







摘要
尽管深度学习取得了成功,但它仍然需要大量的标记数据集才能成功。数据增强在缓解对更多标记数据的需求方面显示出很大的前景。
"无监督数据增强 "或 "UDA"在半监督学习环境下将数据增强应用于无标签数据,鼓励模型在无标签的例子和增强的无标签的例子之间保持预测一致。
通过用先进的数据增强方法(如RandAugment和回译)取代简单的噪声操作,我们的方法在相同的一致性训练框架下为六种语言和三种视觉任务带来了实质性的改进。我们的工作在迁移学习中也可以很好的工作。
1. Introduction
我们的贡献,将在本文的其余部分介绍,具体如下。
- 在监督学习中最先进的数据增量也可以作为一致性执行的半监督框架下的优秀噪声源。见表1和表2的结果。
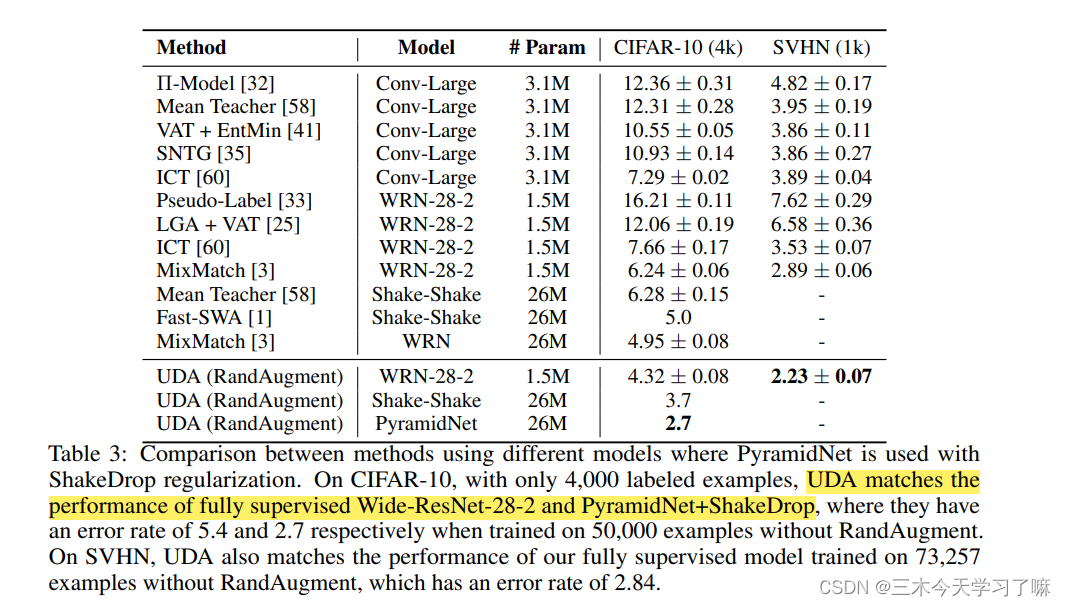
- UDA可以匹配甚至超过使用数量级更多的标记数据的纯监督学习。见表4和图4的结果。表3和表4中报告了视觉和语言任务的最先进结果。
- UDA与迁移学习结合得很好,例如,在从BERT进行微调时(见表4),并且在高数据量下是有效的,例如在ImageNet上(见表5)。
- 对UDA如何提高分类性能和最先进的增强技术的相应作用进行了理论分析。
2. Unsupervised Data Augmentation (UDA)
参数表示:

2.1 Background: Supervised Data Augmentation
