







1. 【2022CoRL MIT&GOOGLE】MIRA: Mental Imagery for Robotic Affordances
动机
人类能够形成3D场景的心理图像,以支持反事实想象、规划和运动控制。
解决方案
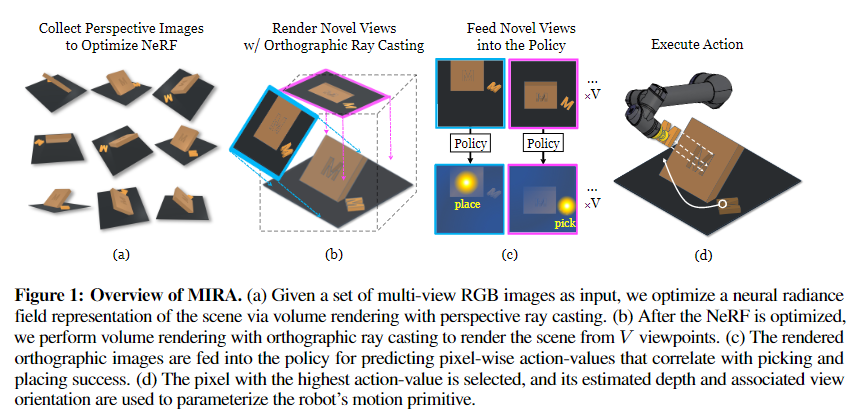
给定一组2D RGB图像,MIRA用nerf构建一致的3D场景表示,通过该表示合成新的正交视图,适用于像素级可承受性预测以优化动作。
使用 NeRF 作为场景表示来执行新颖的视图合成以实现精确的对象重新排列。【网络输入是RGB】
所以,核心是使用nerf【instant-NGP】来合成新的视角,有利于机器人操作的视角,来完成任务。
- MIRA使用神经辐射场(NeRF)作为机器人的“心灵之眼”,以想象场景的外观。
- 结合可承受性模型,预测从任何给定视图的场景中当前可执行的动作。
- 机器人在想象中搜索最佳可承受性的动作对应的心理图像,然后执行与该心理图像相对应的动作。

缺点
MIRA目前需要为每个操纵步骤训练一个场景的NeRF,这在实时视觉-运动控制任务中可能面临挑战。【泛化性很差】
作者提出了使用多个摄像头观察场景或学习即时NGP的先验以大幅减少运行时间的可能性。
2. 【CoRL 2022 (oral)】Instruction-driven history-aware policies for robotic manipulations
输入的表征是RGB-D。
动机
- 一个重要的挑战是序列任务需要跟踪可能从当前观察中隐藏的对象状态,或者记住之前执行的动作。这种行为难以用主要依赖当前观察的方法来建模。
- 另一个挑战是操作任务,这些任务需要精确控制机器人末端执行器以达到目标位置。这类任务在单视图方法中难以解决,特别是在视觉遮挡和不同大小的物体存在的情况下。
解决方案
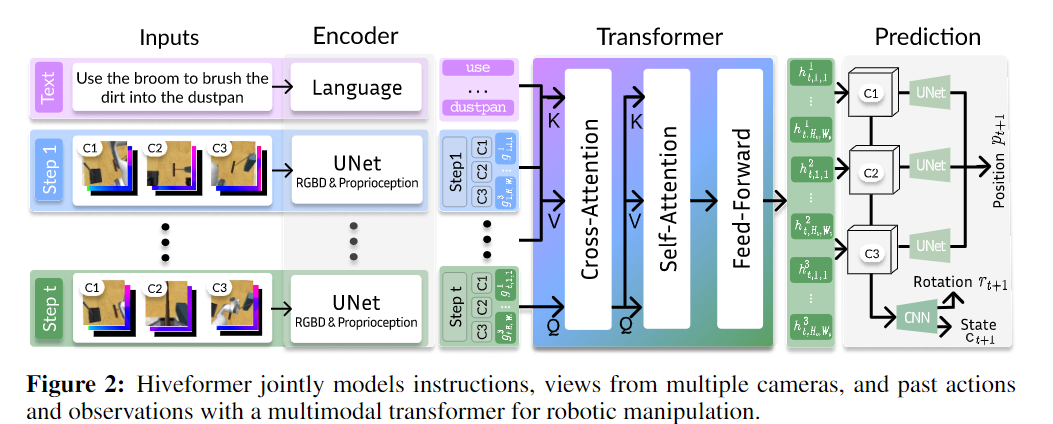
论文提出了一种Transformer架构,该架构能够整合自然语言指令、多视角场景观察以及观察和动作的完整历史记录。
Hiveformer——一个历史感知的指令条件多视图Transformer。它将指令转换为语言标记,并结合了过去和当前的视觉观察以及自我感知的标记。这些标记被连接并输入到多模态Transformer中,该Transformer联合建模当前和过去观察之间的依赖关系、多摄像机视图之间的空间关系,以及视觉和指令之间的精细交叉模态对齐。基于多模态Transformer的输出表示,使用UNet解码器预测7自由度动作,即位置、旋转和夹持器的状态。
使用交叉注意力层学习当前观察与指令和历史记录的跨模态关系。
使用自注意力层学习来自多个相机视图的补丁标记之间的内部关系。
通过前馈网络进一步处理这些关系。
缺点
由于 Transformer,计算成本随输入序列长度二次增加。此外,我们的模型使用行为克隆进行训练,可能会受到暴露偏差的影响。未来的研究可以使用分层模型提高长期任务的效率,并结合强化学习。此外,我们的模型仅针对合成指令进行训练,在人工编写的指令上表现较差。对人工编写的自动生成指令进行训练可以帮助提高性能

3. 【CoRL 2023】PolarNet: 3D Point Clouds for Language-Guided Robotic Manipulation
动机
让机器人能够理解并执行基于自然语言指令的操作任务是机器人技术的长期目标。
语言引导操作的主要方法使用 2D 图像表示,这在组合多视角摄像机和推断精确的 3D 位置和关系方面面临困难
好的relate work写法
