







爬虫之scrapy框架--爬取读书网(基本步骤)
CrawlSpider——继承自scrapy.Spider
CrawlSpider可以定义规则,在解析HTML内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求,意思就是爬取网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的——不懂就往下看就行。
scrapy.linkextractors. LinkExtractor()
常用三个链接提取方法
allow=() #正则表达式,提取符合正则的链接
restrict_xpaths=() #xpath
restrict_css=() #css
链接提取器使用
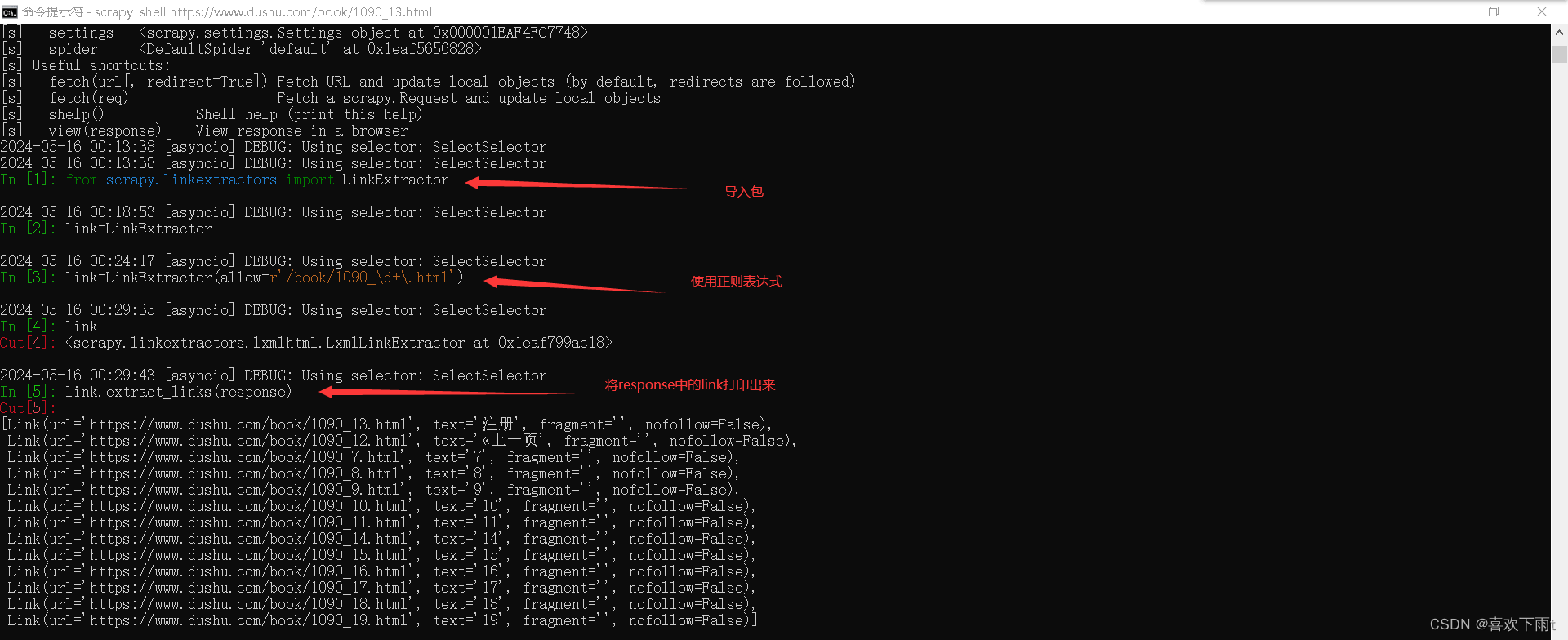
(1)使用正则表达式
from scrapy.linkextractors import LinkExtractor
link=LinkExtractor(allow=r'/book/1090_\d+\.html')