数据增强的目的是通过对数据的输入进行转换,在不改变数据的标签的情况下,创造出新颖和真实的训练数据。
尽管取得了可喜的成果,但数据增强大多被认为是 “蛋糕上的樱桃”,它提供了稳定但有限的性能提升,因为迄今为止,这些增强只被应用于通常较小的标记实例集。
2.2 Unsupervised Data Augmentation
为了同时使用有标签的例子和无标签的例子,我们将有标签的例子上的交叉熵损失和方程2中定义的无监督目标加上一个加权因子作为我们的训练目标,如图1所示。
与传统的扰动相比,如高斯噪声、dropout噪声或仿生变换,我们认为针对每个任务的数据增强可以作为一个更有效的 "噪声 "来源。具体来说,使用有针对性的数据增强作为扰动功能有几个优点。
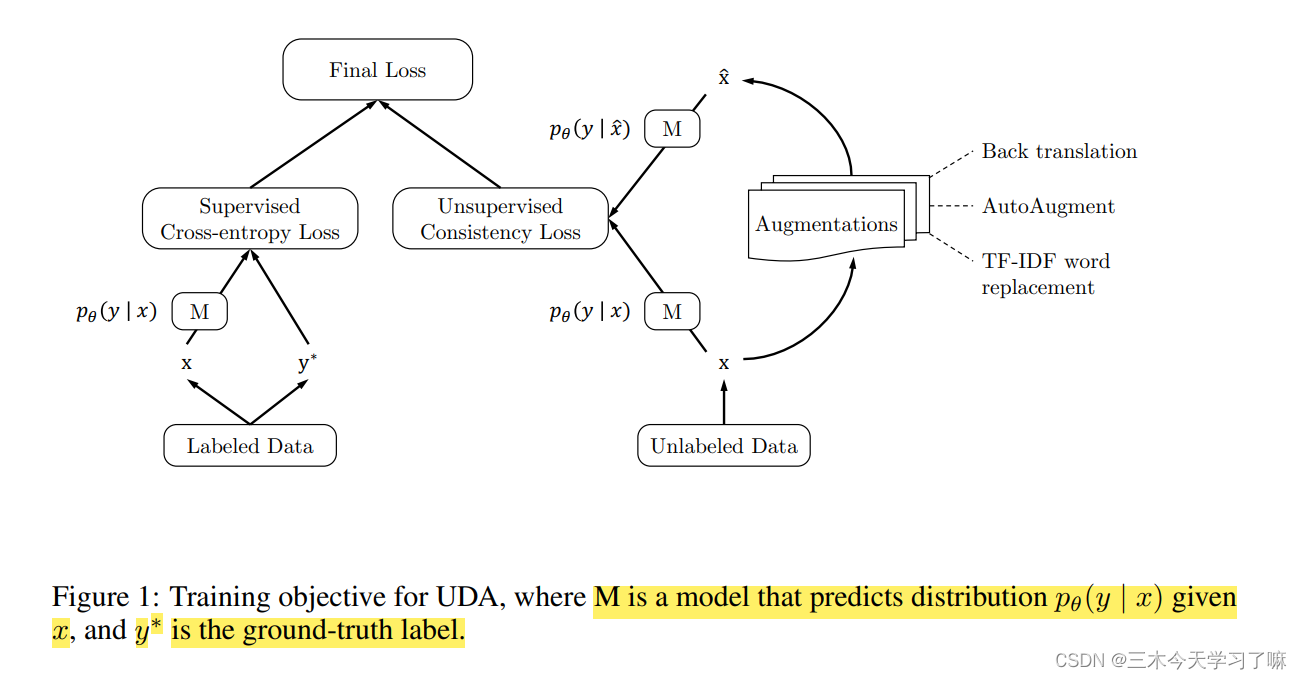
大话-数据增强-UDA理论篇这篇文章给上图一个完美的解释。
从上图的 Final Loss(最终损失函数) 可以看出来,其由两部分组成(Supervised Cross-entropy Loss 和 Unsupervised Consistency Loss)。
Supervised Cross-entropy Loss 是有监督交叉熵损失
Unsupervised Consistency Loss 是无监督一致性损失
当与标记的例子联合训练时,我们利用一个加权因子λ来平衡监督的交叉熵和无监督的一致性训练损失,这在图1中得到说明。
