






高级操作系统期末复习文档
选择题
1.shell脚本/C文件执行
shell脚本执行命令
-
使用绝对路径或者相对路径执行。
语法格式:./a.sh
注意事项: 需要文件具有执行权限(chmod +x a.sh) -
使用 sh或bash命令来执行。
语法格式: sh a.sh 不需要执行权限 -x参数(显示执行过程)
注意事项:/bin/sh是早期版本,是一种便携方式的解释性脚本语言,自带有posix便携式功能,以该方式声明的脚本,脚本中间发生错误会终止脚本的运行,不再运行下面的代码。/bin/bash,是/bin/sh的升级版,默认没有开启posix便携模式,所以以/bin/bash声明的脚本,中间即使发生错误,依然会继续向下运行。 -
使用 . (空格)脚本名称来执行。
语法格式:. a.sh
注意事项: 不需要执行权限(特别注意:第一个.后面有空格)
参考文章:Shell编程: shell脚本5种执行方式 | 脚本不同的执行方法和区别_shell方式-CSDN博客
C文件运行(GCC编译)
-
预处理:
gcc -E hello.c //只激活预处理,不生成文件
gcc -E hello.c -o hello.i //预处理。删除所有的#define、#include指令,展开宏定义,见包含的文件插入到预编译指令的位置
-
编译:
gcc-S hello.c //只激活预处理和编译,
gcc-S hello.c-0 hello.s //编译生成hello.s的汇编代码
gcc -S hello.i-o hello.s I/将.i文件生成.s汇编文件
-
汇编
gcc -chello.c//只激活预处理、编译和汇编,生成hello.o的obj(目标)文件
gcc -c hello.s -o hello.o// 目标文件由段组成(如:代码段、数据段等)
objdump -S hello.o//可用反汇编查看
-
链接
gcc -o hello hello.o//动态链接编译8CC -0 hello hello.o -static //静态链接编译
gcc -o hello hello.c//激活预处理、编译、汇编、链接,生成可执行程序,指定目标名称
objdump -S hello //可用反汇编查看
shell脚本和C语言运行上的区别
-
解释器 vs 编译器:
Shell脚本是由Shell解释器逐行解释执行的,不需要编译成可执行文件。
C语言需要先通过编译器编译成可执行文件,然后才能运行。 -
运行效率:
由于Shell脚本是逐行解释执行的,相对C语言来说运行效率较低。
C语言经过编译成机器码后直接执行,因此通常比Shell脚本具有更高的运行效率。 -
语言特性:
Shell脚本适合用于处理文件、系统管理等任务,具有丰富的文件操作和系统调用功能。
C语言则更适合于开发底层系统、应用程序等,具有更丰富的语言特性和功能。 -
调试和错误处理:在调试和错误处理方面,C语言通常比Shell脚本更灵活和强大,可以进行更细致的调试和错误处理。
2.文件目录的操作
文件:
touch 创建一个空文件或更新文件的访问和修改时间
rm 删除文件
cp 复制文件
mv 移动(重命名)文件
目录:
mkdir 创建目录
rmdir/rm -r 删除目录, rmdir只能删除空目录,如果目录中包含文件或其他子目录,则无法删除。rm -r 命令时,可以递归删除目录及其内容,包括非空目录。
cp 复制目录
mv 移动(重命名)目录
3.编译gcc/调试gdb
gcc编译:C文件运行(GCC编译)
gdb调试:
info breakpoint: 显示当前gdb断点信息
break n 设置断点,在第n行设定断点
run (重新)运行调试的程序
next 执行下一步
参考文章:gdb基本命令(非常详细) - 莫水千流 - 博客园 (cnblogs.com)
4.用信号量解决进程同步问题,涉及到的函数
sem_init: 创建信号量
sem_wait: P操作。等待信号量,如果信号量的值大于0,将信号量的值减1,立即返回。如果信号量的值为0,则线程阻塞。相当于P操作。成功返回0,失败返回-1。
sem_post: V操作。释放信号量,让信号量的值加1。如果有其他进程因为执行sem_wait而被阻塞,其中的一个将被唤醒,以便继续执行。如果没有其他进程在等待sem_wait,sem_post操作只是简单地增加信号量的值。
sem_destroy: 该函数用于对用完的信号量的清理。
参考文献:线程同步之信号量(sem_init,sem_post,sem_wait) - 郑志强Aloha - 博客园 (cnblogs.com)
思考:执行sem_wait:P操作,进程是否一定会阻塞;sem_post:V操作,进程是否一定会被唤醒?
