







目录
从目前所学习到的东西来看,CNN在图像等领域主要有两大方面的应用,第一是图像的分类,第二是图像目标的检测。本文主要是做一个概述性的学习总结,每个网络的详细细节没具体阐述。
基于CNN图像分类算法
LeNet(1998)
由Yann LeCun发表的论文《Gradient based learning applied to document-recognition》,该网络主要由卷积层、池化层和全连接层构成,下图表示了其原理。
AlexNet(2012)
AlexNet是2012年ILSVRC(ImageNet Large Scale Visual Recognition Challenge)冠军, 由Hinton和他的学生Alex Krizhevsky设计,此后CNN开始走进人们的视野,下图所示为其网络结构。
其主要特点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256256的原始图像中截取224224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。

VGGNet
ILSVRC 2014的亚军,VGG网络作者尝试了多种结构,较常用的有VGG16和VGG19(VGG16网络更简单,性能也可以,应用最广泛)。
VGG16的基本架构为conv12 (64) -> pool1 -> conv22(128) -> pool2 -> conv33(256) -> pool3 -> conv43 (512) -> pool4 -> conv5*3 (512) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax。 *3代表重复3次。
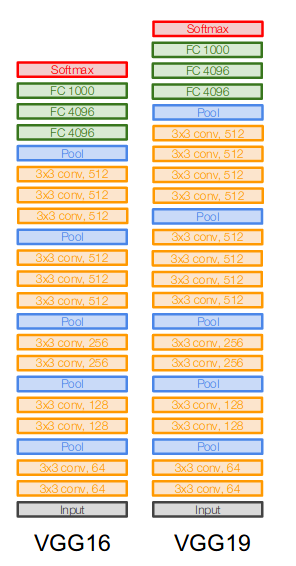
VGGNet特点:
- 结构简单,只有3x3,stride 1,pad 1的卷积和2x2,stride 2的max pooling,每过一次pooling,feature map大小降低一半。
- 参数量大
- 合适的网络初始化
- 使用batch normalization
- FC7提取的特征对其他任务有帮助。FC7始于AlexNet,表示某一全连接层,该层提取特征用于分类任务。
GoogLeNet
GoogLeNet是ILSVRC2014冠军,使用average pooling代替了最耗参数(相应的也最耗时间)的全连接层,同时使用inception模块来代替简单的卷积层(inception的名字来源于盗梦空间中的we need to go deeper的梗);另外,使用1x1的卷积进行了降维。
ResNet
ResNet是ILSVRC 2015的冠军。ResNet最大的贡献在于解决了深层网络难以训练的问题(反向传播梯度弥散),它的网络深度达到了152层!

ResNet的特点:
- 使用BN(Batch Normalization)layer在每个conv layer后
- 每个residual block包含两个3x3 conv layer
- 周期性的使用stride 2 pooling降低维度,相当于除2
- 最耗时的FC层使用pool代替
- SGD + Momentum 0.9
- learning rate 0.1, divided by 10 when validation error plateaus
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3020
3020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









