






系列文章目录
具有自适应路径的多尺度变压器时间序列预测 ICLR2024
文章目录
摘要
基于变压器的模型在时间序列预测中取得了一定的成功。现有的方法主要是从有限或固定的尺度上对时间序列进行建模,很难捕捉到不同尺度上的不同特征。本文提出了一种具有自适应路径的多尺度变压器Pathformer。所提出的Pathformer集成了时间分辨率和时间距离,用于多尺度建模。多尺度分割利用不同大小的补丁将时间序列划分为不同的时间分辨率。基于每个尺度的划分,对这些补丁进行双重关注,以捕获全局相关性和局部细节作为时间依赖性。我们进一步丰富了多尺度变压器的自适应路径,该路径根据输入时间序列中变化的时间动态自适应调整多尺度建模过程,提高了Pathformer的预测精度和泛化能力。在11个真实数据集上的大量实验表明,Pathformer不仅超越了所有现有模型,达到了最先进的性能,而且在各种迁移场景下表现出更强的泛化能力。
提示:以下是本篇文章正文内容
一、引言
时间序列预测是各种行业的基本功能,如能源、金融、交通、物流和云计算(Chen et al., 2012;Cirstea et al., 2009;Ma et al., 2014;Zhu等,2023;Pan et al., 2023;Pedersen等人,2020),也是其他时间序列分析的基础构建块,例如异常值检测Campos等人(2022);Kieu等人(2022b)。由于其在序列建模中的广泛应用以及在CV和NLP等各个领域取得的令人印象深刻的成功(Dosovitskiy等人,2021;Brown等人,2020),Transformer (Vaswani等人,2017)在时间序列中受到越来越多的关注(Wen等人,2023;Wu et al., 2021;Chen et al., 2022)。尽管性能不断提高,但最近的工作已经开始通过提出性能更好的更简单的线性模型来挑战transformer的现有时间序列预测设计(Zeng et al., 2023)。虽然变形金刚的能力在时间序列预测方面仍然很有前景(Nie et al., 2023),但它需要更好的设计和适应来实现其潜力。
现实世界的时间序列在不同的时间尺度上表现出不同的变化和波动。例如,云计算中CPU、GPU和内存资源的利用揭示了跨越日、月和季节尺度的独特时间模式(Pan et al., 2023)。这需要多尺度建模(Mozer, 1991;Ferreira et al., 2006)用于时间序列预测,它从不同尺度的时间间隔中提取时间特征和依赖关系。对于时间序列中的多尺度,有两个方面需要考虑:时间分辨率和时间距离。时间分辨率对应于我们如何在模型中查看时间序列,并决定每个时间补丁或建模考虑的单元的长度。在图1中,同一时间序列可以分为小块(蓝色)或大块(黄色),从而得到细粒度或粗粒度的时间特征。时间距离对应于我们如何显式地建模时间依赖性,并决定时间建模所考虑的时间步之间的距离。在图1中,黑色箭头对附近时间步长之间的关系进行建模,形成局部细节,而彩色箭头对长范围内的时间步长进行建模,形成全局相关性。
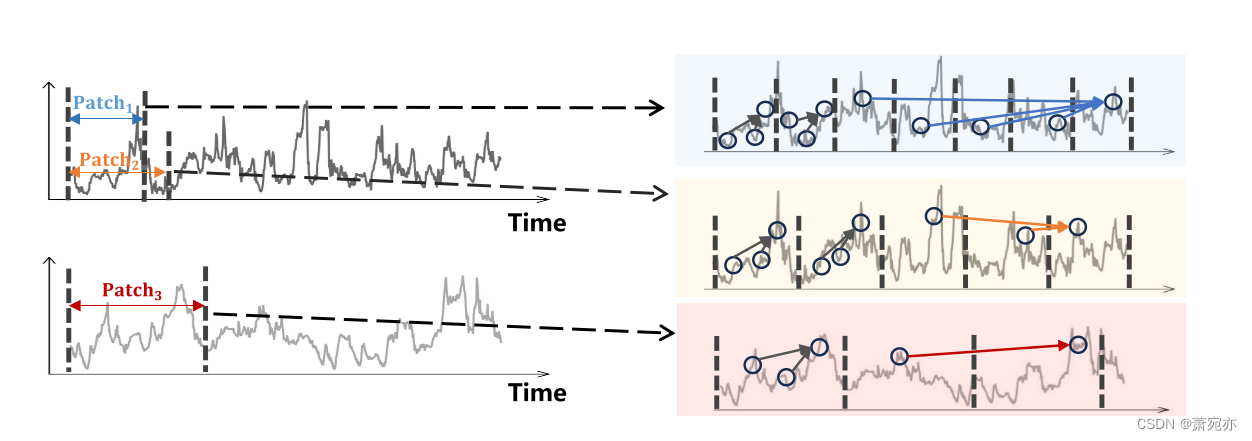
图1:左:时间序列按照时间分辨率划分为不同大小的patch。蓝色、橙色和红色的间隔表示不同的斑块大小。右图:局部细节(黑色箭头)和全局相关性(彩色箭头)通过不同的时间距离建模。
为了进一步探索Transformer在时间序列预测中提取相关性的能力,本文重点研究了利用Transformer架构增强多尺度建模的方面。两个主要问题限制了变形金刚多尺度建模的有效性。第一个挑战是多尺度建模的不完全性。查看不同时间分辨率的数据隐含地影响后续建模过程的尺度(Shabani et al., 2023)。然而,简单地改变时间分辨率并不能明确有效地强调不同范围内的时间依赖性。相反,考虑不同的时间距离可以从不同的范围建模依赖关系,例如全局和局部相关性(Li et al., 2019)。然而,全局和局部间隔的确切时间距离受到数据分割的影响,从单一的时间分辨率角度来看,这是不完整的。第二个挑战是固定的多尺度建模过程。虽然多尺度建模对时间序列的理解更加完整,但不同的序列根据其特定的时间特征和动态,选择不同的尺度。例如,对比图1中的两个序列,上面的序列显示出快速波动,这可能意味着更关注细粒度和短期特征。相反,下面的系列可能需要更多地关注粗粒度和长期建模。所有数据的固定多尺度建模阻碍了对每个时间序列的关键模式的掌握,并且手动调整数据集或每个时间序列的最佳尺度是耗时或棘手的。为了解决这两个问题,需要自适应多尺度建模,即对当前数据从一定的多个尺度进行自适应建模。
基于以上对多尺度建模的理解,我们提出了具有自适应路径的多尺度变压器(Pathformer)用于时间序列预测。为了实现更完整的多尺度建模,我们提出了一种统一多尺度时间分辨率和时间距离的多尺度Transformer块。提出了多尺度分割,将时间序列分割成不同大小的小块,形成不同时间分辨率的视图。基于每个划分的斑块大小,提出了包含斑块间和斑块内注意力的双重注意力来捕获时间依赖性,其中斑块间注意力捕获斑块间的全局相关性,斑块内注意力捕获单个斑块内的局部细节。我们进一步提出了自适应途径来激活多尺度建模能力并赋予其自适应建模特性。在模型的每一层,多尺度路由器根据输入数据自适应地选择特定大小的patch分割和后续的Transformer双关注,控制多尺度特征的提取。我们为路由器配置了趋势分解和季节性分解,增强了路由器对时间动态的把握能力。路由器与聚合器一起通过加权聚合自适应地组合多尺度特征。逐层路由和聚合在整个Transformer中形成了多尺度建模的自适应路径。据我们所知,这是首次将自适应多尺度模型引入时间序列预测的研究。具体而言,我们做出以下贡献:
•我们提出了一个多尺度变压器架构。它融合了时间分辨率和时间距离两个视角,使模型具有更完整的多尺度时间序列建模能力。
•我们进一步提出了多尺度变压器中的自适应路径。具有时间分解的多尺度路由器与聚合器协同工作,根据输入数据的时间动态特性自适应提取和聚合多尺度特征,实现对时间序列的自适应多尺度建模。
•我们在不同的真实世界数据集上进行了广泛的实验,并实现了最先进的预测精度。此外,我们进行了跨数据集的迁移学习实验,以验证模型的强泛化性。
二、相关工作
时间序列预测。时间序列预测是在历史观测的基础上预测未来的观测结果。基于指数平滑及其不同风格的统计建模方法是时间序列预测的可靠工具(Hyndman & Khandakar, 2008;Li et al., 2022a)。在深度学习方法中,GNNs对相关时间序列预测的空间依赖性进行建模(Jin et al., 2023a;Wu et al., 2020;赵等,2024;Cheng等,2024;苗等,2024;Cirstea et al., 2021)。rnn模型的时间依赖性(Chung et al., 2014;Kieu et al., 2009;Wen et al., 2017;Cirstea et al., 2019)。DeepAR (Rangapuram et al., 2018)使用rnn和自回归方法预测未来短期序列。CNN模型使用时间卷积提取子序列特征(Sen et al., 2019;刘等,2022a;Wang et al., 2023)。TimesNet (Wu et al., 2023a)将原来的一维时间序列转换为二维空间,通过卷积捕获多周期特征。基于llm的方法在该领域也显示出有效的性能(Jin et al., 2023b;Zhou et al., 2023)。此外,一些方法结合神经架构搜索来发现最优架构(Wu et al., 2022;2023b)。
