







 文章探讨了如何对小红书平台上关于数据分析的用户和笔记数据进行客观事实的数据化描述。主要内容包括用户和笔记的多个维度分析,如粉丝数、获赞、收藏数等指标,以及数据异常识别和清洗过程,如处理含有“万”字的数据和拆分关联话题。同时,文章提到了标签字段的关键词频次统计方法。
文章探讨了如何对小红书平台上关于数据分析的用户和笔记数据进行客观事实的数据化描述。主要内容包括用户和笔记的多个维度分析,如粉丝数、获赞、收藏数等指标,以及数据异常识别和清洗过程,如处理含有“万”字的数据和拆分关联话题。同时,文章提到了标签字段的关键词频次统计方法。
客观事实数据化
客观事实:
描述“数据分析”相关的小红书用户。
- 维度:用户名;性别;IP属地;标签
- 指标:关注人数;粉丝人数;获赞与收藏数
- 特征指标:爱学习指数;受欢迎程度
描述“数据分析”相关的小红书笔记内容。
- 维度:用户名;标题;小红书类型;文章类型;发布时间;发布省份;关联话题
- 指标:点赞数;收藏数;评论数;关联话题数
- 特征指标:受欢迎程度
数据摘要
小红书用户数据摘要信息

小红书笔记数据摘要信息

数据异常识别
小红书用户数据异常分析:
- 异常类型:非错误异常(数据类型异常)。粉丝人数、获赞与收藏数两个字段的值中存在“万”字,造成字段类型为“文本”类型,作为指标字段需要将其转化为“数值”类型。
- 价值信息抽取:标签字段内容复杂,不易统计分析,而我们对该字段的关注点有限,通过文本查找的方法从标签字段中获取关键词的出现频次。
小红书笔记数据异常分析:
- 异常类型:非错误异常(数据类型异常)。点赞数、收藏数两个字段的值中存在“万”字,造成字段类型为“文本”类型,作为指标字段需要将其转化为“数值”类型。
