






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
使用MMDetection过程中的问题汇总。官方文档
最近要用swin transformer+maskrcnn实现目标检测,之前没怎么接触过cv。边做边记录。
本文基于代码:open-mmlab/mmdetection
一、环境配置(mmdet 3.3.0)
最低要求:需要 Python 3.7 以上,CUDA 9.2 以上、PyTorch 1.8 及其以上。
我的配置:nvcc 11.4; gcc 7.5.0。装 pytorch1.11.0。
1. 新建虚拟环境
bash conda create -n swin python=3.8 conda activate swin
2. 根据配置安装pytorch(# CUDA 11.3)
!一定要根据官网版本来设定官网版本,不然可能安装成cpu版本
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
3. 安装mmcv
bash pip install -U openmim mim install mmengine mim install "mmcv>=2.0.0"
4. 安装mmdetection
bash git clone https://github.com/open-mmlab/mmdetection.git cd mmdetection pip install -v -e . #"-v" 指详细说明,或更多的输出 #"-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。

5. 验证mmdetection的安装
一些示例代码来执行模型推理。
(1) 下载配置文件和模型权重文件
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
完成后,在当前文件夹中发现两个文件 rtmdet_tiny_8xb32-300e_coco.py 和 rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth。
(2) 推理验证
通过源码安装的 MMDetection,直接运行以下命令进行验证:
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth
在当前文件夹中的 outputs/vis 文件夹中看到一个新的图像 demo.jpg,图像中包含有网络预测的检测框。

二、运行例子
configs/swin下可以看到官方实现的几个mask_rcnn算法,可以根据此文件夹下readme.md找到对应模型config和预训练模型参数
这里采用mask-rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco.py和fp16精度的模型数据
1. 下载预训练模型参数和标注集
新建checkpoints文件夹,用wget下载mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006-90a4008c.pth和mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006.log.json
模型参数https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006-90a4008c.pth
标注集https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006.log.json
2. 检测图片
# image_infer.py
# -*- coding: utf-8 -*-
from mmdet.apis import DetInferencer
# 这里要用绝对位置,因为模型应该是在mmdet里面跑的
config_file = '/home/zyh/code/rcnn-swin-detection/configs/swin/mask-rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco.py'
checkpoint_file='/home/zyh/code/rcnn-swin-detection/checkpoints/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006-90a4008c.pth'
device = 'cuda:0'
# 初始化检测器
inferencer = DetInferencer(model=config_file, weights=checkpoint_file, device=device)
# 推理演示图像
img = 'demo/demo.jpg'
result = inferencer(inputs=img, out_dir='./')

三、一些有用的知识
1. 下载Kaggle数据集
在 Kaggle 中,找到要下载的数据集,并检查数据集的名称和用户 上传数据集。您可以在数据集的 URL 中找到它。https://www.kaggle.com/<USER_NAME>/<DATASET_NAME>
- pip install --user Kaggle
- 导航到 Kaggle 的“帐户”页面。转到 “API”部分,然后选择“创建新的 API 令牌”。
这将触发下载包含 API 凭据的文件。JSON 格式:
https://www.kaggle.com/<USER_NAME>/accountkaggle.json
{"username":<USER_NAME>,"key":<API_KEY>}
- mkdir ~/.kaggle
- mv kaggle.json ~/.kaggle
- cat ~/.kaggle/kaggle.json
- kaggle datasets download <USER_NAME>/<DATASET_NAME>
如果kaggle显示无命令,是环境配置出问题了。在kaggle安装环境(如swin)中执行以下命令。