Most existing work on language-guided robotic manipulation uses 2D image representations [1, 2, 3, 4]. BC-Z [1] applies ResNet [5] to encode a single-view image for action prediction. Hiveformer [3] employs transformers [6] to jointly encode multi-view images and all the history. Recent advances in vision and language learning [7, 8] have further paved the way in image-based manipulation [4]. CLIPort [4] and InstructRL [9] take advantage of pretrained vision-and-language models [8, 10] to improve generalization in multi-task manipulation. GATO [11] and PALM-E [12] jointly train robotic tasks with massive web image-text data for better representation and task reasoning.
Although 2D image-based policies have achieved promising results, they have inherent limitations for manipulation in the 3D world. First, they do not take full advantage of multi-view cameras for visual occlusion reasoning, as multi-view images are not explicitly aligned with each other, as shown in Figure 1. Second, accurately inferring the precise 3D positions and spatial relations [13] from 2D images is a significant challenge. Current 2D approaches mainly rely on extensive pretraining and sufficient in-domain data to achieve satisfactory performance.
尽管基于 2D 图像的策略取得了令人鼓舞的成果,但它们在 3D 世界中的操作存在固有的局限性。
为了克服基于2D的操控策略学习的限制,近期的研究已经转向基于3D的方法。使用3D表示提供了一种自然的方式来融合多视图观察,并促进更精确的3D定位。例如,PerAct采用了一种以动作为中心的方法,它采用超过100万个体素的高维输入来分类下一个活跃的体素,为多任务语言引导的操控取得了最先进的结果。然而,这种以动作为中心的3D体素存在量化误差和计算效率低下的问题。以点云形式的替代3D表示已经成功地用于3D对象检测、分割和定位。然而,对于机器人操控来说,3D点云的有效和高效处理仍然未被充分探索。此外,现有的工作主要集中在单一任务操控上,缺乏同时整合语言指令以完成多项任务的多功能性。
解决方案
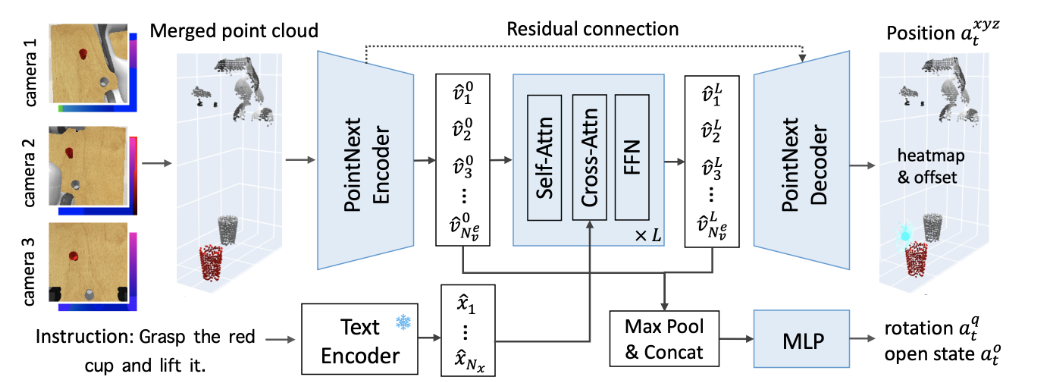
