOUNT(C)'] >0) & (data['AVG_DISCOUNT(C)'] <= 1) # 观测窗口的总飞行公里数,平均折扣率,飞行次数不同时为0的数据保留
len(data[index])
2821
到此数据还剩2821个
第一问
接下来就完成第一下问,针对LRFMC五个新变量,我们确定哪些需要通过计算得到,哪些可以直接在表中获得。
data = data[index]
data.to_csv(cleanedfile)
selectedfile = 'C:/Users/Administrator/Desktop/dy_homework/data_selected.csv'
data = data[['ob_time', 'FFP_DATE', 'LAST_FLIGHT_DATE', 'FLIGHT_COUNT(F)', 'SEG_KM_SUM(M)', 'AVG_DISCOUNT(C)']] # 选取指标相关数据
data.to_csv(selectedfile,index=None)
changedfile = 'C:/Users/Administrator/Desktop/dy_homework/data_changed.csv'
selectedfile = 'C:/Users/Administrator/Desktop/dy_homework/data_selected.csv'
data=pd.read_csv(selectedfile, encoding='utf-8')
lt = pd.to_datetime(data['ob_time']) # 将LOAD_TIME转为日期属性
fpd = pd.to_datetime(data['FFP_DATE']) # 将FFP_DATE转为日期属性
data['LOAD_TIME'] = lt - fpd # 得到日期偏移量
lpd = pd.to_datetime(data['LAST_FLIGHT_DATE']) # 将FFP_DATE转为日期属性
data['LAST_TO_END'] = lt - lpd # 得到日期偏移量
data['LOAD_TIME'] = data['LOAD_TIME'].map(lambda x: x/np.timedelta64(1,'M')) # 计算L,转换为月份精度
data['LAST_TO_END'] = data['LAST_TO_END'].map(lambda x: x/np.timedelta64(1,'M')) # 计算L,转换为月份精度
del(data['ob_time'])
del(data['FFP_DATE'])
del(data['LAST_FLIGHT_DATE']) # 删除FFP_DATE列
data
| FLIGHT_COUNT(F) | SEG_KM_SUM(M) | AVG_DISCOUNT(C) | LOAD_TIME | LAST_TO_END | |
|---|---|---|---|---|---|
| 0 | 3 | 18770.0 | 0.658303 | 96.034826 | 6.505267 |
| 1 | 24 | 35087.0 | 0.615947 | 96.034826 | 3.745457 |
| 2 | 9 | 20660.0 | 0.522271 | 95.804842 | 2.759810 |
| 3 | 12 | 23071.0 | 0.511084 | 91.697981 | 0.985647 |
| 4 | 3 | 2897.0 | 0.954166 | 73.759215 | 3.121214 |
| ... | ... | ... | ... | ... | ... |
| 2816 | 11 | 17835.0 | 0.643787 | 73.693505 | 3.022649 |
| 2817 | 2 | 1691.0 | 0.780189 | 73.200682 | 10.316434 |
| 2818 | 10 | 18516.0 | 0.748938 | 74.909136 | 1.182776 |
| 2819 | 12 | 20501.0 | 0.649121 | 60.255857 | 6.965235 |
| 2820 | 18 | 16318.0 | 0.733692 | 74.120618 | 3.811167 |
2821 rows × 5 columns
data.columns = ['F', 'M', 'C','L', 'R'] # 表头重命名
# print(data)
data.to_csv(changedfile,index=False)
explore = data.describe(percentiles=[], include='all')
explore = explore.loc[['min', 'max']]
explore.index = ['最小值', '最大值'] # 表头重命名
print(explore)
F M C L R
最小值 2.0 746.0 0.14 12.057742 0.032855
最大值 139.0 220948.0 1.00 112.987946 23.885501
datafile = 'C:/Users/Administrator/Desktop/dy_homework/data_changed.csv' # 需要进行标准化的数据文件
zscoredfile = 'C:/Users/Administrator/Desktop/dy_homework/zscored_data.xlsx' # 标准差化后的数据存储路径文件
# 标准化处理
data = pd.read_csv(datafile)
data = (data - data.mean(axis=0))/(data.std(axis=0)) # 标准化变换
data.columns = ['Z'+i for i in data.columns] # 表头重命名
print(data)
data.to_excel(zscoredfile, index=False)
ZF ZM ZC ZL ZR
0 -0.595733 0.043707 -0.209124 1.010249 0.211250
1 0.740168 0.764876 -0.498602 1.010249 -0.276537
2 -0.214047 0.127240 -1.138835 1.002927 -0.450747
3 -0.023204 0.233800 -1.215292 0.872166 -0.764325
4 -0.595733 -0.657839 1.812955 0.301004 -0.386870
... ... ... ... ... ...