link.extract_links(response)
(2)使用xpath表达式
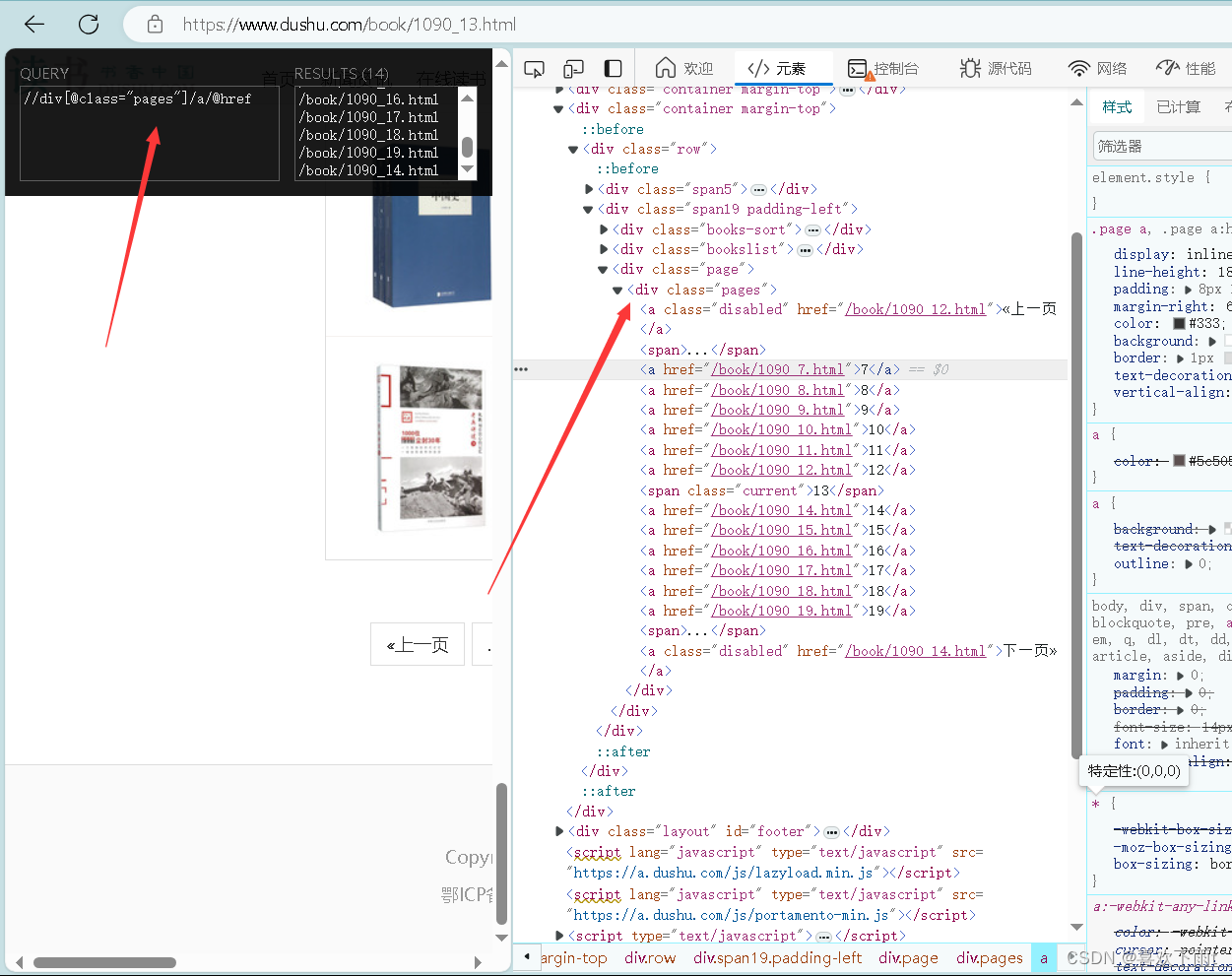
刚才导入了包现在不用导入了
link_1=LinkExtractor(restrict_xpaths=r'//div[@class="pages"]/a/@href')

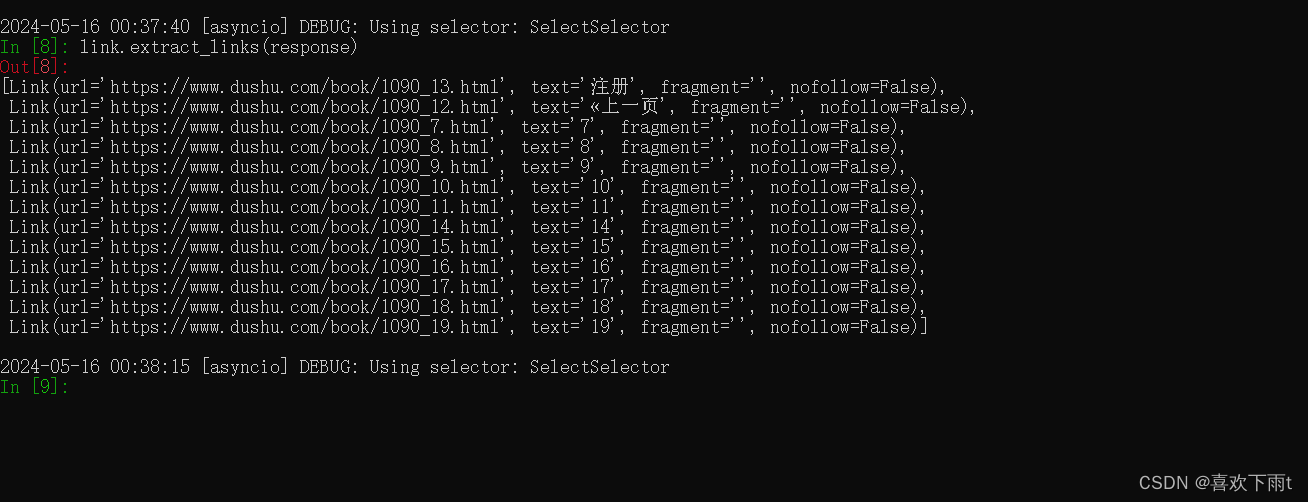
将返回的response中的链接打印出来
link.extract_links(response)
CrawlSpider 爬虫编写
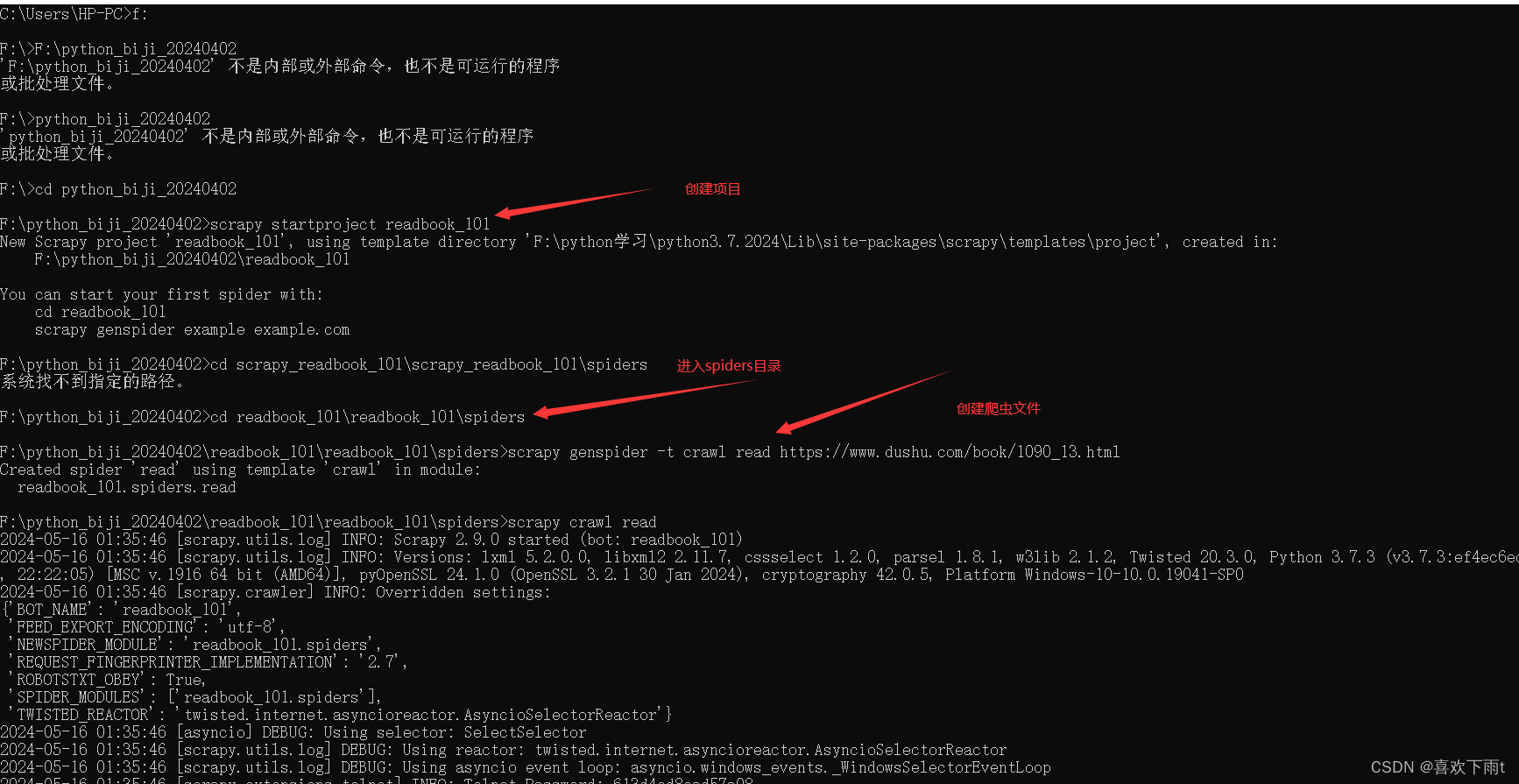
(1)创建项目
scrapy startproject readbook_101
(2)跳转到spider目录
cd readbook_101\readbook_101\spiders
(3)创建爬虫文件
scrapy genspider -t crawl read https://www.dushu.com/book/1090_13.html
效果如图:
(4)编写正则表达式规则——提取符合的链接