执行 sem_wait 操作的进程不一定会立即阻塞,取决于信号量的当前值。执行 sem_post 操作的进程不一定会唤醒其他进程,取决于是否有其他进程正在等待 sem_wait 操作。
5.在分布式系统中,开源代码的作用代码托管与版本控制。
Git 是一个分布式版本控制系统,用于跟踪文件系统中文件的变化,并协助多人协作开发。
GitHub 是一个基于 Git 的代码托管平台,提供了图形化的界面和一系列协作工具。
Gitee(码云)是一个类似于 GitHub 的代码托管平台,主要面向中国用户。它的主要功能和作用与 GitHub 类似。
Git 是版本控制系统,而 GitHub 和 Gitee 则是基于 Git 的代码托管平台,提供了更多的协作和项目管理工具,方便团队协作和开发。选择使用哪一个平台通常取决于用户的偏好和实际需求。
6.虚拟设备/文件(创建一个设备文件)
- mknod mydev c 66 0 创建一个设备名称为mydev 类型为c字符设备 主设备号为66 次设备号为0
- mknod -m 640 mydev2 c 66 1 创建一个设备名称为mydev2 权限为640 类型为c字符设备 主设备号为66 次设备号为0
参考文献:linux文件类型:设备文件、mknod创建设备文件-阿里云开发者社区 (aliyun.com)
mount:作用:用于挂载文件系统到指定的挂载点(目录)。
fdisk:用于分区表的编辑和管理。
df:作用:用于显示文件系统的磁盘空间使用情况。
du:用于估算文件和目录的磁盘使用空间。
mknod:创建字符设备文件或块设备文件。
lsblk:列出块设备的信息,包括磁盘、分区和挂载点。
mkfs:用于创建文件系统。
二、程序设计与分析(头歌)
任务描述
本关任务:程序 3.c 使用 2 个线程计算从 1 到 200 的累加和,请将其改为用 3 个线程实现, 3 个线程分别完成函数 p1、p2 和 p3 的计算任务,总体功能不变。
相关知识
为了完成本关任务,你需要掌握: 1.多线程程序如何编译; 2.pthread_create 函数的各个参数的含义是什么; 3.主线程结束时,子线程会被杀死吗。
编程要求
程序 3.c 使用 2 个线程计算从 1 到 200 的累加和,请将其改为用 3 个线程实现, 3 个线程分别完成函数 p1、p2 和 p3 的计算任务,总体功能不变。
代码:(//表示修改部分)
下面展示一些 内联代码片。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int sum1 = 0, sum2 = 0;
void *p1(){
int i, tmp = 0;
for (i = 1; i <= 100; i++){
tmp += i;
}
sum1 += tmp;
}
void *p2(){
int i, tmp = 0;
for (i = 101; i <= 200; i++){
tmp += i;
}
sum2 += tmp;
}
void p3(){
printf("sum: %d\n", sum1 + sum2);
}
int main(){
int res;
pthread_t t1,t2;
void *thread_result;
res = pthread_create(&t1, NULL, p1, NULL); // pthread_create函数创建t1线程。
res = pthread_create(&t2,NULL,p2,NULL); // pthread_create函数创建t2线程。
