





系列文章目录
面向原型的多变量时间序列无监督异常检测 ICML 2023
文章目录
摘要
多变量时间序列(MTS)的无监督异常检测(UAD)旨在学习正常多变量时间模式的鲁棒表示。现有的UAD方法试图为每个MTS学习一组固定的映射,这需要昂贵的计算和有限的模型适应。为了解决这一关键问题,我们在概率框架下提出了一种面向原型的UAD (PUAD)方法。具体来说,提出的PUAD不是学习每个MTS的映射,而是将多个MTS视为一组原型上的分布,这些原型被提取以表示不同的正常模式集。为了学习和调节原型,PUAD引入了一种基于重构的无监督异常检测方法,该方法将面向原型的最优传输方法融入到变压器驱动的概率动态生成框架中。利用元学习可转移原型,PUAD可以实现对新mts的高模型适应能力。在5个公共MTS数据集上的实验均验证了该方法的有效性。
提示:以下是本篇文章正文内容
一、引言
现代信息技术操作产生了大量需要持续监控的高维传感器数据。两个典型的例子是内容分发网络(CDN)系统(Dai et al., 2021)和大型数据中心的服务器机器(Su et al., 2021;2019;Sun等人,2021)。对于以多元时间序列(multivariate time series, MTS)表示的大型系统监测数据,发现系统故障的一种方法是检测MTS内的异常时间点,这对于确保安全和服务质量以及减轻经济损失具有重要意义(Xu et al., 2021)。异常检测的目标是识别不符合常规数据描述的异常输入数据(Cao et al., 2022)。基于机器学习的异常或离群值检测方法大致可分为监督异常检测(AD) (Liu et al., 2015;Shon & Moon, 2007;Yamada et al., 2013)或无监督AD (UAD) (Su et al., 2021;2019;Zhang et al., 2019;Li et al., 2019;徐等,2018a;Audibert et al., 2020;Malhotra et al., 2016;Hundman et al., 2018a)。由于异常通常是罕见的,并且隐藏在大量的正态点中,不仅异常的标记是困难和昂贵的,而且由于严重的类不平衡,监督学习的AD分类器的性能往往是次优的(Chalapathy & Chawla, 2019)。出于这个原因,我们专注于MTS的UAD,它不需要对异常进行标记。
MTS的UAD的基本思想是通过比较MTS与多变量时间模式来检测异常,这些模式是从先前被认为是正常的MTS中提取的。多年来,已经开发了许多基于重建的UAD方法。他们首先学习正常的MTS模式,然后使用这些模式下的重建误差作为异常分数。已经提出了几条工作线,包括基于概率动态模型的工作线,如GmVRNN (Dai等人,2022)和VGCRN (Chen等人,2022),它们通过考虑MTS内的时间依赖性和可变性,实现了卓越的检测性能。注意机制具有捕捉长期依赖关系的非凡能力。Transformer最初是为离散序列建模而开发的,也经过修改以检测MTS中的异常,其中Anomaly Transformer (Xu et al., 2021)和TranAD (Tuli et al., 2022)是两个代表性示例。
来自大型系统的MTS中的UAD面临的一个关键挑战是,其中包含的每个设备都有自己独特的正常模式。例如,用于视频网站的服务器和用于购物网站的服务器的分布有明显的区别。因此,通过一组固定的映射来捕获多个不同的正常模式是具有挑战性的。为了更好地学习正常模式,以往的方法通常是用一组单独的参数对MTS的一种模式进行建模,这不仅需要大量的参数(当MTS数量很大时),而且在适应新的MTS时需要大量的数据来训练这些参数。GmVRNN (Dai等人,2022)试图通过将潜在状态分配到高斯混合分布中,用一组参数对不同的mts进行建模。在获得令人满意的性能的同时,它忽略了一个事实,即一组参数不能拟合所有的模式,需要针对不同的mts调整模型以达到最佳性能。
为了解决以前的工作在捕获多个MTS中的不同时间依赖性以及在很少观察的情况下适应新的MTS方面的局限性,我们在概率框架下为MTS开发了一种面向原型的UAD (PUAD)方法,其中利用最佳传输(OT) (Peyr ’ e等人,2019)来学习原型。我们展示了在PUAD中使用原型有助于识别mss中的各种正常模式并适应新的mss(给出了几个示例)。与以往大多数使用不同参数组对不同mts进行建模的UAD方法不同,PUAD将多个mts中的各种正常动态模式视为一组全局原型,并通过提出的新型面向原型的OT模块学习这些原型记忆,该模块的灵感来自(Tanwisuth et al., 2021;Wang et al., 2022;郭等人,2022)。由于PUAD中的每个原型都被鼓励捕获多个mts共享的统计时间依赖性,这类似于元学习中所有相关任务的迁移模式(Guo等人,2022;Vilalta & Drissi, 2002;Zhen et al., 2020;Du et al., 2021),从而使PUAD能够实现较高的模型适应能力。此外,我们还引入了新到达的mts的本地原型,以提高PUAD的适应能力。最后,PUAD将面向原型的OT模块整合到一个强大的概率动态生成框架中,用于MTS基于重建的无监督异常检测方法。
我们的主要工作贡献总结如下:
•通过提取一组原型,实现了对多个mts中不同正常模式的学习,并提出了一个名为PUAD的概率框架用于异常检测。
•我们开发了一个面向原型的OT模块,利用分布之间的OT距离来指导原型的学习。
•我们定义了全局和局部原型,以增强PUAD在有限观测条件下适应新mts的能力。
•我们提供了广泛的实验结果和五个数据集的比较,以证明我们的方法在传统和元异常检测任务上都实现了整体SOTA性能。
二、背景信息
2.1. Prototype-based Methods
