






这里写目录标题
hadoop 安装spark
一. 准备三台虚拟机,并可有网络
master 192.168.100.101
slave1 192.168.100.102
slave2 192.168.100.103

二,修改主机名
hostname master
hostname slave1
hostname slave2
三.SecureCR连接三台虚拟机,方便操作
以下操作三台机同步骤
四.修改/etc/host
vi /etc/hosts
添加内容
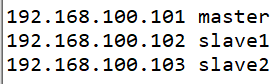
192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
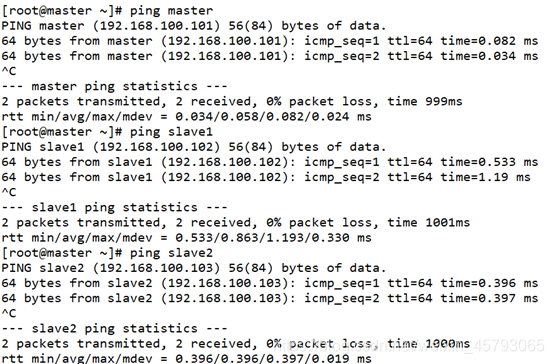
测试
ping master
Ping slave1
Ping slave2
五.ssh无密码denglu
安装 ssh
yum install openssh-server
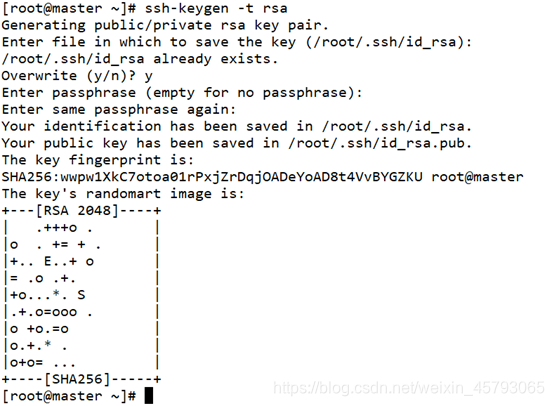
ssh-keygen -t rsa 接着按三次enter
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
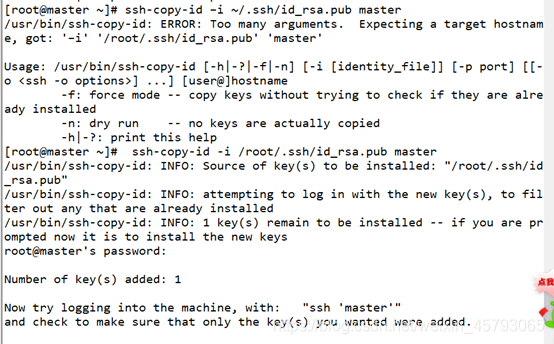
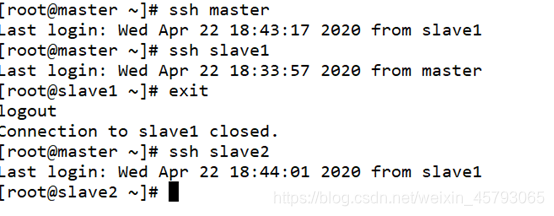
测试登录
ssh master
ssh slave1
ssh slave2
六.在/usr 创建java scala 文件夹
mkdir /usr/java /usr/scala

七.进入 /usr/java 命令 SecureCRT上传jdk文件

八.scala 同样方法上传到/usr/scala

九.配置jdk和scala环境变量
Vi /etc/profile
后面添加:
export JAVA_HOME=/usr/java/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export PATH="$PATH:/usr/scala/scala-2.11.12/bin"
export SCALA_HOME=/usr/scala/scala-2.11.12
按esc :x 保存退出

重启 /etc/profile
source /etc/profile
测试jdk
javac
测试scala
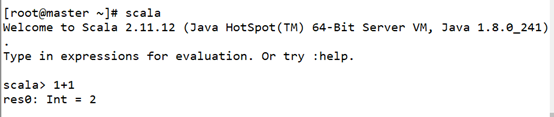
十.配置spark
创建 /usr/spark 存放spark文件
如jdk上传文件方式一样上传文件

进入/usr/spark/spark-2.4.5-bin-hadoop2.6/conf
复制spark-env.sh.template为 spark-env.sh
cp spark-env.sh.template spark-env.sh

编辑
vi spark-env.sh
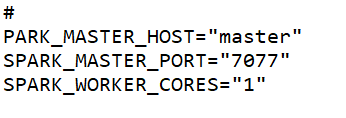
添加内容:
SPARK_MASTER_HOST=”master”
SPARK_MASTER_PORT=”7077”
SPARK_WORKER_CORES=”1”
复制slaves.template 为slaves

vi slaves
修改 localhost 为
master slave1 slave2

十一.启动spark
./sbin/start-all.sh
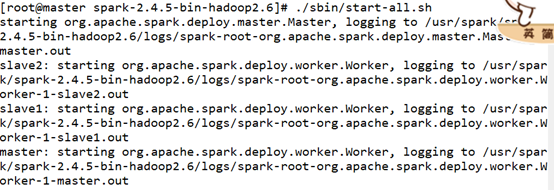
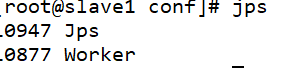
查看jps,是否启动成功
Master
jps

Slave1 slave2

十二.例子 在master 操作
在spark-2.4.5-bin-hadoop2.6的bin
./run-example --master spark://master:7077 SparkPi
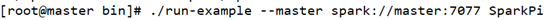
结果:
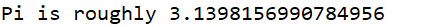














 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









