






目录
(写这篇博客的意义在于之后方便之后重装不用再重新看一大堆博客了)
我的电脑配置为y9000p(2022),12i7,3060的显卡 pycharm版本为2022.2,cuda版本为11.6.2
cudnn版本为8.4.1,tensorrt版本为8.4.1
一.pycharm的安装
官方的安装连接:Download PyCharm: Python IDE for Professional Developers by JetBrains
下载下来后先不着急可以先把pycharm固定到收藏夹上
cd ~/.local/share/applications/
sudo gedit Pycharm.desktop之后将下方文字复制进去(注意注释!)
[Desktop Entry]
Version=1.0
Terminal=false
Type=Application
Name=Pycharm
Exec=/opt/pycharm/bin/pycharm.sh
# 注意:Exec表示安装软件的**启动快捷方式**文件路径
# 注意:Icon表示安装软件的图标路径
Icon=/opt/pycharm/bin/pycharm.png
NoDisplay=false
StartupWMClass=
之后就可以把pycharm固定到收藏夹上
二.minconda的安装
miniconda安装的时候如果采用sudo则以后使用conda命令需要加sudo
这里选择的是miniconda因为我服务器上面之前配置的也是miniconda为了向服务器看齐,这里的话如果安装的是anconda的话window环境下anconda的env拷贝进来好像是可以直接用的,这个我还没有尝试过。