所提出的 PolarNet 采用精心设计的点云输入、高效的点云编码器和多模态转换器来预测语言条件操作的 7-DoF 动作。我们发现将点颜色与颜色一起使用、过滤不相关的点以及合并多个视图至关重要。
缺点
- 【多任务学习方法】我们的多任务模型仍然不如最好的单任务模型,需要更先进的多任务学习算法。
- 【泛化性不够】此外,虽然我们的策略可以执行多项任务,但我们还没有研究对新场景、对象和任务的泛化。
4. 【corl2022】PERCEIVER-ACTOR: A Multi-Task Transformer for Robotic Manipulation
https://kimi.moonshot.cn/share/cpcip8e0atp5gutos860
Additional Related Work
附录I
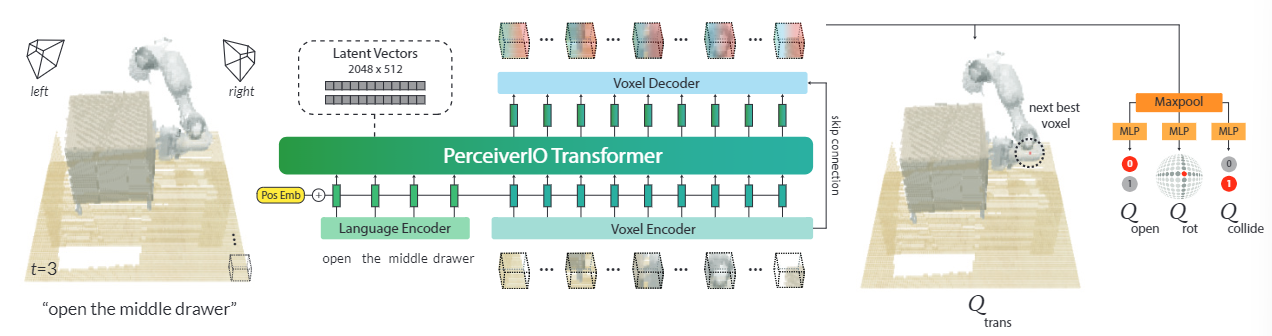
Voxel-based representations have been used in several domains that specifically benefit from 3D understanding. Like in object detection [91, 92], object search [93], and vision-language grounding [94, 95], voxel maps have been used to build persistent scene representations [96]. In Neural Radiance Fields (NeRFs), voxel feature grids have dramatically reduced training and rendering times [97, 98]. Similarly, other works in robotics have used voxelized representations to embed viewpoint-invariance for driving [99] and manipulation [100]. The use of latent vectors in Perceiver [1] is broadly related to voxel hashing [101] from computer graphics. Instead of using a location-based hashing function to map voxels to fixed size memory, PerceiverIO uses cross attention to map the input to fixed size latent vectors, which are trained end-to-end. Another major difference is the treatment of unoccupied space. In graphics, unoccupied space does not affect rendering, but in PERACT, unoccupied space is where a lot of “action detections” happen. Thus the relationship between unoccupied and occupied space, i.e., scene, objects, robot, is crucial for learning action representations.

缺点
在附录L中讲了很多:
- Generlization to Novel Instances and Objects.