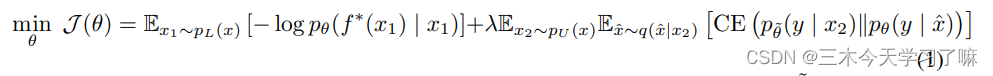
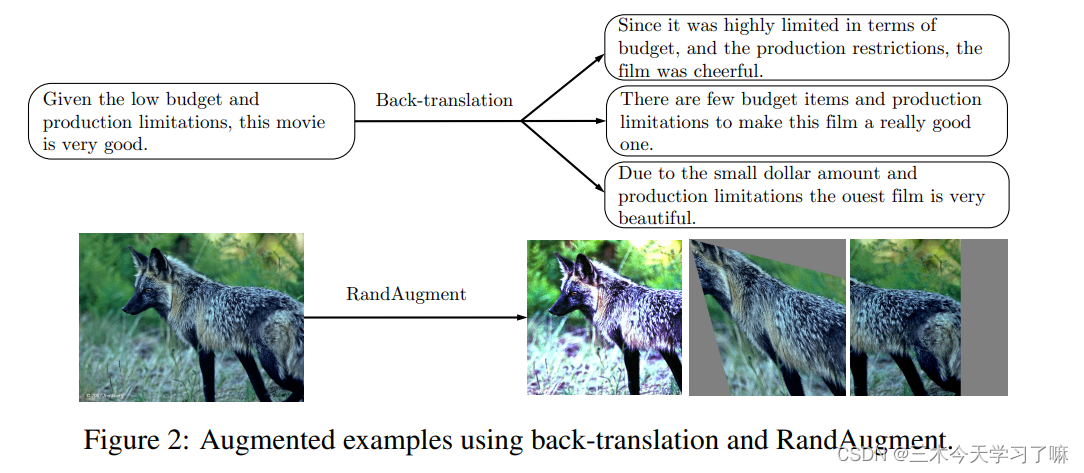
2.3 Augmentation Strategies for Different Tasks
- 用于图像分类的RandAugment
- 文本分类的逆向翻译
- 用TF-IDF进行文本分类的单词替换
2.4 Additional Training Techniques
第二部分Unsupervised Consistency Loss采用如下公式:
(1)一致性损失项只对分类类别中最高概率大于阈值β的例子进行计算。
(2)Sharpening Predictions,采用一个低softmax温度控制参数τ。我们实验中采用0.4.
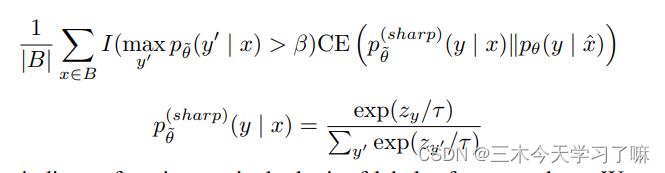
3. Theoretical Analysis

(1)数据增强丰富了(覆盖了)子类别的各种情况,如下面c图。(2)子类列中的数据是可以通过各种转换操作进行互相转换的,所以UDA只需要很少的标注样本即可
4. Experiments
4.1 Correlation between Supervised and Semi-supervised Performances