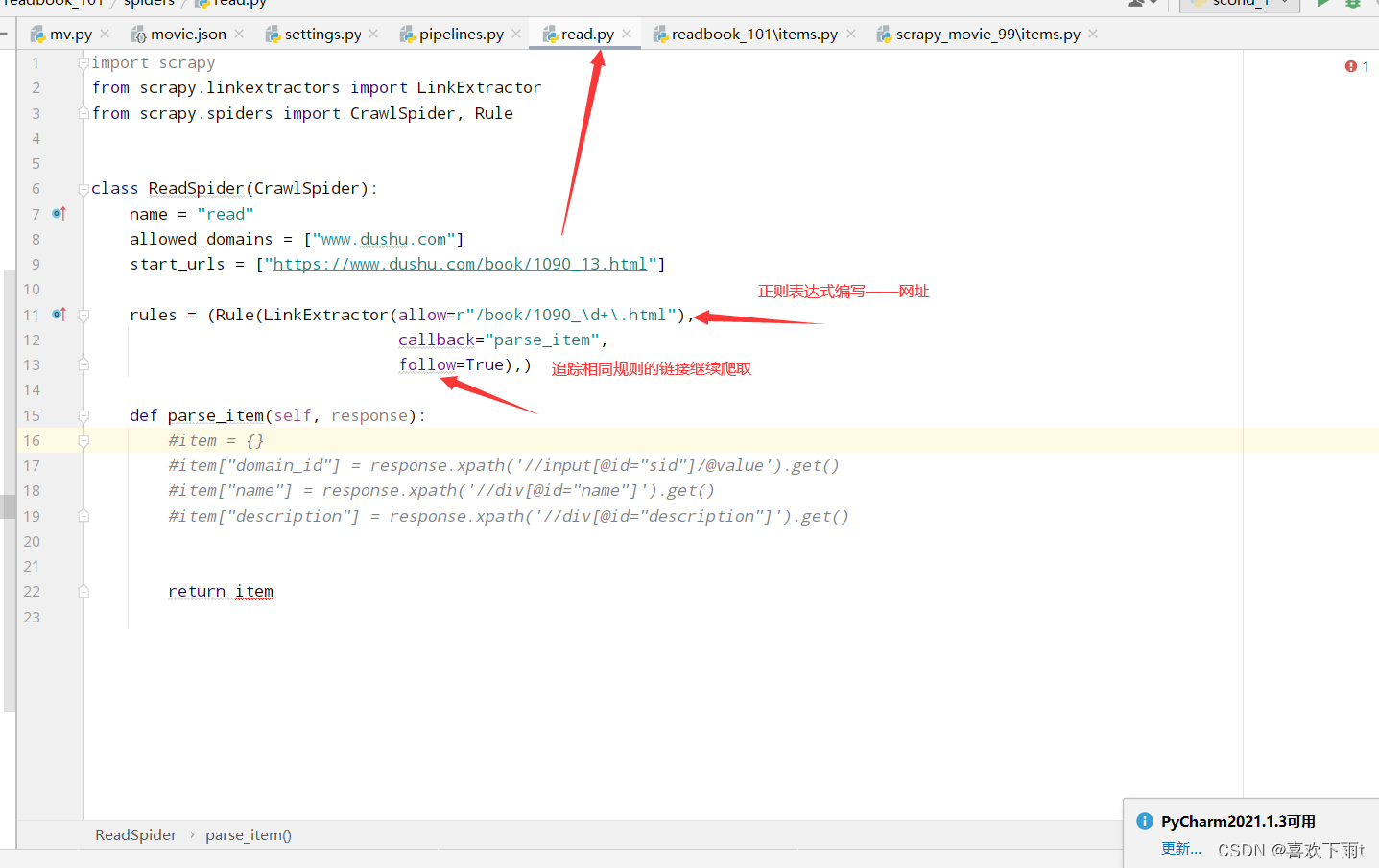
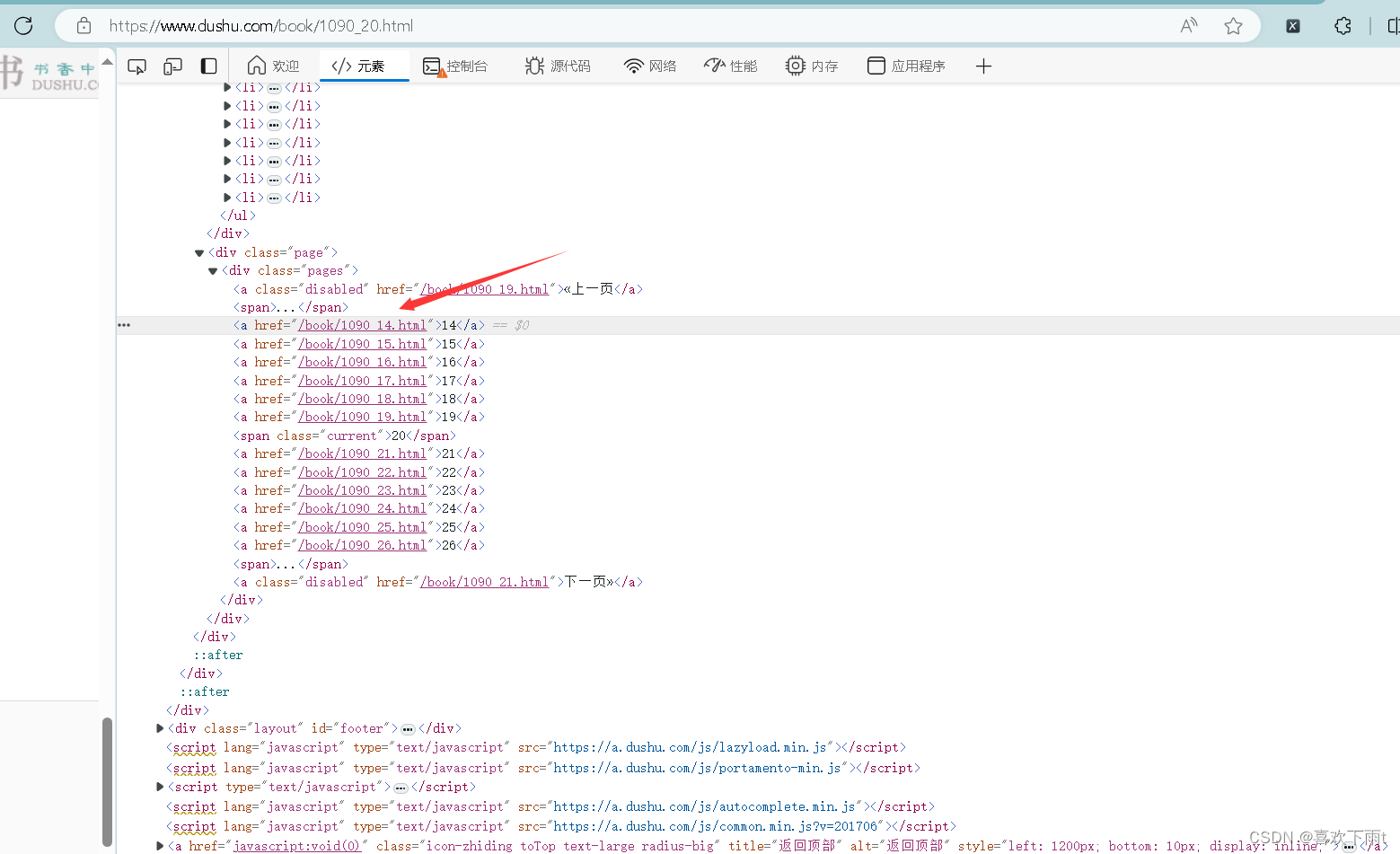
从此图中可以观察到规则:
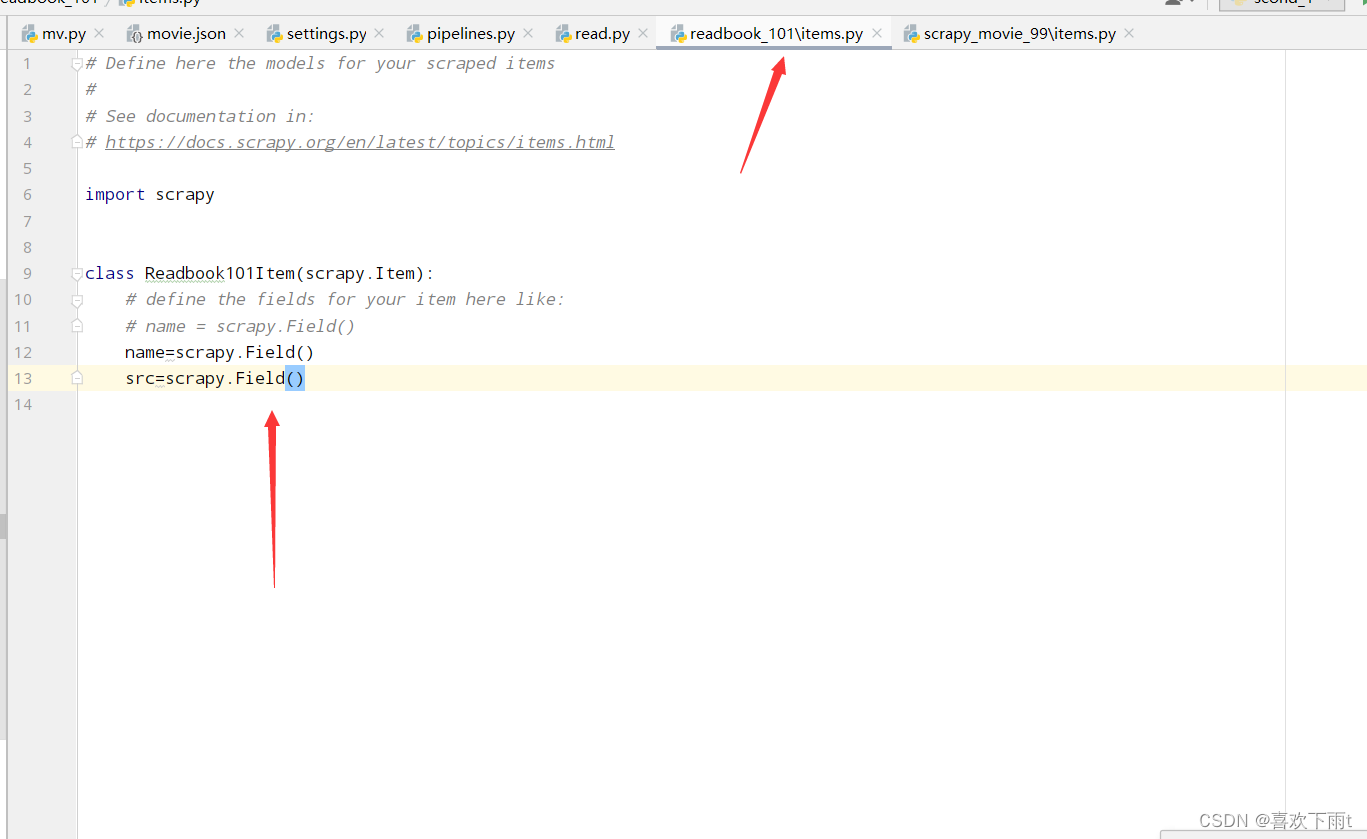
(5)定义数据结构
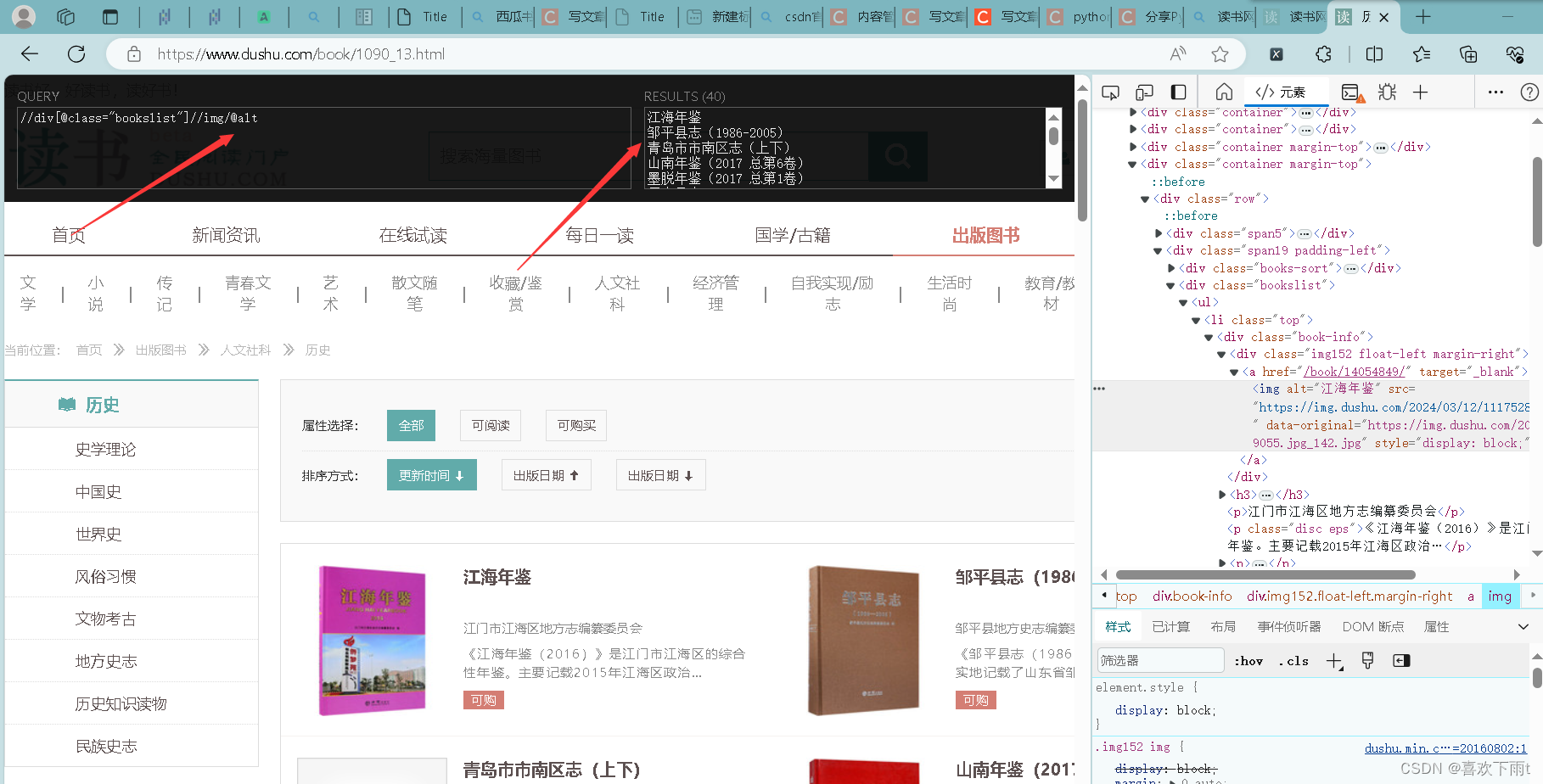
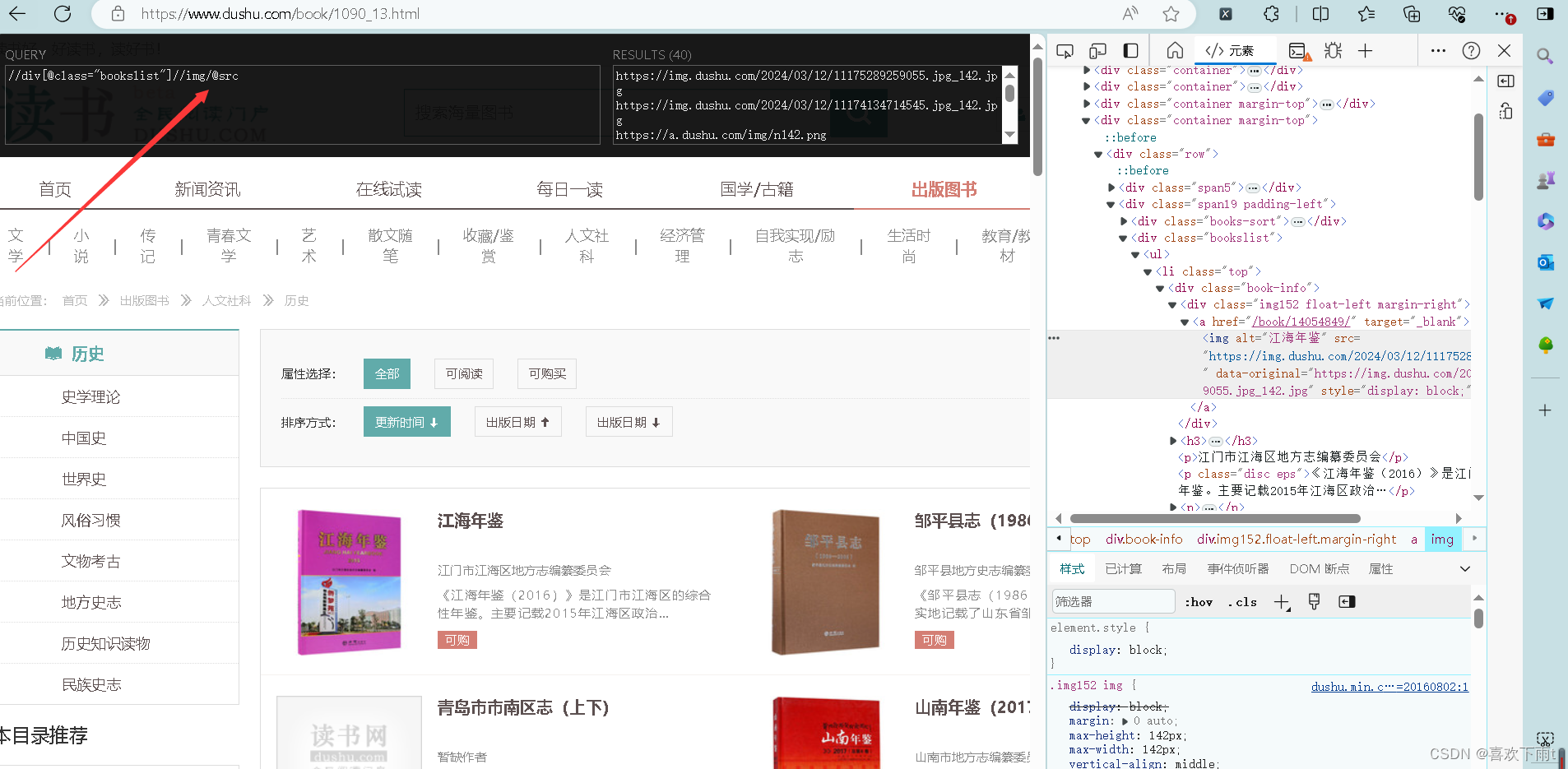
(6)根据网页分析出xpath——name和src
(7)编写爬虫函数

代码如下:
def parse_item(self, response):
#item = {}
#item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
#item["name"] = response.xpath('//div[@id="name"]').get()
#item["description"] = response.xpath('//div[@id="description"]').get()
#根xpath