- echo 'export PATH=/home/zyh/.local/bin:$PATH' >>~/.bashrc
- source ~/.bashrc
2. COCO数据格式
MMDetection 一共支持三种形式应用新数据集:
重新组织为 COCO 格式;
重新组织为一个中间格式;
实现一个新的数据集。
如果数据集格式是 VOC 或者 Cityscapes,可以使用 tools/dataset_converters 直接转化成 COCO 格式。如果是其他格式,可以使用 images2coco 脚本进行转换。
python tools/dataset_converters/images2coco.py \
${IMG_PATH} \
${CLASSES} \
${OUT} \
[--exclude-extensions]
四、仿真流程及问题解决
以下均为swin transformer+maskrcnn架构上的测试。
wget https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth

1. 写config,现有模型+更换数据集(微调)
这个例子用的数据集,本身已经是coco标注,但是似乎标注质量不高。
另外我偷懒了一点,只用了val集做所有事情。
(1) 建立config文件
【注意:运行这个文件时,会出现自动生成的config代码,若不想被覆盖,请不要把work_dir设定成当前目录
# -*- coding: utf-8 -*-
# /home/zyh/code/rcnn-swin-detection/map_train_config.py
# 新配置继承了基本配置,并做了必要的修改
_base_ = '/home/zyh/code/mmdetection/configs/swin/mask-rcnn_swin-t-p4-w7_fpn_1x_coco.py'
# 我们还需要更改 head 中的 num_classes 以匹配数据集中的类别数
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1), mask_head=dict(num_classes=1)))
max_epochs=1
train_cfg = dict(max_epochs=1)
# 修改数据集相关配置
data_root = '/data/zyh/mapchallenge/'
metainfo = {
'classes': ('building', ),
'palette': [
(220, 20, 60),
]
}
train_dataloader = dict(
batch_size=1,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='val/annotation-small.json',
data_prefix=dict(img='val/images/')))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='val/annotation-small.json',
data_prefix=dict(img='val/images/')))
test_dataloader = val_dataloader
# 修改评价指标相关配置
val_evaluator = dict(ann_file=data_root + 'val/annotation-small.json')
test_evaluator = val_evaluator
# 使用预训练的 Mask R-CNN 模型权重来做初始化,可以提高模型性能
load_from = '/home/zyh/code/rcnn-swin-detection/checkpoints/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth'
work_dir = '/home/zyh/code/rcnn-swin-detection/checkpoints/'
(2) 运行
用的是自带的mmdetection/tools/train.py文件,把args里面的元素都加上了–(如config变–config)
python train.py --config ./map_train_config.py
多GPU训练
# sh_train.sh
export CUDA_VISIBLE_DEVICES='0,1'
GPUS=2
CHECKPOINT_FILE='None'
python -m torch.distributed.launch \
--nproc_per_node=$GPUS \
train.py \
--config='./map_train_config.py' \
--launcher pytorch
--resume=${CHECKPOINT_FILE}
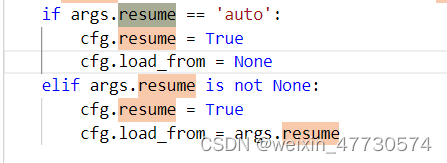
resume:代表继续训练
auto:如果 load_from 为 None,将恢复 work_dir 中的最新检查点
※ 补充:
(1) 出现 loss为nan的情况
各种原因的详细解决方案
一般如果gpu个数多batchsize大都要让lr线性变大,相反gpu少、batchsize小要让lr线性缩小
(2) resume、load-from、pretrained的区别
原答案地址1;原答案地址2
resume 和 load-from 的区别:
resume 既加载了模型的权重和优化器的状态,也会继承指定 checkpoint 的迭代次数,不会重新开始训练。load-from 则是只加载模型的权重,它的训练是从头开始的,经常被用于微调模型。其中load-from需要写入配置文件中,而resume作为命令行参数传入。
resume和pretrained的区别
pretrained用于加载主干权重(backbone),而且自动下载。
若要微调,应该使用 .load_from用于加载整个模型权重(包括necks, heads, etc.),必须手动下载。
(3) 如何修改训练参数?