基于原型的模型的动机来自于聚类假设(Grandvalet & Bengio, 2004),它指出决策边界不应该跨越数据的高密度区域。这些模型试图学习不同类型模式的原型表示。基于原型的模型在各个领域都受到了很多关注,比如基于度量的少镜头学习(Snell等人,2017)、无监督域适应(Tanwisuth等人,2021)或表示学习(Guo等人,2021)。近年来,基于原型的方法也被引入到计算机视觉异常检测中。例如,针对视频异常检测(VAD)提出了原型引导的判别潜嵌入(Lai et al., 2021),该方法尝试学习深度自编码器,以较小的重建误差描述正常事件模式。Grandvalet et al. (de Paula Monteiro et al., 2022)引入了基于原型选择的工业机器异常检测方法,其中模型输入是频谱图。此外,Snell等人(Liu et al., 2021)展示了用于工业表面检测异常检测的双原型自编码器。然而,目前还没有基于原型的MTS建模方法,尽管它们在MTS的无监督异常检测中具有独特的优势,因为它们能够表示多个模式并适应新的模式。
2.2. 无监督异常检测
无监督异常检测的过程可以概括为三个步骤。首先,需要对原始MTS数据进行预处理,使学习模型能够使用原始MTS数据进行训练。具体来说,本研究采用了归一化和滑动时间窗方法(Dai et al., 2021)。其次,利用处理后的数据对异常检测模型进行无监督训练;然后,利用训练好的模型获得测试数据的异常分数,并根据定义的度量选择阈值实现检测。我们考虑了两种无监督异常检测的设置,包括:“一对一”(Dai et al., 2022):模型在所有mts上进行训练和执行;“一对一”(Dai et al., 2021):模型分别在每个MTS上进行训练和执行。
2.3. Optimal Transport
最优运输(OT)是一种广泛使用的工具,用于量化两种分布之间的差异(Peyr ’ e et al., 2019)。具体来说,考虑两个离散分布p = ∑ i = 1 n a i δ x i a n d q = ∑ j = 1 m b j δ y j , \sum_{i=1}^{n}a_{i}\delta_{x_{i}}\mathrm{~and~}q=\sum_{j=1}^{m}b_{j}\delta_{y_{j}}, ∑i=1naiδxi and q=∑j=1mbjδyj,,其中 x i , y j ∈ R d x_{i},y_{j}\in\mathbb{R}^{d} xi,yj∈Rd, δ x \delta_{x} δx是在x处放置单位点质量的狄拉克函数。
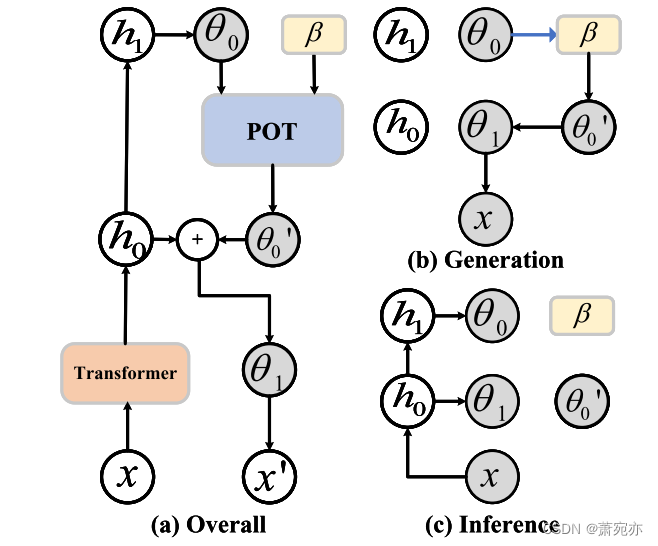
图1。PUAD各操作的图解:(a) PUAD的整体操作;(b) x的生成过程;©
θ
0
\boldsymbol{\theta}_{0}
θ0和
θ
1
\boldsymbol{\theta}_{1}
θ1的变分分布推断。注意,灰色圆圈表示隐藏变量,白色圆圈表示输入数据和特征,黄色方块表示原型。箭头表示数据流和生成关系。
p与q之间的OT距离可表示为:
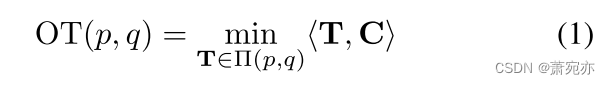
其中⟨·,·⟩表示Frobenius点积,
C
∈
R
≥
0
n
×
m
\mathrm{C}\quad\in\quad\mathbb{R}_{\geq0}^{n\times m}
C∈R≥0n×m是运输成本矩阵,并且
C
i
j
=
C
(
x
i
,
y
j
)
.
T
∈
R
>
0
n
×
m
C_{ij}\quad=\quad C\left(x_{i},y_{j}\right).\quad\textbf{T}\quad\in\quad\mathbb{R}_{>0}^{n\times m}
Cij=C(xi,yj).T∈R>0n×m表示
Π
(
p
,
q
)
:
=
{
T
∣
∑
i
=
1
n
T
i
j
=
b
j
,
∑
j
=
1
m
T
i
j
=
a
i
}
,
\Pi(p,q):=\{\mathbf{T}\mid\sum_{i=1}^{n}T_{ij}=b_{j},\sum_{j=1}^{m}T_{ij}=a_{i}\},
Π(p,q):={T∣∑i=1nTij=bj,∑j=1mTij=ai},的双随机输运概率矩阵,可以通过最小化OT(p, q)来学习。由于Eq.(1)的优化通常需要很高的计算成本,因此离散OT的Sinkhorn算法这是通过引入熵规律
H
=
−
∑
i
j
T
i
j
ln
T
i
j
,
H=-\sum_{ij}T_{ij}\operatorname{ln}T_{ij},
H=−∑ijTijlnTij,来实现的,在实践中通常用于减少计算量(Peyr´e等人,2019)。
2.4. Meta元异常检测
元学习,也被称为学习学习,是指专注于帮助深度模型快速适应新环境的技术(Cao等人,2022;Wu等人,2021)。本文以MTS的元异常检测为研究重点,将其定义为在观测值有限的情况下,使异常检测方法能够快速适应新到达的MTS(如新机器、新网站等)的任务,旨在设计一种基于模型的方法来执行元异常检测。
三、方法论
在本节中,我们首先定义了本文要解决的异常检测问题。然后我们提出了PUAD,它由一个面向原型的最优传输(POT)模块组成,用于学习mts的原型,并通过OT算法对其进行改进(Peyr ’ e等人,2019)。一个由原型指导的深度概率生成模块,该原型考虑了多个mss内的不同时间依赖性,用于鲁棒表示学习,以及一个推理模块(Zhang等人,2018;Duan et al., 2021)基于Transformer (Vaswani et al., 2017)来近似生成模块中的难处理后向分布。最后,介绍了PUAD的培训过程。
3.1. 问题定义
定义MTS为 x = ( x 1 , x 2 , . . . , x T ) ∈ R V × T , \boldsymbol{x}=(x_1,x_2,...,x_T)\in\mathbb{R}^{V\times T}, x=(x1,x2,...,xT)∈RV×T,,其中T为x的持续时间, x t ∈ R V x_{t}\in\mathbb{R}^{V} xt∈RV为时刻T的v维观测值。MTS上的异常检测定义为判断在某时刻 x t x_{t} xt采集到的观测值是否异常的问题。为了以无监督的方式有效地解决这个问题,我们需要一种强大的方法来学习输入数据的鲁棒表示。