miniconda的地址:Index of /anaconda/miniconda/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
anconda的地址:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
minconda和anconda的差别就是anconda的base环境包括了conda管理器、Pyhon编译器、常用的包和Spyder IDE等,而miniconda的base环境选择只包括conda管理器和Python编译器
然后选择你下载下来的sh进行安装
sudo bash Miniconda3-py39_4.9.2-Linux-x86_64.sh三.Nvdia显卡的安装
首先是关于显卡的卸载,我们可以进入附加驱动中选择x.org选项就相当于把本来的显卡驱动删除了,如果你有两个显示屏的话安装完显卡驱动后副屏才可以用因为副屏是挂载在你的独显上
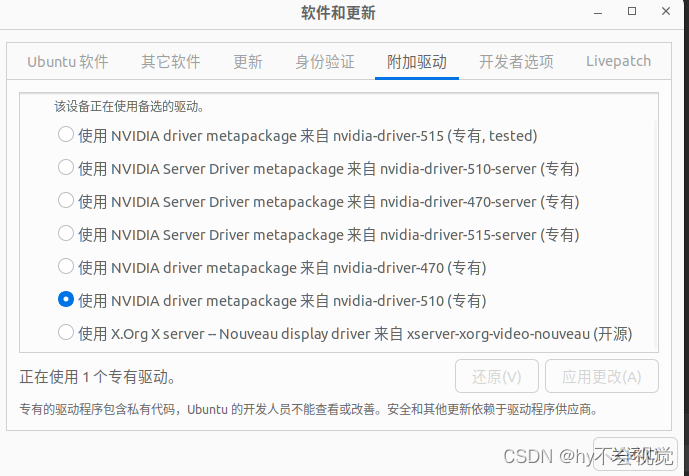
显卡安装不建议用附加驱动,因为很慢,所以可以换源后直接用命令行安装
ubuntu-drivers devices这是可用的显卡
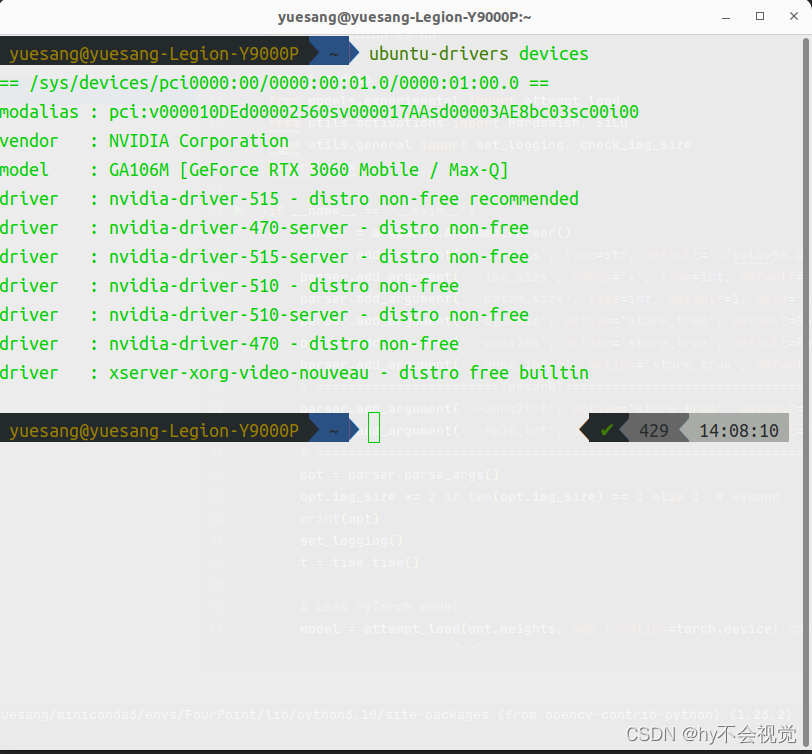