官网支持在config文件中delete掉继承的设置并覆盖。_delete_=True
在这个例子的base文件_base_ = '/home/zyh/code/mmdetection/configs/swin/mask-rcnn_swin-t-p4-w7_fpn_1x_coco.py'中,有max_epochs = 12 train_cfg = dict(max_epochs=max_epochs),所以应该在自定义的文件中加入
max_epochs=1
train_cfg = dict(max_epochs=1)
若想修改具体类型的值,可以参考以下方法(如:把基于epoch次数变为基于迭代次数)
train_cfg = dict(
_delete_=True, # 忽略继承的配置文件中的值(可选)
type='IterBasedTrainLoop', # iter-based 训练循环
max_iters=90000, # 最大迭代次数
val_interval=10000) # 每隔多少次进行一次验证
(4) 认识config文件
在运行这个bash文件时自动生成的config文件就能看出config的一般结构【尝试注释
# 基本设置
auto_scale_lr = dict(base_batch_size=16, enable=False)
backend_args = None
data_root = '/data/zyh/mapchallenge/'
dataset_type = 'CocoDataset'
default_hooks = dict(
checkpoint=dict(interval=1, type='CheckpointHook'),
logger=dict(interval=50, type='LoggerHook'),
param_scheduler=dict(type='ParamSchedulerHook'),
sampler_seed=dict(type='DistSamplerSeedHook'),
timer=dict(type='IterTimerHook'),
visualization=dict(type='DetVisualizationHook'))
default_scope = 'mmdet'
env_cfg = dict(
cudnn_benchmark=False,
dist_cfg=dict(backend='nccl'),
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
launcher = 'pytorch'
load_from = '/home/zyh/code/rcnn-swin-detection/checkpoints/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth'
log_level = 'INFO'
log_processor = dict(by_epoch=True, type='LogProcessor', window_size=50)
max_epochs = 1
metainfo = dict(
classes=('building', ), palette=[
(
220,
20,
60,
),
])
# 模型部分,模块如下
# data_preprocessor、backbone、neck(FPN)、rpn_head
# roi_head(bbox_roi_extractor、bbox_head、mask_roi_extractor、mask_head(和前面一样只不过用了mask))
# train_cfg(rpn和rcnn训练超参数)、test_cfg = dict(rpn 和 rcnn 测试超参数)
model = dict(
# backbone: swin transformer
# mmdetection/mmdet/models/backbones/swin.py
backbone=dict(
attn_drop_rate=0.0,
convert_weights=True,
depths=[
2,
2,
6,
2,
],
drop_path_rate=0.2,
drop_rate=0.0,
embed_dims=96,
init_cfg=dict(
checkpoint=
'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth',
type='Pretrained'),
mlp_ratio=4,
num_heads=[
3,
6,
12,
24,
],
out_indices=(
0,
1,
2,
3,
),
patch_norm=True,
qk_scale=None,
qkv_bias=True,
type='SwinTransformer',
window_size=7,
with_cp=False),
# 数据预处理: DetDataPreprocessor
# mmdetection/mmdet/models/data_preprocessors/data_preprocessor.py
data_preprocessor=dict(
bgr_to_rgb=True,
mean=[
123.675,
116.28,
103.53,
],
pad_mask=True,
pad_size_divisor=32,
std=[
58.395,
57.12,
57.375,
],
type='DetDataPreprocessor'),
# neck: FPN
neck=dict(
in_channels=[
96,
192,
384,
768,
],
num_outs=5,
out_channels=256,
type='FPN'),
# roi_head: StandardRoIHead
roi_head=dict(
bbox_head=dict(
bbox_coder=dict(
target_means=[
0.0,
0.0,
0.0,
0.0,
],
target_stds=[
0.1,
0.1,
0.2,
0.2,
],
type='DeltaXYWHBBoxCoder'),
fc_out_channels=1024,
in_channels=256,
loss_bbox=dict(loss_weight=1.0, type='L1Loss'),
loss_cls=dict(
loss_weight=1.0, type='CrossEntropyLoss', use_sigmoid=False),
num_classes=1,
reg_class_agnostic=False,
roi_feat_size=7,
type='Shared2FCBBoxHead'),
bbox_roi_extractor=dict(
featmap_strides=[
4,
8,
16,
32,
],
out_channels=256,
roi_layer=dict(output_size=7, sampling_ratio=0, type='RoIAlign'),
type='SingleRoIExtractor'),
mask_head=dict(
