







前言
上次的文章写了如何通过一个店铺名获得一个店铺所有的商品的基本信息,其中包括这次我们需要使用的id。这次我们就来使用商品id获取商品的评论
网页分析
我们首先打开一个商品的页面,然后打开开发者模式,没有显示包的话刷新一下。
我们需要注意的是这两个包。
 其中第一个是商品评论,第二个是好评和差评。
其中第一个是商品评论,第二个是好评和差评。
先看一下评论。
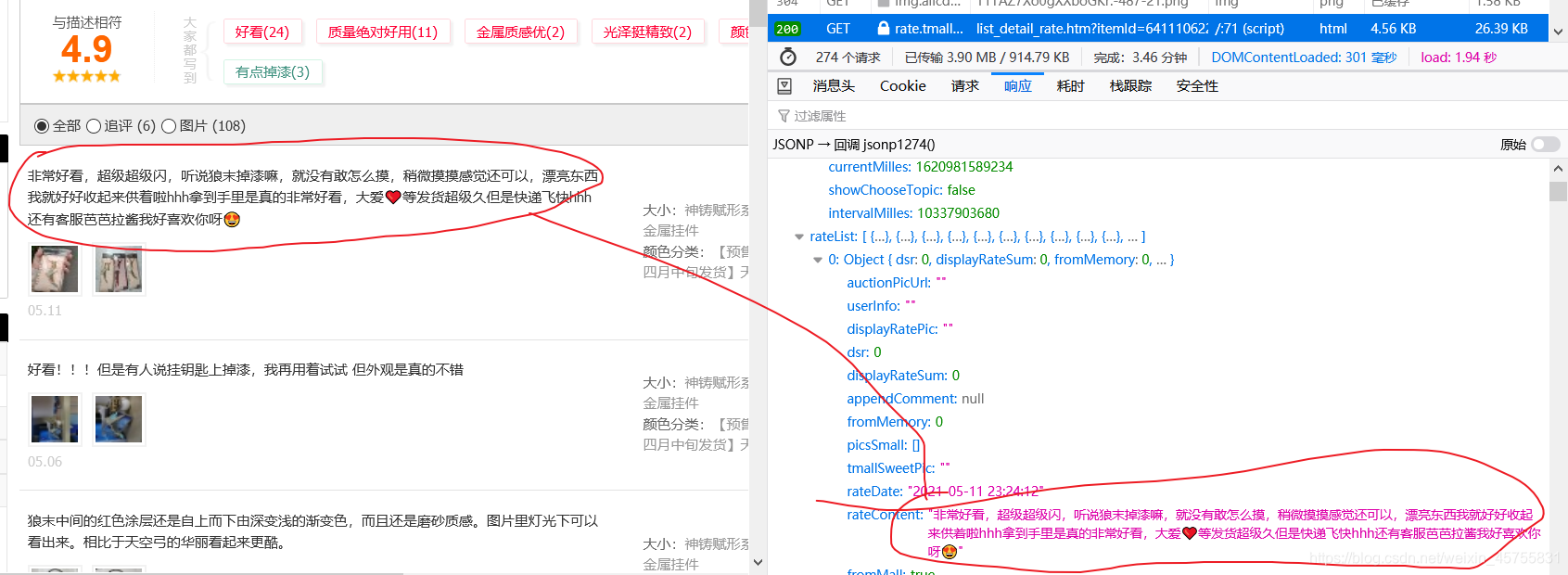 而且最后面也可以看到有当前页数和总页数。
而且最后面也可以看到有当前页数和总页数。
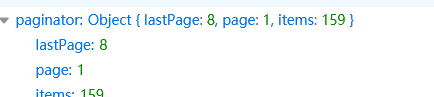
然后是好评和差评数,不过我们可以看到有红色和绿色的,这里红色为好评,绿色为差评。