在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau:可以先通过指令lsmod | grep nouveau查看nouveau驱动的启用情况,如果有输出表示nouveau驱动正在工作,如果没有内容输出则表示已经禁用了nouveau(这里我没有图所以找了一张网上的)
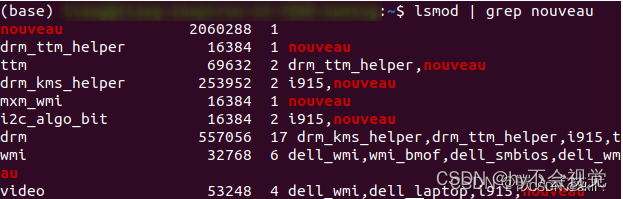
电脑有有输出,表示nouveau启动了,下面进行nouveau的禁用
sudo gedit /etc/modprobe.d/blacklist.conf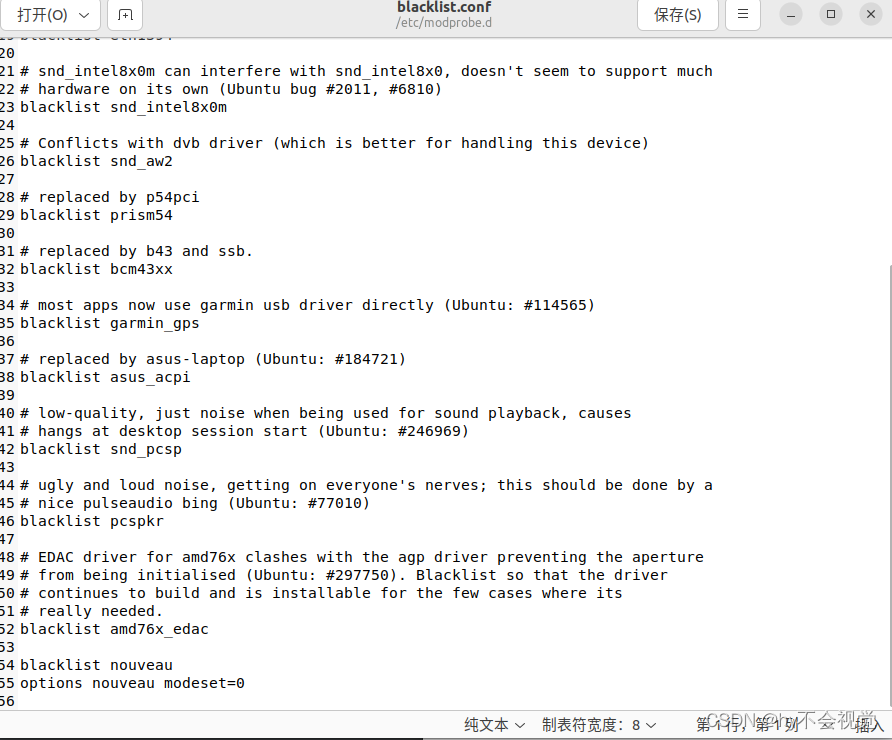
在blacklist.conf文件末尾加上这两行,并保存:
blacklist nouveau
options nouveau modeset=0
然后在终端中输入:
sudo update-initramfs -u #应用更改
选择合适的显卡进行下载(可以进入官网查看cuda和显卡的对应版本:Release Notes :: CUDA Toolkit Documentation)
sudo apt install nvidia-driver-510 # 根据自己的n卡可选驱动下载显卡驱动重启电脑后
nvidia-smi
查看是否安装完成
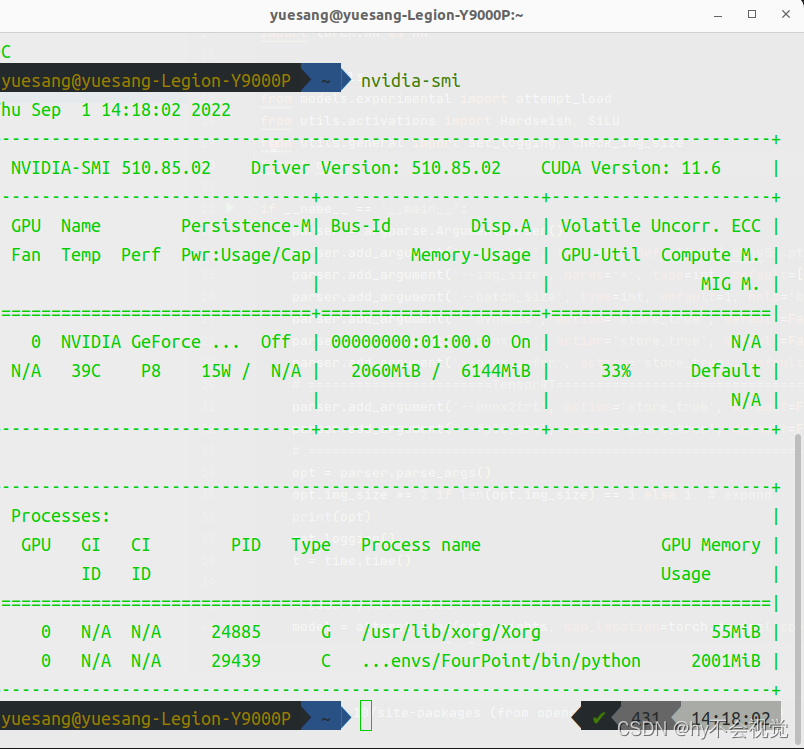
(这里有一点需要特别注意:右上角的CUDA Version的意思是你的装的显卡驱动最大支持11.6的cuda)
四:CUDA的安装
CUDA下载
我们进入CUDA Toolkit Archive | NVIDIA Developer选择我们适合的cuda这里我选择11.6.2版本的