conv_out_channels=256,
in_channels=256,
loss_mask=dict(
loss_weight=1.0, type='CrossEntropyLoss', use_mask=True),
num_classes=1,
num_convs=4,
type='FCNMaskHead'),
mask_roi_extractor=dict(
featmap_strides=[
4,
8,
16,
32,
],
out_channels=256,
roi_layer=dict(output_size=14, sampling_ratio=0, type='RoIAlign'),
type='SingleRoIExtractor'),
type='StandardRoIHead'),
# rpn_head: RPNHead
rpn_head=dict(
anchor_generator=dict(
ratios=[
0.5,
1.0,
2.0,
],
scales=[
8,
],
strides=[
4,
8,
16,
32,
64,
],
type='AnchorGenerator'),
bbox_coder=dict(
target_means=[
0.0,
0.0,
0.0,
0.0,
],
target_stds=[
1.0,
1.0,
1.0,
1.0,
],
type='DeltaXYWHBBoxCoder'),
feat_channels=256,
in_channels=256,
loss_bbox=dict(loss_weight=1.0, type='L1Loss'),
loss_cls=dict(
loss_weight=1.0, type='CrossEntropyLoss', use_sigmoid=True),
type='RPNHead'),
test_cfg=dict(
rcnn=dict(
mask_thr_binary=0.5,
max_per_img=100,
nms=dict(iou_threshold=0.5, type='nms'),
score_thr=0.05),
rpn=dict(
max_per_img=1000,
min_bbox_size=0,
nms=dict(iou_threshold=0.7, type='nms'),
nms_pre=1000)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
ignore_iof_thr=-1,
match_low_quality=True,
min_pos_iou=0.5,
neg_iou_thr=0.5,
pos_iou_thr=0.5,
type='MaxIoUAssigner'),
debug=False,
mask_size=28,
pos_weight=-1,
sampler=dict(
add_gt_as_proposals=True,
neg_pos_ub=-1,
num=512,
pos_fraction=0.25,
type='RandomSampler')),
rpn=dict(
allowed_border=-1,
assigner=dict(
ignore_iof_thr=-1,
match_low_quality=True,
min_pos_iou=0.3,
neg_iou_thr=0.3,
pos_iou_thr=0.7,
type='MaxIoUAssigner'),
debug=False,
pos_weight=-1,
sampler=dict(
add_gt_as_proposals=False,
neg_pos_ub=-1,
num=256,
pos_fraction=0.5,
type='RandomSampler')),
rpn_proposal=dict(
max_per_img=1000,
min_bbox_size=0,
nms=dict(iou_threshold=0.7, type='nms'),
nms_pre=2000)),
type='MaskRCNN')
# 优化器,可以改学习超参数
optim_wrapper = dict(
optimizer=dict(
betas=(
0.9,
0.999,
), lr=0.0001, type='AdamW', weight_decay=0.05),
paramwise_cfg=dict(
custom_keys=dict(
absolute_pos_embed=dict(decay_mult=0.0),
norm=dict(decay_mult=0.0),
relative_position_bias_table=dict(decay_mult=0.0))),
type='OptimWrapper')
# 可选的scheduler
param_scheduler = [
dict(
begin=0, by_epoch=False, end=1000, start_factor=0.001,
type='LinearLR'),
dict(
begin=0,
by_epoch=True,
end=12,
gamma=0.1,
milestones=[
8,
11,
],
type='MultiStepLR'),
]
# 关于resume 和 load-from 的区别、load-from和pretrained区别,见上
pretrained = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth'
resume = False
#测试参数
test_cfg = dict(type='TestLoop')
test_dataloader = dict(
batch_size=1,
dataset=dict(
ann_file='val/annotation-small.json',
backend_args=None,
data_prefix=dict(img='val/images/'),
data_root='/data/zyh/mapchallenge/',
metainfo=dict(classes=('building', ), palette=[
(
220,
20,
60,
),
]),
pipeline=[
dict(backend_args=None, type='LoadImageFromFile'),
dict(keep_ratio=True, scale=(
1333,
800,
), type='Resize'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='PackDetInputs'),
],
test_mode=True,
type='CocoDataset'),
drop_last=False,
num_workers=2,
persistent_workers=True,
sampler=dict(shuffle=False, type='DefaultSampler'))
test_evaluator = dict(
ann_file='/data/zyh/mapchallenge/val/annotation-small.json',