res = pthread_cancel(t1);// 在这里使用 pthread_cancel(t1) 来发送取消请求
res = pthread_cancel(t2);// 在这里使用 pthread_cancel(t2) 来发送取消请求
res = pthread_join(t1, &thread_result); // pthread_join函数等待线程t1的结束,并获取线程的返回值。
res = pthread_join(t2, &thread_result);// pthread_join函数等待线程t2的结束,并获取线程的返回值。
p3();
return 0;
}
pthread_create函数的四个参数分别是:
第一个参数是指向线程标识符的指针,用于存储新创建的线程的标识符。
第二个参数是用于设置线程属性的指针,通常可以将其设置为NULL以使用默认属性。
第三个参数是指向函数的指针,该函数是新线程将执行的函数。
第四个参数是传递给新线程函数的参数。
pthread_join函数的两个参数分别是:
第一个参数是要等待的线程的标识符。
第二个参数是一个指向指针的指针,用于存储线程函数的返回值。
三、综合
1.结构设计
1) 操作系统的两种结构(宏内核Linux和微内核Minix)
宏内核(Monolithic Kernel):
结构:宏内核将操作系统的核心功能封装在一个单一的、大型的内核中。所有的系统服务和功能都运行在同一个地址空间中,直接共享数据结构和函数调用。
通信方式:由于所有服务都在内核地址空间内运行,宏内核的通信更加高效,因为服务之间的调用可以直接进行,无需通过额外的 IPC(进程间通信)机制。
优点:性能通常更好,因为系统服务之间的通信开销较小,直接共享资源。
缺点:内核较为庞大,难以维护和升级。一个组件的错误可能影响整个系统的稳定性。
微内核(Microkernel):
结构:微内核采用模块化设计,将操作系统的核心功能分解为独立的模块。最小的内核只包含基本的调度、内存管理和进程通信功能,而其他系统服务作为用户空间的进程运行。
通信方式:由于服务在用户空间运行,它们通过 IPC 与内核进行通信。这种设计使得系统服务更容易替换和升级。
优点:模块化设计提高了系统的灵活性和可维护性。一个组件的故障通常不会影响整个系统的稳定性。
缺点:可能引入一些性能开销,因为服务之间的通信需要通过 IPC。
举例:
宏内核:Linux、Windows NT、Kylin OS(国产)、Deepin OS(国产)
微内核:QNX、MINIX、L4、RT-Thread(国产)、鸿蒙OS(国产)
2) Linux内核动态加载机制
Linux 内核的动态加载机制允许在运行时加载和卸载模块,而无需重新启动整个系统。这种机制允许用户在系统运行期间添加、移除功能模块,以适应不同的需求。动态加载机制为 Linux 内核提供了灵活性和可扩展性,使得系统可以根据需要动态调整功能和驱动。以下是 Linux 内核动态加载机制的主要方面:
1. 内核模块: 内核模块是一段二进制代码,它可以在运行时加载到 Linux 内核中。模块通常包含功能、驱动程序或文件系统等。
2. 模块符号表: 内核维护一个模块符号表,其中包含了所有已加载模块的函数和数据结构的符号信息。这使得在运行时可以动态解析模块中的符号。
3. 模块参数: 内核模块可以接受参数,这些参数可以在加载模块时传递给它。这允许同一个模块在不同情况下以不同的配置加载。
4. 模块的编译和构建: 内核模块通常是由独立的源代码文件编写的,使用内核源代码中的构建系统进行编译。make 命令和 makefile 文件通常用于构建和编译内核模块。