变压器模型最近在时间序列预测中受到了越来越多的关注(Wen et al., 2023)。Informer (Zhou et al., 2021)提出了probo -sparse self-attention来选择重要的key, Triformer (Cirstea et al., 2022a)采用三角形架构,降低了复杂度。Autoformer (Wu et al., 2021)提出了自相关机制来取代自关注来建模时间动态。FEDformer (Zhou et al., 2022)从频率的角度利用傅里叶变换来模拟时间动态。然而,研究人员对变形金刚在时间序列预测中的有效性提出了担忧,因为简单的线性模型被证明是有效的,甚至优于以前的变形金刚(Li et al., 2022a;Challu et al., 2023;Zeng et al., 2023)。与此同时,PatchTST (Nie et al., 2023)在Transformer中使用了补丁和信道独立来有效地提高性能,这表明Transformer架构在时间序列预测中仍然有其潜力,只要适当的适应。
时间序列的多尺度建模。多尺度特征建模被证明对计算机视觉等领域的相关学习和特征提取是有效的(Wang et al., 2021;Li et al., 2012;Wang et al., 2022b)和多模式学习(Hu et al., 2020;Wang et al., 2022a),这在时间序列预测中探索相对较少。N-HiTS (Challu et al., 2023)采用多速率数据采样和分层插值来模拟不同分辨率的特征。Pyraformer (Liu et al., 2022b)引入了金字塔关注来提取不同时间分辨率下的特征。Scaleformer (Shabani et al., 2023)提出了一个多尺度框架,需要在不同的时间分辨率下分配一个预测模型,这导致了更高的模型复杂性。这些方法使用固定的尺度,不能自适应地改变不同时间序列的多尺度建模,而我们提出了一种基于不同时间动态的多尺度自适应路径的多尺度变压器。
三、方法
为了有效地捕获多尺度特征,我们提出了具有自适应路径的多尺度变压器(称为Pathformer)。如图2所示,整个预测网络由实例Norm、自适应多尺度块(AMS Blocks)堆叠和Predictor组成。实例规范(Kim et al., 2022)是一种用于解决训练数据和测试数据之间分布转移的归一化技术。Predictor是一种全连接神经网络,因其适用于长序列预测而被提出(Zeng et al., 2023;Das et al., 2023)。
我们设计的核心是用于多尺度特征自适应建模的AMS模块,它由多尺度Transformer模块和自适应路径组成。受《变形金刚》(Nie et al., 2023)中的补丁思想的启发,多尺度Transformer块通过引入具有多个补丁大小的补丁分割和对分割后的补丁的双重关注,集成了多尺度时间分辨率和距离。使模型具有综合模拟多尺度特征的能力。基于Transformer块中的多种多尺度建模选项,自适应路径利用多尺度建模能力,赋予其自适应建模特征。多尺度路由器根据输入数据在Transformer中选择特定大小的patch分割和后续的双重关注,控制多尺度特征的提取。路由器与聚合器一起工作,通过加权聚合来组合这些多尺度特征。逐层路由和聚合形成了贯穿Transformer块的多尺度建模的自适应路径。在接下来的部分中,我们详细描述了多尺度变压器模块和AMS模块的自适应路径。
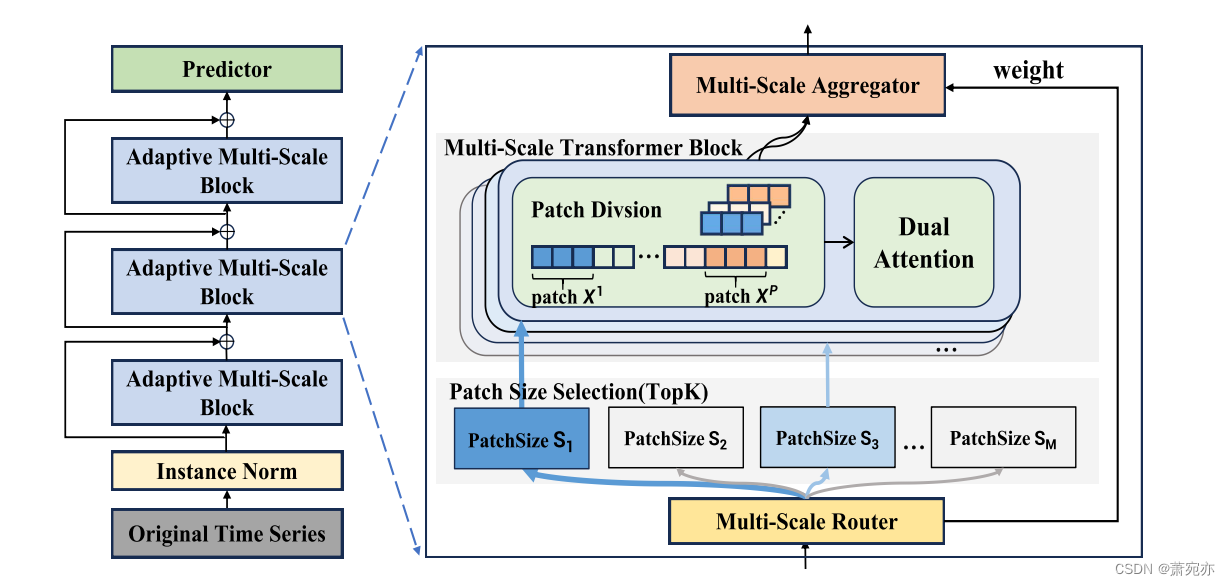
图2:Pathformer的架构。多尺度变压器块(MST块)由多个补丁大小的补丁划分和双重关注组成。自适应路径根据路由器生成的前K个权重值选择补丁大小,以捕获多尺度特征,选择的补丁大小用蓝色表示。然后,聚合器对从MST块中获得的特征进行加权聚合。
3.1 MULTI-SCALE TRANSFORMER BLOCK
多尺度划分。为了简化符号,我们使用单变量时间序列进行描述,并且通过独立考虑每个变量,该方法可以很容易地扩展到多变量情况。在多尺度Transformer块中,我们定义M个补丁大小值的集合为 S = { S 1 , … , S M } \mathcal{S}=\{S_{1},\ldots,S_{M}\} S={S1,…,SM},每个补丁大小S对应一个补丁分割操作。对于输入的时间序列 X ∈ R H × d {\text{X}} \in \mathbb{R}^{H\times d} X∈RH×d,其中H表示时间序列的长度,d表示特征的维数,每一次以patch大小为S的patch分割操作,将X分割成P个(P = H/S) patch,分别为 ( X 1 , X 2 , … , X P ) , (\mathrm{X}^{1},{\mathrm{X}}^{2},\ldots,\mathrm{X}^{P}), (X1,X2,…,XP),,其中每个补丁 X i ∈ R S × d \mathrm{X}^{i}\in\mathbb{R}^{S\times d} Xi∈RS×d包含S个时间步长。集合中不同的补丁大小导致不同的分割补丁的尺度,并给出输入序列的不同时间分辨率视图。这种多尺度划分与下面描述的多尺度建模的双重注意机制一起工作。
双重注意力。基于每个尺度的斑块划分,我们提出了在划分的斑块上对模型时间依赖性的双重关注。为了掌握不同时间距离上的时间依赖性,我们对不同的时间距离采用补丁划分作为指导,双注意机制包括每个被划分的补丁内的补丁内注意和不同补丁间的补丁间注意,如图3(a)所示。
考虑一组补丁 ( X 1 , X 2 , … , X P ) \mathrm{(X^{1},X^{2},\dots,X^{P})} (X1,X2,…,XP), XP)除以补丁大小S,补丁内注意力建立了每个补丁内时间步长之间的关系。对于第i个patch X i ∈ R S × d \mathrm{X}^{i}\in\mathbb{R}^{S\times d} Xi∈RS×d,我们首先沿着特征维d嵌入该patch,得到 X i n t r a i ∈ R S × d m X_{\mathrm{intra}}^{i}\in\mathbb{R}^{S\times d_{m}} Xintrai∈RS×dm,其中dm表示嵌入维数。然后对 X i n t r a i \mathrm{X}_{\mathrm{intra}}^{i} Xintrai进行可训练的线性变换,得到注意力运算中的键和值,记为 K i n t r a i , V i n t r a i ∈ R S × d m K_{\mathrm{intra}}^{i},V_{\mathrm{intra}}^{i}\in\mathbb{R}^{S\times d_{m}} Kintrai,Vintrai∈RS×dm。我们使用一个可训练的查询矩阵 Q i n t r a i ∈ R 1 × d m Q_{\mathrm{intra}}^{i}\in\mathbb{R}^{1\times d_{m}} Qintrai∈R1×dm来合并patch的上下文,然后计算 Q i n t r a i , K i n t r a i , V i n t r a i Q_{\mathrm{intra}}^i,K_{\mathrm{intra}}^i,V_{\mathrm{intra}}^i Qintrai,Kintrai,Vintrai之间的交叉关注来建模第i个patch内的局部细节:
A t t n i n t r a i = S o f t m a x ( Q i n t r a i ( K i n t r a i ) T / d m ) V i n t r a i . \mathrm{Attn}_{\mathrm{intra}}^i=\mathrm{Softmax}(Q_{\mathrm{intra}}^i(K_{\mathrm{intra}}^i)^T/\sqrt{d_m})V_{\mathrm{intra}}^i. Attnintrai=Softmax(Qintrai(Kintrai)T/dm)Vintrai.