3.2. 面向原型的无监督异常检测
如图1所示,基于面向原型的最优传输方法,PUAD构建了一个变压器驱动的概率动态生成框架。PUAD具有一个由θ0、θ1和原型β三部分组成的潜在空间。受分层VAEs的启发(Vahdat & Kautz, 2020;Duan等人,2021), θ 0 θ_0 θ0和 θ 1 θ_1 θ1被提出分层生成多个mst,而一组原型β被设计用于捕获多个mss内的各种正常动态模式。给定嵌入采样形式 θ 0 θ_0 θ0,利用OT对原型表示的相关信息进行索引,指导mts的生成。在PUAD中包含两种原型:全局原型包含从所有历史MTS中总结的共享信息(Dai et al., 2022),而局部原型考虑在元异常检测中定义的新MTS中的特定信息。PUAD是一种基于重构的异常检测方法,其生成过程可以写成
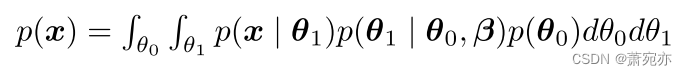
3.2.1. 学习最优运输的原型LEARNING PROTOTYPES WITH OPTIMAL TRANSPORT
大多数现有作品(Dai et al., 2022;Xu et al., 2021;Su等人,2019)专注于用一组单独的参数对MTS的一种模式进行建模。相反,我们建议用一组原型来描述多个mss的正常模式,并通过组合这些原型来重构不同的mss。这种改变有几个好处。首先,原型总结了不同MTSs的各种正常动态模式,使PUAD能够通过一组原型覆盖具有不同特征的多个MTSs。其次,鼓励每个全局原型捕获多个mts共享的统计信息,这类似于元学习提取的所有相关任务有用的可转移模式(Guo等人,2022)。因此,我们可以将PUAD应用于元学习问题,从而有效地适应有限观测值下新mts的异常检测。最后但并非最不重要的是,我们独立地定义了一些本地原型,以捕获新的mts的特定信息。当我们将该模型应用于新的MTS时,只需要对少数局部原型进行优化,而不影响总结的全局原型,大大节省了部署成本。如图2所示,我们引入POT模块来捕获不同的模式,并通过优化(Tanwisuth et al., 2021;郭等人,2022)。POT可以看作是索引全局和局部原型的选择器,这有助于模型处理全局原型不适合当前MTS或局部原型不适合有限数据的极端情况。
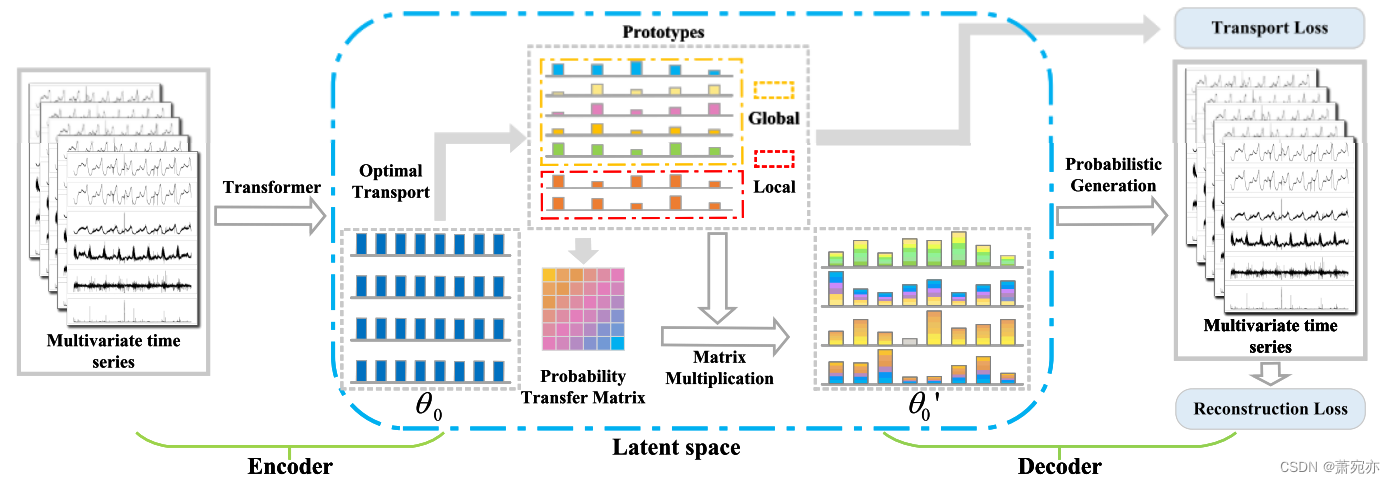
图2。概述了基于变压器的编码器、基于概率生成模型的解码器和基于潜在空间的POT模块组成的PUAD框架。
θ
0
θ_0
θ0为编码器从mts中提取的特征,
θ
0
θ_0
θ0到原型采用OT算法获得概率传递矩阵,
θ
0
′
\boldsymbol{\theta}_0^{\prime}
θ0′为概率传递矩阵与原型相乘得到的潜在表示。
给定一组全局原型
β
g
=
[
b
g
1
,
b
g
2
,
.
.
.
,
b
g
K
g
]
∈
\beta_{\boldsymbol{g}}=[b_{g}^{1},b_{g}^{2},...,b_{g}^{K_{g}}]\in
βg=[bg1,bg2,...,bgKg]∈
R
K
g
×
d
f
\mathbb{R}^{K_g\times d_f}
RKg×df,局部原型
β
l
=
[
b
l
1
,
b
l
2
,
.
.
.
,
b
l
K
l
]
\beta_{\boldsymbol{l}}=[b_{l}^{1},b_{l}^{2},...,b_{l}^{K_{l}}]
βl=[bl1,bl2,...,blKl]∈
R
K
l
×
d
f
\mathbb{R}^{K_{l}\times d_{f}}
RKl×df,其中每个原型的维数
d
f
d_{f}
df与特征编码器后的隐藏维数相同,
K
g
K_{g}
Kg和
K
l
K_{l}
Kl分别为全局原型和局部原型的个数。将原型定义为
β
=
[
β
g
;
β
l
]
∈
R
(
K
g
+
K
l
)
×
d
f
\beta=[\beta_{\boldsymbol{g}};\beta_{\boldsymbol{l}}]\in\mathbb{R}^{(K_{g}+K_{l})\times d_{f}}
β=[βg;βl]∈R(Kg+Kl)×df。为了总结多个MTS之间共享的信息,我们可以将MTS集中的
N
j
N_{j}
Nj个样本表示为
N
j
N_{j}
Nj上的经验分布(Guo et al., 2022):
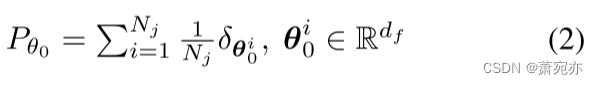
式中θ0为隐含变量的嵌入样本。原型被用来表示多个MTS上的不同模式,因此当我们试图索引合适的原型来表示一个具体的MTS时,原型之间的重要性是相等的,因此,全局原型上的分布可以定义为经验分布:
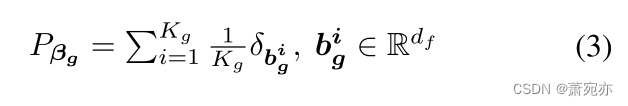
其中
β
g
\beta_{g}
βg是全局原型。这样,我们可以通过Sinkhorn算法获得从
P
θ
0
to
P
β
g
P_{\theta_0}\text{ to }P_{\beta_g}
Pθ0 to Pβg的传输概率矩阵
M
∈
R
>
0
N
j
×
K
g
{M}\in\mathbb{R}_{>0}^{N_j\times K_g}
M∈R>0Nj×Kg (Cuturi, 2013):
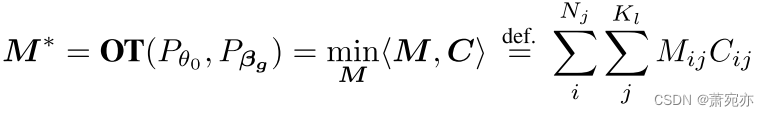
C
∈
R
≥
0
N
j
×
K
g
\begin{array}{ccc}\mathbf{C}&\in&\mathbb{R}_{\geq0}^{N_j\times K_g}\end{array}
C∈R≥0Nj×Kg为运输成本矩阵,我们使用嵌入
θ
0
θ_0
θ0与原型
β
g
β_g
βg之间的欧氏距离,
C
i
j
=
(
θ
0
i
−
β
g
j
)
2
.