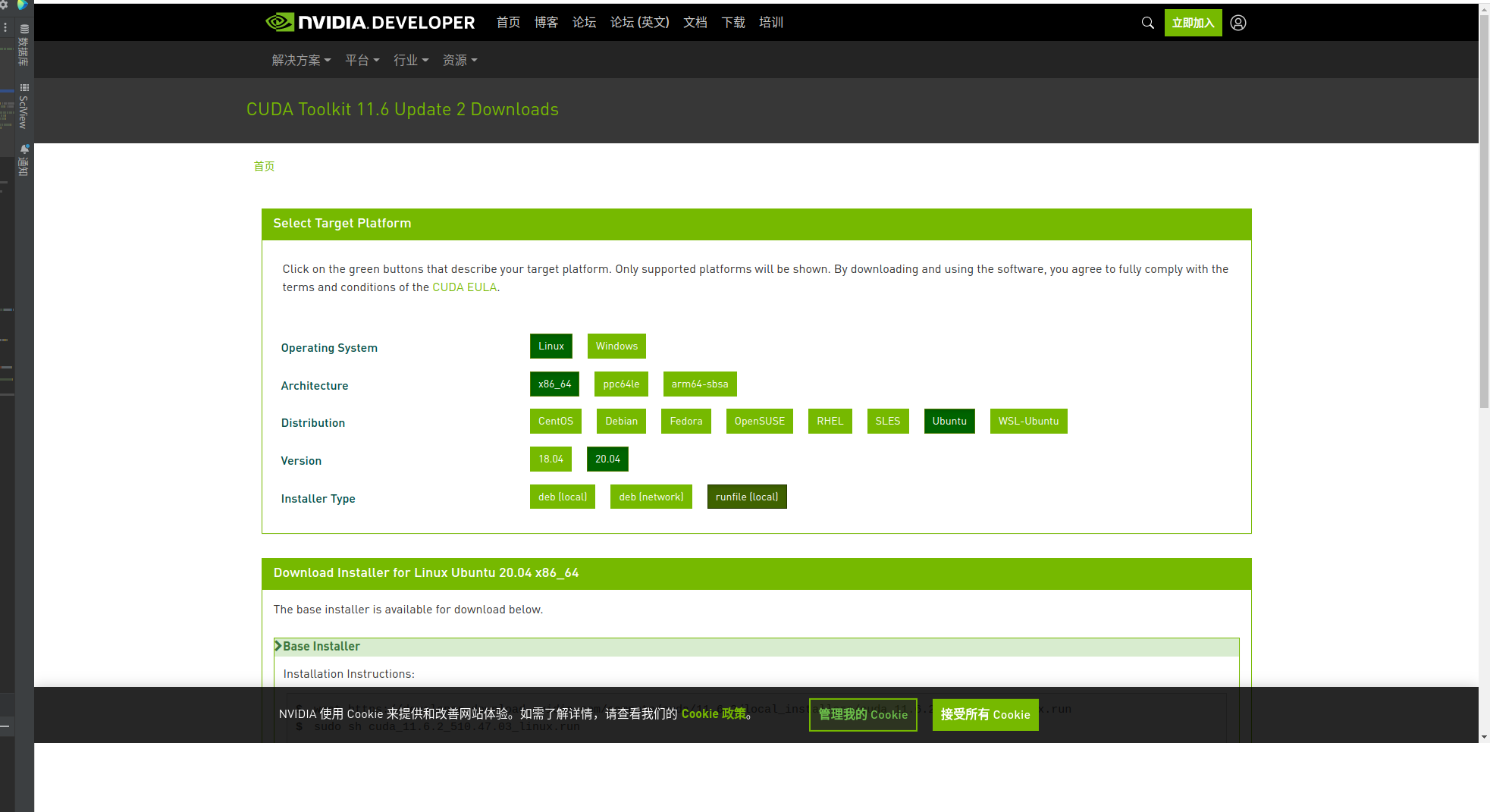
安装的命令如下
wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run
sudo sh cuda_11.6.2_510.47.03_linux.run细节的地方来了,你的tmp空间可能不够你可以在你的home文件夹下建立一个tmp然后
wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run
sudo sh cuda_11.6.2_510.47.03_linux.run --tmpdir=这里填写你的新建立的tmp位置使用完以后删掉这个tmp即可因为tmp文件夹重启后里面的文件默认不保存
等待一会这个时间可能会有点长
选择continue
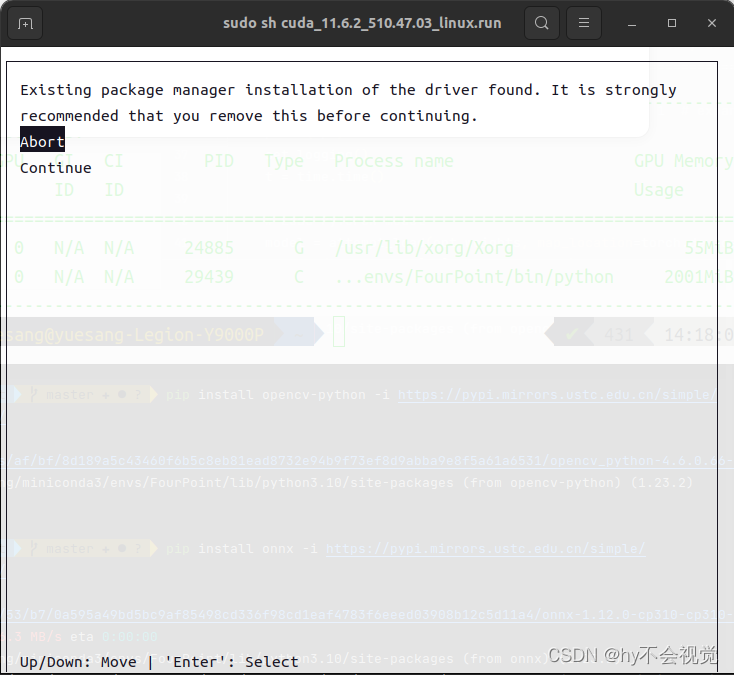 输入accept
输入accept
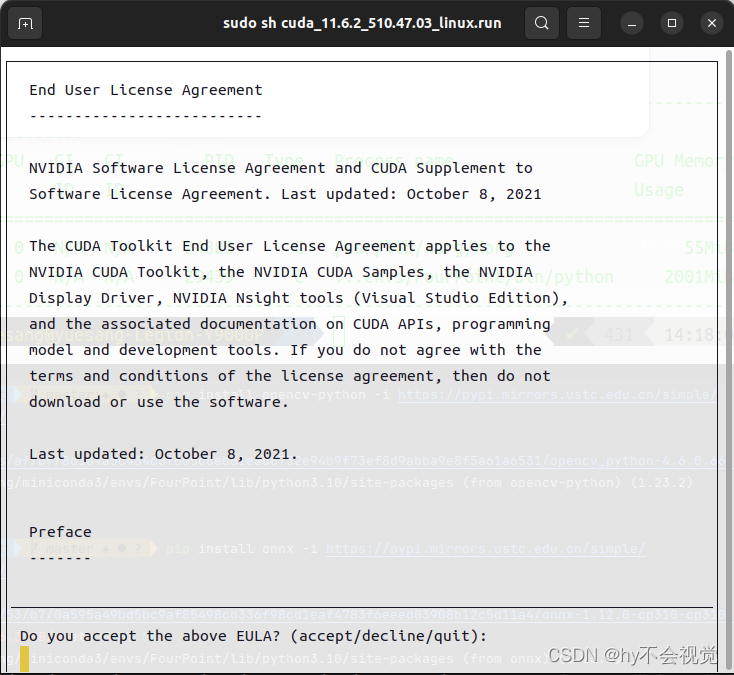
因为刚开始我们已经安装完驱动所以这里可以不用选择(之前安装的时候出现了一个小问题就是我当初重装显卡驱动的时候把显卡驱动删了想着能不能用run里面自带的但是我是没有成功,之后用下面这个方法也同样成功运行)
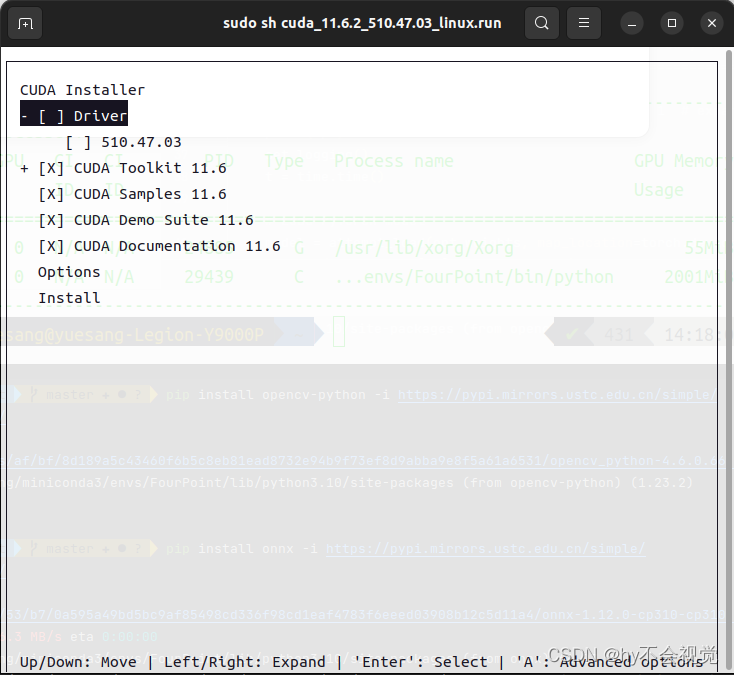
配置cuda环境
sudo gedit ~/.bashrc添加以下到末尾
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
然后