- 异常类型:非错误异常(数据维度转换)。关联话题属于一维数据,每个话题之间以分号间隔,可以通过分列拆分每一个话题,然后分组计数每个话题的出现频次。
数据清洗
- 用户数据中粉丝人数、获赞与收藏数以及笔记数据中点赞数、收藏数四个字段中去除“万”字并将文本类型转换为数值类型。
# 新建辅助列,先用RIGHT函数获取该字段值右侧第一个字符,再利用IF函数判断是否是“万”字,最后利用SUBSTITUTE函数将“万”替换掉并×10000,返回计算的值。
=IF(RIGHT(D2,1)="万",SUBSTITUTE(D2,"万","")*10000,D2)
- 利用Excel替换操作和分列进行“万”的去除。
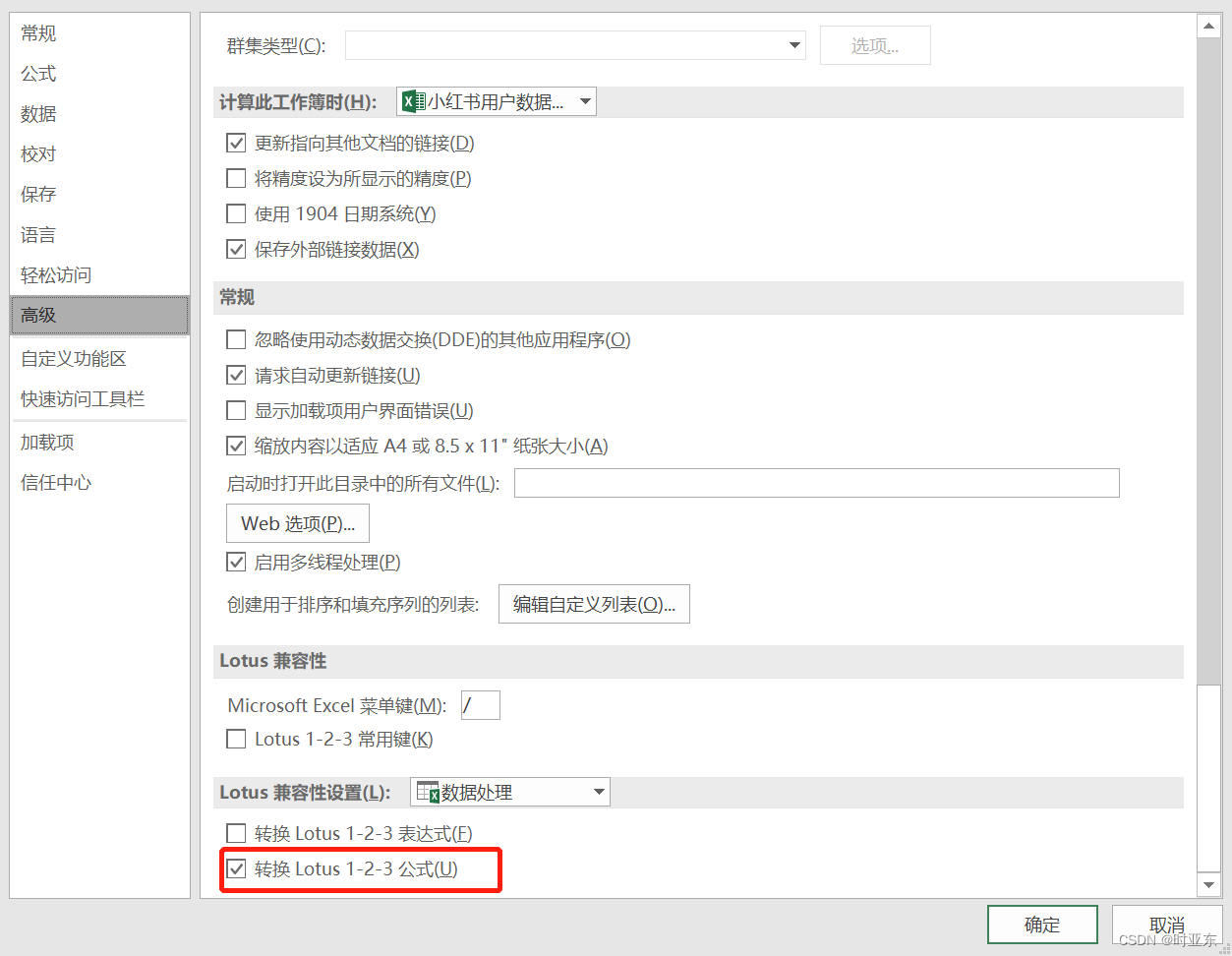
- 第一步:文件 – 选项 – 高级 – 勾选【转换Lotus 1-2-3 公式】
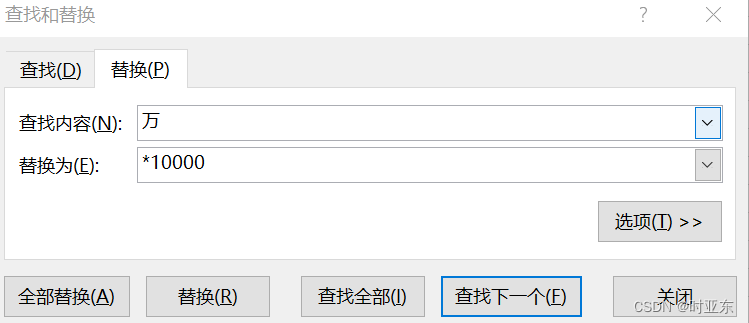
- 第二步:Ctrl+H,调出替换命令窗口,将“万”替换成“*10000”
- 第三步:数据 – 分列 – 下一步 – 完成,当前列中公式完成计算。
- 通过文本查找的方法从标签字段中获取关键词的出现频次。
# 将所有的关键词作为字段名,利用FIND函数依次查找标签中是否包含关键字,存在则返回1,不存在则返回0。
=IF(IFERROR(FIND(J$1,$G2),0)<>0,1,0)
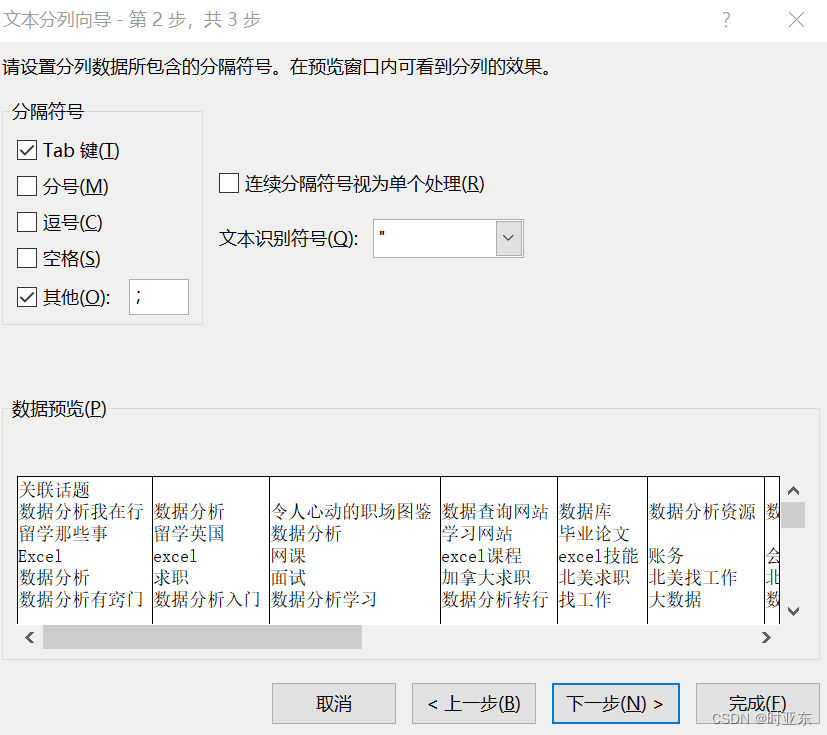
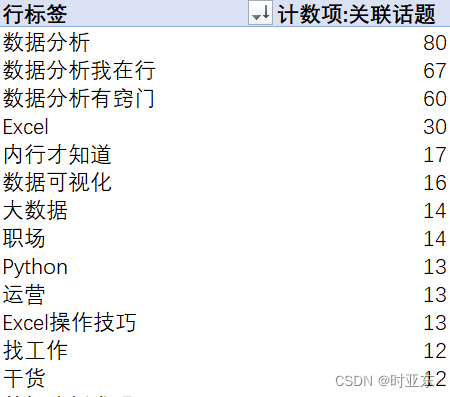
- 关联话题字段分列并分组计数。

















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