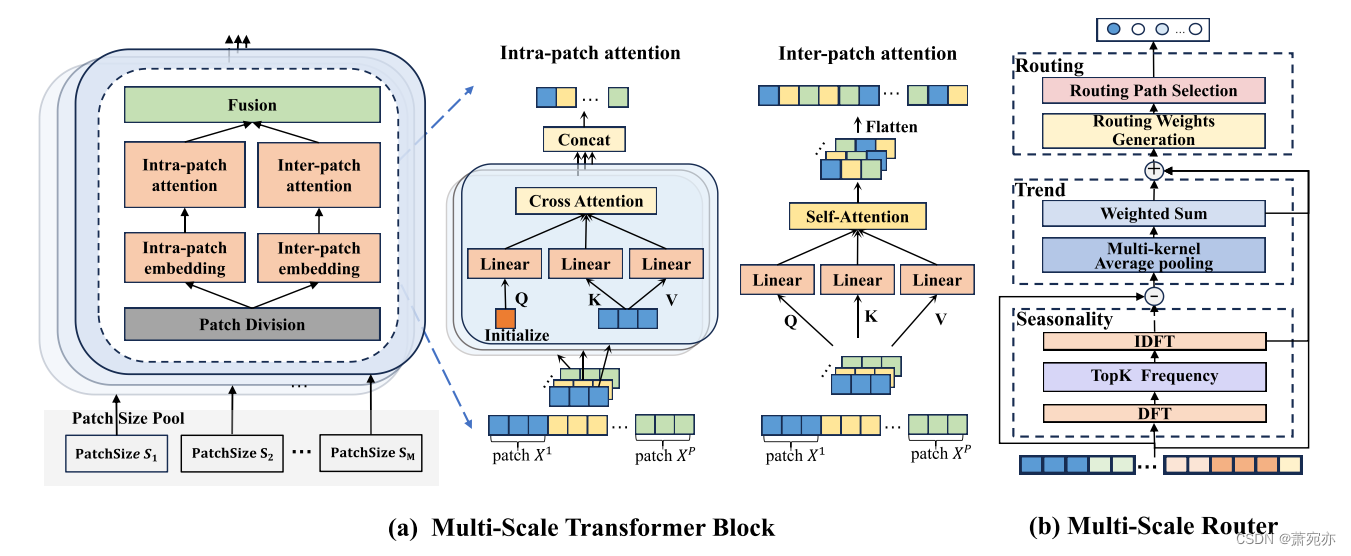
图3:(a)多尺度变压器块的结构,主要由Patch Division、Inter-patch attention和Intra-patch attention组成。(b) Multi-Scale Router的结构。
经过patch内关注后,每个patch从原来的输入长度S转变为1。将所有patch的关注结果进行连接,得到分割后patch的intra-attention输出为 Attn intra ∈ R P × d m {\text{Attn}_\text{intra }} \in \mathbb{R}^{P\times d_m} Attnintra ∈RP×dm,表示时间序列中邻近时间步长的局部细节:
A t t n i n t r a = C o n c a t ( A t t n i n t r a 1 , … , A t t n i n t r a P ) . \mathrm{Attn}_{\mathrm{intra}}=\mathrm{Concat}(\mathrm{Attn}_{\mathrm{intra}}^1,\ldots,\mathrm{Attn}_{\mathrm{intra}}^P). Attnintra=Concat(Attnintra1,…,AttnintraP).
补丁间注意力建立了补丁之间的关系,以捕捉全局相关性。对于patch分割的时间序列 X ∈ R P × S × d \mathrm{X}\in\mathbb{R}^{P\times S\times{d}} X∈RP×S×d,我们首先沿特征维度d ~ dm进行特征嵌入,然后将数据重新排列,将patch数量S和特征嵌入dm这两个维度结合起来,得到 X i n t e r ∈ R P × d m ′ \mathrm{X}_{\mathrm{inter}}\in\mathbb{R}^{P\times d_{m}^{'}} Xinter∈RP×dm′,其中 d m ′ = S ⋅ d m \begin{aligned}d_m^{'}&=S\cdot d_m\end{aligned} dm′=S⋅dm。经过这样的嵌入和重新排列过程,将同一斑块内的时间步长组合在一起,因此我们在Xinter上执行自关注来建模斑块之间的相关性。我们按照标准的自关注协议,通过在Xinter上的线性映射得到查询、键和值,记为 Q i n t e r , K i n t e r , V i n t e r ∈ R P × d m ′ Q_{\mathrm{inter}},K_{\mathrm{inter}},V_{\mathrm{inter}}\in\mathbb{R}^{P\times d_{m}^{'}} Qinter,Kinter,Vinter∈RP×dm′,然后计算注意力 A t t n i n t e r Attn_{inter} Attninter,它涉及到patch之间的相互作用,表示时间序列的全局相关性:
A t t n i n t e r = S o f t m a x ( Q i n t e r ( K i n t e r ) T / d m ′ ′ ) V i n t e r . ( 3 ) \mathrm{Attn}_{\mathrm{inter}}=\mathrm{Softmax}(Q_{\mathrm{inter}}(K_{\mathrm{inter}})^T/\sqrt{d_{m^{\prime}}^{\prime}})V_{\mathrm{inter}}.\quad\quad\quad\quad(3) Attninter=Softmax(Qinter(Kinter)T/dm′′)Vinter.(3)
为了融合全局相关性和双关注捕获的局部细节,我们将patch内关注的输出重新排列到 A t t n i n t r a ∈ R P × S × d m \mathop{\mathrm{Attn_{intra}}}\in\mathbb{R}^{P\times S\times d_{m}} Attnintra∈RP×S×dm,对patch大小维度进行从1到S的线性变换,将每个patch中的时间步长组合起来,再与patch间关注 A t t n i n t e r ∈ R P × S × d m \mathrm{Attn}_{\mathrm{inter}}\in\mathbb{R}^{P\times S\times d_m} Attninter∈RP×S×dm相加,得到双关注 Attn ∈ R P × S × d m \begin{aligned}\text{Attn}\in\mathbb{R}^{P\times S\times d_m}\end{aligned} Attn∈RP×S×dm的最终输出。
