







零、说明
-
这个程序包括
①通过输入建立赫夫曼树(哈夫曼树)
②输入一串字符串,能得到其赫夫曼编码,输入一串赫夫曼编码,也能得到其原始字符串,有能实现这两个功能的两个函数 -
思路是下面这个博主的,在此表示感谢:
NOJ-哈夫曼编/译码器 -
原题目:
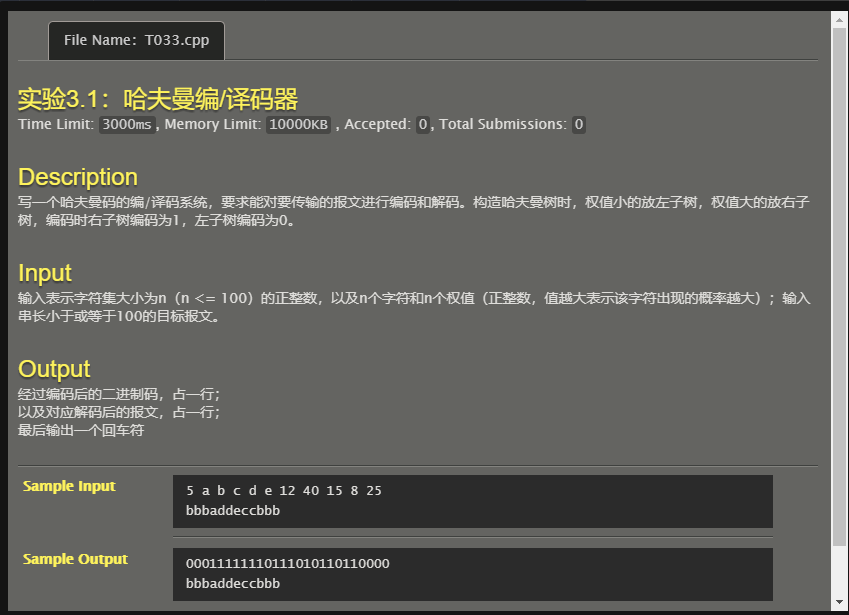
不过为了以后复习时看得懂,我修改了输入方式:
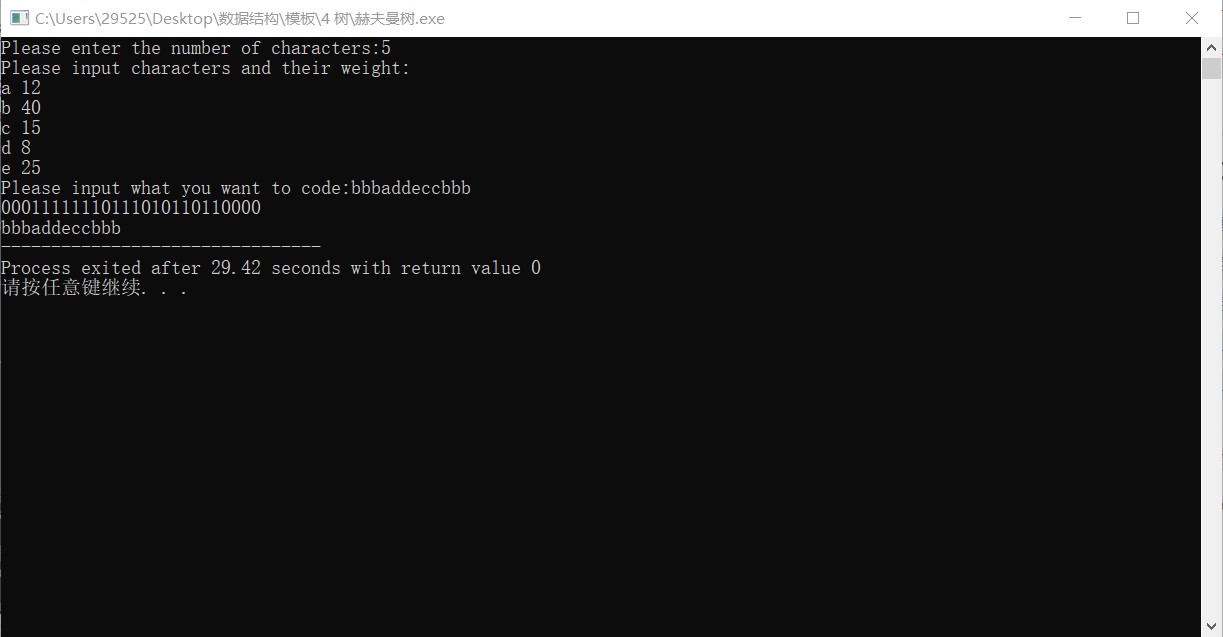
不过由于中间步骤不同,最后输出的编码序列和其他算法可能有不同,是由于同编码的赫夫曼树不止有一棵,如果两个节点权值相同,两个的左右位置可以交换
一、数据类型
上学期写这个实验的时候我用的是指针*lch,*rch,非常费事,代码也不知道哪去了,所以借用那个博主的思路直接使用顺序结构构造树
typedef struct
{
char data;//字符
int weight;//权值
int parent,lch,rch;//是双亲表示法的拓展
int visited;//这个节点是否已被纳入树中
}Huffnode;//单个的树节点
typedef struct
{
Huffnode Tree[MAXSIZE];//树的本身
int num;//树中节点个数
int root;//根节点位置:顺序结构不像链式结构的根节点的地址就是树本身,而是要特别存储标志,
//更何况赫夫曼树是从底往上构建的,刚开始时根节点还没创建
}Hufftree;
二、主函数
先说明主函数内容,理解整体思路,再分条进入看每个功能如何实现
int main()
{
Hufftree T;//新建一棵树
int A[2001]={0},i,Nodenum;//A存储字符串编码后的01序列,i用来计数,Nodenum是字符数目,A[0]存储内容长度
char B[101]={0};//B用来存储01序列翻译成的字符串,B[0]存储内容长度
Nodenum=Input(&T);//把字符及其权值输入到树中,同时返回字符数(T->num总结点数)
Buildtree(&T);//建树
Code(&T,A,Nodenum);//给字符串编码(字符串在这个函数中读取)
Encode(&T,A,B);//将A中的编码翻译成B中的字符
for(i=1;i<=A[0];i++)//输出A中的编码,同时注意:A[0]、B[0]存储的都是内容长度,所以从A[1]、B[1]开始
{
cout<<A[i];
}
cout<<endl;
for(i=1;i<=B[0];i++)//输出B中的编码
{
cout<<B[i];
}
return 0;
}
三、建立赫夫曼树
- 输入:按提示输入(主函数Input,一个子函数Initnode)
int Input(Hufftree *T)
{
int num,i;
cout<<"Please enter the number of characters:";
cin>>num;//字符数,即文本中有哪些字符
T->num=num;
//此时的T->num就是字符数,但后续会++来新建节点,所以结束后不是字符数,上面的Nodenum有用
cout<<"Please input characters and their weight:"<<endl;//依次输入字符+权值
for(i=1;i<=num;i++)//按这个数量将字符及其权值输入某个节点中
{
Initnode(&(T->Tree[i]));//初始化这个节点,后序还要用
cin>>T->Tree[i].data;//字符
cin>>T->Tree[i].weight;//字符的权值
}
return num;//最后返回字符的数量
}
void Initnode(Huffnode *Node)
{
Node->data='#';
Node->weight=0;
Node->parent=0;
