







YOLO9000: Better, Faster, Stronger
简介
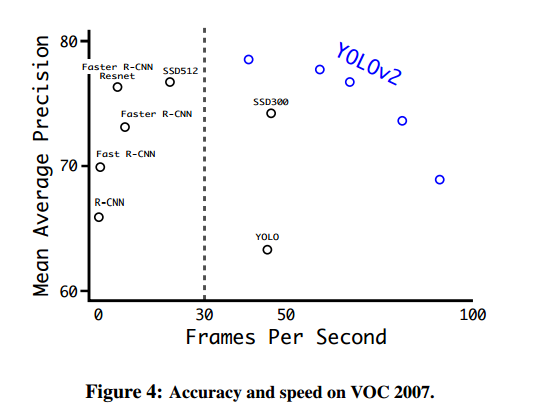
YOLO9000是CVPR2017的最佳论文提名。这篇论文一共介绍了YOLOv2和YOLO9000两种模型,前者是v1的升级版,而后者做了提升可以检测9000多类物体,因此得名。在67帧每秒时,YOLOv2在VOC2007上的精度是76.8。在40帧每秒时,YOLOv2的精度是78.6,超过了主流的方法如Faster R-CNN和SSD,而且速度更快。
基本原理

Better
batch normalization
在GOOGLeNet中提到过。BN对每一个mini-batch数据的内部进行标准化(normalization),使输出规范化到N(0,1)的正态分布,减少了内部神经元分布的改变。
在所有卷积层后增加一个BN,可以有效提升收敛能力,而不需要其他形式的正则化。同时在去除dropout后不必担心过拟合问题。
high resolution classifier
YOLOv2首先在448*448分辨率的ImageNet上微调分类网络,总共10个epochs。这使得网络有时间调整filter,以在更高分辨率的输入上运行。然后在检测数据上微调此输出网络。
convolutional with anchor boxes
作者移除了YOLO中的全连接层,借鉴Faster RCNN使用anchor boxes来预测边框。经过卷积层后得到13*13的特征图,每个cell预测9个建议框,总共预测13*13*9 = 1521个boxes。
YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值,这和SSD比较类似(但SSD没有预测置信度,而是把background作为一个类别来处理)。
dimension clusters
在Faster RCNN中,anchor box的长度是手动设定的,不一定适合所有尺寸的物体。而YOLOv2采用kmeans聚类方法对训练集中的边界框做了聚类分析,采取的评判标准并非传统的欧式距离,因为这会使较大的box产生更大的距离。实际上作者采用IOU来评判,使其与尺度无关。
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box,centroid)=1-IOU(box,centroid) d(box,centroid)=1−IOU(box,centroid)
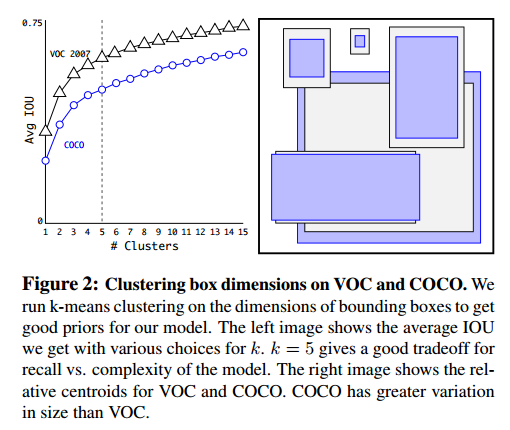
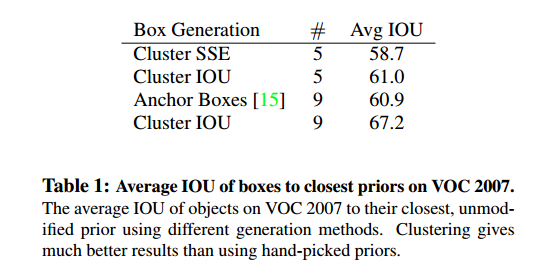
最终是选择了k=5,也就是5种anchor box,但Avg IOU已经达到了Faster RCNN的水平。
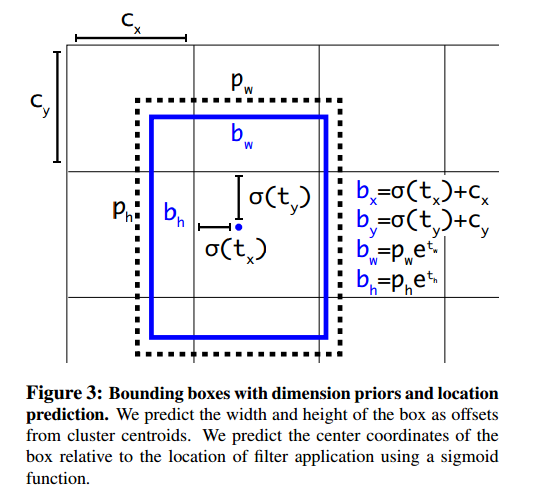
direct location prediction
RPN网络预测边界框位置时
x = ( t x ∗ w a ) + x a y = ( t y ∗ h a ) + y a x=(t_x*w_a)+x_a\\y=(t_y*h_a)+y_a x=(tx∗wa)+xay=(ty∗ha)+ya
其中 ( x , y ) (x,y) (x,y)为预测框, ( t x , t y ) (t_x,t_y) (tx,ty)是偏移值, ( w a , h a ) (w_a,h_a) (wa,ha)为GT的尺寸, ( x a , y a ) (x_a,y_a) (xa,ya)是GT的中心坐标。
