







基于人工智能的多肽药物分析问题(知识点补充二)
2021SC@SDUSC
1. Dropout层作用
1.1 定义
大规模的神经网络有两个缺点:
- 费时
- 容易过拟合
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
Dropout的出现很好的可以解决费时这个问题,每次做完dropout,相当于从原始的网络中找到一个更瘦的网络;它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
1.2 运作方式
在训练时,每个神经单元以概率pp被保留(Dropout丢弃率为1−p);在预测阶段(测试阶段),每个神经单元都是存在的,权重参数w要乘以p,输出是:pw。示意图如下:
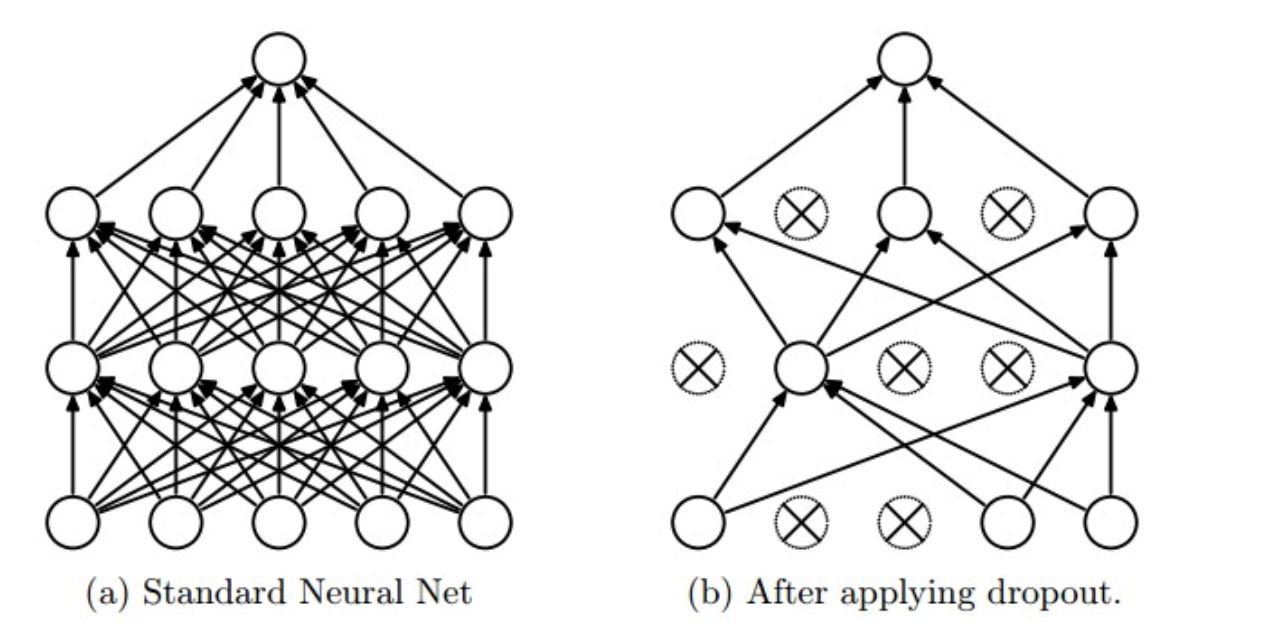
预测阶段需要乘上p的原因:
前一层隐藏层的一个神经元在dropout之前的输出是x,训练时dropout之后的期望值是E=px+(1−p)0; 在预测阶段该层神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整x−>px. 其中p是Bernoulli分布(0-1分布)中值为1的概率。
2. Embedding层作用
在深度学习的应用过程中,Embedding 这样一种将离散变量转变为连续向量的方式为神经网络在各方面的应用带来了极大的扩展。该技术目前主要有两种应用,NLP 中常用的 word embedding 以及用于类别数据的 entity embedding
2.1 Embedding 和 One Hot 编码
上面说了,Embedding 是一个将离散变量转为连续向量表示的一个方式。在神经网络中,embedding 是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
embedding 的三个主要目的:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
要了解 embedding 的优点,我们可以对应 One-hot 编码来观察。One-hot 编码是一种最普通常见的表示离散数据的表示,首先我们计算出需要表示的离散或类别变量的总个数 N,然后对于每个变量,我们就可以用 N-1 个 0 和单个 1 组成的 vector 来表示每个类别。这样做有两个很明显的缺点:
- 对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。
- 映射之间完全独立,并不能表示出不同类别之间的关系。
# One Hot Encoding Categoricals
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
Similarity (dot product) between First and Second = 0
Similarity (dot product) between Second and Third = 0
Similarity (dot product) between First and Third = 0
因此,考虑到这两个问题,表示类别变量的理想解决方案则是我们是否可以通过较少的维度表示出每个类别,并且还可以一定的表现出不同类别变量之间的关系,这也就是 embedding 出现的目的。
# Idealized Representation of Embedding
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded_ideal = [[0.53, 0.85],
[0.60, 0.80],
[-0.78, -0.62]]
Similarity (dot product) between First and Second = 0.99
Similarity (dot product) between Second and Third = -0.94
Similarity (dot product) between First and Third = -0.97
而为了更好的表示类别实体,我们还可以是用一个 embedding neural network 和 supervised 任务来进行学习训练,以找到最适合的表示以及挖掘其内在联系。
One-hot 编码的最大问题在于其转换不依赖于任何的内在关系,而通过一个监督性学习任务的网络,我们可以通过优化网络的参数和权重来减少 loss 以改善我们的 embedding 表示,loss 越小,则表示最终的向量表示中,越相关的类别,它们的表示越相近。
2.2 总结
总的来说,相对于one-hot编码,embedding嵌入层的作用就是将从稀疏态变成了密集态,并且让相互独立向量变成了有内在联系的关系向量。它把我们的稀疏矩阵,通过一些线性变换(在CNN中用全连接层进行转换,也称为查表操作),变成了一个密集矩阵,这个密集矩阵用了N个特征来表征所有的文字,在这个密集矩阵中,表象上代表着密集矩阵跟单个字的一一对应关系,实际上还蕴含了大量的字与字之间,词与词之间甚至句子与句子之间的内在关系。他们之间的关系,用的是嵌入层学习来的参数进行表征。从稀疏矩阵到密集矩阵的过程,叫做embedding,很多人也把它叫做查表,因为他们之间也是一个一一映射的关系。