source ~/.bashrc在终端输入
nvcc -V显示以下则为成功(记得V要大写)
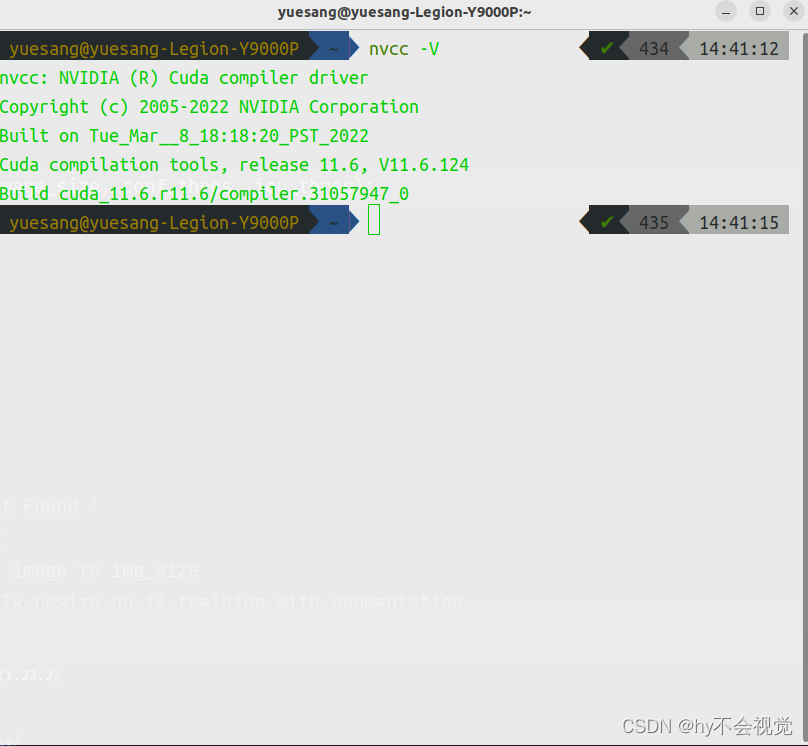
如果不成功,重新source ~/.bashrc然后输入nvcc -V成功的话,细节的地方来了!!!!!
首先,我们需要搞明白Linux启动时读取配置文件的顺序。在刚登录Linux时,首先启动/etc/profile 文件,然后再启动用户目录下的 ~/.bash_profile、~/.bash_login或 ~/.profile文件中的其中一个,
执行的顺序为:~/.bash_profile、~/.bash_login、 ~/.profile
所以如果行不同我们可以:
sudo gedit /etc/profile然后输入
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
最后
source /etc/profile之后应该就能显示了
CUDA的测试
下载解压后make一下
出现这个结果就是成功了

四.CUDANN的安装
CUDANN下载
下载连接:https://developer.nvidia.com/rdp/cudnn-download
这里我下在的是cudann8.4.1
下载Linux x86-64(tar)
进入解压后的界面,然后
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda-11.6/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda-11.6/lib64