我们需要把相同颜色的值加起来就是好评和差评数了。
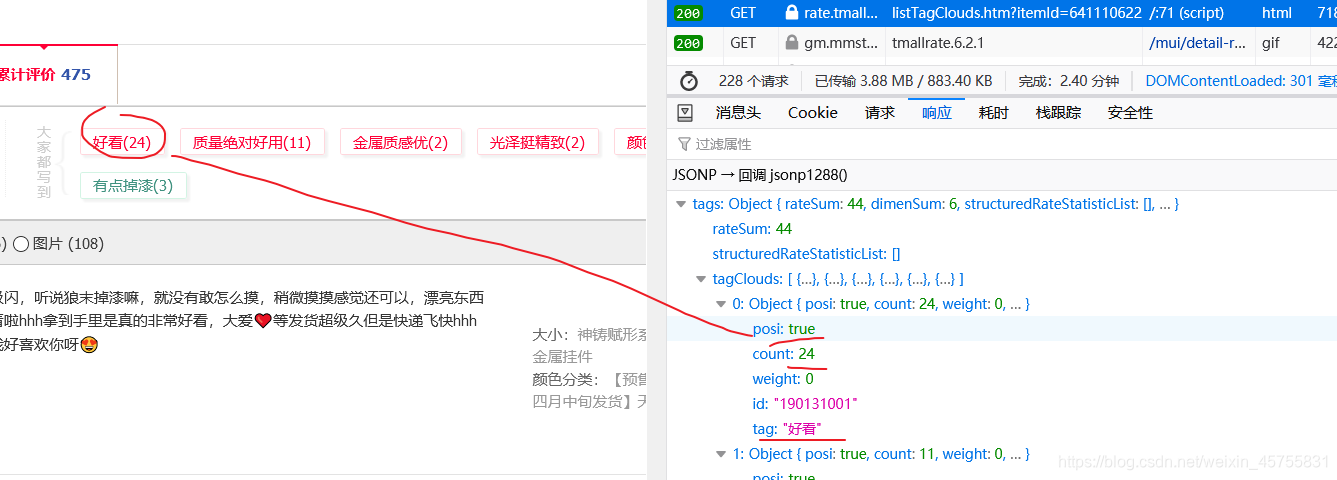 这个只有一页
这个只有一页
爬取流程
下面为本次的爬取流程,比较简陋。
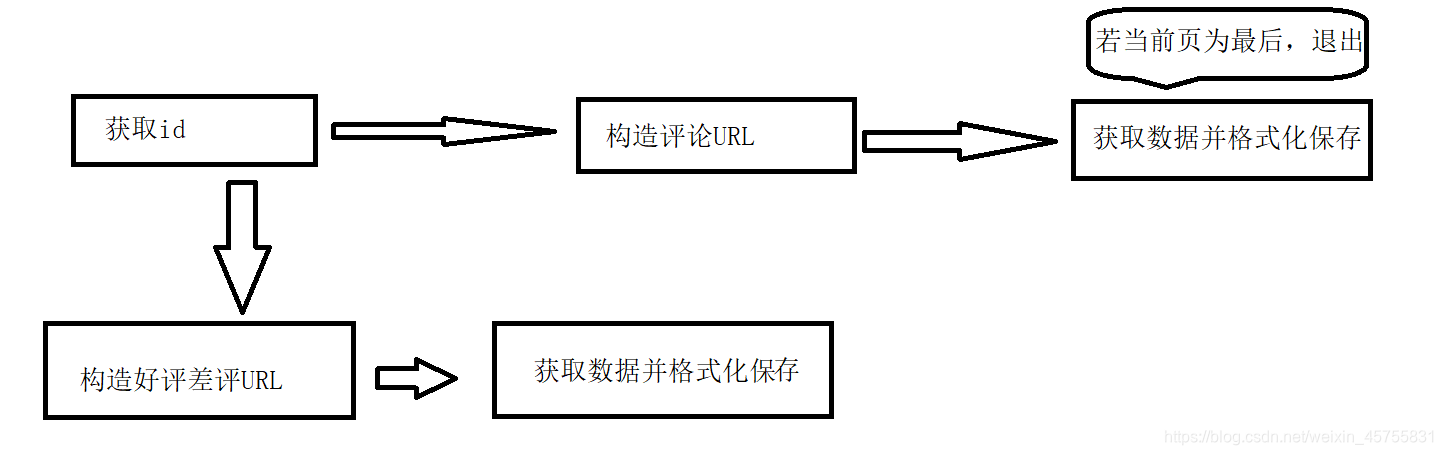
代码和运行结果
这里使用的id是上一篇博客生成的数据,需要进行读取并格式化为id列表。
需要注意的是,如果数据最后一行是换行的话,读取可能会报错,这次我写了一个异常捕获来避免报错的发生,当然,你也可以直接把换行那个删掉将光标移动到上一行的最后的位置。建议加入异常捕获而不是去动文件内部。
这里给出文件内部示例。
每个字段分别是商品名,商品id,商品价格,商品销量和评价。

