







一、正交化
通俗的理解就是:要能够诊断出系统性能瓶颈在哪里,以有策略刚好解决这个问题。一个“按钮”只负责解决一件事情。
二、单一数字评估指标
准确率(precision):在分类器中标记为猫的例子中,有多少是真的猫
召回率(recall):对于所有的真猫图片,你的分类器正确识别了多少。
但如果有两个评估指标,就很难去选择一个更好的分类器,如下图所示。
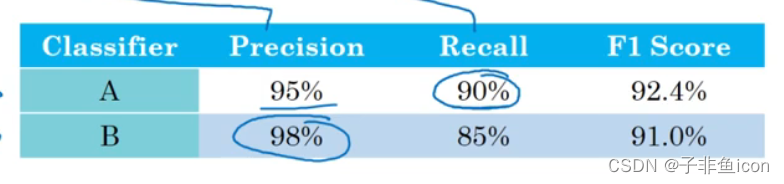
所以有一个结合这两个指标的标准方法,也即F1分数,定义如下:
F 1 = 2 1 P + 1 R F_1 = \frac{2}{\frac{1}{P}+\frac{1}{R}} F1=P1+R12
也叫做P和R的调和平均数。非正式的来说,也可以看成是这两个指标的平均数,只不过不是直接的算术平均。
很多机器学习团队便是如此,有一个定义明确的开发集来测量P和R,再加上这样一个单一数值评估指标,快速判断哪一个分类器性能更好。
三、满足和优化指标
假设已经决定了很看重分类器的分类准确度,这可以是F1分数或者用其他衡量准确度的指标。但除了准确度之外,我们还需要考虑运行时间。
这时,运行时间可以作为一个满足指标,意思是它必须足够的好,例如,只需要小于100ms。而准确度则是一个优化指标,因为想要做得尽可能的准确。