C_{ij}=\sqrt{(\theta_0^i-\beta_g^j)^2}.
Cij=(θ0i−βgj)2.传输概率矩阵M应满足
Π
(
g
,
h
)
:
=
\Pi(\boldsymbol{g},\boldsymbol{h}):=
Π(g,h):=
{
M
∣
M
1
K
g
=
g
,
M
⊤
1
N
j
=
h
}
\left\{M\mid M\mathbf{1}_{K_g}=\boldsymbol{g},M^\top\mathbf{1}_{N_j}=\boldsymbol{h}\right\}
{M∣M1Kg=g,M⊤1Nj=h},其中
g
=
[
1
K
g
]
g=\begin{bmatrix}\frac1{K_g}\end{bmatrix}
g=[Kg1]和
h
=
[
1
N
j
]
{\boldsymbol{h}}=\bigl[\frac1{N_j}\bigr]
h=[Nj1]是公式2和公式3中的两个概率向量。OT根据成本矩阵C给出了从嵌入
P
θ
0
P_{\theta_0}
Pθ0到原型机
P
β
g
P_{\beta_{g}}
Pβg的最优传输方案,我们可以通过传输概率M和原型机
β
g
β_g
βg重构
θ
0
θ_0
θ0:
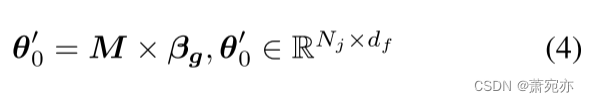
与原始 θ 0 {\theta}_0 θ0相比, θ 0 ′ \boldsymbol{\theta}_0^{\prime} θ0′包含了原型传递的多样性动态信息,从而涵盖了mts的多种模式。受现有基于OT的面向原型方法的启发(Guo et al., 2022;Tanwisuth et al., 2021),为了学习原型β,我们采用熵约束(Cuturi, 2013),并定义所有训练集的平均OT损失为:
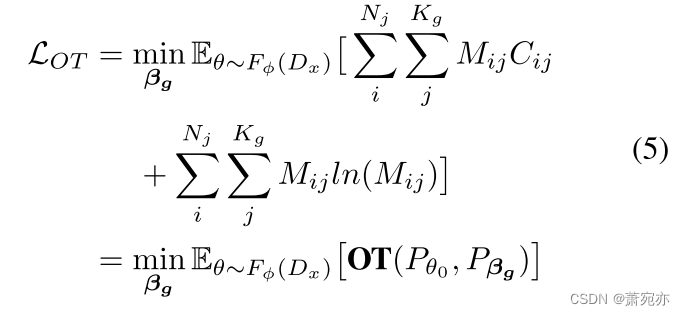
F
ϕ
(
⋅
)
F_{\phi}(\cdot)
Fϕ(⋅)是下面将要引入的推理模块,其参数用φ表示,
D
x
D_{x}
Dx是由正常MTS数据组成的训练集。
到目前为止,全局原型可以代表多MTSs内部的各种正常模式,并鼓励它们捕获多个MTSs共享的统计时间依赖性,这类似于元学习中的迁移模式,从而具有强大的适应新MTSs的能力。但是新的mts的具体信息可能会被全局原型所忽略。因此,我们进一步引入局部原型 β l \beta_{l} βl来补充被忽略的信息,增强模型的自适应能力。首先从新MTSs的少量样本中总结出 β l \beta_{l} βl,然后在检测新MTSs上的异常时,用OT将 β g \beta_{g} βg和 β l \beta_{l} βl一起索引。
3.2.2. 原型导向概率生成模型
利用POT模块的原型,我们为基于重建的无监督异常检测制定了一个分层概率生成模型,如图1 (a)所示。与现有的分层VAEs不同(Vahdat & Kautz, 2020;Su等人,2019),他们将信息存储在随机变量之间的神经网络中。我们引入了一种分层概率生成模型,该模型根据原型中存储的相关信息的方向生成数据。形式上,生成过程可以表示为:
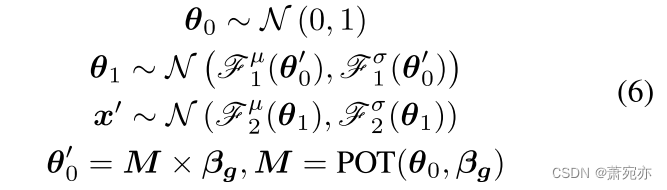
其中
x
′
∈
R
T
×
V
x^{\prime}\in\mathbb{R}^{T\times V}
x′∈RT×V为当前时间步长生成的MTS向量,N(·,·)为高斯分布,括号内的值为分布系数。具体来说,在对潜在表征
θ
0
θ_0
θ0进行采样后,我们将学习到的原型纳入到
θ
0
θ_0
θ0中,通过POT模块得到
θ
0
′
\theta_{0}^{\prime}
θ0′。由于原型所索引的信息代表了各种正常的动态模式,这提高了OT对正常MTS的生成能力,因此在OT找不到合适原型的情况下,正常MTS异常得分平滑,异常MTS异常得分更高,如图1 (b)所示。引入Eq. 7中的四个非线性函数
F
1
μ
,
F
2
μ
,
F
1
σ
,
F
2
σ
\mathscr{F}_{1}^{\mu},\mathscr{F}_{2}^{\mu},\mathscr{F}_{1}^{\sigma},\mathscr{F}_{2}^{\sigma}