5. 模块加载和卸载: 使用 insmod 命令可以将模块加载到内核中,而使用 rmmod 命令可以将已加载的模块卸载。这样可以在运行时添加和移除模块。使用dmesg查看打印信息。
6. 模块依赖性: 内核模块可以依赖于其他模块。当加载一个模块时,内核会自动检查并加载该模块所依赖的其他模块。
7. /proc 文件系统: 在 /proc 文件系统中,有一些文件和目录提供了有关已加载模块的信息。例如,/proc/modules 文件列出了当前加载的模块。
8. 动态链接和解析: 内核动态加载机制使用动态链接和解析技术,以便在运行时解析模块的符号和进行函数调用。
2.物理/逻辑CPU
1) 给出实验图,写出物理CPU、每个核的线程数、每个座的核数,计算逻辑CPU
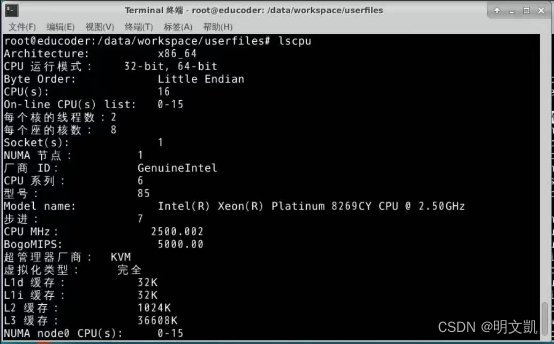
物理 CPU 数量(physical id):1
每个核的线程数(siblings):2
每个物理核的核数(cpu cores):8
逻辑 CPU=物理 CPU 数量 × 每个物理核的核数 × 每个核的线程数
逻辑CPU=1*2*8=16
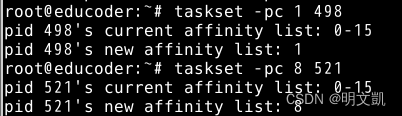
2) 给出实验截图(top),将两个进程绑定到不同的逻辑CPU上。
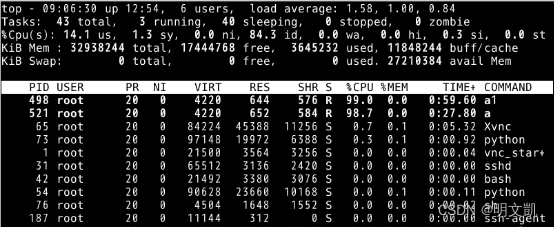
taskset -pc 1 498
taskset -pc 8 521
3.实验结果
1) 内存在地址空间中对应的位置
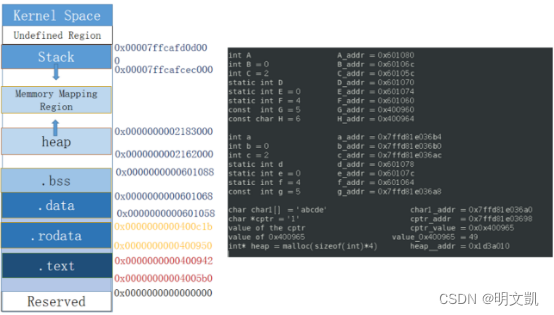
给出左侧信息,将对应的参数位置填到对应段中。
每一段的含义:
1. Stack(栈):栈区用于存放函数调用时需要的参数和局部变量。
栈是一种后进先出(LIFO)的数据结构,用于存储局部变量、函数参数、返回地址和进行函数调用时的上下文切换。栈内存是程序运行时临时分配的内存,用于存储函数执行时的数据。每个线程或进程都有自己的调用栈,栈内存通常在程序启动时分配,并在程序结束时释放。
2. Heap(堆):堆区用于动态分配内存,即 malloc()函数分配的内存。
堆是程序运行时动态分配的内存区域,用于存储通过内存分配函数(如malloc、free、calloc、realloc等)分配的内存。堆内存的大小不是固定的,它可以根据程序的需求动态增长或缩小。堆内存的分配和释放由程序员控制,因此需要谨慎管理以避免内存泄漏。
3. .bss(Block Started by Symbol):初始化数据段,存放程序开始时需要初始化的全局变量。
.bss段通常用于存放程序中未初始化的全局变量和静态变量。在程序启动时,操作系统会自动将.bss段中的所有数据清零。BSS是英文Block Started by Symbol的缩写,它属于静态内存分配。
4. .data(数据段):数据段存放程序运行期间使用的全局变量和静态变量。
.data段用于存放程序中已初始化的全局变量和静态变量。数据段中的数据在程序编译时就已经确定,并在程序运行时被加载到内存中。数据段属于静态内存分配,其中的数据在程序执行期间可以被读取和修改。
5. .rodata(只读数据段):只读数据段,存放常量字符串等不更改的数据。
.rodata段也称为常量数据段,用于存放程序中的常量数据,如字符串常量和已定义的宏。.rodata段通常是只读的,意味着程序在运行时不能修改这些数据。这些数据在编译时就已经确定,并且在程序的生命周期内保持不变。
6. .text(代码段):代码段,包含程序执行所需的机器码。
