






1.以swin transformer为主干网络的faster rcnn(带FPN)
搞毕设时候用了mmdet的swim-transformer但是刚刚好遇上mmdet版本大更新,于是导致很多小问题,所以我基于pytorch2.0搭建了一个的以swin-transformer为特征提取网络带有FPN的swin faster rcnn。
基本原理如下图
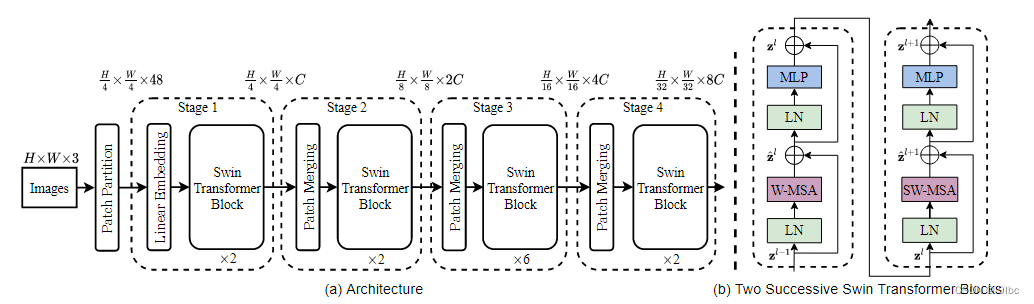

可以看出,我们可以swin-transformer基本看为四个block组成,其中我们可以提取这四个Block的输出,进入FPN以实现多尺度融合的特征图,然后用pytorch的bonewithfpn方法就可以建立一个基本的faster rcnn,再传入pytorch的faster rcnn库就行。不过值得注意的是layernorm导致维度,permute了一下,直接使用pytorch方法会导致四个block得出的特征图不是增加而是递减的效果。
可见代码库中的network_files/get_trans_fpn.py 这一段代码
def forward(self, x):
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = torch.permute(x, [0, 3, 1, 2])
return out在上述代码中,实现了重新permute回到[96, 96 * 2, 96 * 2 * 2, 96 * 2 * 2 * 2]这种递增的特征图形式,mmdet提取的特征也是如此。
先介绍一下环境配置与如何训练自己的数据集,不过代码也有许多没有完成的功能,比如多gpu训练,断点重续等。
最后,如果你要换swin_transformer的预训练模型,例如你想要swin_s模型把下列代码的swin_t换成swin_s,Swin_T_Weights.DEFAULT的T换成S即可。
可换的种类
"Swin_T_Weights",
"Swin_S_Weights",
"Swin_B_Weights",
"Swin_V2_T_Weights",
"Swin_V2_S_Weights",
"Swin_V2_B_Weights",
"swin_t",
"swin_s",
"swin_b",
"swin_v2_t",
"swin_v2_s",
"swin_v2_b",def create_model(num_classes):
backbone = swin_t(weights=Swin_T_Weights.DEFAULT).features2.搭建环境
建立conda 虚拟环境
conda create -n test_swin python=3.8
conda activate test_swin
pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
pip install pycocotools
pip install opencv-python
pip install lxml
到这里就完成基本的环境搭建了,可以train了。
更改pascal_voc_classes.json,改为自己的类别,从1开始,0为backgrroud(不用填),将trian中下段代码改为自己的类别数+1,将自己的voc标准的数据集放入swin_faster\dataset下直接是VOCdevkit,VOCdevkit下是VOC2007
model = create_model(num_classes=7)到这就应该可以训练了。
3.torch的基本方法讲解
所有的任务都要从dataset开始构建,目标检测的dataset构建算是比较复杂的了,总得来说你的数据集类必须有3个方法 init ,在init中你就要完成所有数据与标签的集合,举个例子必须最后你的self.data与lself.abel必须包含所有img,xml文件的路径。
然后就是__getitem__,它一个取数据的功能,假如你的dataset = VOCDataSet(voc_root),当你调用dataset[0]时,他就会返回你所要的数据与标签(要经过处理)。最后时len方法返回长度而已。
class VOCDataSet(Dataset):
"""读取解析PASCAL VOC2007/2012数据集"""
def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"):
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
return image, target
最后调用
val_data_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=1,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)就可以得到一个迭代器,你可以用for循环遍历里面的物品,例如
fo i (image, target) in enumerate(valdataloder)
print(i,image,target)最后就是训练,基本的训练过程,model(image,label)调用是model中forward函数,有时候loss函数就在模型里,外面训练就不要loss函数了。
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.AdamW(params)
for epoch in range(epoches)
for i (image, target) in enumerate(valdataloder)
out=model(image,target)
loss = nn.损失函数(out,label)
optimizer.zero_grad() #基本的反向传播与梯度更新
loss.backward()
optimizer.step()4,数据增强方法
直接转入Dataset类就行,基本格式如下
transforms = {"train":
T.Compose([
T.ToTensor(),
T.Normalize(mean=(0.3946, 0.7648, 0.3659), std=(0.1767, 0.0993, 0.1097)),
# T.ElasticTransform(),
# T.RandomCrop(size = 300),
# T.RandomPerspective(distortion_scale=0.5, p=0.5),
T.RandomHorizontalFlip(),
# ,n
]),
"val": T.Compose(
[T.ToTensor(),
T.Normalize(mean=(0.3946, 0.7648, 0.3659), std=(0.1767, 0.0993, 0.1097))])
}归一化参数计算函数
def get_mean_and_std(dataset): # (tensor([0.3946, 0.7648, 0.3659]), tensor([0.1767, 0.0993, 0.1097]))
'''Compute the mean and std value of dataset.'''
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=0)
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for images, labels in dataloader:
for i in range(3):
mean[i] += images[:, i, :, :].mean()
std[i] += images[:, i, :, :].std()
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std最后,感谢以下项目的开源
pytorch/vision: Datasets, Transforms and Models specific to Computer Vision (github.com)
代码
链接:https://pan.baidu.com/s/19bKf_g0ShTAa-8Qc7Kai3w?pwd=ptod
提取码:ptod
swin transformer论文 http://export.arxiv.org/pdf/2103.14030v2.pdf
想起之前写论文一直写的是swim-transformer就好笑,hhhhhh
最后用什么问题可以在评论区一起探讨。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