img_list=response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
src=img.xpath('./@data-original').extract_first()
name=img.xpath('./@alt').extract_first()
#记得导入自定义数据结构
book=Readbook101Item(name=name,src=src)
#yield就相当于返回值,并交给管道
yield book
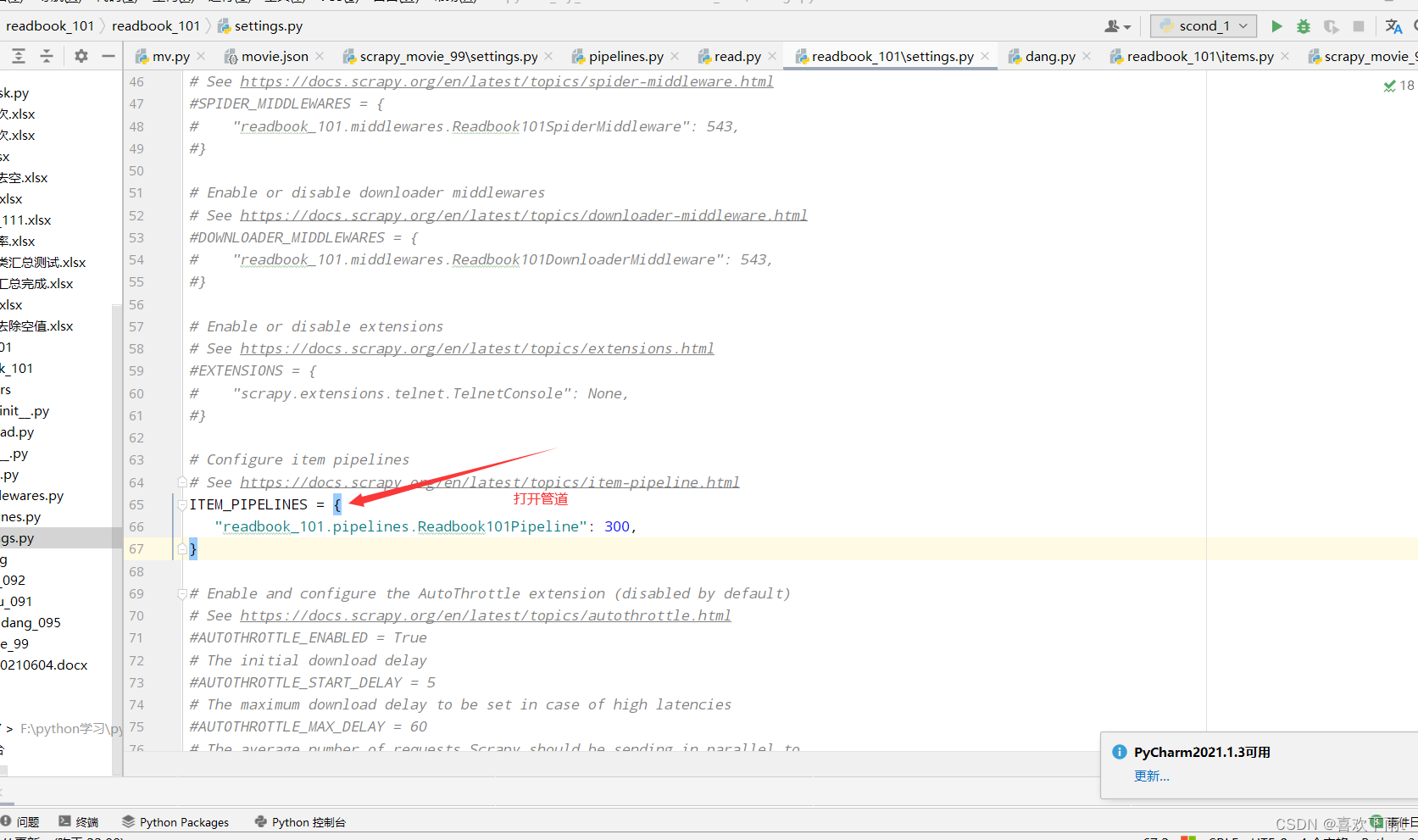
(8)打开管道
(9)管道函数编写——保存为json数据
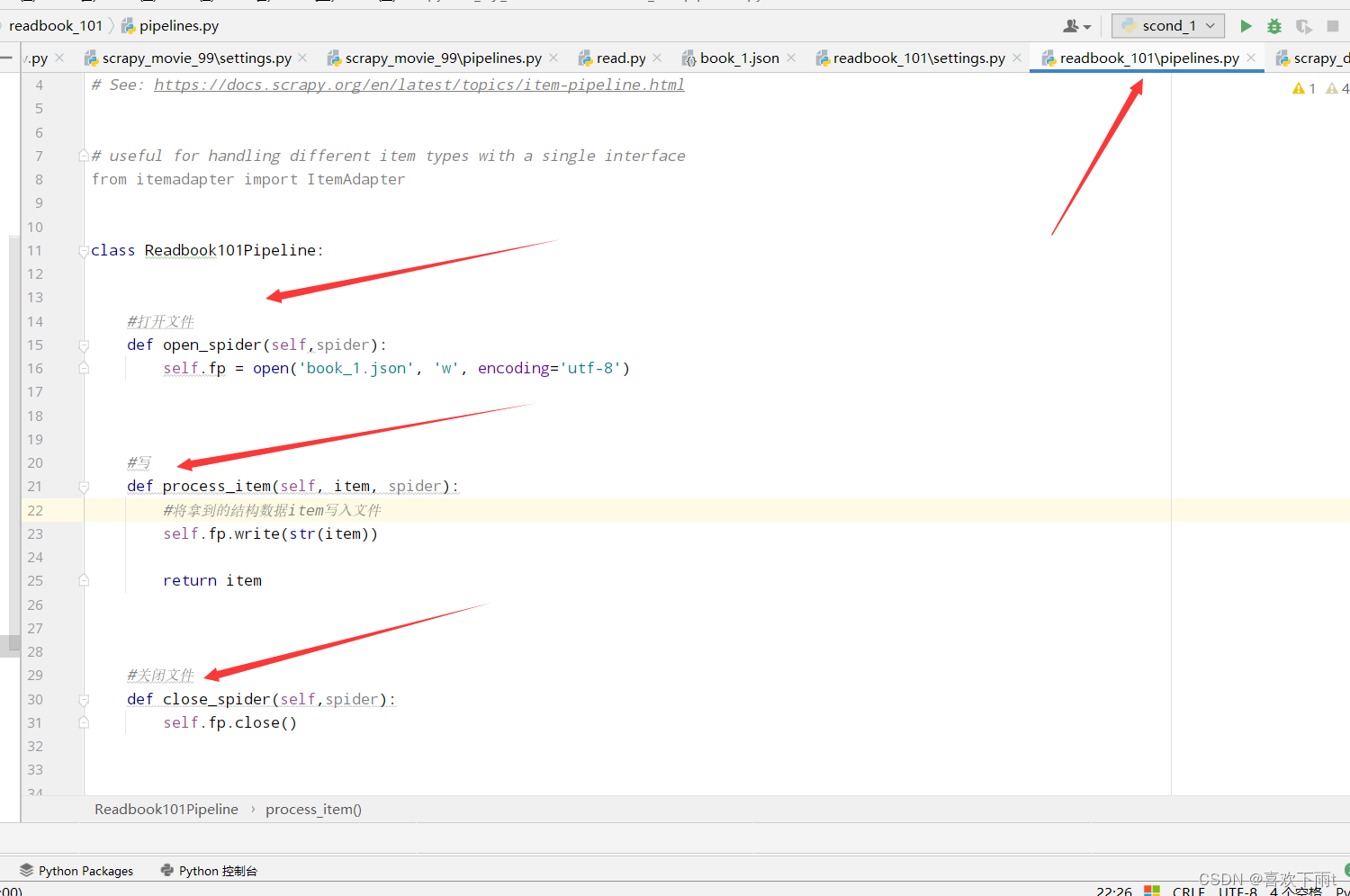
代码如下:
class Readbook101Pipeline:
#打开文件
def open_spider(self,spider):
self.fp = open('book_1.json', 'w', encoding='utf-8')
#写
def process_item(self, item, spider):
