import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dsigmoid(y):
return y * (1 - y)
def tanh(x):
return np.tanh(x)
def dtanh(y):
return 1.0 - y ** 2
class MLPClassifier:
def __init__(self, layers, activation='tanh', epochs=20, learning_rate=0.01):
self.epochs = epochs
self.eta = learning_rate
self.layers = [np.zeros(layers[0])]
self.weights = []
self.biases = []
for i in range(len(layers) - 1):
weight = np.random.random((layers[i + 1], layers[i]))
layer = np.ones(layers[i + 1])
bias = np.random.random(layers[i + 1])
self.weights.append(weight)
self.layers.append(layer)
self.biases.append(bias)
if activation == 'tanh':
self.activation = tanh
self.dactivation = dtanh
elif activation == 'sigmoid':
self.activation = sigmoid
self.dactivation = dsigmoid
def fit(self, X, y):
for _ in range(self.epochs):
indexes = np.random.permutation(X.shape[0])
for i in range(X.shape[0]):
self.forward(X[indexes[i]])
self.backward(y[indexes[i]])
return self
def predict(self, X):
return np.where(self.predict_prob(X) >= 0.5, 1, 0)
def predict_prob(self, X):
y = np.empty((X.shape[0], len(self.layers[-1])))
for i in range(X.shape[0]):
self.forward(X[i])
y[i, :] = self.layers[-1]
return y
def forward(self, inputs):
self.layers[0][:] = inputs
for i in range(len(self.weights)):
self.layers[i + 1] = self.activation(self.weights[i].dot(self.layers[i]) + self.biases[i])
def backward(self, y):
y_predict = self.layers[-1]
pre_gradient_neurons = y - y_predict
for i in range(len(self.layers) - 1, 0, -1):
gradient_bias = pre_gradient_neurons * self.dactivation(self.layers[i])
gradient_weight = gradient_bias.reshape(-1, 1).dot(self.layers[i - 1].reshape(1, -1))
pre_gradient_neurons = gradient_bias.dot(self.weights[i - 1])
self.weights[i - 1] += self.eta * gradient_weight
self.biases[i - 1] += self.eta * gradient_bias
def plot_decision_boundary(model, X):
axis = [np.min(X[:, 0]), np.max(X[:, 0]), np.min(X[:, 1]), np.max(X[:, 1])]
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9', '#EE82EE', '#00FFFF', '#7FFFAA', '#BDB76B'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
if __name__ == '__main__':
X, y = datasets.make_moons(n_samples=1000, noise=0.1, random_state=666)
n = MLPClassifier((2, 3, 1), activation='tanh', epochs=300, learning_rate=0.01)
n.fit(X, y)
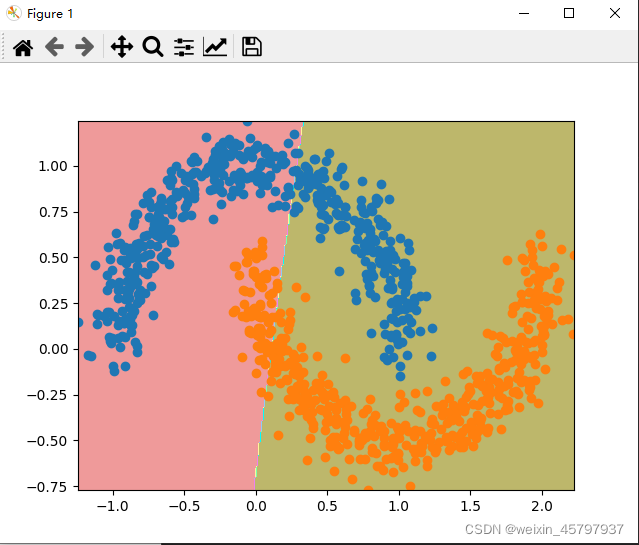
plot_decision_boundary(n, X)
plt.scatter(X[y == 0, 0], X[y == 0, 1])
plt.scatter(X[y == 1, 0], X[y == 1, 1])
plt.show()
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dsigmoid(y):
return y * (1 - y)
def tanh(x):
return np.tanh(x)
def dtanh(y):
return 1.0 - y ** 2
class MLPClassifier:
def __init__(self, layers, activation='tanh', epochs=20, batch_size=1, learning_rate=0.01):
self.epochs = epochs
self.eta = learning_rate
self.batch_size = batch_size