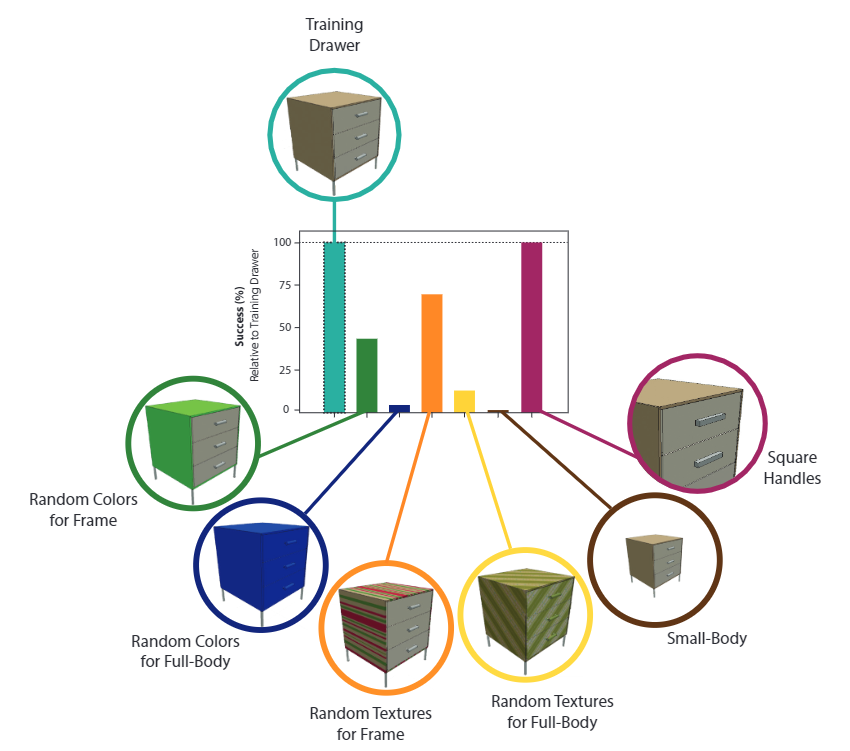
5. 【CoRL 2023 (Oral)】RVT: Robotic View Transformer for 3D Object Manipulation
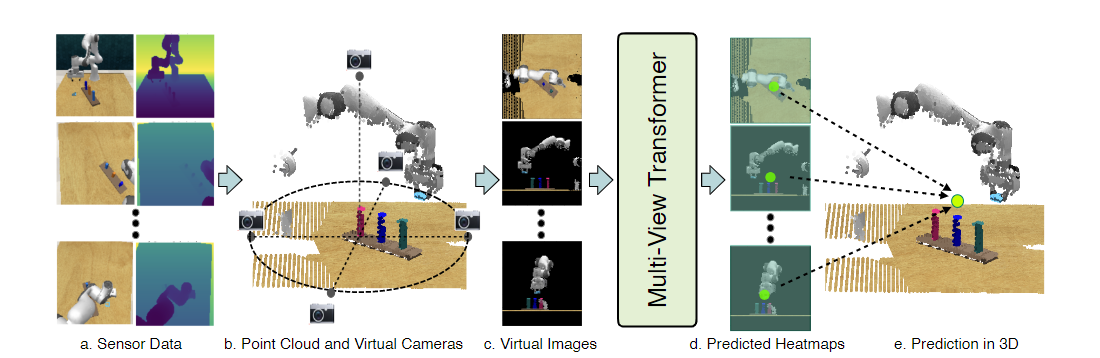
输入:RGB-D
动机
基于视图的方法直接处理单个或多个相机的图像,并在拾取放置和物体重新排列任务上取得了显著的成功。然而,这些基于视图的方法在需要3D推理的任务上成功有限
但是,创建和推理体素的成本比基于图像的推理更高,因为体素的数量随着分辨率的增加而呈立方比例增加,而图像像素则呈平方比例增加。这使得基于体素的方法在可扩展性方面不如基于视图的方法。
我们能否构建一个既能表现良好又继承基于视图方法的可扩展性的操纵网络?