这是一种将准确度和运行时间结合起来的方式。只要运行时间少于100ms,用户可能不在乎是50还是100ms,或者更快。

更一般地,如果要考虑N个指标,选择其中一个指标作为优化指标是合理的,剩下的N-1个指标都是满足指标。
四、训练\开发\测试集划分
开发(dev)集也叫做(development set),有时称为保留交叉验证集(hold out cross validaition set)。
机器学习的工作流程:尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,不断迭代去改善开发集的性能,直到最后可以得到一个令人满意的成本,然后再用测试集去评估。
开发集和测试集要来自同一分布
五、人的表现
贝叶斯最优错误率(Bayes optimal error):理论上可以达到的最优错误率,也就是说没有任何办法设计一个x到y的函数,让它能够超过一定的准确度。
训练的算法即使模型越来越大,数据越来越多,但性能始终无法超过某个理论上限。
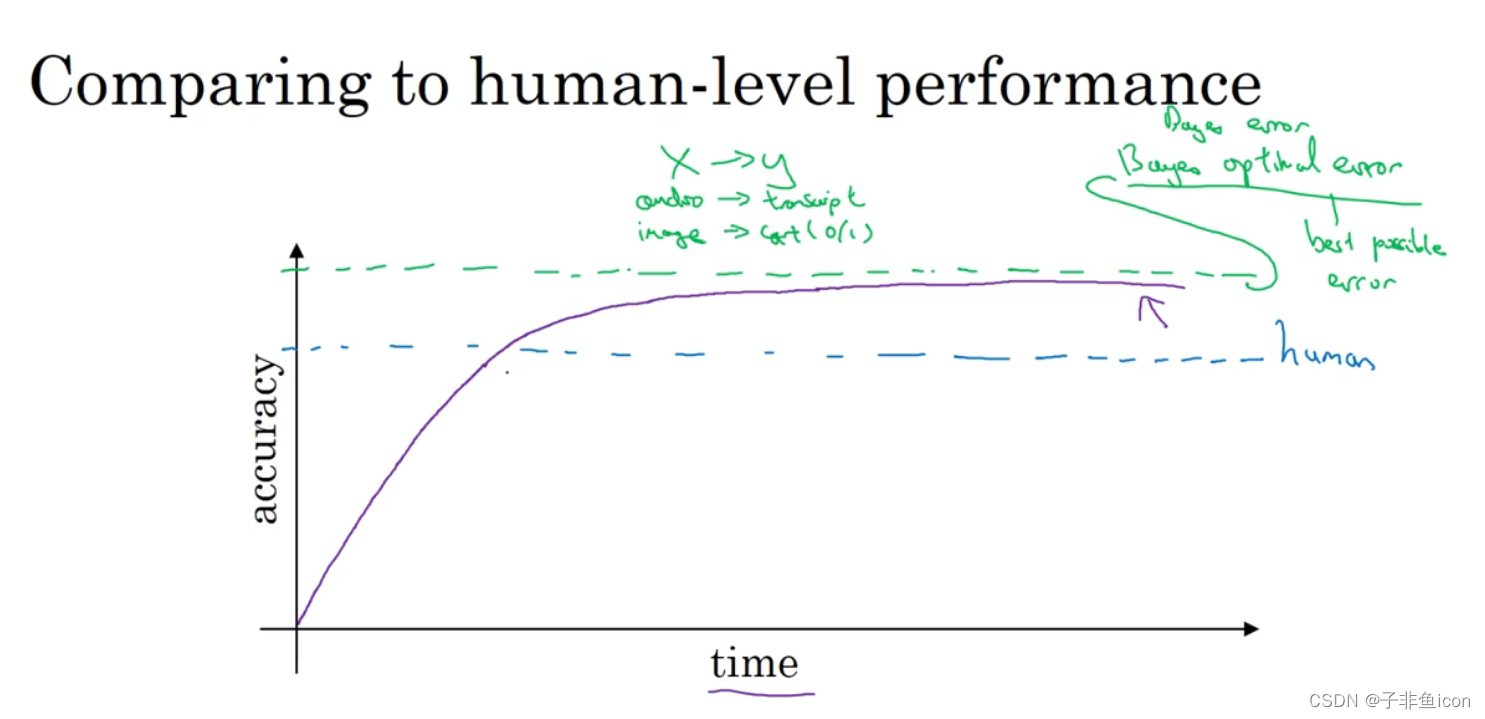
可避免偏差:贝叶斯错误率或者对贝叶斯错误率的估计和训练错误率之间的差值称为可避免偏差。
左边:0.5%是可避免偏差的指标。