backend_args=None,
format_only=False,
metric=[
'bbox',
'segm',
],
type='CocoMetric')
test_pipeline = [
dict(backend_args=None, type='LoadImageFromFile'),
dict(keep_ratio=True, scale=(
1333,
800,
), type='Resize'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='PackDetInputs'),
]
# 训练参数
train_cfg = dict(max_epochs=1, type='EpochBasedTrainLoop', val_interval=1)
train_dataloader = dict(
batch_sampler=dict(type='AspectRatioBatchSampler'),
batch_size=1,
dataset=dict(
ann_file='val/annotation-small.json',
backend_args=None,
data_prefix=dict(img='val/images/'),
data_root='/data/zyh/mapchallenge/',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
metainfo=dict(classes=('building', ), palette=[
(
220,
20,
60,
),
]),
pipeline=[
dict(backend_args=None, type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(keep_ratio=True, scale=(
1333,
800,
), type='Resize'),
dict(prob=0.5, type='RandomFlip'),
dict(type='PackDetInputs'),
],
type='CocoDataset'),
num_workers=2,
persistent_workers=True,
sampler=dict(shuffle=True, type='DefaultSampler'))
train_pipeline = [
dict(backend_args=None, type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(keep_ratio=True, scale=(
1333,
800,
), type='Resize'),
dict(prob=0.5, type='RandomFlip'),
dict(type='PackDetInputs'),
]
# 评价参数
val_cfg = dict(type='ValLoop')
val_dataloader = dict(
batch_size=1,
dataset=dict(
ann_file='val/annotation-small.json',
backend_args=None,
data_prefix=dict(img='val/images/'),
data_root='/data/zyh/mapchallenge/',
metainfo=dict(classes=('building', ), palette=[
(
220,
20,
60,
),
]),
pipeline=[
dict(backend_args=None, type='LoadImageFromFile'),
dict(keep_ratio=True, scale=(
1333,
800,
), type='Resize'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='PackDetInputs'),
],
test_mode=True,
type='CocoDataset'),
drop_last=False,
num_workers=2,
persistent_workers=True,
sampler=dict(shuffle=False, type='DefaultSampler'))
val_evaluator = dict(
ann_file='/data/zyh/mapchallenge/val/annotation-small.json',
backend_args=None,
format_only=False,
metric=[
'bbox',
'segm',
],
type='CocoMetric')
# xxxx
vis_backends = [
dict(type='LocalVisBackend'),
]
visualizer = dict(
name='visualizer',
type='DetLocalVisualizer',
vis_backends=[
dict(type='LocalVisBackend'),
])
# 保存checkpoints位置(以及生成完整config的位置)
work_dir = '/home/zyh/code/rcnn-swin-detection/checkpoints/'
2. 改指定数据集格式
coco数据集格式:
{
"info": {"contributor": "crowdAI.org", "about": "Dataset for crowdAI Mapping Challenge", "date_created": "07/03/2018", "description": "crowdAI mapping-challenge dataset", "url": "https://www.crowdai.org/challenges/mapping-challenge", "version": "1.0", "year": 2018},
"categories": [{"id": 100, "name": "building", "supercategory": "building"},{'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'},{'supercategory': 'vehicle', 'id': 3, 'name': 'car'},..]
"images": [{"id": 20289, "file_name": "000000020289.jpg", "width": 300, "height": 300}, ...],
"annotations": [{"id": 377545, "image_id": 44153, "segmentation": [[152.0, 180.0, 156.0, 176.0, 160.0, 181.0, 156.0, 186.0, 152.0, 180.0]], "area": 42.0, "bbox": [152.0, 152.0, 28.0, 8.0], "category_id": 100, "iscrowd": 0}, ...]