sudo chmod a+r /usr/local/cuda-11.6/include/cudnn*.h /usr/local/cuda-11.6/lib64/libcudnn*
#下面这个是方便后面opencv配置cuda
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda-11.6/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
之后查看CUDNN版本
cat /usr/local/cuda-11.6/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
CUDNN依赖
依赖网站:Index of /compute/cuda/repos/ubuntu2004/x86_64
找到对应的依赖(一个带dev一个不带)
或者使用命令行进行下载
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/libcudnn8_8.4.1.50-1+cuda11.6_amd64.deb
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/libcudnn8-dev_8.4.1.50-1+cuda11.6_amd64.deb
安装依赖
sudo dpkg -i libcudnn8_8.4.1.50-1+cuda11.6_amd64.deb
sudo dpkg -i libcudnn8-dev_8.4.1.50-1+cuda11.6_amd64.deb
五.Tensortrt的安装
1.下载
这里是tensorrt的下载连接:https://developer.nvidia.com/nvidia-tensorrt-8x-download
下载tar包解压后的到的连接
修改环境变量:
sudo gedit ~/.bashrc
在文件末尾加入
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/stand/Software/TensorRT-8.4.1.5/lib
然后
source ~/.bashrc2. 测试样例
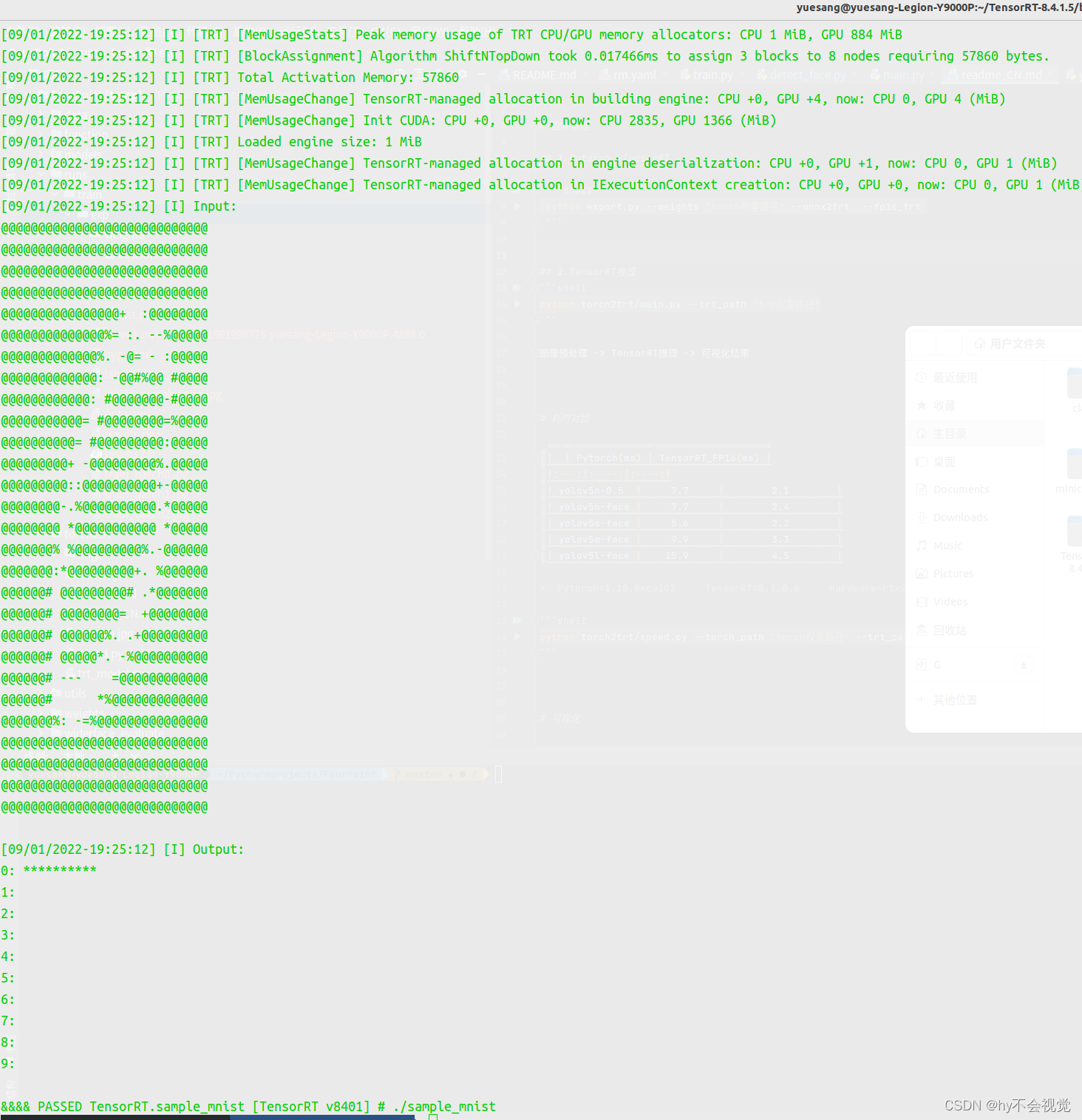
cd TensorRT-8.4.1.5/samples/sampleMNIST
make -j16
cd ../../bin/
./sample_mnist这样就成功了
3.python部分的安装
用miniconda创建完环境之后
直接pip目录中的uff,python(注意选择和你conda创建python的版本相对应) ,graphsurgeon下的whl就可以了
我这里是一次就成功了可能出现问题的话可以参考这位大佬:Ubuntu22.04 下安装驱动、CUDA、cudnn以及TensorRT_lilin020401的博客-CSDN博客

















 7200
7200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