#将拿到的结构数据item写入文件
self.fp.write(str(item))
return item
#关闭文件
def close_spider(self,spider):
self.fp.close()
(10)注意事项——小坑
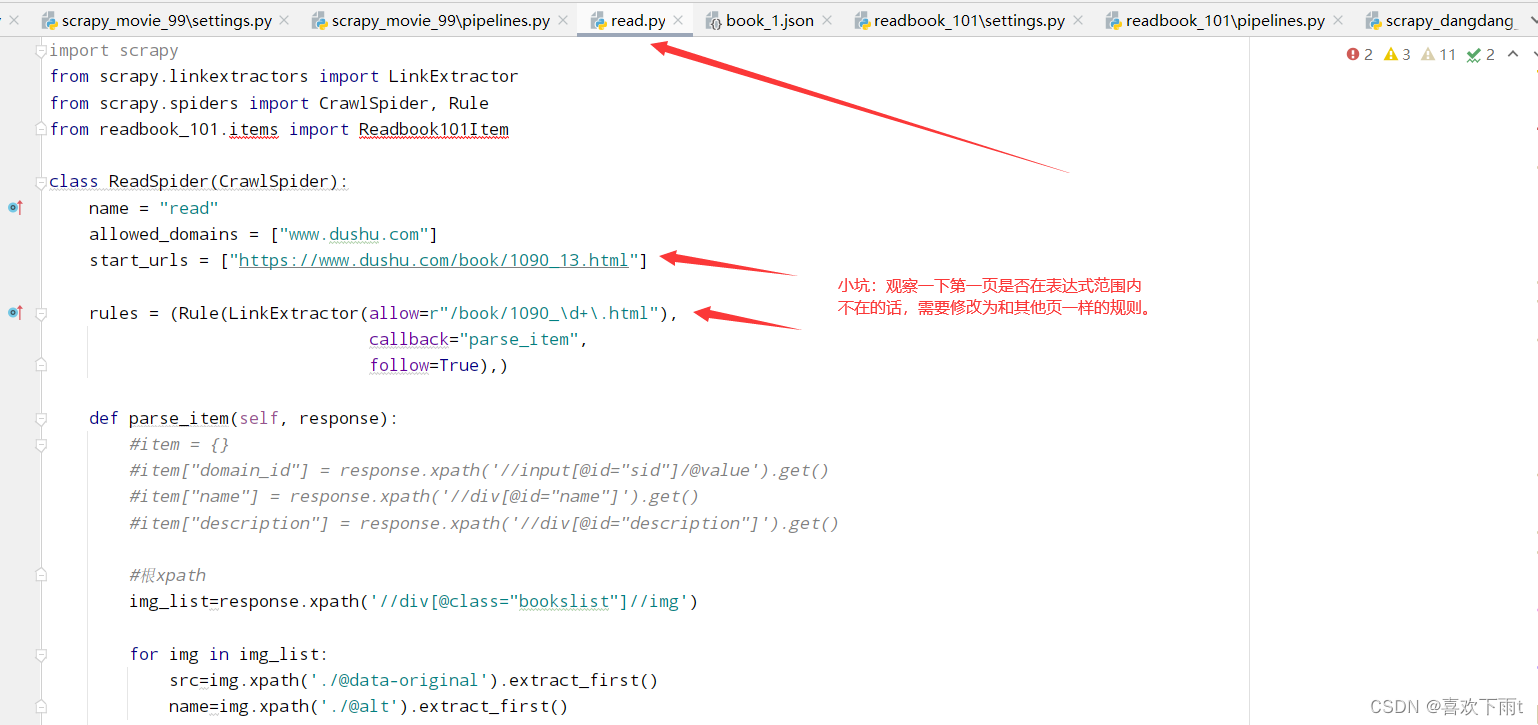
(11)效果如图——crtl+alt+L调整json数据格式快捷键

再编写一条管道——将数据保存到数据库
(1)进入数据库——以管理员的身份
mysql -u root -p
(2)创建数据库
create database spiders01;
(3)创建数据表
create table bookspiderdata(
id int auto_increment primary key,
name varchar(128),
src varchar(128));

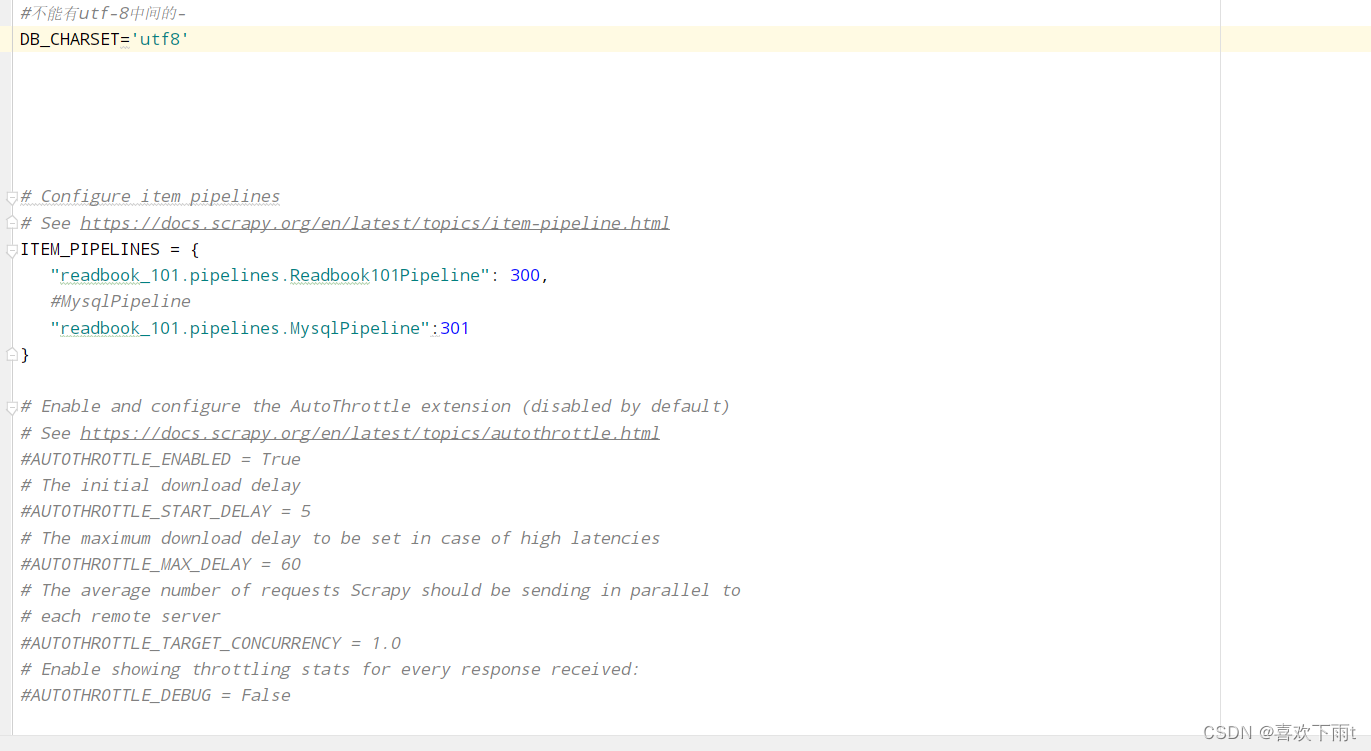
(4)在settings中配置数据库参数用来连接数据库
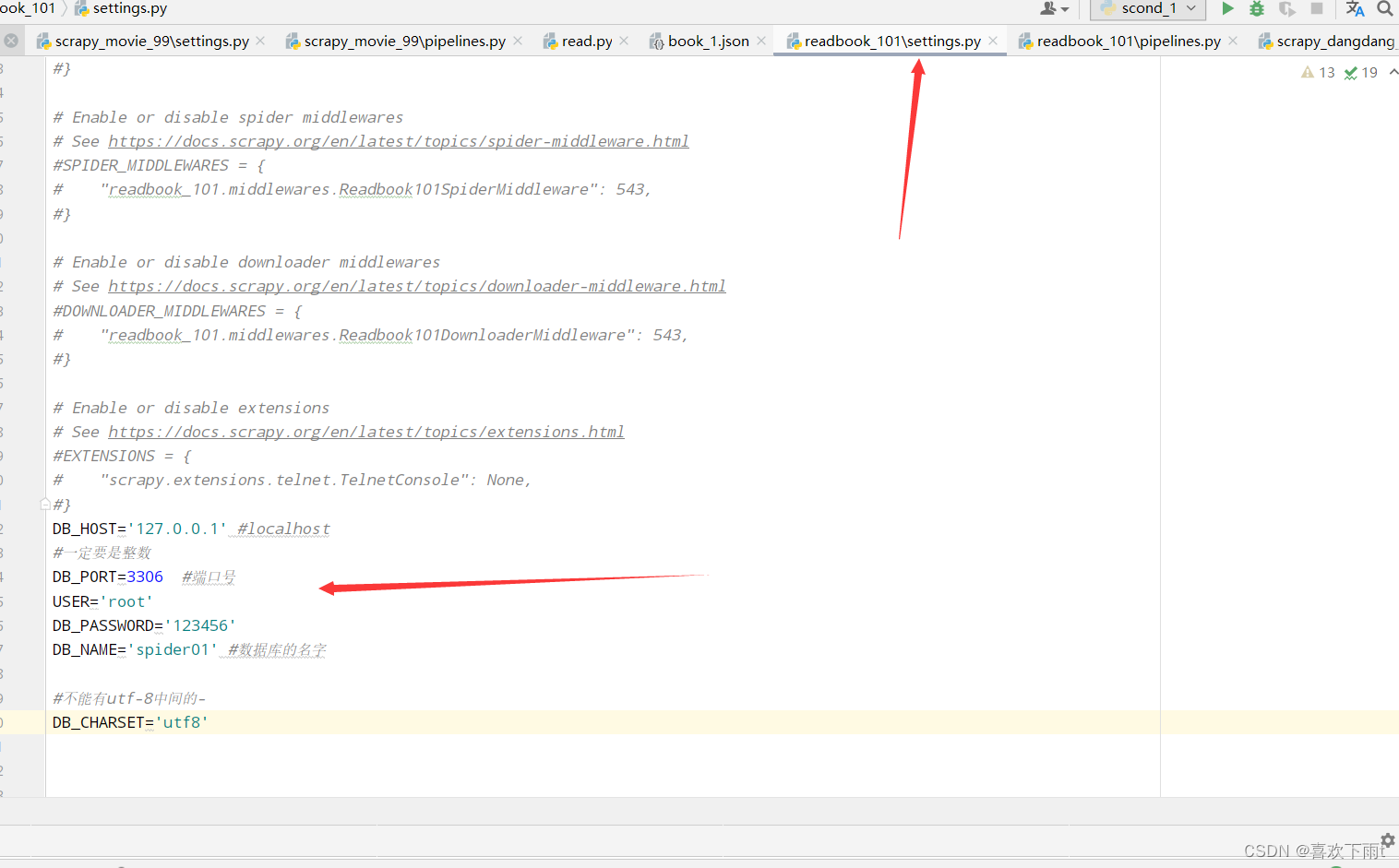