F1μ,F2μ,F1σ,F2σ,生成
θ
1
θ_1
θ1和x′ 的分布系数,定义为:
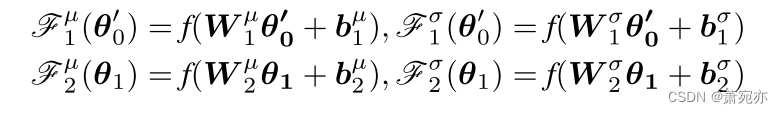
我们使用全连通网络作为非线性函数,其中权重
W
1
μ
,
W
1
σ
,
W
2
μ
,
W
2
σ
∈
R
d
f
×
d
f
\boldsymbol{W}_1^\mu,\boldsymbol{W}_1^\sigma,\boldsymbol{W}_2^\mu,\boldsymbol{W}_2^\sigma\in\mathbb{R}^{d_f\times d_f}
W1μ,W1σ,W2μ,W2σ∈Rdf×df和偏置
b
1
μ
,
b
1
σ
,
b
2
μ
,
b
2
σ
∈
R
d
f
b_1^\mu,b_1^\sigma,b_2^\mu,b_2^\sigma\in\mathbb{R}^{d_f}
b1μ,b1σ,b2μ,b2σ∈Rdf是可学习的参数,f(·)是一个确定性的非线性过渡函数。
3.2.3. 变压器结构推理模型
考虑到MTS中长期和复杂的时间依赖关系,并专注于学习表达性表示,我们引入了一个变换结构的推理模型来近似 θ 0 θ_0 θ0和 θ 1 θ_1 θ1的真实后验分布,这一直是一个棘手的问题。变分分布可以定义为:
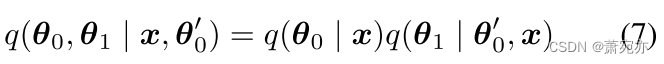
如图1 (a)和©所示,部署了一个广泛用于处理时间序列数据的变压器(Vaswani et al., 2017)来编码不同时间步长之间的时间关系。对于向上的信息转换,我们定义从变压器中提取的特征为
h
0
h_0
h0,并应用全连通网络得到特征
h
1
h_1
h1:
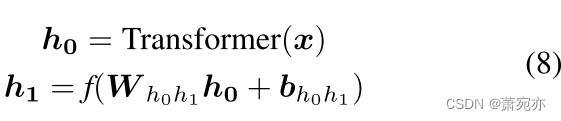
然后,给定变压器提取的特征,推理过程可以描述为:
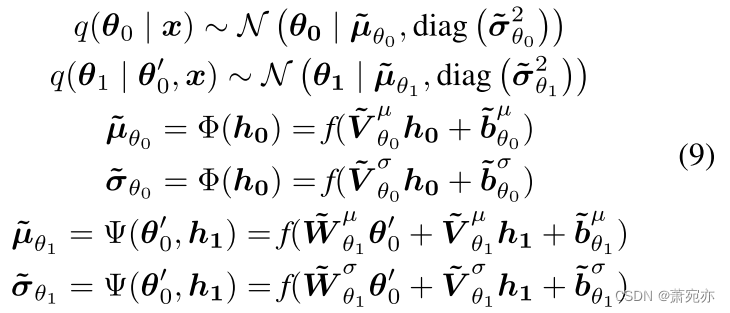
其中Φ和Ψ是两个非线性函数,它们包括可学习参数
{
V
~
θ
0
μ
,
V
~
θ
0
σ
,
V
~
θ
1
μ
,
V
~
θ
1
σ
,
W
~
θ
1
μ
,
W
~
θ
1
σ
}
∈
R
d
f
×
d
f
a
n
d
{
b
~
θ
0
μ
,
b
~
θ
0
σ
,
b
~
θ
1
μ
,
b
~
θ
1
σ
}
∈
R
d
f
\{\tilde{\boldsymbol{V}}_{\theta_0}^\mu,\tilde{\boldsymbol{V}}_{\theta_0}^\sigma,\tilde{\boldsymbol{V}}_{\theta_1}^\mu,\tilde{\boldsymbol{V}}_{\theta_1}^\sigma,\tilde{\boldsymbol{W}}_{\theta_1}^\mu,\tilde{\boldsymbol{W}}_{\theta_1}^\sigma\}\in\mathbb{R}^{d_f\times d_f}\mathrm{~and~}\{\tilde{\boldsymbol{b}}_{\theta_0}^\mu,\tilde{\boldsymbol{b}}_{\theta_0}^\sigma,\tilde{\boldsymbol{b}}_{\theta_1}^\mu,\tilde{\boldsymbol{b}}_{\theta_1}^\sigma\}\in\mathbb{R}^{d_f}
{V~θ0μ,V~θ0σ,V~θ1μ,V~θ1σ,W~θ1μ,W~θ1σ}∈Rdf×df and {b~θ0μ,b~θ0σ,b~θ1μ,b~θ1σ}∈Rdf。这样,利用推理网络,结合生成分布中自下而上的似然信息(h1)和先验信息(
θ
0
′
\boldsymbol{\theta}_{0}^{\prime}
θ0′),推断潜变量θ0和θ1 (Rezende et al., 2014)。

3.3. 模型训练
根据Eq. 2的定义,通过最大化对数边际似然的证据下界(ELBO)来实现PUAD的优化目标(详见附录),可表示为:
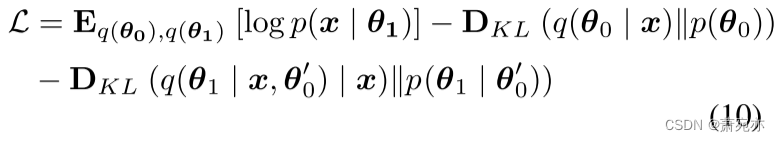
受beta-VAE (Higgins et al., 2016)的启发,我们引入了三个超参数ρ1 > 0、ρ2 > 0和ρ3 > 0,然后在前K个训练周期中,随着ρ1、ρ2和ρ3从0增加到1,逐渐增加KL损失。最后,通过联合优化Eq. 5中的ELBO和OT损失来学习网络参数和全局原型:
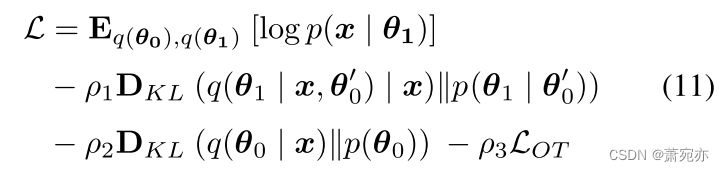
综上所述,优化由原型分布Pβ和嵌入分布
P
θ
0
P_{\theta_{0}}
Pθ0定义的OT损失提供了一种原则性和无监督的方法,以鼓励原型在多个mts中捕获不同的正态模式。算法1采用端到端随机梯度下降法对模型参数进行优化。
3.4. 异常检测
由于模型被训练为学习mts的正常模式,因此观察值越遵循正常模式,就越有可能以更高的置信度很好地重建它。因此,我们使用x的重构概率作为异常评分来确定观测变量是否异常(an & Cho, 2015;Su et al., 2019;2021;Xu et al., 2018b),计算为:
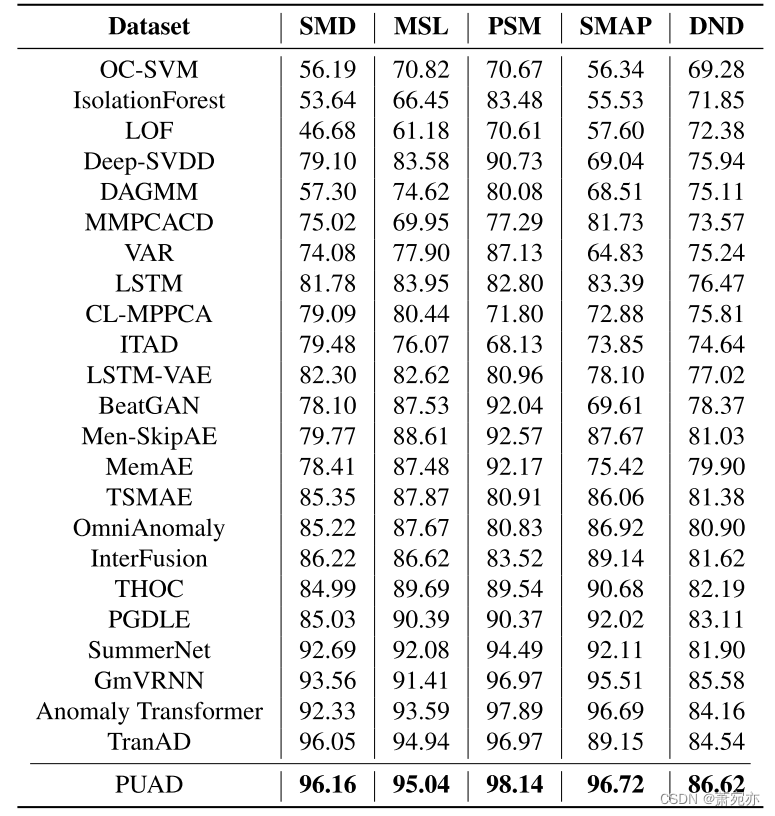
表1。不同方法在5个公共数据集和1个真实数据集上的f1得分结果。F1-score是准确率和召回率的调和平均值。对于这个指标,值越高表示性能越好,参见附录了解更多指标。
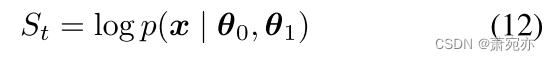
如果 S t S_t St低于特定阈值,则观测x将被归类为异常。从实际的角度来看,我们使用峰值-超过阈值(Siffer等人,2017)方法来帮助选择阈值。
四、 实验评价
4.1. 实验设置
数据集:我们的实验中使用了五个数据集,包括四个公共数据集:SMD (Su等人,2019)、NASA的MSL和SMAP (Hundman等人,2018b)、PSM (Abdulaal等人,2021)和一个真实世界数据集:DND (Chen等人,2022)。详见附录。
实现细节:在我们的实验中,实现了一个具有512维隐藏状态的三层变压器作为编码器。映射特征h0, h1的MPL维数为256。POT由10个(Kg)全局原型和2个(Kl)维度为256的局部原型组成。我们设置潜在状态θ0和θ1与512有相同的维数。超参数ρ1, ρ2和ρ3设置为0.01,以平衡所有数据集的重构和KL部分。使用Adam优化器,学习率为0.00002,批大小设置为256。根据经验,峰值超过阈值中使用的与初始阈值相关的概率p被设置为0.01。我们采用滑动窗口来获取一组子序列(Shen et al., 2020),所有数据集的滑动窗口大小固定为20。所有实验都是在Pytorch (Paszke et al., 2019)和NVIDIA RTX 3090 24GB GPU中实现的。
我们的实现可以在https://github.com/ BoChenGroup/PUAD上公开获得
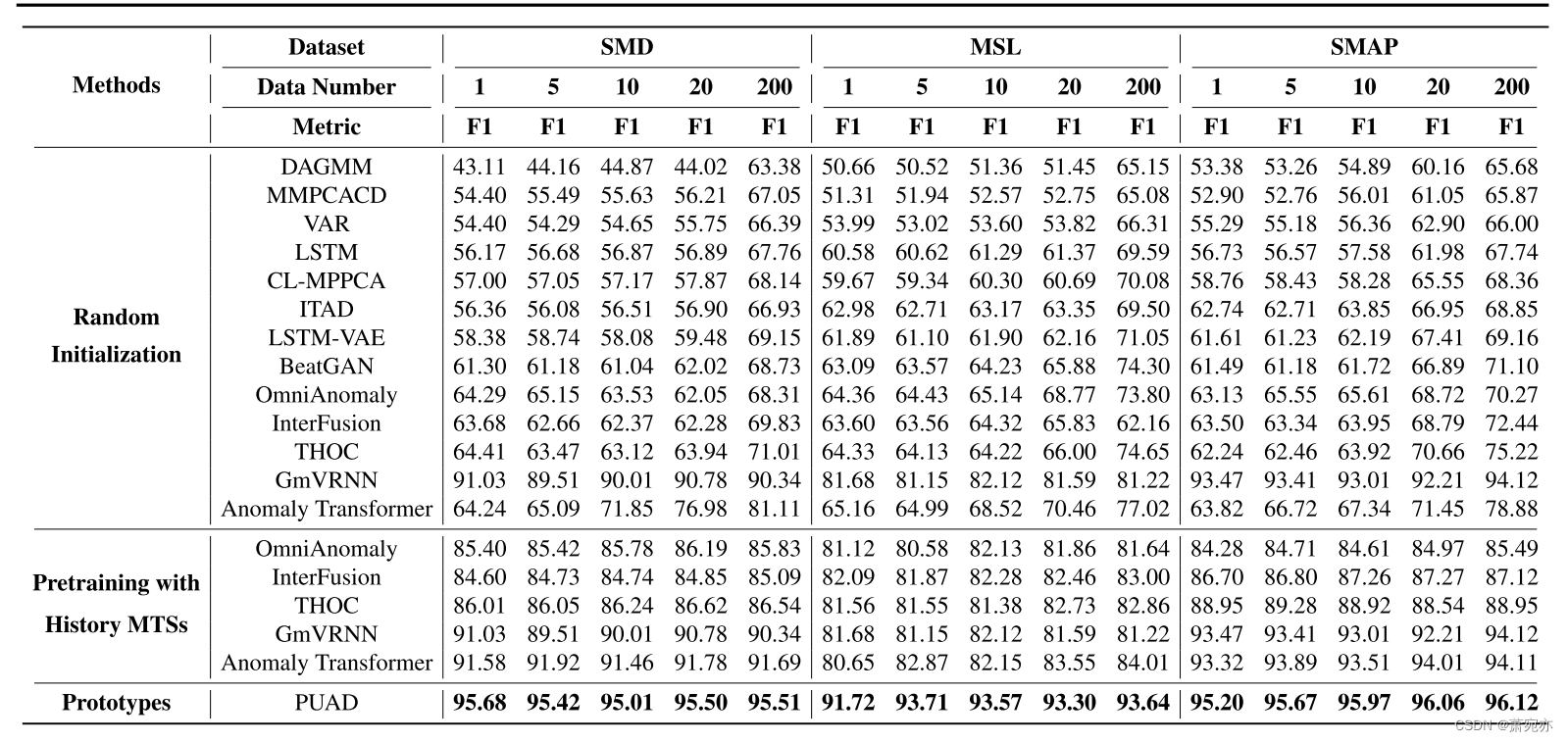 表2。不同元异常检测方法在三个公共数据集上的定量结果。
表2。不同元异常检测方法在三个公共数据集上的定量结果。
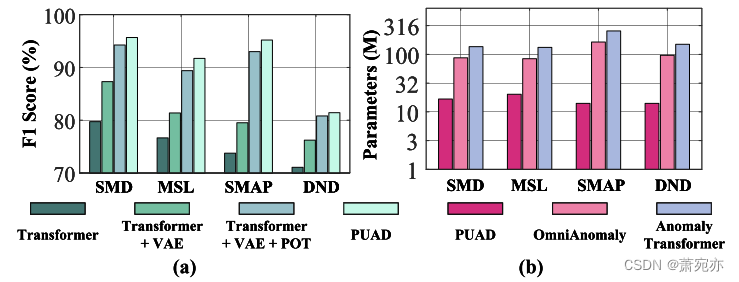
图3。(a)四个数据集上PUAD的消融研究。(b)模型参数比较。
4.2. 主要结果
4.2.1. 基线
我们将我们的模型与24条基线进行了广泛的比较,包括基于重建的模型:InterFusion (Li等人,2021)、BeatGAN (Zhou等人,2019)、OmniAnomaly (Su等人,2019)、LSTM-VAE (Park等人,2018);密度估计模型:DAGMM (Zong等人,2018)、mppcadd (Yairi等人,2017)、LOF (Breunig等人,2000);基于聚类的方法:ITAD (Shin等人,2020)、THOC (Shen等人,2020)、Deep-SVDD (Ruff等人,2018);基于自回归的模型:CL-MPPCA (Tariq等人,2019)、LSTM (Hundman等人,2018b)、VAR (Clements & Mizon, 1991);经典方法:OC-SVM (Tax & Duin, 2004)、IsolationForest (Liu et al., 2008);基于memautoencoder的模型:Men-SkipAE (Yan等人,2023)、MemAE (Gong等人,2019)和TSMAE (Gao等人,2022);基于原型的模型:PGDLE (Lai等人,2021)和SummerNet (Guo等人,2021)。