选择使用 避免偏差策略还是避免方差策略。
人类水平错误率如何界定?


当接近人类水平时,更难分辨出是偏差还是方差。

六、进行误差分许
主要意思是:找出所有识别错误的结果,然后人工分辨其原因,是把狗识别成猫了,还是把狮子、豹子等识别成猫,还是说图片模糊或者加了滤镜。以统计结果进而确定减小误差的方向。

七、清楚错误标记的数据
监督学习问题的数据由输入x和输出标签y构成,如果观察一下数据,会发现有些输出标签y原本就是错的。


如果这些标记错误严重影响了你在开发集上评估算法的能力,那么就应该去花时间修正错误的标签。但是,如果他们并没有严重影响到用开发集评估成本偏差的能力,那么可能就不应该花宝贵的时间去处理。
开发集的主要目的是:希望用它来从两个分类器A和B中选择一个。
不管采用什么修正手段,都要同时作用到开发集和测试集。
有可能算法判断正确的一些样本也需要修正,因为算法有可能运气好把某个东西判对了。
八、使用来自不同分布的数据进行训练和测试
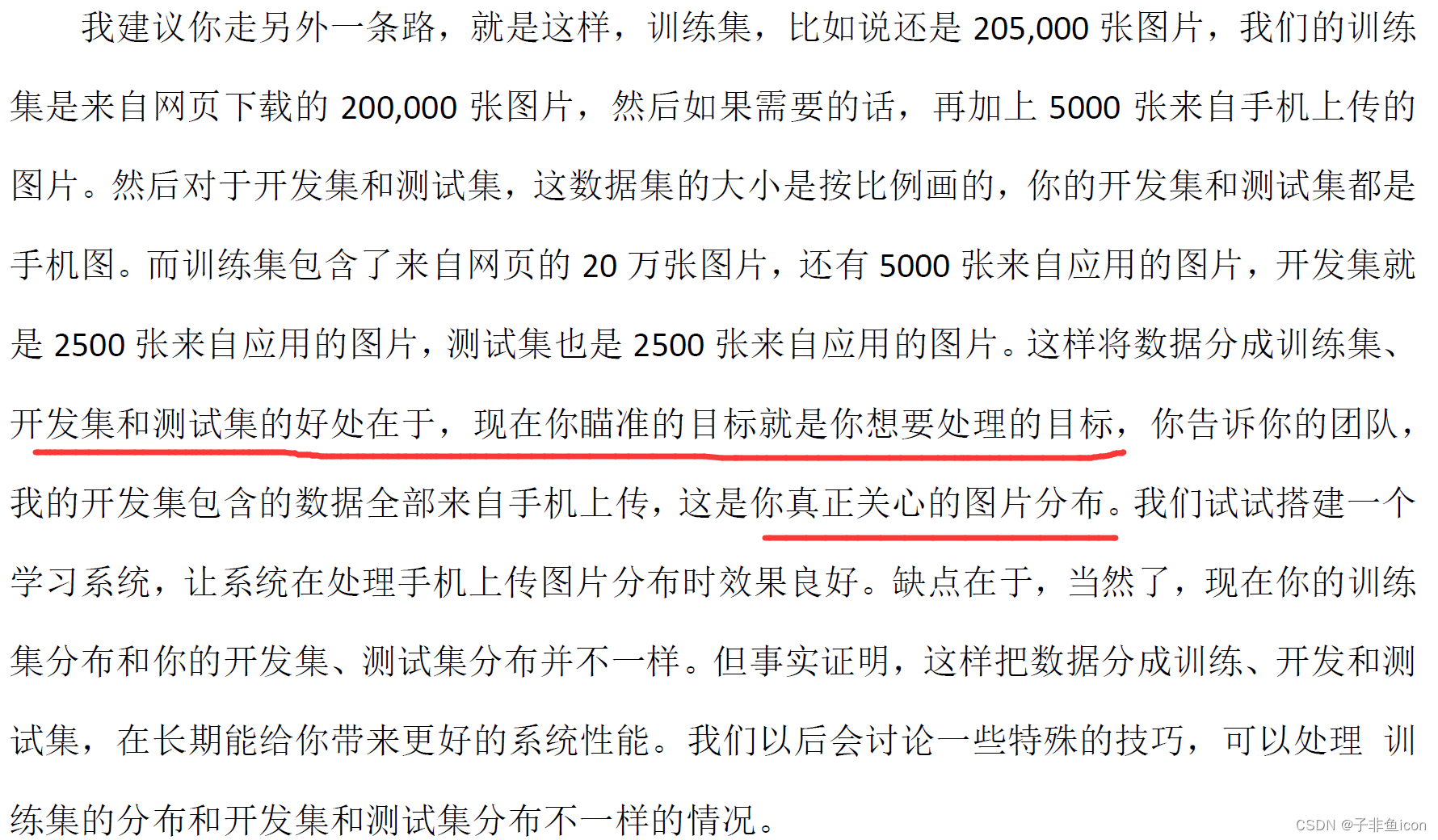
假如有200000张是从网页上下载的猫猫图,很清晰,图片质量很高;但只有10000张用户拍摄的猫猫图,这些图片大多比较模糊。
有一种选择就是,将两组数据组合到一起,这21万张照片随机分配到训练、开发和测试集中。如果确定开发集和测试集各包含2500个样本,训练集就有205000个样本。
好处:训练集、开发集、测试集都来自于同一分布;
坏处:开发集这2500个样本大多来自于网页下载的图片,并不是我真心关注的数据分布,真正要处理的是来自手机的分布。
但并不推荐这样子做!!!
九、数据分布不匹配时的偏差与方差分析
如果开发集和训练集来自同一分布,可能会说,这里存在着很大的方差问题,算法不能很好的从训练集泛化,它处理训练集很好,但处理开发集就突然间效果差了。
但如果训练集和开发集数据不是来自同一分布,这个结论可能就不正确了。因为训练集都是高分辨率的图片,而开发集更难识别。所以也许软件没有方差问题,只不过反映了开发集更难准确识别的图片。当你看训练误差,再看开发集误差,有两件事变了。首先算法 只见过训练集数据,没见过开发集数据。第二,开发集数据来自不同的分布,所以很难说,这增加的9%的误差率,有多少是因为算法没有看到开发集中的数据导致的,这是问题方差的部分,有多少是因为开发集数据就是不一样。