yolo2弃用了这种方式,yolo2生成的5个anchorbox中,每个box预测5个坐标, t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to。
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h b_x=\sigma(t_x)+c_x\\b_y=\sigma(t_y)+c_y\\b_w=p_we^{t_w}\\b_h=p_he^{t_h} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
其中网格相对于图片的左上角坐标是 ( c x , c y ) (c_x, c_y) (cx,cy),边框的宽度和高度是 p w , p h p_w,p_h pw,ph, σ ( x ) \sigma(x) σ(x)是Sigmoid激活函数。如下图,虚线框为GT,蓝色框为预测box。
fine-grained features(细粒度特征)
主要是提出了passthrough层,将较高分辨率的特征与较低分辨率的特征连接起来 。比如26*26*26的特征图变为13*13*2048的特征图,使得后续网络可以在这个特征图上运行。
multi-scale training
每10个batches,网络将随机选取新的图片尺寸。由于模型下采样的factor为32,故随机选取的图片尺寸在32的倍数中选择,320,352,···,608。这使得网络能够预测不同分辨率上的物体。
Faster
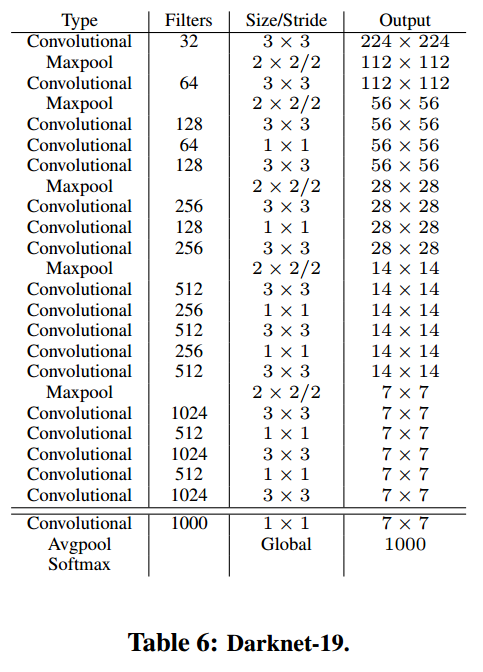
darknet-19
与VGG类似,作者使用3×3的滤波器,在每个池化操作后将通道数加一倍。使用全局average pooling做预测,在3×3的卷积中间使用1×1的滤波器来压缩特征图。作者也使用了BN来稳住训练,加速收敛,以及正则化模型。
training for classification
在有1000类别的ImageNet数据集上使用随机梯度下降(stochastic gradient descent)训练了160epochs,初始学习率0.1。使用了一些数据增强技巧,如随机裁剪(random crops),旋转,色度、亮度的调整等。
在224*224的数据集上初始化网络后,微调到448*448的尺寸。10个epochs,初始学习率设为0.001 。由此获得的top-1精度是76.5%,top-5准确率为93.3%。
training for detection
对于VOC,预测5个boxes,每个box有5个坐标和20个类别,所以一共需要125个filter。
Stronger
YOLO9000提出了在分类和检测数据上共同训练的方法。
hierarchical classification
显然分类和检测数据标签并不全是互斥的,所以不能直接放入softmax。ImageNet的标签是从WordNet中提取的,WordNet是有向图结构,通过构造一个层级树(hierarchical tree)来简化问题。
joint classification and detection
利用Joint training,YOLO9000使用COCO中的检测数据来学习找到图像中的物体,使用ImageNet中的数据来学习分类图像中的物体。
reference:














 2169
2169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