2816 -0.086819 0.002382 -0.308328 0.298912 -0.404291
2817 -0.659348 -0.711141 0.623909 0.283221 0.884862
2818 -0.150433 0.032481 0.410321 0.337617 -0.729483
2819 -0.023204 0.120213 -0.271879 -0.128936 0.292548
2820 0.358482 -0.064665 0.306122 0.312511 -0.264923
[2821 rows x 5 columns]
第二问
通过拐点法找最优k值
最优聚类个数为4。通过簇内平方和计算最优聚类个数:在不同k值计算簇内离差平方和,然后通过可视化找到“拐点”所对应的k值。随着簇数量增加,簇中样本量会越来越少,导致目标函数值越来越小。重点关注斜率的变化,当斜率突然由大变小时,且之后斜率变化缓慢,则认为突然变化的点就是寻找的目标点。
from sklearn.cluster import KMeans
def k_SSE(X, clusters):
# 选择连续的K种不同的值
K = range(1,clusters+1)
# 构建空列表用于存储总的簇内离差平方和
TSSE = []
for k in K:
# 用于存储各个簇内离差平方和
SSE = []
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 返回簇标签
labels = kmeans.labels_
# 返回簇中心
centers = kmeans.cluster_centers_
# 计算各簇样本的离差平方和,并保存到列表中
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2))
# 计算总的簇内离差平方和
TSSE.append(np.sum(SSE))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与GSSE的关系
plt.plot(K, TSSE, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('簇内离差平方和之和')
# 显示图形
plt.show()
return TSSE
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.cluster import KMeans
TSSE=k_SSE(data,10)
TSSE

[14099.999999999996,
10301.074026505783,
8151.053877330114,
6506.058163441127,
5678.227456785575,
4979.564193265437,
4406.092543286752,
4058.569425309114,
3762.6360291064634,
3528.0051549783893]
进行kmeans求解
from sklearn.cluster import KMeans
outputfile = 'C:/Users/Administrator/Desktop/dy_homework/cluster_result.xlsx'
# 调用K-Means算法,进行聚类分析
kmodel = KMeans(n_clusters=4)
kmodel.fit(data) # 训练模型
# 储存结果
cc = pd.DataFrame(kmodel.cluster_centers_, columns=['ZL','ZR','ZF','ZM','ZC'], index=['客户群1', '客户群2',
'客户群3', '客户群4']) # 查看聚类中心
# print(cc)
labels = kmodel.labels_ # 查看各样本对应的类别
# print(labels)
# print(pd.Series(kmodel.labels_).value_counts().sort_index())
labels = pd.Series(labels).value_counts().sort_index()
# print(labels)
df = pd.DataFrame(labels) # 创建df对象保存结果
df.columns = ['聚类个数']
df.index = ['客户群1', '客户群2', '客户群3', '客户群4']
df = pd.concat([df, cc], axis=1) # 按列标签合并两个表格
# print(df)
df.to_excel(outputfile)
第三问
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体
mpl.rcParams['font.size'] = 12 # 字体大小
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
labels = data.columns #标签
print(labels)
k = 5 #数据个数
plot_data = kmodel.cluster_centers_
print(plot_data)
color = ['b', 'g', 'r', 'c', 'y'] #指定颜色
angles = np.linspace(0, 2*np.pi, k, endpoint=False)
plot_data = np.concatenate((plot_data, plot_data[:,[0]]), axis=1) # 闭合
angles = np.concatenate((angles, [angles[0]])) # 闭合
# print(angles)
fig = plt.figure()
ax = fig.add_subplot(111, polar=True) #polar参数!!