为了分辨清楚两个因素的影响,定义一组新的数据,称之为训练-开发集,这是一个新的数据子集,从训练集的分布中来,但不会用来训练网络。
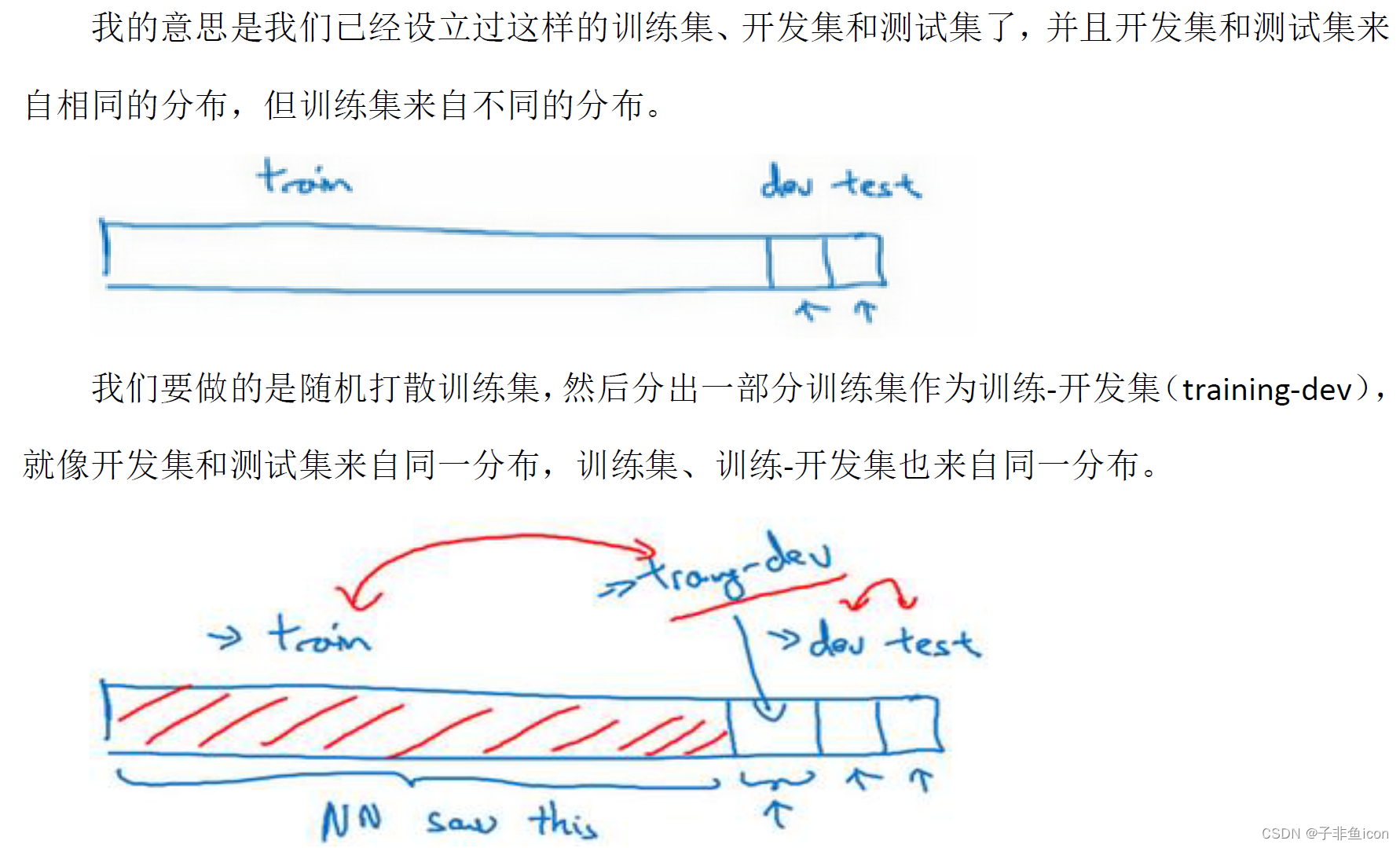
但我们只会在训练集上训练网络,不会在训练-开发集上跑后向传播。
比如这个样本中:
训练误差:1%
训练-开发集误差:9%
开发集误差:10%
结论:算法存在方差问题。因为当从训练数据变到训练-开发集数据时,错误率上升了很多。神经网络能看到第一部分并直接而在上面做了训练,但没有在训练-开发集上直接训练,尽管它们来自同一分布。无法很好的泛化推广到来自同一分布,但以前没见过的数据中,所以这个样本的确存在方差问题。
另一个不同的样本:
训练误差:1%
训练-开发集误差:1.5%
开发集误差:10%
结论:方差问题很小,这是数据不匹配的问题。也即你的算法擅长处理和你关心的数据不同的分布。
这个样本:
训练误差:10%
训练-开发集误差:11%
开发集误差:12%
结论:存在偏差问题。因为人类水平对贝叶斯错误率的估计大概是0%。
最后一个例子:
训练误差:10%
训练-开发集误差:11%
开发集误差:20%
结论:第一,可避免偏差相当高;第二,方差似乎很小,但数据不匹配问题很大(训练-开发集误差和开发集误差相差大)。
一般性原则:

十、解决数据不匹配
发现有严重的数据不匹配问题,要做错误分析,尝试了解训练集和开发测试集的具体差异。技术上,为了避免对测试集过拟合,要做错误分析,应该人工去看开发集而不是测试集。
当了解到开发集误差的性质后,开发集有可能跟训练集不同或者更难识别,可以尝试把训练数据变得更像开发集一些,或者,也可以收集更多类似于开发集和测试集的数据。
人工合成数据的空间子集较小,学习算法可能会对其合成的小子集过拟合。
十一、迁移学习
有时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。例如,你已经训练好了一个神经网络,能够识别猫这样的对象,就可以使用那些知识,或者部分习得的知识去帮助您更好地阅读X射线扫描图。


迁移学习起作用的场合是,在迁移来源问题中有很多数据,但迁移目标问题你没有那么多数据。


十二、多任务学习
在迁移学习中,步骤是串行的,从任务A学习然后迁移到任务B。但在多任务学习中,同时开始学习,试图让单个神经网络同时做几件事情,然后希望这个任务能帮到其他任务。
比如研究无人驾驶,需要同时检测不同的问题,行人、车辆、停车标志等。输入图像 x ( i ) x^{(i)} x(i),输出不再是一个标签,而是有多个标签。
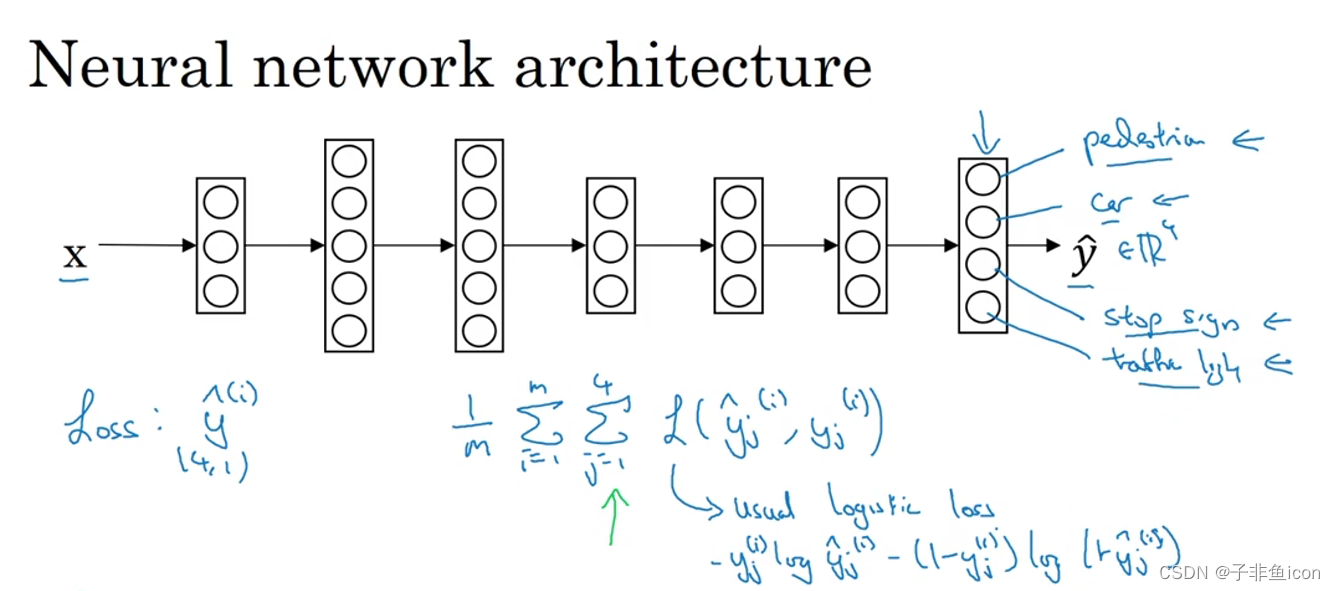
输出是一个四位向量。画了四个节点,第一个节点是预测图中有没有行人,第二个输出节点预测有没有车,第三个输出节点预测有没有停车标志,第四个有无交通灯。
损失计算:

与softmax回归的主要区别在于:softmax将单个标签分配给单个样本,而多任务学习中的每张图可以有很多不同的标签。
另一个细节:如果有些图片含有没有标记的部分,比如给数据贴标签的人只标记了有一个行人,没有车,但没有标记是否有停车标记。
即使是这样的数据集,也可以在上面训练算法,同时做四个任务。这里,计算损失时,就会只对带标签的求和,忽略没有标签的项。
当三件事为真时,多任务学习就是有意义的。