self.layers = [np.zeros((layers[0], batch_size))]
self.weights = []
self.biases = []
for i in range(len(layers) - 1):
weight = np.random.random((layers[i + 1], layers[i]))
layer = np.ones((layers[i + 1], batch_size))
bias = np.random.random((layers[i + 1], 1))
self.weights.append(weight)
self.layers.append(layer)
self.biases.append(bias)
if activation == 'tanh':
self.activation = tanh
self.dactivation = dtanh
elif activation == 'sigmoid':
self.activation = sigmoid
self.dactivation = dsigmoid
def fit(self, X, y):
if y.ndim == 2:
assert y.shape[1] == X.shape[0], "each column of y is a label of a row in X"
for _ in range(self.epochs):
indexes = np.random.permutation(X.shape[0])
for i in range(X.shape[0] // self.batch_size):
start_index = i * self.batch_size
end_index = start_index + self.batch_size
self.forward(X[indexes[start_index:end_index]])
self.backward(y[indexes[start_index:end_index]])
return self
def predict(self, X):
return np.where(self.predict_prob(X) >= 0.5, 1, 0)
def predict_prob(self, X):
self.forward(X)
y = self.layers[-1].copy()
return y
def forward(self, inputs):
self.layers[0] = inputs.T
for i in range(len(self.weights)):
self.layers[i + 1] = self.activation(self.weights[i].dot(self.layers[i]) + self.biases[i])
def backward(self, y):
y_predict = self.layers[-1]
pre_gradient_neurons = y - y_predict
for i in range(len(self.layers) - 1, 0, -1):
gradient_bias_matrix = pre_gradient_neurons * self.dactivation(self.layers[i])
gradient_weight = gradient_bias_matrix.dot(self.layers[i - 1].T) / self.batch_size
pre_gradient_neurons = np.sum(gradient_bias_matrix.T.dot(self.weights[i - 1]), axis=0) \
.reshape(-1, 1) / self.batch_size
gradient_bias = np.mean(gradient_bias_matrix, axis=1).reshape(-1, 1)
self.weights[i - 1] += self.eta * gradient_weight
self.biases[i - 1] += self.eta * gradient_bias
def plot_decision_boundary(model, X):
axis = [np.min(X[:, 0]), np.max(X[:, 0]), np.min(X[:, 1]), np.max(X[:, 1])]
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9', '#EE82EE', '#00FFFF', '#7FFFAA', '#BDB76B'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
if __name__ == '__main__':
X, y = datasets.make_moons(n_samples=1000, noise=0.1, random_state=666)
n = MLPClassifier((2, 3, 1), activation='tanh', epochs=300, learning_rate=0.01)
n.fit(X, y)
plot_decision_boundary(n, X)
plt.scatter(X[y == 0, 0], X[y == 0, 1])
plt.scatter(X[y == 1, 0], X[y == 1, 1])
plt.show()
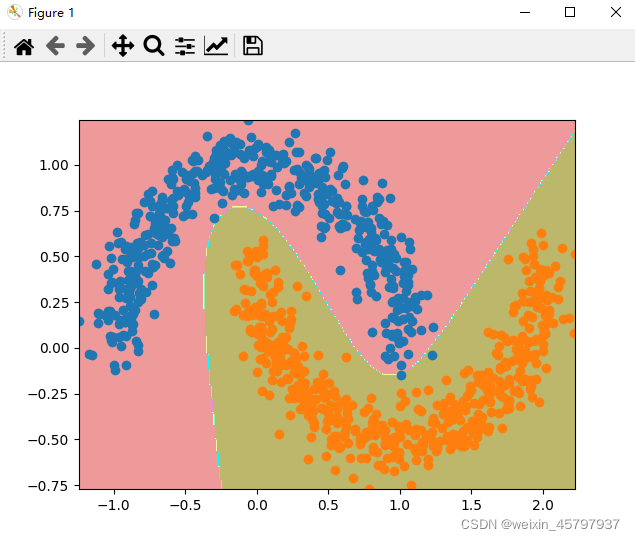







 该博客介绍了如何实现一个多层感知机(MLP)分类器,包括激活函数(Sigmoid和Tanh)、反向传播算法以及小批量梯度下降的优化。代码展示了MLP在二维数据集上的决策边界绘制,并通过调整超参数(如层数、迭代次数和学习率)来适应数据。
该博客介绍了如何实现一个多层感知机(MLP)分类器,包括激活函数(Sigmoid和Tanh)、反向传播算法以及小批量梯度下降的优化。代码展示了MLP在二维数据集上的决策边界绘制,并通过调整超参数(如层数、迭代次数和学习率)来适应数据。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