}
(1) 数据集1(已弃用
为了划分训练集/验证集/测试集,我做了一点改动,如下:
# /data/zyh/SAR-Ship-Dataset/voc_xml2json.py
import xml.etree.ElementTree as ET
import os
import json
import glob
import numpy as np
import glob
import shutil
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = 0
image_id = 20180000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
#bbox[] is x,y,w,h
#left_top
seg.append(bbox[0])
seg.append(bbox[1])
#left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
#right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
#right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_files):
for xml_file in xml_files:
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
#elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'path':
file_name = elem.text.split('.xml')[0]
if file_name in category_set:
raise Exception('file_name duplicated')
#add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
#subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox ['xmin'] = None
bndbox ['xmax'] = None
bndbox ['ymin'] = None
bndbox ['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
#option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
#only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
#x
bbox.append(bndbox['xmin'])
#y
bbox.append(bndbox['ymin'])
#w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
#h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id, bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox )
def test():
xml_path = 'Annotations_new'
json_file = 'instances.json'
xml_list = glob.glob(xml_path + "/*.xml")
# print(xml_list[0])
parseXmlFiles(xml_list)
json.dump(coco, open(json_file, 'w'))
if __name__ == '__main__':
PATH ='../ship_data/'
xml_path = 'Annotations_new'
train_ratio = 0.9
save_json_train = '../ship_data/instances_train.json'
save_json_val = '../ship_data/instances_val.json'
xml_list = glob.glob(xml_path + "/*.xml")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_ratio = 0.9
train_num = int(len(xml_list)*train_ratio)
xml_list_train = xml_list[:train_num]
parseXmlFiles(xml_list_train)
with open(save_json_train, 'w') as file:
json.dump(coco, file)
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
xml_list_val = xml_list[train_num:]
parseXmlFiles(xml_list_val)
with open(save_json_val, 'w') as file:
json.dump(coco, file)
# with open(save_json_train, 'r') as file:
# data = json.load(file)
# data['categories'] = coco['categories']
# with open(save_json_train, 'w') as file:
# json.dump(data, file)
if os.path.exists(PATH + "/annotations"):
shutil.rmtree(PATH + "/annotations")
os.makedirs(PATH + "/annotations")
if os.path.exists(PATH + "/images/train"):
shutil.rmtree(PATH + "/images/train")
os.makedirs(PATH + "/images/train")
if os.path.exists(PATH + "/images/val"):
shutil.rmtree(PATH +"/images/val")
os.makedirs(PATH + "/images/val")
with open(PATH + "train.txt", "w") as file:
for xml in xml_list_train:
img = os.path.basename(xml)[:-4]
file.write(img + "\n")
shutil.copyfile("./JPEGImages/"+ img + ".jpg", PATH + "/images/train/" + img + ".jpg")
with open(PATH + "test.txt", "w") as file:
for xml in xml_list_val:
img = os.path.basename(xml)[:-4]
file.write(img + "\n")
shutil.copyfile("./JPEGImages/"+img+ ".jpg", PATH + "/images/train/" + img + ".jpg")
print("-------------------------------")
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
(2) 数据集2(处理中
用的Xview1和github上面的切割,自己改成coco数据集格式。代码有点长,最后会都放出来,现在暂且记录一下。
数据集如果出错:一般是json出问题,注意id的数据类型;还有config文件中的位置、classes要改、num_class要改。
现在在把数据处理和复原整图这部分放到pipeline里面,切片处理+原图拼接
3.
五、其他无关问题
环境设置
- 如果出现无虚拟环境配置时,进行多次conda deactivate,直到无环境。后conda activate [NAME]
解压问题
zip文件过大,按照p7zip下载安装。【可能需要管理员权限】
安装成功后出现找不到7z的情况,可能是因为当前位置7z管不到。将命令行改为/usr/local/bin/7za x train2017.zip即可解决。















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