异常变压器(Xu et al., 2021)和InterFusion (Li et al., 2021)是最先进的深度模型。GmVRNN (Dai et al., 2022)是一种用于异常检测的最先进的深度概率模型。TranAD (Tuli et al., 2022)是我们认知中最新的异常检测方法。我们在附录中列出了更多的描述。
4.2.2. 定量比较
异常检测:为了评估PUAD在典型异常检测设置中的性能,我们在五个具有多个竞争基线的数据集上考虑我们的模型。采用F1-score (Dai et al., 2022)作为绩效指标。我们注意到GmVRNN和PUAD是一对一的模型,而其他是一对一的模型。如表1所示,考虑到MTS内部的随机性和分集性,GmSVRNN的性能优于其他非变压器方法。基于变压器的方法具有强大的复杂动力学建模能力,优于其他方法。在所有测试数据集上,PUAD在所有方法中获得了最好的f1分数,这表明了在多个mts中使用原型考虑不同动态模式并制定变压器供电概率生成模型的有效性。我们在附录中列出了精度和召回性能。
参数数量:为了证明PUDA的计算效率,我们对模型参数数量进行比较,并将结果列于图3 (b)中。我们可以看到,作为一种一对一的方法,PUAD的参数数量远少于一对一的方法,但它可以获得更高的F1-score,如表2所示。我们还测试了时间效率和附录中的列表。
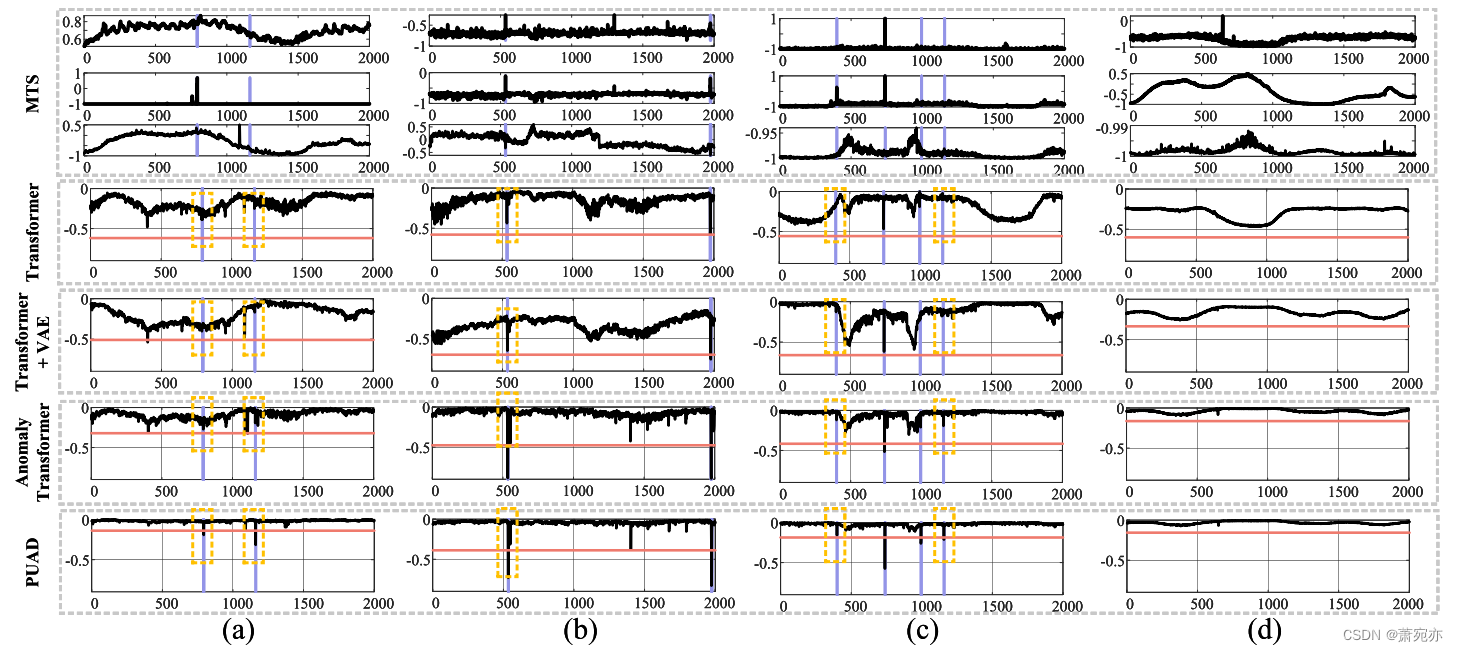
图4。基于SMD数据集的异常评分实例研究。紫色突出显示的区域代表groundtruth异常段,读取线代表阈值。(a)、(b)、©、(d)分别为不同时刻的数据块。
元异常检测:在具有MTS数据的真实单词应用程序中,可能需要使检测模型适应新的MTS,例如具有有限观察数据的新机器或新网站。因此,我们定义了一个新的实验设置,称为元异常检测,以评估模型在实际应用场景中的性能。对于我们实验中的所有数据集,我们使用80%的mts作为历史数据,其他作为新数据。在真实的word应用中,如果在新设备上部署一对一的异常检测模型,我们可能只有很少的数据样本来训练模型。基于以上原因,我们在每个新的MTS中对i (i∈{1,5,10,20,200})样本进行一对一的模型训练,并在其余数据上对模型进行测试。对于“一刀切”模型,参数已根据历史mts进行了更新。不同方法的检测性能如表2所示。正如我们所看到的,一对一模型不能在有限的观察值下正确地学习正常模式,从而导致性能下降。相反,得益于历史mss中存储的信息,包括GmVRNN和PUAD在内的“一对一”模型比“一对一”模型的性能要好得多。此外,借助可转移的全局原型和元学习的局部原型,PUAD实现了最佳的元异常检测性能。此外,为了进一步证明我们为一对一设置设计的原型的优势,我们使用历史数据对一对一模型进行预训练,并在新的mts中对前i个数据进行微调。如表2所示,一对一模型可以执行得更好,因为涉及历史mts,但它们的性能仍然比PUAD差得多。我们在附录中列出了更多的结果。
4.2.3. 消融研究
如图3 (a)所示,我们进一步研究了各部分在PUAD中的作用。在我们的烧蚀研究中进行了四个实验,变压器是一个只有三层变压器的基线模型,变压器+VAE将变压器结构纳入VAE编码器中,变压器+VAE+POT进一步介绍了所提出的POT模块,而PUAD则是将OT成本作为常规条款纳入损耗的集成版本。从图3 (a)中我们可以看到,在四个数据集上,PUAD的平均性能比Transformer+VAE+POT的平均性能好4.52%,这表明我们提出的基于OT的损失函数正则项的有效性。对比Transformer+VAE+POT和Transformer+VAE,我们发现所提出的POT模型的F1得分平均提高了7.11%,这得益于面向原型的框架。简而言之,我们合并到模型中的所有组件都可以提高性能,说明每个组件的有效性。