十三、端到端的深度学习
以前有一些数据处理系统或者学习系统,他们需要多个阶段的处理。那么端到端的深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。
端到端的深度学习的挑战之一是:可能需要大量数据才能让系统表现良好。
人脸识别门禁问题:
尝试直接学习图像x到人物身份y的函数映射,这并不是最好的办法。因为人可以从不同角度接近门禁,位置不同,脸的大小也不同。

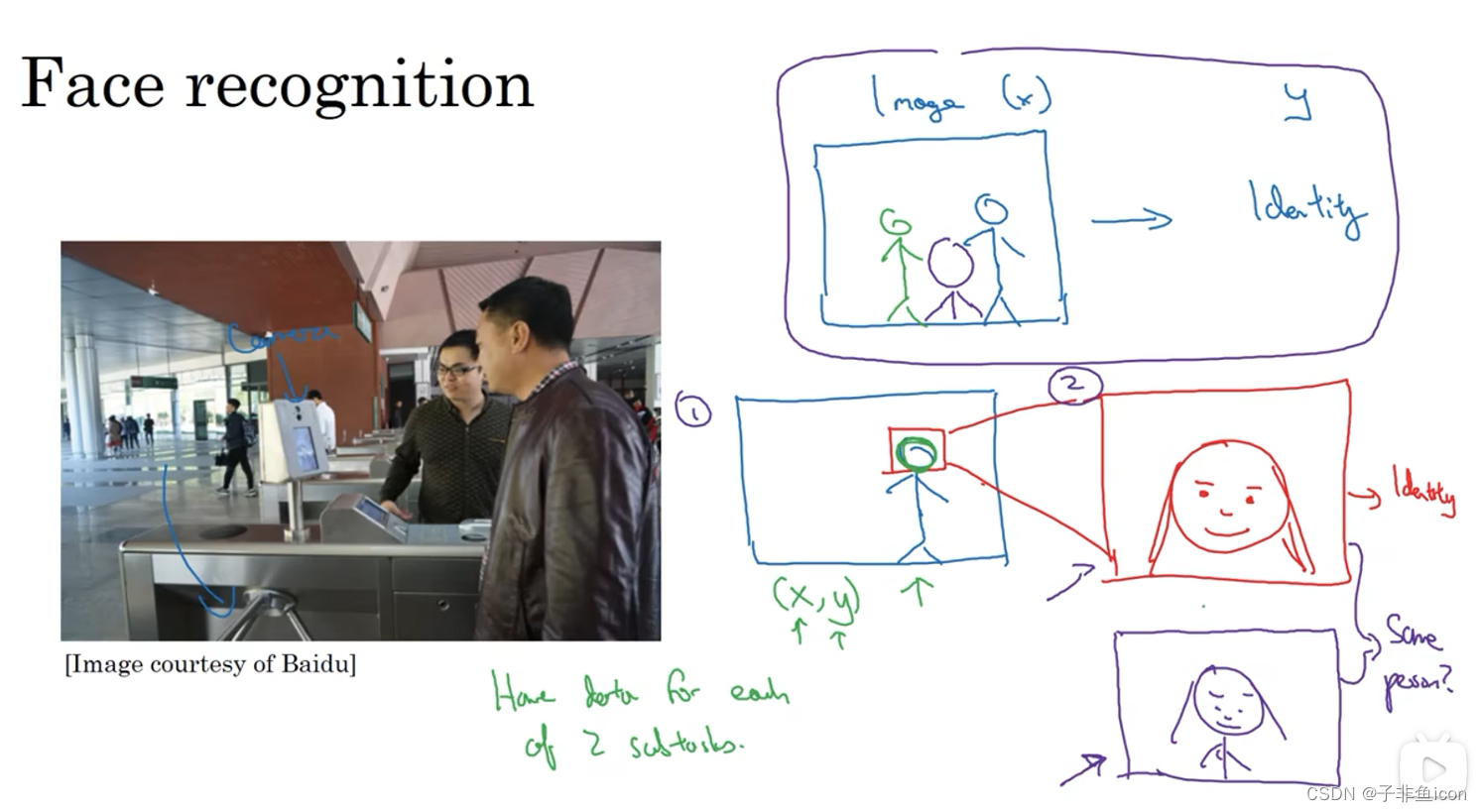

优点和缺点:
















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