Node->lch=0;
Node->rch=0;
Node->visited=0;
}
- 建树(主函数Buildtree,两个子函数Weightsum和Smallest(不包括Initnode))
void Buildtree(Hufftree *T)
{
int Node1,Node2,weightsum;//使用Node1、Node2是因为建立赫夫曼树过程中每次要取出两个节点
weightsum=Weightsum(T);//在Smallest函数中用。某个节点的权值如果为全部之和,则这个节点就是根节点,那时候树就建完了
while(Smallest(T,weightsum))//Smallest函数中,如果最后某个节点的权值为weightsum,就返回0,就跳出这个循环了
{//注意:下列的节点包括两种:存储字符的节点,字符节点的双亲节点,两者都参与Smallest的选取
Node1=Smallest(T,weightsum);//T中最小节点
T->Tree[Node1].visited=1; //表示已经把这个节点拿出来建树了
Node2=Smallest(T,weightsum);//取出Node1后的最小节点
T->Tree[Node2].visited=1; //同上
T->num++;//T中新增一个节点,左右孩子是上述(即此时树中权值最小的两个节点)
Initnode(&(T->Tree[T->num]));//初始化这个新节点
T->Tree[T->num].lch=Node1;//左孩子是最小
T->Tree[T->num].rch=Node2;//右孩子是次小
//权值是两孩子权值之和
T->Tree[T->num].weight=T->Tree[Node1].weight+T->Tree[Node2].weight;
T->Tree[Node1].parent=T->num;
T->Tree[Node2].parent=T->num;//两孩子的双亲节点是这个新建节点
}
T->root=T->num;//当从上面那个while循环出来之后,T->num就是最后一个新建的节点,而它就是根节点。
//由此可见,顺序存储且赫夫曼树,根节点最后才确定
}
int Weightsum(Hufftree *T)//就是一个一个累加权值
{
int i,weightsum;
weightsum=0;
for(i=1;i<=T->num;i++)//注意,上面调用这个函数时,T->num还没增加,仍为字符数,因此这边直接用了
{
weightsum+=T->Tree[i].weight;
}
return weightsum;
}
int Smallest(Hufftree *T,int weightsum)
{
int i,min,rec;
min=65535;//min用来记录最小的权值
rec=0;//rec用来记录最小权值的节点编码
for(i=1;i<=T->num;i++)
{
if(T->Tree[i].visited==1)//如果已经被纳入树中,就跳过(因为要比较的不是它,而是它的双亲节点)
{
continue;
}
if(min>T->Tree[i].weight)//这两步就是一步一步筛选出权值最小的节点
{
rec=i;
min=T->Tree[i].weight;
}
}
if(min==weightsum)//但是如果此时得到的权值为所有字符权值之和,说明只剩一个根节点还没visited了
//那不就是树建完了吗?于是返回0,来跳出Buildtree函数中的循环
{
return 0;
}
else//如果不是上述情况,那rec记录的就是权值最小的节点了
{
return rec;
}
}
四、编码与译码
- 编码
调用了strlen,要include<string.h>
void Code(Hufftree *T,int A[2001],int Nodenum)
{