总体而言,多尺度分割提供了不同斑块大小的时间序列的不同视图,而斑块大小的变化进一步影响了双注意,双注意在斑块分割的指导下从不同距离建模时间依赖性。这两个组件一起工作以支持Transformer中的多个时间建模尺度。
3.2 ADAPTIVE PATHWAYS
多尺度变压器块的设计使模型具备了多尺度建模的能力。然而,不同的序列可能偏好不同的尺度,这取决于它们特定的时间特征和动态。简单地应用更多的尺度可能会带来冗余或无用的信号,并且手动调整数据集或每个时间序列的最佳尺度是耗时或棘手的。理想的模型需要在输入数据的基础上找出这样的关键尺度,以便更有效地建模和更好地泛化未见数据。
为了实现自适应多尺度建模,我们提出了基于多尺度Transformer的自适应路径,如图2所示。它包括两个主要组成部分:多尺度路由器和多尺度聚合器。多尺度路由器根据输入数据选择特定大小的贴片分割,激活变压器中的特定部件,控制多尺度特征的提取。路由器与多尺度聚合器一起通过加权聚合将这些特征组合起来,得到Transformer块的输出。
多尺度路由器。多尺度路由器在多尺度变压器中实现数据自适应路由,选择最优尺寸进行贴片分割,从而控制多尺度建模过程。由于每个时间序列的最优尺度或临界尺度可能受到其复杂的固有特征和动态模式(如周期性和趋势)的影响,因此我们在路由器中引入了一个时间分解模块,该模块包含季节性和趋势分解,以提取周期性和趋势模式。如图3(b)所示。
季节性分解包括将时间序列从时域转换到频域,以提取周期模式。我们利用分辨傅立叶变换(DFT) (Cooley & Tukey, 1965),记为DFT(·),将输入X分解为傅立叶基,并选择振幅最大的Kf基,以保持频域的稀疏性。然后,我们通过逆DFT得到周期模式Xsea,记为IDFT(·)。流程如下:
X s e a = I D F T ( { f 1 , … , f K f } , A , Φ ) , \mathrm{X}_{\mathrm{sea}}=\mathrm{IDFT}(\{f_1,\ldots,f_{K_f}\},A,\Phi), Xsea=IDFT({f1,…,fKf},A,Φ),
其中Φ和A表示DFT(X)中各频率的相位和幅度, { f 1 , … , f K f } \{f_1,\ldots,f_{K_f}\} {f1,…,fKf}表示Kf幅值最高的频率。趋势分解采用移动平均线平均池化的不同核,在季节性分解 X r e m = X − X s e a \mathrm{X_{rem}}=\mathrm{X-X_{sea}} Xrem=X−Xsea后的剩余部分基础上提取趋势模式。对于不同核得到的结果,进行加权运算得到趋势分量的表示:
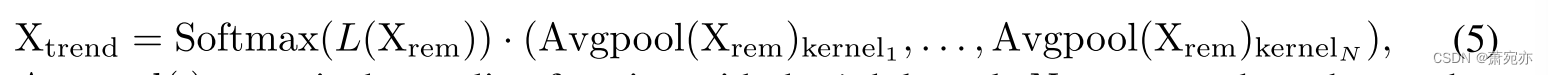
其中 A v g p o o l ( ⋅ ) k e r n e l i \mathrm{Avgpool}(\cdot)_{\mathrm{kernel}_i} Avgpool(⋅)kerneli是第i个内核的池化函数,N对应内核的个数,Softmax(L(·))控制不同内核结果的权重。我们将季节性模式和趋势模式与原始输入X相加,然后进行线性映射 Linear ( ⋅ ) \operatorname{Linear}(\cdot) Linear(⋅),沿时间维度进行变换合并,得到 X t r a n s ∈ R d \mathrm{X}_{\mathrm{trans}}\in\mathbb{R}^d Xtrans∈Rd。
基于时间分解的结果 X t r a n s \mathrm{X}_{\mathrm{trans}} Xtrans,路由器使用路由函数来生成路径权重,从而确定当前数据选择的补丁大小。为了避免始终选择几个补丁大小,导致相应的尺度被反复更新,而忽略了多尺度变压器中其他可能有用的尺度,我们在权重生成过程中引入噪声项来增加随机性。生成路径权值的整个过程如下:
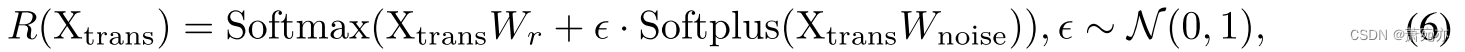
式中,R(·)表示整个路由函数,
W
r
W_{r}
Wr和
W
noise
∈
R
d
×
M
\begin{aligned}W_{\text{noise}} \in \mathbb{R}^{d\times M}\end{aligned}
Wnoise∈Rd×M是生成权值的可学习参数,d表示
X
t
r
a
n
s
\mathrm{X}_{\mathrm{trans}}
Xtrans的特征维数,M表示patch大小的个数。为了在路由中引入稀疏性并鼓励选择关键尺度,我们对路径权重进行topK选择,保持前K个路径权重并将其余权重设置为0,并将最终结果表示为
R
ˉ
(
X
t
r
a
n
s
)
\bar{R}(\mathrm{X}_{\mathrm{trans}})
Rˉ(Xtrans)。