3. pytorch自定义模型
前言:pytorch中对于一般的序列模型,直接使用torch.nn.Sequential类及可以实现,这点类似于keras,但是更多的时候面对复杂的模型,比如:多输入多输出、多分支模型、跨层连接模型、带有自定义层的模型等,就需要自己来定义一个模型了。
3.1 torch.nn.Module类
(1)keras更常见的操作是通过继承Layer类来实现自定义层,不推荐去继承Model类定义模型,详细原因可以参见官方文档
(2)pytorch中其实一般没有特别明显的Layer和Module的区别,不管是自定义层、自定义块、自定义模型,都是通过继承Module类完成的,这一点很重要。其实Sequential类也是继承自Module类的。
总结:pytorch里面一切自定义操作基本上都是继承nn.Module类来实现的
二、torch.nn.Module类的简介
先来简单看一它的定义:
class Module(object):
def __init__(self):
def forward(self, *input)
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法。但有一些注意技巧:
(1)一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然我也可以吧不具有参数的层也放在里面;
(2)一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替
(3)forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
例子:
import torch
import torch.nn.functional as F
class MyNet(torch.nn.Module):
def __init__(self):
super(MyNet, self).__init__() # 第一句话,调用父类的构造函数
self.conv1 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.conv2 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.dense1 = torch.nn.Linear(32 * 3 * 3, 128)
self.dense2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x)
x = self.dense1(x)
x = self.dense2(x)
return x
model = MyNet()
print(model)
'''
运行结果为:
MyNet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(dense1): Linear(in_features=288, out_features=128, bias=True)
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
'''
注意:此时,将没有训练参数的层没有放在构造函数里面了,所以这些层就不会出现在model里面,但是运行关系是在forward里面通过functional的方法实现的。
总结:所有放在构造函数__init__里面的层的都是这个模型的“固有属性”.
3.2 forward 函数介绍
在定义好module类之后,调用module时,通常执行
一个参数x
pred = module(x)
import torch
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
print("init执行")
def forward(self,x,out):
x=out
print("输入为:",x)
print("out:",out)
return x
module = Net()
pred = module(5,6)
print(pred)
输出为:
init执行
输入为: 6
out: 6
6
调用module时传入参数与module类定义的forward参数一致
module返回的函数值为forward的返回值,即return的x=out,即out值,这里返回了6,于是pred为6
3.3 调用顺序
forward是在__call__中调用的,而__call__函数是在类的对象使用‘()’时被调用。一般调用在类中定义的函数的方法是:example_class_instance.func(),如果只是使用example_class_instance(),那么这个操作就是在调用__call__这个内置方法,有了上面的知识,那么从第一步来看,pred = module(5,6)实际上就是调用了__call__方法,而call方法调用的是forward()方法,所以,直接用pred = module(5,6)就能够直接调用forward()方法。















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