int length,i,j,position,Alength;
char Get[100];
cout<<"Please input what you want to code:";
cin>>Get;//得到想要编码的字符串
length=strlen(Get);//想要编码的字符串的长度
Alength=1;
for(i=length-1;i>=0;i--)//逐个字符在树中匹配,将编码输入A数组中,
//同时注意:由于下面每个字符编码本身就是逆序输入A,所以要从i=length-1,即最后一个存储字符的节点开始
{
for(j=1;j<=Nodenum;j++)//找待编码的字符串中每个字符 在树中的位置
{
if(Get[i]==T->Tree[j].data)//如果匹配到了
{
position=j;//用position存储这个位置
break;//进入下一步
}
}
//下面的原理就是从树中某个字符节点出发,逐个找它的双亲节点,因此是逆序的
while(T->Tree[position].parent)//当还没到根节点(根节点的parent是0)
{
if(T->Tree[T->Tree[position].parent].lch==position)//如果双亲的左孩子是它,那编码中这一位就是0
{
A[Alength]=0;
}
else//不然就是1
{
A[Alength]=1;
}
Alength++;
position=T->Tree[position].parent;//看它的双亲节点编码如何
}
}
A[0]=Alength-1;//最后一步没有下一步,却仍然搞了Alength++,所以真实长度是Alength-1
Reverse(A);//最后A是逆序的,因此为了方便起见,把A逆回来,就正序了
}
void Reverse(int A[2001])
{
int i,temp;
for(i=1;i<=A[0]/2;i++)
{
temp=A[i];
A[i]=A[A[0]-i+1];
A[A[0]-i+1]=temp;
}
}
- 译码
想象一个虚拟指针,开始指向根节点,根据赫夫曼编码每一位的0或1,决定下一步指到它的左孩子还是右孩子.直到指向某个字符,把这个字符输入到B中,然后让这个虚拟指针返回根节点,即可
void Encode(Hufftree *T,int A[2001],char B[101])
{
int i,position,Blength;
position=T->root;//position意为虚拟一个指针,它的位置
Blength=1;//存在B中的哪个位置
for(i=1;i<=A[0];i++)//从A的第一个结点开始
{
if(A[i]==0)//如果是零,position指向其左孩子
{
position=T->Tree[position].lch;
if(T->Tree[position].lch==0)//如果左孩子为0,说明到底了,这个节点就是字符节点
{
B[Blength]=T->Tree[position].data;
Blength++;
position=T->root;//虚拟指针返回根节点
}
}
else
//解释同上,不过注意,if(T->Tree[position].rch那步也可以为lch,只要表达出到了底部的意思即可
{
position=T->Tree[position].rch;
if(T->Tree[position].rch==0)
{
B[Blength]=T->Tree[position].data;
Blength++;
position=T->root;
}
}
}
B[0]=Blength;//出循环,B内容的长度Blength
}















 1619
1619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