多尺度聚合器。生成的路径权值 R ˉ ( X t r a n s ) ∈ R M \bar{R}(\mathrm{X}_{\mathrm{trans}})\in\mathbb{R}^M Rˉ(Xtrans)∈RM的每一个维度对应于多尺度Transformer中的一个patch大小,其中 R ( X t r a n s ) i > 0 {R(\mathrm{X}_{\mathrm{trans}})}_{i}>0 R(Xtrans)i>0表示执行此大小的patch分割 S i S_{i} Si,双关注和 R ˉ ( X t r a n s ) i = 0 \bar{R}(\mathrm{X}_{\mathrm{trans}})_{i}=0 Rˉ(Xtrans)i=0表示忽略当前数据的此patch大小。令Xi表示多尺度变压器的输出,其patch大小为 S i S_{i} Si,由于不同的patch大小产生的时间维度不同,聚合器首先执行一个变换函数 T i ( ⋅ ) T_{i}(\cdot) Ti(⋅)来对齐不同尺度的时间维度。然后,聚合器根据路径权重对多尺度输出进行加权聚合,得到该AMS块的最终输出:
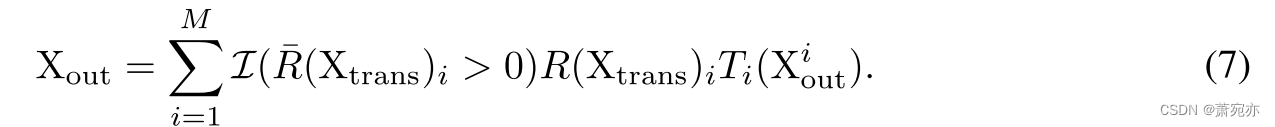
I
(
R
ˉ
(
X
t
r
a
n
s
)
i
>
0
)
\mathcal{I}(\bar{R}(\mathrm{X}_{\mathrm{trans}})_i>0)
I(Rˉ(Xtrans)i>0)是指示函数,当
R
ˉ
(
X
t
r
a
n
s
)
i
>
0
,
\bar{R}(\mathrm{X}_{\mathrm{trans}})_i>0,
Rˉ(Xtrans)i>0,输出1,否则输出0,表示在聚合时只考虑或需要Transformer的前K个patch大小和相应的输出。
四、实验
4.1时间序列预测
**数据集。**我们在九个真实世界的数据集上进行实验,以评估Pathformer的性能,包括电力运输、天气预报和云计算等一系列领域。这些数据集包括ETT (ETTh1、ETTh2、ETTm1、ETTm2)、天气、电力、交通、ILI和云集群(Cluster- a、Cluster- b、Cluster- c)。
基线和指标。我们选择了一些最先进的模型作为基线,包括PatchTST (Nie等人,2023)、NLinear (Zeng等人,2023)、Scaleformer (Shabani等人,2023)、TIDE (Das等人,2023)、FEDformer (Zhou等人,2022)、Pyraformer (Liu等人,2022b)和Autoformer (Wu等人,2021)。为了确保公平比较,所有模型都遵循相同的输入长度(ILI数据集H = 36,其他数据集H = 96)和预测长度(云集群数据集F∈{24,49,96,192},ILI数据集F∈{24,36,48,60},其他数据集F∈{96,192,336,720})。我们选择了时间序列预测中常用的两个指标:平均绝对误差(MAE)和均方误差(MSE)。
实现细节。Pathformer使用Adam优化器(Kingma & Ba, 2015),学习率设置为10−3。使用的默认损失函数是L1 loss,我们在训练过程中在10个epoch内实现提前停止。所有实验均使用PyTorch进行,并在NVIDIA A800 80GB GPU上执行。Pathformer由3个自适应多尺度块(AMS Blocks)组成。每个AMS块包含4个不同的补丁大小。这些补丁大小是从常用选项池中选择的,即{2,3,6,12,16,24,32}。
主要结果。表1显示了多变量时间序列预测的预测结果,在88个案例中,Pathformer在81个案例中表现最好,在5个案例中表现第二。与第二好的基线相比,PatchTST, Pathformer显示出显著的改善,MSE降低了8.1%,MAE降低了6.4%。与强线性模型NLinear相比,Pathformer也有全面的表现,特别是在电力和交通等大型数据集上。这证明了Transformer架构在时间序列预测方面的潜力。与多尺度模型Pyraformer和Scaleformer相比,Pathformer表现出了良好的性能提升,MSE降低了36.4%,MAE降低了19.1%。结果表明,基于时间分辨率和时间距离的自适应路径综合建模对于多尺度建模更为有效。
4.2 TRANSFER LEARNING迁移学习
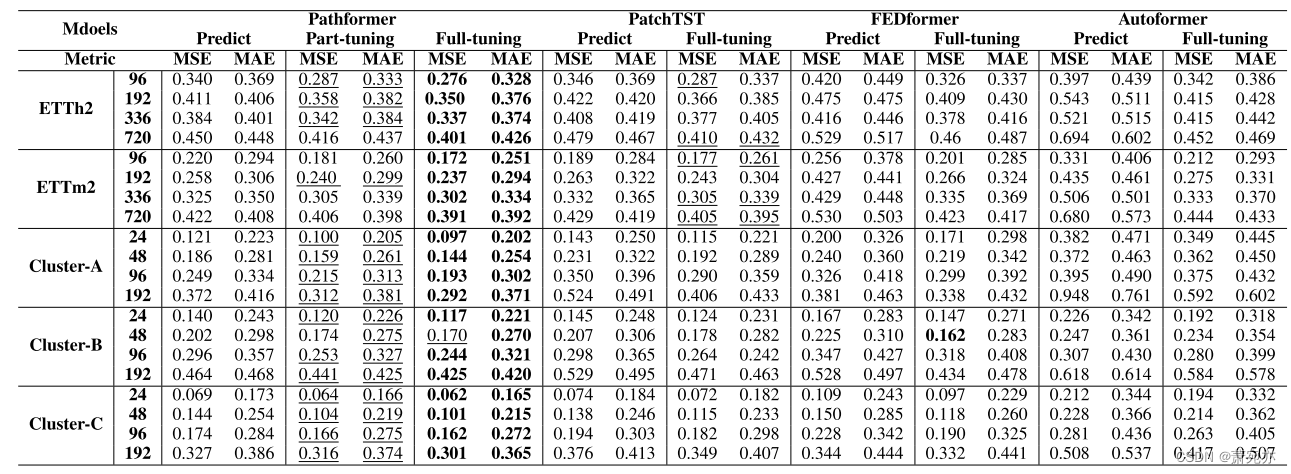
实验设置。为了评估Pathformer的可转移性,我们对三个基线进行了基准测试:PatchTST, FEDformer和Autoformer,设计了两个不同的转移实验。在评估不同数据集之间的可转移性的背景下,模型首先在ETTh1和ETTm1上进行预训练。随后,我们使用ETTh2和ETTm2对它们进行微调。为了评估对未来数据的可转移性,模型在来自三个集群(Cluster-A, Cluster-B和Cluster-C)的前70%的训练数据上进行预训练。这个预训练之后是对每个集群特定的剩余30%的训练数据进行微调。在基线的方法方面,我们探索了两种方法:直接预测(零射击)和全调优。与这些方法不同,Pathformer集成了部分调优策略。在这种方法中,特定参数(如路由器网络的参数)经过微调,从而显著减少了计算资源需求。