.text段是程序中的代码段,用于存放程序的指令代码。代码段在程序编译时生成,并在程序运行时被加载到内存中执行。代码段通常是只读的,防止程序在运行时修改其指令。在某些架构中,代码段也可以是可写的,允许在运行时修改程序的行为。
每个段在内存中占据不同的区域,并且在程序执行过程中有不同的作用。程序员在编写程序时需要根据数据的使用特点和内存管理的要求,合理地分配和使用这些不同的内存段。
为什么落在这些段中:
- A在.bss段,A是未初始化的全局变量。
- B在.bss段,B赋初值为0,与未初始化的默认值一样,所以处于.bss段。
- C在.data段,C已赋值为2,已赋值的全局变量处于.data段。
- D在.bss段,同A,D只适用于本文件内。
- E在…bss段,同B。
- F在.data段,同C。
- G和H在.rodata,定义为常量数据,一般程序中不会改变。
- a、b、c属于自动变量,被分配到Stack上
- d、e、f属于静态变量,d、e处于.bss段,是未初始化的静态变量。F处于.data段,是已赋值的静态变量
- g在Stack段,虽然用const修饰但仍然是自动变量,同abc。
- char1属于局部字符数组,局部变量在Stack段。
- cptr字符串指针变量属于自动变量,处于Stack段。
- malloc函数分配的空间在heap上,所以变量heap在heap段上
2) 堆和栈结构的不同
栈:使用后进先出(LIFO)的方式存储数据、通常用于存储函数的参数值、局部变量和返回地址等、空间由系统自动分配和释放。
堆:用于动态分配内存、存储的数据没有固定的大小或生存期、空间的分配和释放需要手动管理。
malloc 函数分配的空间在堆上,这是因为堆(heap)是程序中用于动态内存分配的区域,它的生命周期是由程序员控制的,而不是由函数调用栈决定的。
1. 段出错(Segmentation Fault):通常是由于程序试图访问未分配给它的内存段或者试图在只读内存段执行写操作导致。这可能是指针操作错误、数组越界、访问已释放的内存等引起的。
2. 内存泄漏(Memory Leak):内存泄漏是指程序在使用完内存后未释放该内存,导致程序在运行时持续占用更多的内存。这可能是由于没有正确释放动态分配的内存,或者持续分配而不释放内存。
3. 缓冲区溢出(Buffer Overflow):缓冲区溢出是指程序试图向缓冲区写入超过其预分配大小的数据,导致覆盖了相邻内存的数据。这种情况可能被利用为恶意代码注入或执行。
或生存期、空间的分配和释放需要手动管理。
malloc 函数分配的空间在堆上,这是因为堆(heap)是程序中用于动态内存分配的区域,它的生命周期是由程序员控制的,而不是由函数调用栈决定的。
1. 段出错(Segmentation Fault):通常是由于程序试图访问未分配给它的内存段或者试图在只读内存段执行写操作导致。这可能是指针操作错误、数组越界、访问已释放的内存等引起的。
2. 内存泄漏(Memory Leak):内存泄漏是指程序在使用完内存后未释放该内存,导致程序在运行时持续占用更多的内存。这可能是由于没有正确释放动态分配的内存,或者持续分配而不释放内存。
3. 缓冲区溢出(Buffer Overflow):缓冲区溢出是指程序试图向缓冲区写入超过其预分配大小的数据,导致覆盖了相邻内存的数据。这种情况可能被利用为恶意代码注入或执行。















 2071
2071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