for i in range(len(plot_data)):
ax.plot(angles, plot_data[i], 'o-', color = color[i], label = '客户群'+str(i+1), linewidth=2)# 画线
ax.set_rgrids(np.arange(0.01, 4.0, 0.5), np.arange(-1, 3.0, 0.5), fontproperties="SimHei")
ax.set_thetagrids(angles[0:5] * 180/np.pi, labels, fontproperties="SimHei")
plt.legend(loc = 4)
# plt.show()
plt.savefig('C:/Users/Administrator/Desktop/dy_homework/雷达分析图.jpg',dpi=1000)
Index(['ZF', 'ZM', 'ZC', 'ZL', 'ZR'], dtype='object')
[[-0.28433083 -0.2727946 -0.33890014 -1.14563901 -0.2503591 ]
[ 2.63367953 2.61083606 0.36957347 0.47399235 -0.80651588]
[-0.05017461 -0.06703803 0.14099292 0.74987043 -0.420287 ]
[-0.55648188 -0.52639694 0.07744735 -0.03878303 1.75654073]]
即:
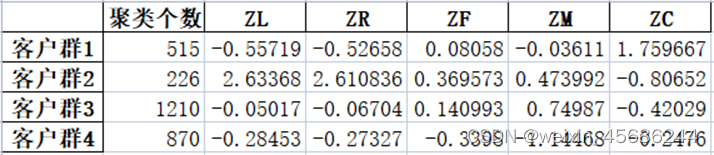

通过雷达图进行后续分析。
第四五问
通过雷达图和表格数据进行分析。
非专业,仅供参考:
根据雷达图分析得到客户群特征描述表:
| 群类别 | 优势特征 | 弱势特征 |
|---|---|---|
| 客户群1 | R(最大)F(最小)M(最小) | |
| 客户群3 | M(最大)F(最大)R(最小) | |
| 客户群3 | L(最大) | |
| 客户群4 | L(最小) |
五个指标的含义为:平均折扣率(C)、最近乘坐过本公司航班(R)、乘坐次数(F)、里程(M)、入会时长(L),根据指标的含义定义四个等级的客户类别:
A. 重要保持客户:这类客户F和M高、R低、C较高。对这类用户,公司应优先将资源投放到他们身上,对他们进行差异化管理和一对一营销,提高这类客户的忠诚度和满意度,尽可能延长这类客户的高水平消费。
B. 重要挽留客户:这类客户L最高,入会时间最长,但M和F相对不高。公司应根据这些客户的最近消费时间、消费次数的变化情况,推测客户消费的异动状况,并列出客户名单,对其重点联系,采取一定营销手段,延长客户的生命周期。
C. 重要发展客户:这类客户L最短,是近期刚入会的客户,虽然M和F都较低,但是潜在价值客户。公司要努力加强这类客户的满意度,增加他们在本公司的乘机消费,提高他们转向竞争对手的转移成本,使他们逐渐成为公司的忠诚客户。
D. 低价值客户:这类客户R最高,F和M最低,L也较短。这类客户黏性低,不建议花费太多资源在这类客户身上。
则:
| 客户群 | 排名 | 排名意义 |
|---|---|---|
| 客户群2 | 1 | 重要保持客户 |
| 客户群4 | 2 | 重要发展客户 |
| 客户群3 | 3 | 重要挽留客户 |
| 客户群1 | 4 | 低价值客户 |


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