4.2.4. 定性分析
异常评分:首先,我们比较了PUAD、Anomaly Transformer、Transformer + VAE和一个简单Transformer的异常评分。结果如图4所示。作为确定性方法,Transformer忽略了MTS的随机性,得到了较为粗糙的异常评分,而对于概率方法,Transformer + VAE的异常评分由于概率模型设计更为精细,得到了较为平滑的异常评分。然而,简单的高斯隐变量模型仍然难以处理一些困难的情况。图4 (a) - ©表示了几种可以检测到PUAD但其他方法无法检测到的情况。在(a)和©中,模型很容易忽略一些不明显的异常作为噪声,而PUAD可以检测到这些异常,但其他异常由于鲁棒性不够,无法提供足够高的异常评分。在图4 (b)中,更加实用的模型设计使得Anomaly Transformer和PUAD的异常得分更高,从而成功检测到异常。如图4 (d)所示,由于POT提供了多样化的全局信息,在非异常状态下,PUAD的异常评分远低于其他模型。POT在原型中寻找相关信息的过程可以等同于将当前MTS与大量历史数据进行比较。这样可以使PUAD在非异常情况下获得更平滑的异常分数,在异常情况下获得更高的异常分数。
传输概率矩阵:在本文中,一个重要的贡献是提出了一个面向原型的UAD模型,我们希望通过原型在多个mss中捕获不同的时间信息,以增强对正常模式的捕获。从学习良好的原型中为新的mts回忆适当的信息对我们的模型至关重要。为了验证这种能力,我们在图5中观察了POT的传输概率矩阵权重。我们随机选择5个原型,以可视化所选原型与θ0之间的输运概率权重,以便观察。图的顶部显示了MTS数据,其中包含由红框表示的四种不同的动态模式。下面的柱状图表示红框中概率权重的平均值。如图5所示,通过调整输运概率权重,可以对不同的mts生成相应的原型。
4.2.5. 时间效率
与之前的工作类似(Dai et al., 2022),我们测试了不同方法的时间效率,包括我们提出的PUAD、基于变压器的方法TranAD、基于rnn的方法GmVRNN的训练和测试时间,结果如表3所示。我们可以看到,在图形处理单元(gpu)的加速下,我们提出的方法的训练和测试时间比其他方法要短得多。同时,所有模型都可以在十分之一秒内完成对一个样本的异常检测,而数据采集间隔为60秒,说明这些方法可以用于在线检测。
五、 结论
本文提出了一种新的面向原型的概率元异常检测方法——PUAD,以改进现有的MTS无监督异常检测方法在对多种正态模式建模和适应新数据方面的局限性。PUAD通过定义一组原型来考虑多个MTS中的各种动态,并将每个MTS视为这些原型上的分布。在此基础上,提出了一种基于重构的无监督异常检测方法,并在此基础上建立了基于transformer的强大概率动态生成框架。PUAD不仅可以利用全局原型捕获多个mss的各种正常模式,还可以利用元学习可转移原型实现对新mss的高模型自适应能力。在5个数据集上的大量实验表明,PUAD在MTS的常规和元异常检测任务上都达到了SOTA的性能。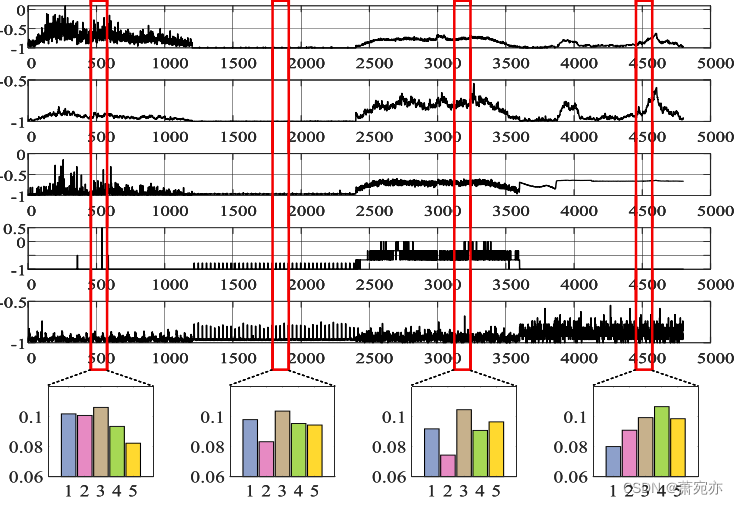
图5。传输概率矩阵权重的说明。图上半部分为部分MTS通道,截取了四种不同的图案,下半部分高=5.0cm,宽=9.0cm为相应位置的矩阵权重,用红框表示。
本研究得到国家自然科学基金项目(项目编号:U21B2006)的部分资助;部分由陕西省青年创新团队项目资助;部分项目由中央高校基本科研业务费专项资金QTZX23037和QTZX22160资助;部分由B18039拨款下的111计划资助;陈文超的工作得到了国家雷达信号处理实验室项目(JKW202X0X)和国家自然科学基金(6220010437)的稳定支持。















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