def _Get_ids():
with open("shuangfeiyandata.csv", encoding='utf-8') as f:
data = f.read()
ids = []
for da in data.split('\n'):
try:
ids.append(da.split(',')[1])
except IndexError:
print("IndexError"+str(da))
return ids
这边是完整代码
# -*- coding: utf-8 -*-
# @Time : 2021/5/14 17:04
# @Author : Leviathan_Sei
# @File : from_id_get_comments.py
# @Python : 3.7
import requests
import csv
import json
import time
def _Get_html(page, item_id):
url = "https://rate.tmall.com/list_detail_rate.htm"
header = {
"referer": "https://detail.tmall.com/item.htm",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:60.0)Gecko/20100101 Firefox/60.0'",
}
params = {"itemId": str(item_id), "sellerId": "2616970885", "currentPage": "1", "order": "1",
"callback": "jsonp2359"}
cookies = {
}
req = requests.get(url, params, headers=header, cookies=cookies, timeout=2).content.decode(
'utf-8');
req = req[req.find('(') + 1:req.rfind(')')]
return json.loads(req)
def _Get_good_bad(item_id):
url = "https://rate.tmall.com/listTagClouds.htm?itemId=" + str(
item_id) + "&isAll=true&isInner=true&t=1620984765718&groupId=&_ksTS=1620984765718_1070&callback=jsonp1071"
cookies = {
}
headers = {
"Host": "rate.tmall.com",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:60.0)Gecko/20100101 Firefox/60.0'",
}
req = requests.get(url, cookies=cookies, headers=headers).text
return req
def _Format_data(item_id):
gb_comments = _Get_good_bad(item_id)
gb_comments = gb_comments[gb_comments.find('jsonp1071(') + 10:gb_comments.rfind('})') + 1]
gb_comments = json.loads(gb_comments)
gb_comments = gb_comments['tags']['tagClouds']
good_comments = 0
bad_comments = 0
for gb_comment in gb_comments:
if gb_comment['posi']:
good_comments += gb_comment['count']
else:
bad_comments += gb_comment['count']
with open('gb_comments.csv', 'a', encoding='utf-8-sig', newline='') as f:
w = csv.writer(f)
w.writerow([item_id, good_comments, bad_comments])
IsLastPage = True
Page = 1
with open(str(item_id) + '.csv', 'w', encoding='utf-8-sig', newline="") as f:
write = csv.writer(f)
write.writerow(['id', 'c1', 'v1', 'p1', 'c2', 'v2', 'p2'])
_data = []
while IsLastPage:
html = _Get_html(Page, item_id)
if html["rateDetail"]["paginator"]["lastPage"] == html["rateDetail"]["paginator"]["page"]:
IsLastPage = False
Page += 1
for comment in html["rateDetail"]["rateList"]:
data = [comment["id"], comment["rateContent"]]
if comment["videoList"]:
data.append(comment["videoList"])
else:
data.append("NULL")
if comment["videoList"]:
data.append(comment["pics"])
else:
data.append("NULL")
try:
data.append(comment["appendComment"]["content"])
except KeyError:
data.append("NULL")
except TypeError:
data.append("NULL")
try:
data.append(comment["appendComment"]["videoList"])
except KeyError:
data.append("NULL")
except TypeError:
data.append("NULL")
try:
data.append(comment["appendComment"]["pics"])
except KeyError:
data.append("NULL")
except TypeError:
data.append("NULL")
_data.append(data)
with open(str(item_id) + '.csv', 'a', encoding='utf-8-sig', newline="") as f:
write = csv.writer(f)
for data in _data:
write.writerow(data)
if IsLastPage:
time.sleep(10)
def _Get_ids():
with open("shuangfeiyandata.csv", encoding='utf-8') as f:
data = f.read()
ids = []
for da in data.split('\n'):
try:
ids.append(da.split(',')[1])
except IndexError:
print("IndexError" + str(da))
return ids
def _Main():
ids = _Get_ids()
for item_id in ids:
_Format_data(item_id)
if __name__ == '__main__':
_Main()
评论信息
字段分别为评论id、评论、评论视频、评论图片、追评、追评视频、追评图片。

好评数和差评数
字段为商品id,好评数和差评数。

后记
这次写的比较着急,要是有些东西有疑问,可以评论。
cookies没有放,要是不知道如何找cookies,就去上一篇博客去找。
如果有想要爬的东西,可以留言。
谢谢阅读!














 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