DB_HOST='127.0.0.1' #localhost
#一定要是整数
DB_PORT=3306 #端口号
USER='root'
DB_PASSWORD='123456'
DB_NAME='spider01' #数据库的名字
#不能有utf-8中间的-
DB_CHARSET='utf8'
(5)自定义写入数据库的管道
(5.1) 导入settings中的参数,并连接(字符集不能有-,端口号一定要是数字)
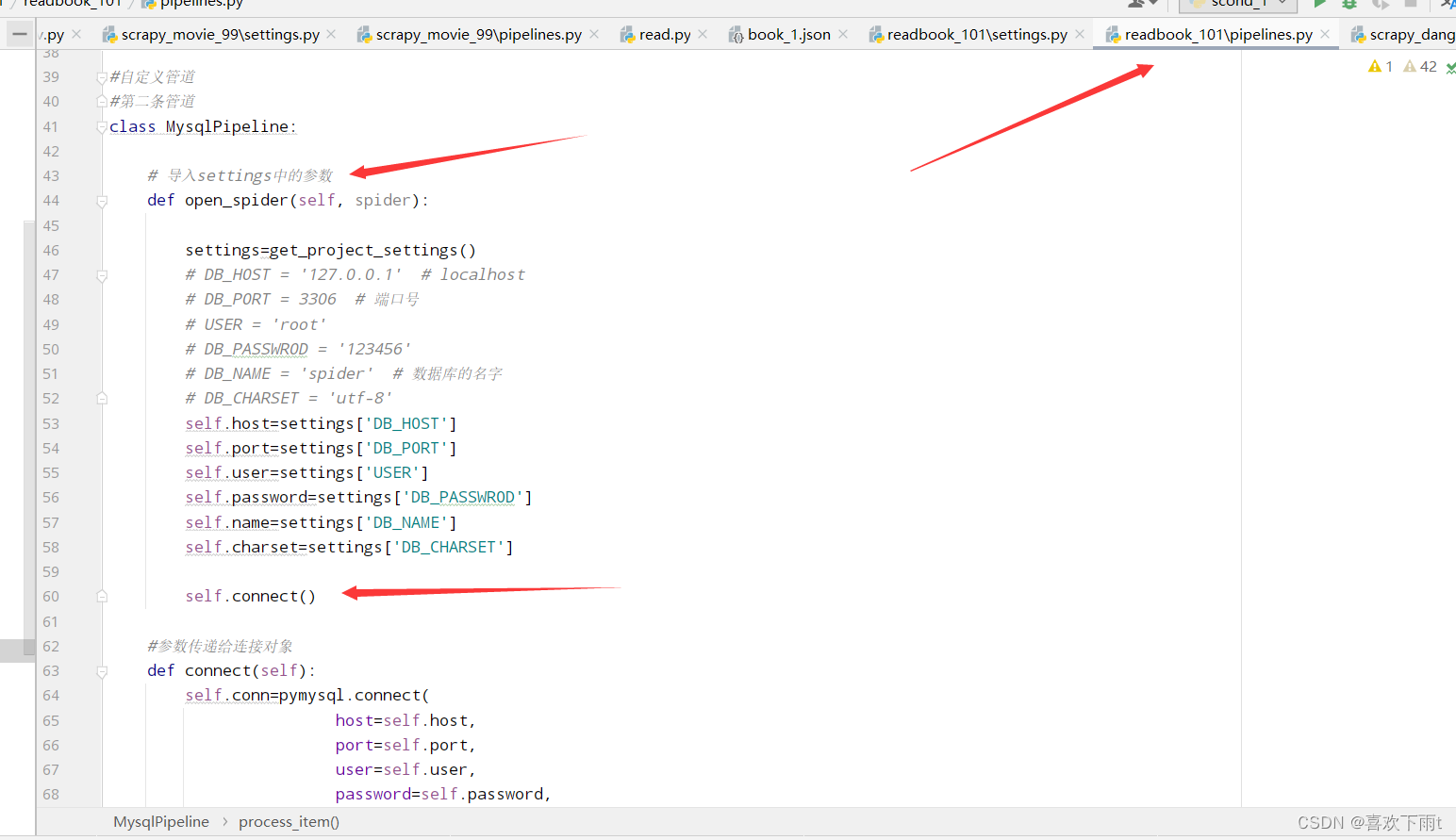
(5.2) 调用数据库连接函数connect——覆写,并交给游标,游标用来执行sql语句
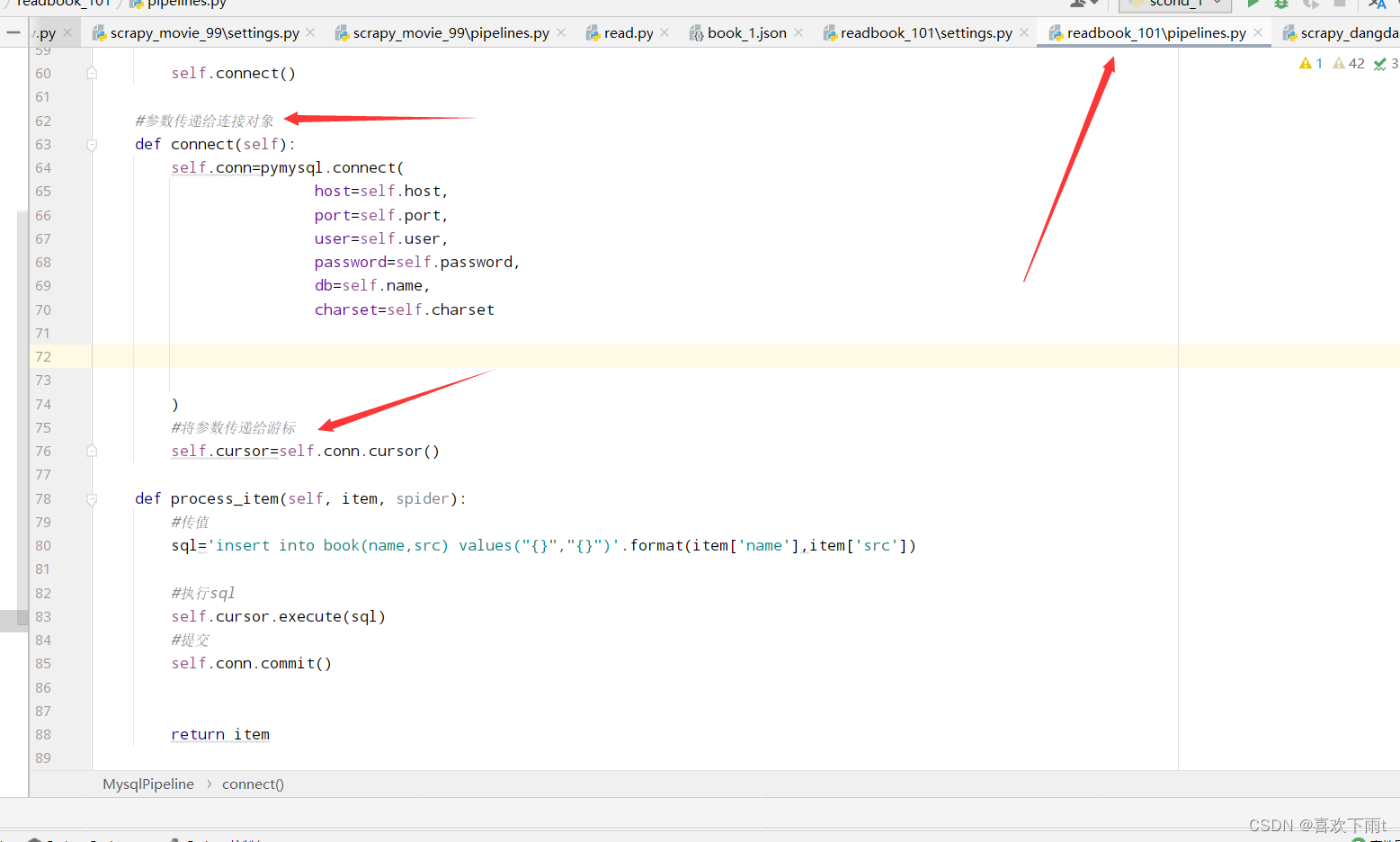
(5.3)执行sql语句并提交
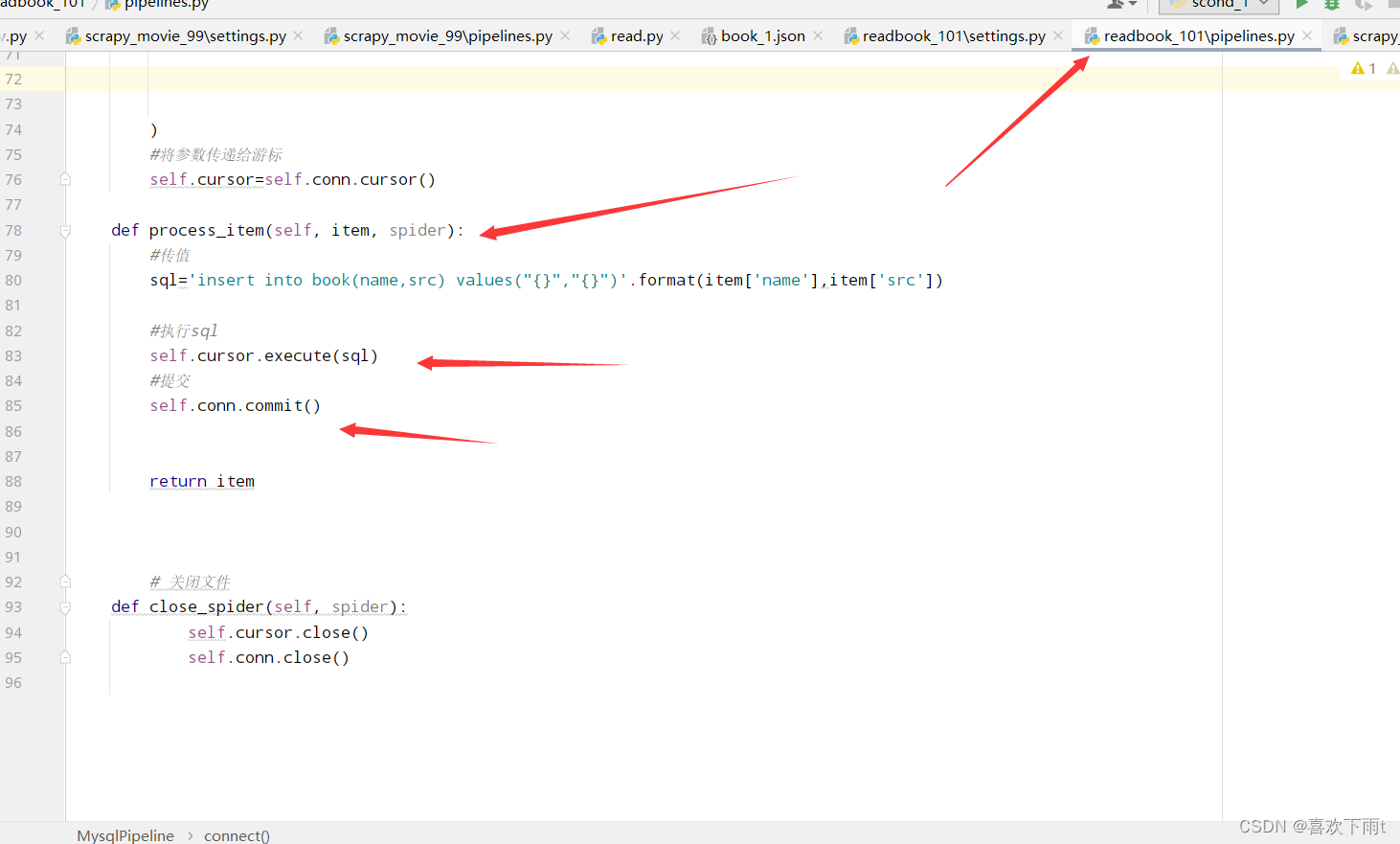
(5.4)关闭游标,关闭连接对象

(5.5)记得下载pysql
(5.6)第二条管道代码:
#导入
from scrapy.utils.project import get_project_settings
import pymysql
#自定义管道
#第二条管道
class MysqlPipeline:
# 导入settings中的参数
def open_spider(self, spider):
settings=get_project_settings()
# DB_HOST = '127.0.0.1' # localhost
# DB_PORT = 3306 # 端口号
# USER = 'root'
# DB_PASSWROD = '123456'
# DB_NAME = 'spider' # 数据库的名字
# DB_CHARSET = 'utf-8'
self.host=settings['DB_HOST']
self.port=settings['DB_PORT']
self.user=settings['USER']
self.password=settings['DB_PASSWROD']
self.name=settings['DB_NAME']
self.charset=settings['DB_CHARSET']
#调用数据库连接函数——覆写
self.connect()
#参数传递给连接对象——连接函数编写
def connect(self):
self.conn=pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
#将参数传递给游标——游标用来执行sql语句
self.cursor=self.conn.cursor()
def process_item(self, item, spider):
#sql语句
sql='insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
#执行sql
self.cursor.execute(sql)
#提交
self.conn.commit()
return item
# 关闭文件
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
(5.7)开启管道
(5.8)执行爬虫文件——即可得到数据
scrapy crawl read
















 5504
5504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











