







引入
有些时候答案在深度比较浅的位置,而像我们传统的dfs会先搜索到深的位置,导致浪费很多时间;
比如下图中,打星的地方代表答案;
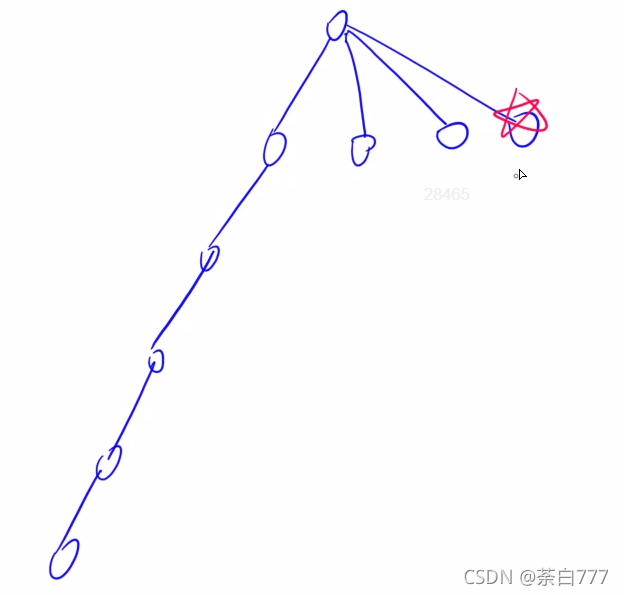
迭代加深有点类似bfs,但是有些题目bfs是做不了的;
我们每次给定一个max_depth,超过这个深度就先剪掉;
然后一圈圈的往外扩展;这tm不就是bfs
跟bfs同理,第一次搜到的就是最小的答案;
与BFS区别?
BFS是用一个队列,每一次都将下一层信息全部扩展进来;
因此需要的空间是指数级别的;
而迭代加深本质上还是DFS,他每一次只会记录一条路径;
因此需要的空间是线性的;
适合的题目
综上所述,迭代加深适合有以下特点的题目;
- 有些分支很深,但是答案很浅;
- 提供给我们的空间不多
- 配合IDA*
重复搜索会不会浪费时间?
因为一颗搜索树,最少也有两个结点;
假设我们搜索第 k k k层,我们会重复搜索第 1 1 1层到第 k − 1 k-1 k−1层;
但是我们求和后发现, 2 1 + 2 2 + . . . + 2 k − 1 = 2 k − 1 2^1+2^2+...+2^{k-1}=2^k-1 21+22+...+2k−1=2k−1;
前面之和比第 k k k层要搜索的还少,因此是可以忽略不记的;
且这是最坏情况;
当一颗搜索树不止两个结点的时候(有更多结点的情况),更加可以忽略不计了;
因为时间复杂度我们往往只看花费时间最多的地方;
例题
加成序列
题面

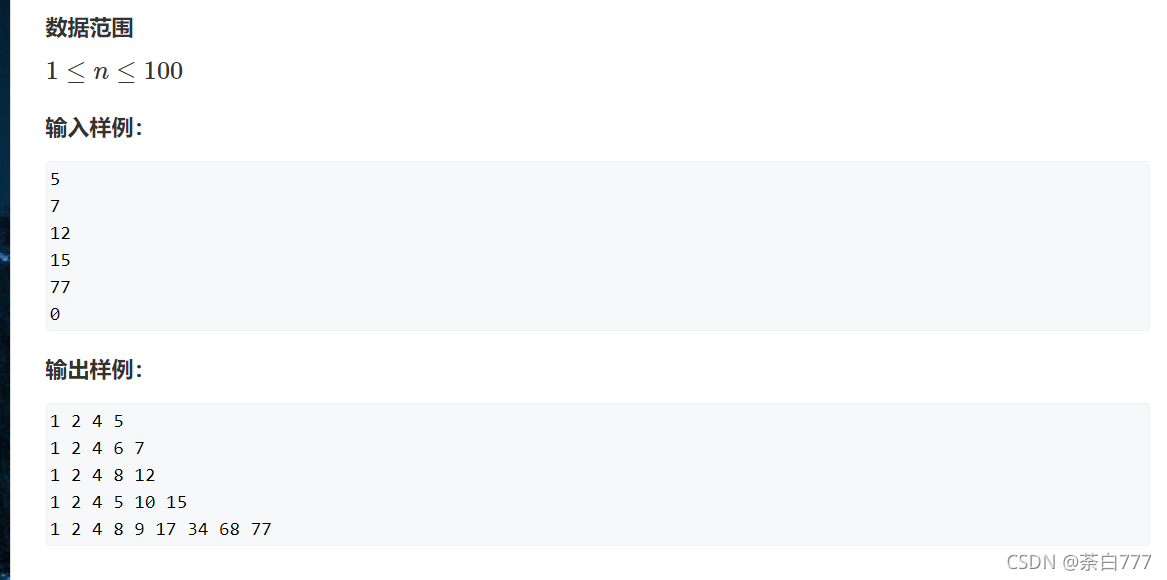
思路
因为数据范围有100,所以普通的dfs会搜索的比较深;
而假定我们的 n = 128 n=128 n=128,我们发现 1 , 2 , 4 , 8 , 16 , 32 , 64 , 128 1,2,4,8,16,32,64,128 1,2,4,8,16,32,64,128
翻倍着跳是 l o g log log级别的,因此深度必然不会很深;
因此我们可以考虑迭代加深;
不难想到,从第一个数 1 1 1开始搜,肯定是能搜到解的;
接着考虑剪枝;
剪枝一、
优化搜索顺序,我们希望当前的分支越少越好;
因此我们应该先枚举大的数,再枚举小的数;
剪枝二、
消除等效冗余,显然这道题用组合即可,而不需要排列;
因为 1 + 2 = 3 1+2=3 1+2=3, 2 + 1 = 3 2+1=3 2+1=3,枚举一次就够了;
而且我们发现, 1 + 4 = 5 1+4=5 1+4=5, 2 + 3 = 5 2+3=5 2+3=5,等号右边的数可能被重复搜索;
因此我们可以用一个布尔数组来去重;
剪枝三、
可行性剪枝,序列必须是递增的且不能超过 n n n
Code
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long ll;
const int N = 1e2 + 10;
int n;
bool vis[N];
int path[N];
//当前的层数、最深的层数
bool dfs(int u,int dep){
if (u == dep) return path[u - 1] == n;
//剪枝、优化搜索顺序
//剪枝、枚举组合数
for(int i=u-1;i>=0;--i){
for(int j=i;j>=0;--j){
int s = path[i] + path[j];
//剪枝、可行性剪枝
//剪枝、消除等效冗余
if(s < path[u-1]) return false;//从大到小枚举的,现在都不行,以后更不行
if(s > n || vis[s]) continue;
vis[s] = 1;
path[u] = s;
if(dfs(u+1,dep)) return true;
vis[s] = 0;
}
}
return false;
}
void solve(){
memset(vis,0,sizeof vis);
int dep = 1;
//第0层肯定是1,因此我们从第1层开始搜
while(!dfs(1,dep)) ++dep;
for(int i=0;i<dep;++i){
cout << path[i] << ' ';
}
cout << '\n';
}
int main(){
std::ios::sync_with_stdio(false),cin.tie(0),cout.tie(0);
path[0] = 1;
while(cin >> n,n)
solve();
return 0;
}














 1943
1943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