表1和表2显示了监督和半监督设置之间的增强效果的强烈相关性。这验证了我们的想法,即在监督学习中发现的更强大的数据增强,在应用于半监督学习设置时,总是可以带来更多的收益。
4.2 Algorithm Comparison on Vision Semi-supervised Learning Benchmarks
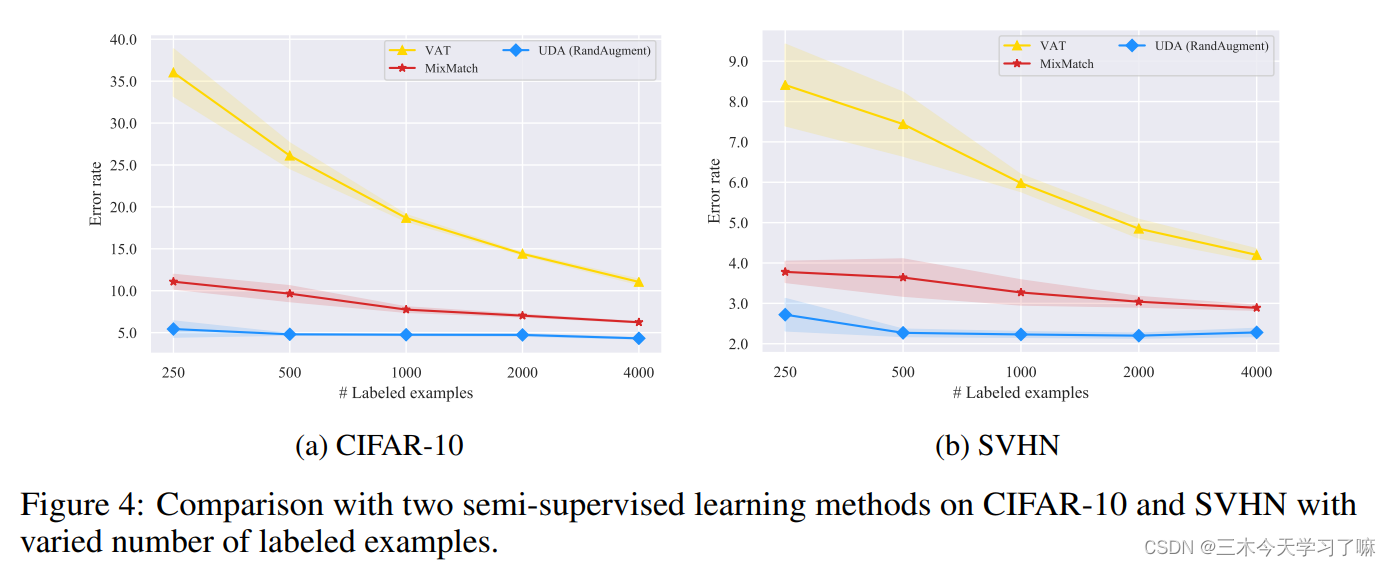
在不同规模的标记数据下,UDA始终优于两个基线。而数据增强大多产生多样化和真实的图像
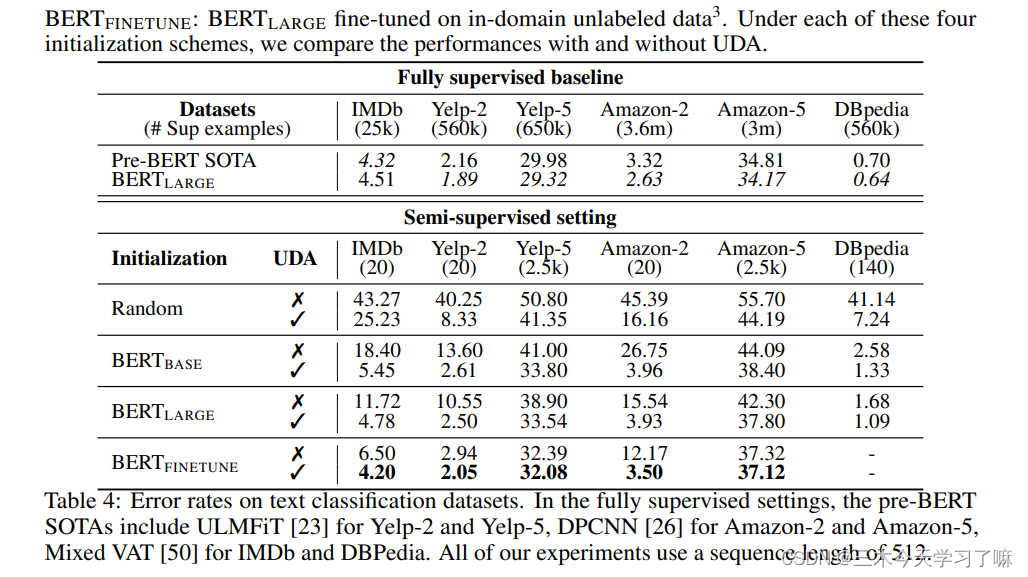
UDA是对迁移学习/表示学习的补充。我们可以看到,当用BERT初始化并在域内数据上进一步微调时,UDA仍然可以在IMDb上将错误率从6.50大幅降低到4.20
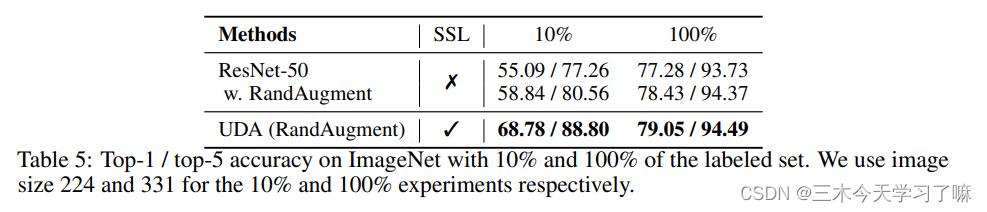
为了评估UDA是否可以扩展到大规模和高难度的问题,我们现在转向以ResNet-50为基础架构的ImageNet数据集。具体来说,我们考虑两种不同性质的实验设置。
- 使用ImageNet中10%的监督数据,而将所有其他数据作为无标签数据。因此,未标记的示例完全是域内的。
- 在第二种情况下,我们将ImageNet中的所有图像作为监督数据。















 4503
4503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