迁移学习结果。表2给出了我们迁移学习评估的结果。在直接预测和全调优方法中,Pathformer都超越了基线模型,突出了其增强的泛化和可转移性。Pathformer的一个关键优势在于它对不同时间动态选择不同尺度的自适应能力。这种适应性使其能够有效地捕获不同数据集中存在的复杂时间模式,从而显示出优越的泛化和可转移性。部分调优是一种轻量级的微调方法,它需要更少的计算资源,平均减少了52%的训练时间,同时仍然可以达到与Pathformer全面调优几乎相当的预测精度。此外,它在大多数数据集上优于其他基线模型的全调优。这表明Pathformer可以为时间序列预测提供有效的轻量级迁移学习。
表1:多元时间序列预测结果。输入长度H = 96 (ILI为H = 36)。最好的结果用粗体突出显示,次好的结果用下划线突出显示。
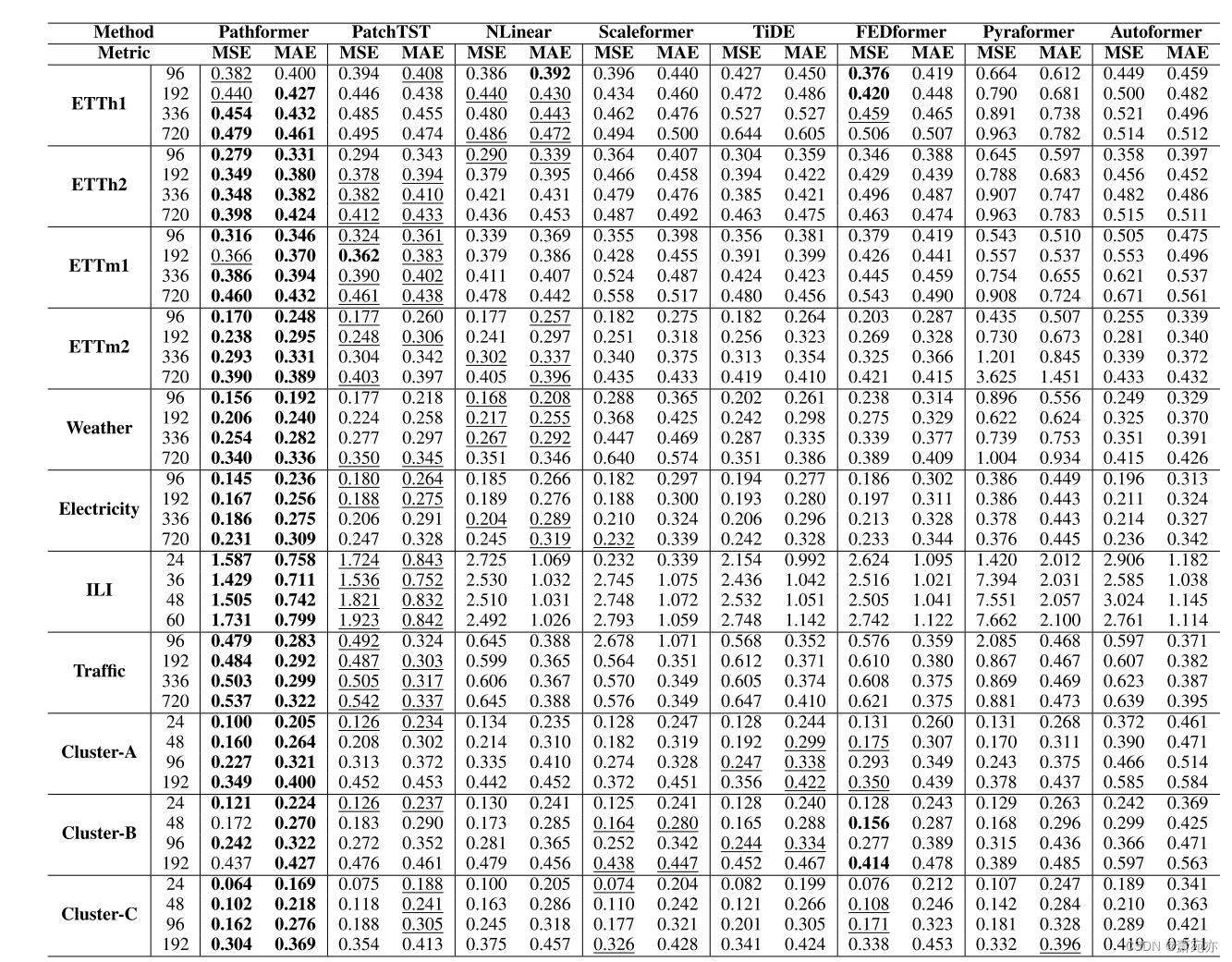
表2:迁移学习结果。最好的结果用粗体表示,第二的结果用下划线表示。
4.3消融研究
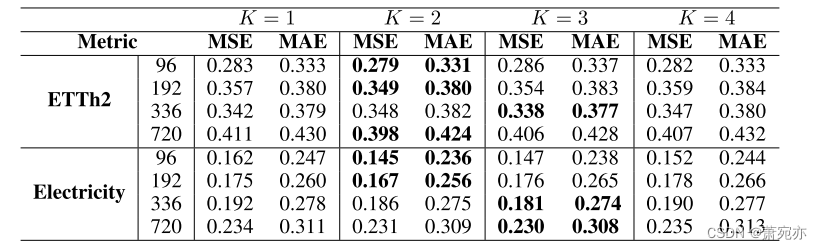
为了确定Pathformer中不同模块的影响,我们进行了聚焦于斑块间注意力、斑块内注意力、时间序列分解和路径的消融研究。W/O路径配置需要对每个数据集使用补丁大小池中的所有补丁大小,从而消除了自适应选择。表3说明了每个模块的独特影响。Pathways的影响是显著的;忽略它们会导致预测精度的显著降低。这强调了优化斑块大小组合以提取多尺度特征的重要性,从而显著提高了模型的预测精度。在效率方面,斑块内的注意力特别善于识别局部模式,而斑块间的注意力主要捕捉更广泛的全局模式。时间序列分解模块对趋势模式和周期模式进行分解,以提高捕获其输入的时间动态的能力,帮助识别适合组合的补丁大小。
表3:消融研究。W/O Inter、W/O Intra、W/O decomposition分别代表去除补丁间注意、补丁内注意和时间序列分解。
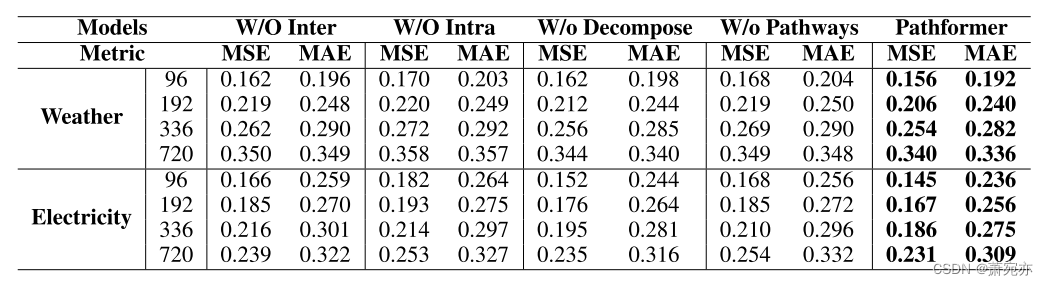
表4:参数敏感性研究。预测精度随K的变化而变化。
改变自适应选择的补丁大小的数量。Pathformer自适应选择前K个补丁大小进行组合,适应不同的时间序列样本。我们在表4中评估了不同K值对预测精度的影响。我们的研究结果表明,K = 2和K = 3比K = 1和K = 4产生更好的结果,突出了自适应建模关键多尺度特征的优势,以提高精度。此外,不同的时间序列样本受益于使用不同的补丁大小的特征提取,但并不是所有的补丁大小都是同样有效的。
路径权重可视化。我们展示了三个样本,并在图4中描绘了每个斑块大小的平均路径权重。我们的观察表明,样品具有独特的路径权重分布。样本1和样本2表现出较长的季节性和相似的趋势模式,显示出相似的可视化路径权重。这表现在它们赋予更大的补丁大小更高的权重。另一方面,样本3的特征是季节性模式较短,对于较小的斑块大小,其权重较高。这些观察结果强调了Pathformer的适应性,强调了其辨别和应用样本中不同季节和趋势模式的最佳斑块大小组合的能力。
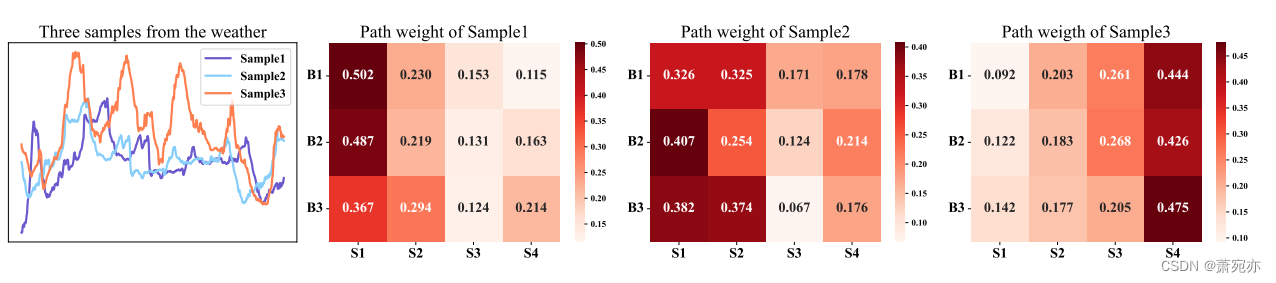
图4:不同斑块大小的平均路径权重。B1、B2和B3表示不同的AMS (Adaptive Multi-Scale)块,S1、S2、S3和S4表示每个AMS块内不同的补丁大小,补丁大小依次递减。
五、结论
本文提出了具有自适应路径的多尺度变压器Pathformer,用于时间序列预测。该方法通过引入多尺度补丁分割和对分割后的补丁的双重关注,将多尺度时间分辨率和时间距离相结合,实现多尺度特征的综合建模。此外,自适应路径根据不同的时间动态动态选择和聚合尺度特征。这些创新机制共同使Pathformer能够实现出色的预测性能,并在多个预测任务中展示出强大的泛化能力。
本工作得到国家自然科学基金(62372179)和阿里巴巴创新研究计划的支持。
A附录
A.1实验细节
a.1.1数据集