解决方案
- 与以前的基于视图的方法不同,作者们通过从虚拟视图重新渲染图像,将相机图像与输入到变换器的图像解耦。这允许他们控制渲染过程,并带来几个好处。例如,他们可以从对任务有用的视点重新渲染(例如,直接在桌子上方),而不受现实世界物理约束的限制。此外,由于RVT的多视图输入是通过重新渲染获得的,即使在现实世界实验中,也可以使用单个传感器相机
缺点
- 视图选择:尽管作者们探索了不同的视图选项并找到了一个适用于多个任务的配置,但未来的研究可以进一步优化视图的选择过程,甚至从数据中学习视图选择。
- 相机到机器人基座的外参校准:与之前的基于视图的方法以及显式的体素基方法(如PerAct和C2F-ARM)相比,RVT需要校准相机到机器人基座的外参。未来的工作可以探索消除这一要求的扩展。
- 现实世界应用:尽管RVT在模拟环境中表现出色,但在现实世界的应用可能面临不同的挑战,如传感器噪声和复杂环境因素。进一步的研究可以集中在提高模型在现实世界条件下的鲁棒性。
6. 【2024Baidu】 VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
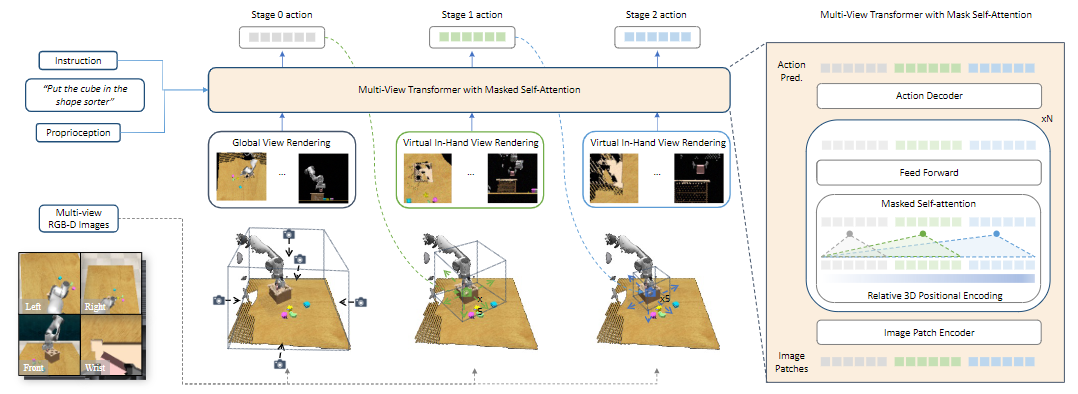
基于二维图像的操作
动机
现有方法通常均匀地处理三维工作空间,忽略了末端执行器附近的空间对于操作任务自然发生的归纳偏差的重要性。以前的研究强调了在手视角的价值:例如,有研究表明在手视图揭示了更多与任务相关的细节,这对于高精度任务特别有利。同样,有研究表明,结合在手视图可以减少与夹持器动作无关的干扰,从而提高泛化能力。
7. Act3D: 3D Feature Field Transformers for Multi-Task Robotic Manipulation
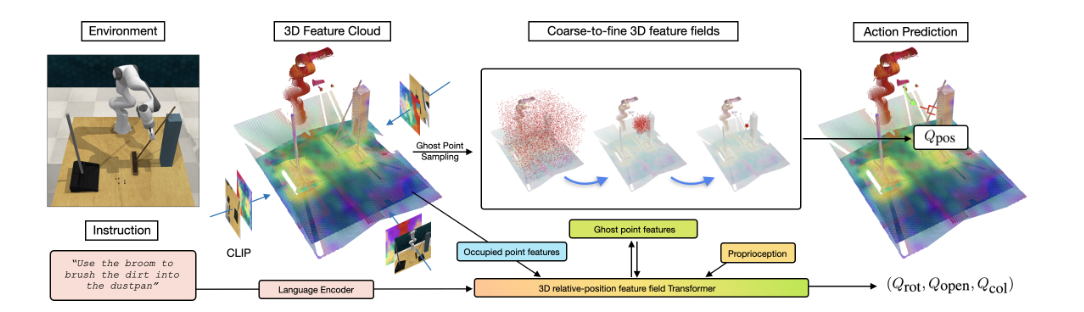
输入:点云
解决方案
Act3D是一个策略变换器,它在给定时间步长t时,根据一个或多个RGB-D图像、语言指令以及有关机器人当前末端执行器姿态的本体感知信息,预测6-DoF末端执行器姿态。模型的核心思想是通过迭代的粗到细3D点采样和特征化来估计高分辨率的3D动作图,从而学习自由空间的3D感知表示。
缺点
Act3D [8] 利用点云进行 3D 表示,但在计算上也受到大量采样点的影响,并且忽略了操作任务中空间偏差的潜在优势。















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