关于实验数据集的特殊细节如下:ETT 1数据集由7个变量组成,来自两台不同的变压器。它涵盖了2016年1月至2018年1月期间。每个变压器都记录了15分钟和1小时粒度的数据,标记为ETTh1, ETTh2, ETTm1和ETTm2。Weather 2数据集包括德国的21个气象指标,每10分钟收集一次。电力3数据集包含321名用户的用电量,每小时记录一次,时间跨度为2016年7月至2019年7月。ILI 4收集2002年至2021年期间美国疾病控制和预防中心关于流感样疾病患者的每周数据。Traffic 5包括来自加州交通部的每小时数据。这个数据集描绘了在旧金山湾区的高速公路上由各种传感器测量的道路占用率。云集群数据集是私有业务数据,每隔1分钟记录三个集群的客户资源需求:集群A、集群B、集群C,其中A、B、C分别代表不同的城市,时间段为2023年2月至2023年4月。对于数据集准备,我们遵循以往研究的既定做法(Zhou et al., 2021;Wu等人,2021)。详细统计数据如表5所示。
A.1.2基线在时间序列预测领域,近年来出现了许多模型。我们选择2021年至2023年具有卓越预测性能的模型作为基准,包括2021年最先进的(SOTA) Autoformer, 2022年SOTA FEDformer,以及2023年SOTA PatchTST和NLinear等。这些模型的具体代码库如下:
• PatchTST: https://github.com/yuqinie98/PatchTST
• NLinear: https://github.com/cure-lab/LTSF-Linear
• FEDformer: https://github.com/MAZiqing/FEDformer
• Scaleformer: https://github.com/borealisai/scaleformer
• TiDE: https://github.com/google-research/google-research/tree/master/tide
• Pyraformer: https://github.com/ant-research/Pyraformer
• Autoformer: https://github.com/thuml/Autoformer
A.2单变量时间序列预测
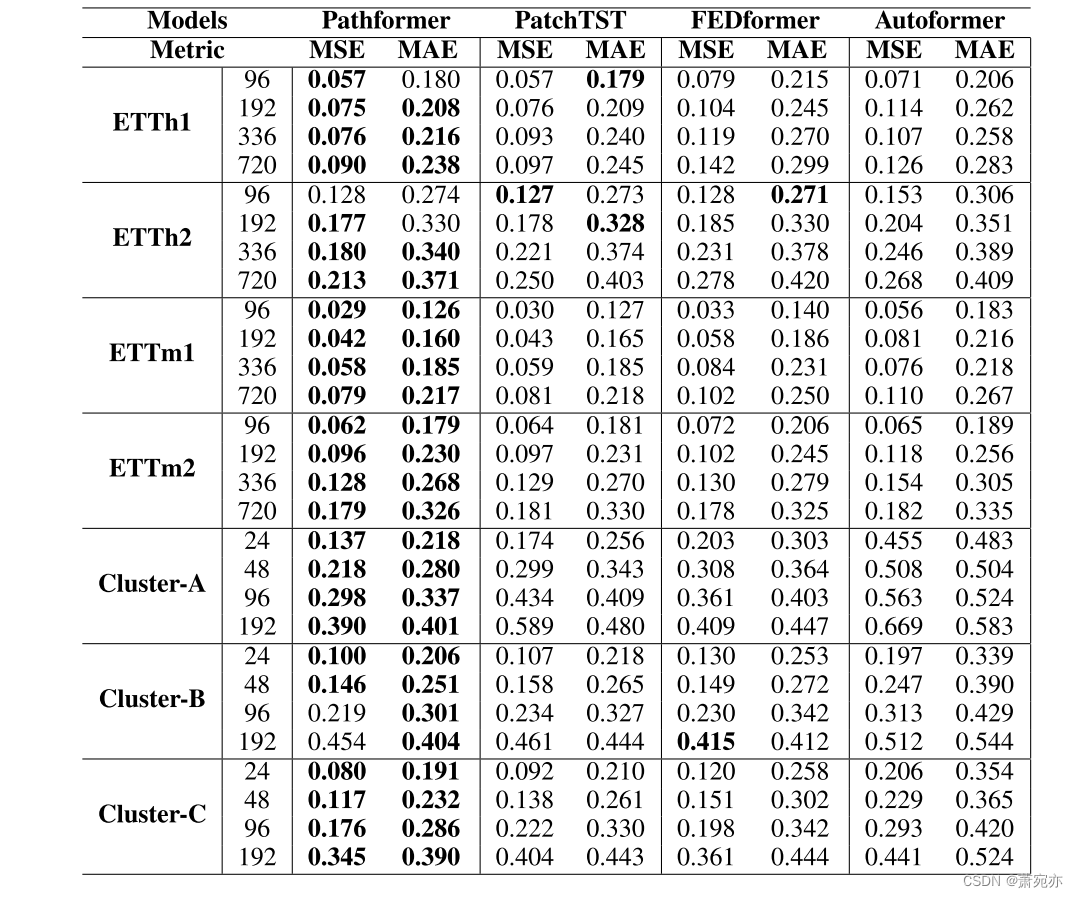
我们对ETT和Cloud cluster数据集进行了单变量时间序列预测实验。如表6所示,Pathformer在50个案例中表现最佳,在56个案例中有5个案例表现第二。Pathformer已经超越了第二好的基线PatchTST,特别是在云集群数据集上。我们的模型Pathformer在多变量和单变量时间序列预测中都表现出优异的预测性能。
1https://github.com/zhouhaoyi/ETDataset
2https://www.bgc-jena.mpg.de/wetter/
3https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014
4https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html
5https://pems.dot.ca.gov/
表6:单变量时间序列预测结果。输入长度H = 96,预测长度F∈{96,192,336,720}(对于云集群数据集F∈{24,48,96,192})。最好的结果以粗体突出显示。
A.3根据变压器型号改变输入长度
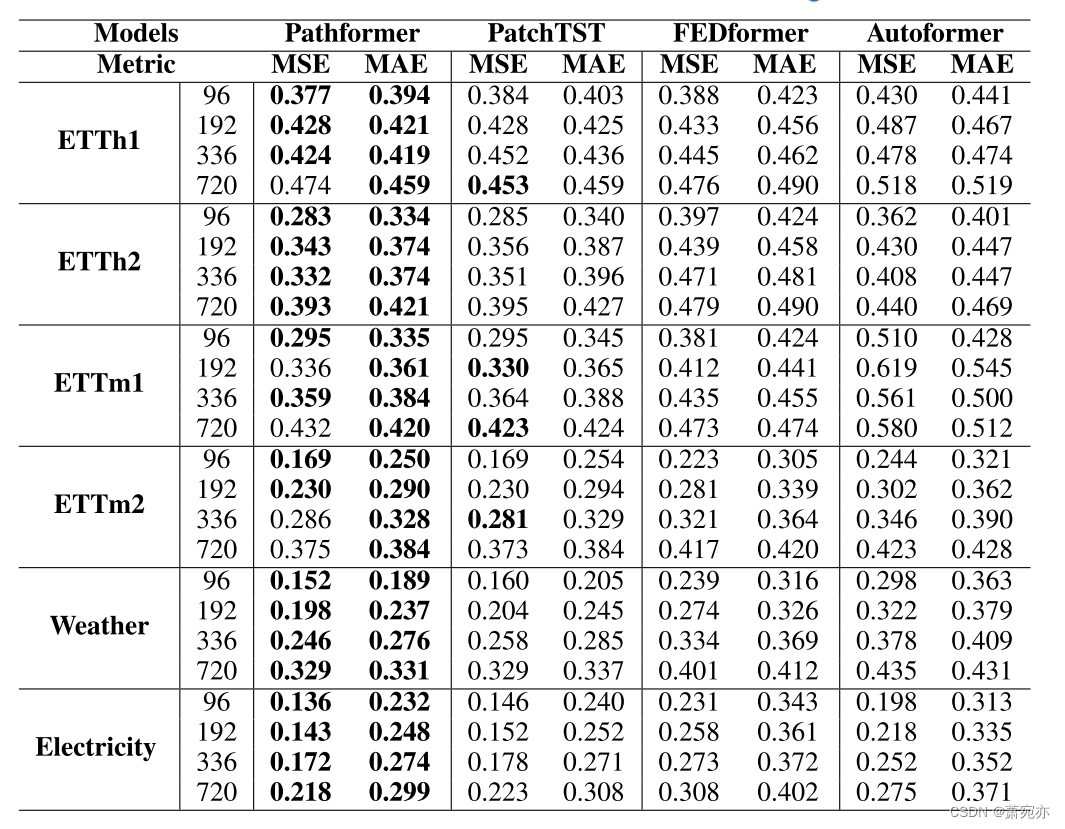
在时间序列预测任务中,输入长度的大小决定了模型接收到多少历史信息。我们从主要实验中选择预测性能较好的模型作为基准。我们配置不同的输入长度来评估Pathformer的有效性,并将输入长度为48,192的预测结果可视化。从图5中可以看出,Pathformer在ETTh1、ETTh2、Weather和Electricity上的表现始终优于基线。如表7和表8所示,当H = 48,192时,Pathformer在48个案例中分别有46个和44个案例表现最佳。基于上述结果,很明显Pathformer在不同输入长度上的表现优于基线。随着输入长度的增加,Pathformer的预测指标不断降低,表明它能够建模更长的序列。
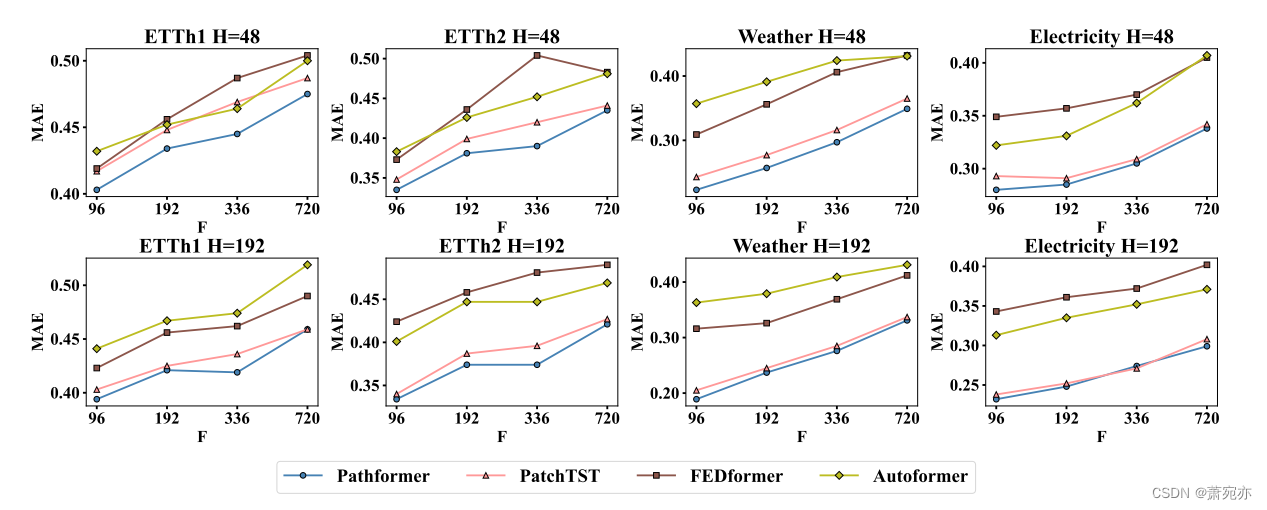
图5:ETTh1, ETTh2, Weather和Electricity不同输入长度的结果。
表7:多元时间序列预测结果。输入长度H = 48,预测长度F∈{96,192,336,720}。最好的结果以粗体突出显示。
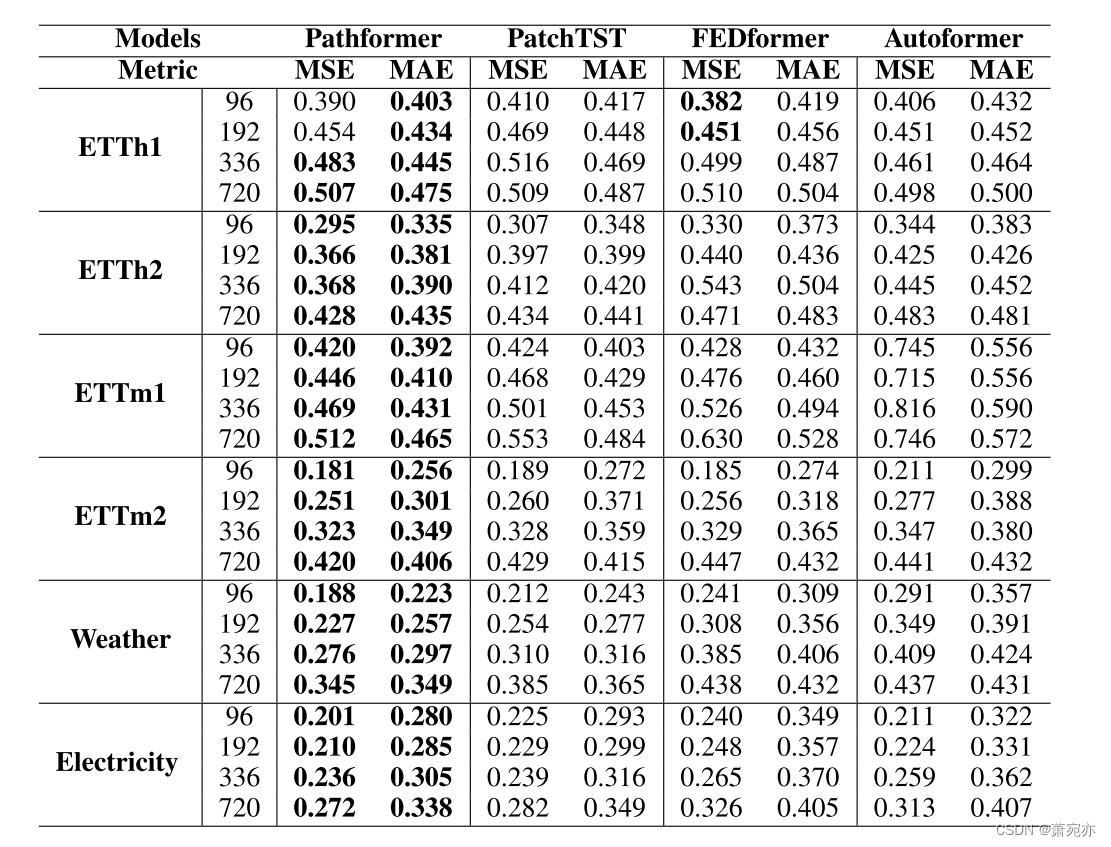
表8多元时间序列预测结果。输入长度H = 192,预测长度F∈{96,192,336,720}。最好的结果以粗体突出显示。
A.4 MORE COMPARISONS WITH SOME BASIC BASELINES
为了验证Pathformer的有效性,我们对一些最近表现良好的基本基线进行了广泛的实验:DLinear, NLinear和N-HiTS,使用长输入序列长度(H = 336)。如表9所示,对于输入长度336,我们提出的模型Pathformer优于这些基线。Zeng等人(2023)指出,以前的Transformer不能很好地从较长的输入序列中提取时间关系,而我们提出的Pathformer在较长的输入长度下表现更好,这表明考虑自适应多尺度建模是增强Transformer这种关系提取能力的有效方法。
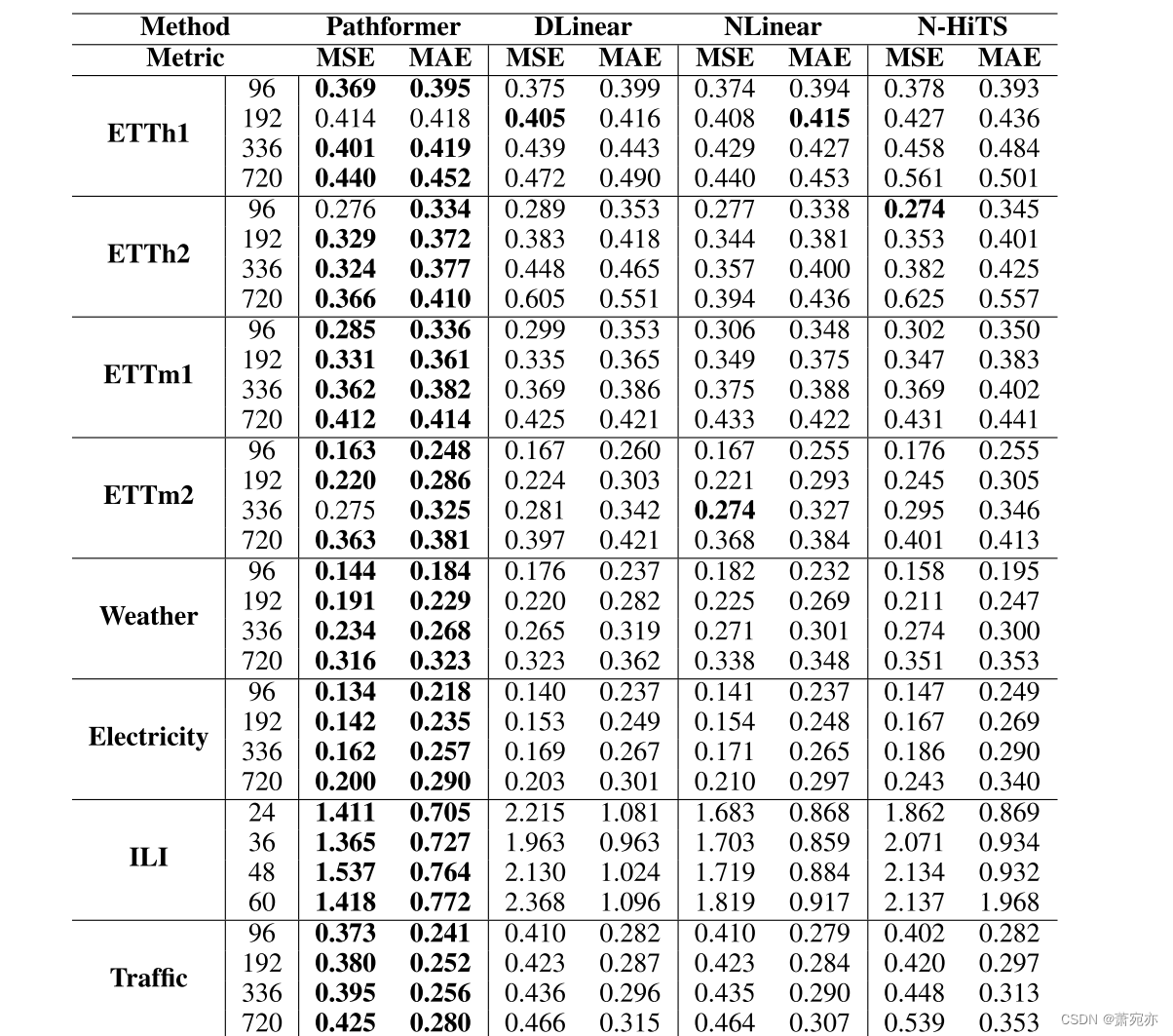
表9多变量时间序列预测结果。输入长度H = 336(对于ILI数据集H = 106),预测长度F∈{96,192,336,720}(对于ILI数据集F∈{24,36,48,60})。最好的结果以粗体突出显示。
A.5.1与PATCHTST的比较
PATCHTST将时间序列划分为多个补丁,经验证据表明,在时间序列预测中,补丁是提高模型性能的有效方法。我们提出的模型Pathformer扩展了补丁方法以整合多尺度建模。与PatchTST的主要区别在于:(1)多补丁大小分区:PatchTST采用单一补丁大小对时间序列进行分区,以单一分辨率获得特征。相比之下,Pathformer在每层使用多个不同的补丁大小进行分区。该方法从时间分辨率的角度捕捉多尺度特征。(2)补丁之间的全局相关性和每个补丁的局部细节:PatchTST在划分的补丁之间进行关注,忽略每个补丁的内部细节。相比之下,Pathformer不仅考虑补丁之间的相关性,还考虑每个补丁内的详细信息。引入双注意(补丁间注意和补丁内注意),整合全局相关性和局部细节,从时间距离的角度捕捉多尺度特征。(3)自适应多尺度建模:PatchTST对所有数据采用固定的patch大小,阻碍了对不同时间序列关键模式的把握。我们提出了自适应路径,根据单个样本的特征动态选择不同的补丁大小,从而实现自适应多尺度建模。
A.5.2与N-HITS的比较
N-HITS利用多尺度特征建模进行时间序列预测,但与Pathformer的不同之处在于:(1)N-HITS通过多速率数据采样和分层插值对不同分辨率的时间序列特征进行建模。Pathformer不仅考虑了不同分辨率的时间序列特征,而且从时间距离的角度进行了多尺度建模。同时考虑时间分辨率和时间距离使多尺度建模方法更加全面。(2) N-HiTS采用固定采样率进行多速率数据采样,缺乏基于时间序列样本差异的自适应多尺度建模能力。相比之下,Pathformer具有自适应多尺度建模能力。(3) N-HiTS采用线性结构构建模型框架,而Pathformer采用Transformer架构进行多尺度建模。
A.5.3与SCALEFORMER的比较
SCALEFORMER还利用多尺度特征建模进行时间序列预测。它与Pathformer的不同之处在于:(1)Scaleformer通过下采样获得不同时间分辨率的多尺度特征。相比之下,Pathformer不仅考虑不同分辨率的时间序列特征,而且从时间距离的角度进行建模,同时考虑全局相关性和局部细节。这为通过时间分辨率和时间距离进行多尺度建模提供了更全面的方法。(2) Scaleformer需要在不同时间分辨率下分配预测模型,导致模型复杂度高于Pathformer。(3) Scaleformer采用固定采样率,Pathformer具有基于时间序列样本差异的自适应多尺度建模能力。
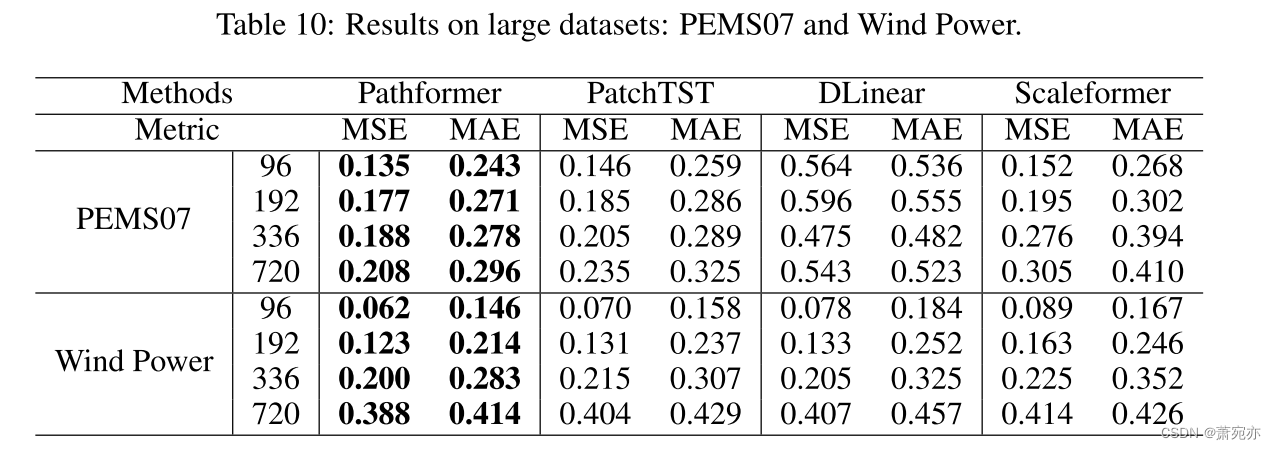
a .6在大数据集上的实验
目前的时间序列预测基准相对较小,并且存在模型的预测性能可能受到过拟合影响的担忧。为了解决这个问题,我们探索了更大的数据集来验证所提出模型的有效性。具体过程如下:我们从数据量和变量数量两个角度寻求更大的数据集。我们添加了两个数据集,风电数据集和PEMS07数据集,以评估Pathformer在更大数据集上的性能。Wind Power数据集包括7397147个时间戳,达到百万样本量,而PEMS07数据集包括883个变量。如表10所示,与一些最先进的方法(如PatchTST、DLinear和Scaleformer)相比,Pathformer在这些更大的数据集上展示了优越的预测性能。
A.7可视化
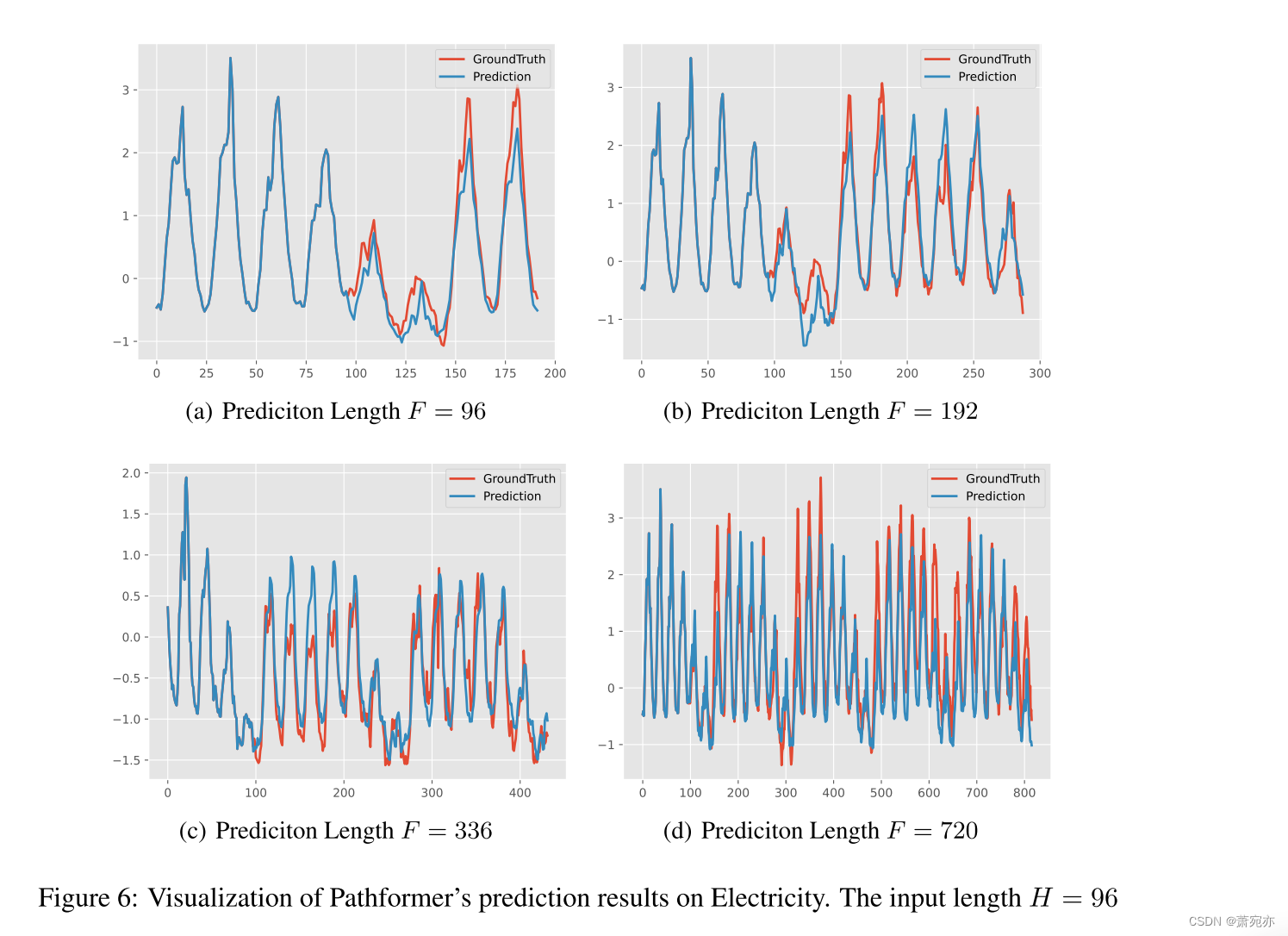
我们将Pathformer在Electricity数据集上的预测结果可视化。如图6所示,当预测长度F = 96、192、336、720时,预测曲线与Ground Truth曲线非常接近,表明Pathformer具有出色的预测性能。同时,Pathformer在捕获不同样本中存在的多周期和复杂趋势方面表现出有效性。这证明了其对多尺度特征的自适应建模能力。
与DCdetector的对比
在与Patch大小可以变化,双重注意力不同,有着自适应。















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











