






# 导入库:KNeighborsClassifier
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
%matplotlib inline
# 导入sklearn自带数据集
from sklearn import datasets
import pandas as pd
导入文件路径
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\KNNTest"
读取npy文件
x_train=np.load(path+"\\"+"x_train.npy") #数据
x_train.shape

x_train
y_train=np.load(path+"\\"+"y_train.npy") #数据
y_train.shape
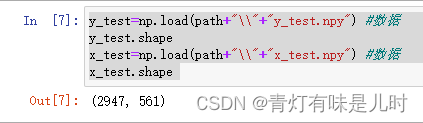
y_test=np.load(path+"\\"+"y_test.npy") #数据
y_test.shape
x_test=np.load(path+"\\"+"x_test.npy") #数据
x_test.shape
人类的动作有以下几种
label={1:"walking",
2:"walking up",
3:"walking down",
4:"sitting",
5:"standing",
6:"laying"}
看看有几种结果
pd.Series(y_train).unique() #y的结果
y_train
x_train[0]
x_train[0].shape
knn=KNeighborsClassifier(100) #计算周围100个点
knn.fit(x_train,y_train)#训练数据
knn.predict(x_test[::100])#预测以100为间隔的点0 100 200...
y_test[::100]
knn.score(x_test,y_test)
y_new=knn.predict(x_test) #预测的结果
(y_new == y_test).sum()
2611/len(y_test)

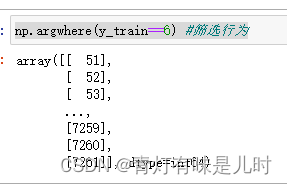
np.argwhere(y_train==6) #筛选行为
plt.subplot: plt.subplot(2,3,1)也可以简写plt.subplot(231)表示把显示界面分割成2*3的网格。其中,第一个参数是行数,第二个参数是列数,第三个参数表示图形的标号。
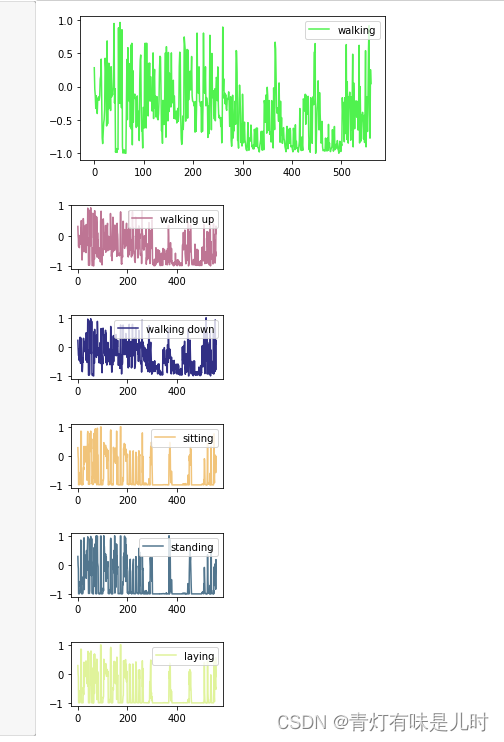
# 78,162,640,29,0,7260 分别对应6种行为抽样数据
x=[78,152,640,29,0,7260]
plt.figure(figsize=(12,9))
for i,r in enumerate(x):
plt.subplot(3,2,(i+1))
#取出动作对应数据
data=x_train[r]
color=np.random.rand(3)
plt.plot(data,c=color,label=label[i+1])
plt.legend()
plt.show()
ren.m是一个模型,可以发现数据才是关键,才能训练出好的模型
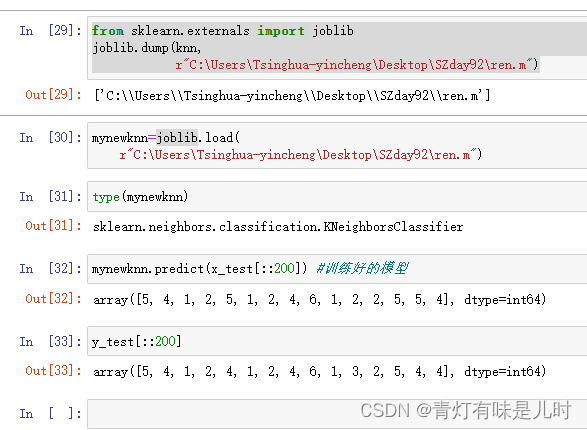
from sklearn.externals import joblib
joblib.dump(knn,
r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\ren.m")
mynewknn=joblib.load(
r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\ren.m")
type(mynewknn)
mynewknn.predict(x_test[::200]) #训练好的模型
y_test[::200]
手写训练
import pandas as pd
from sklearn.decomposition import PCA #特征处理
from sklearn.neighbors import KNeighborsClassifier #分类器
import time
if __name__ =="__main__":
train_num=20000 #训练的数据
test_num=30000 #测试的数据
data=pd.read_csv("train.csv")#读取数据
print(data)
train_data=data.values[0:train_num,1:] #抓取训练数据
train_label=data.values[0:train_num,0] #训练的结果
test_data=data.values[train_num:test_num,1:] #测试的数据
test_label = data.values[train_num:test_num, 0]#测试的结果
start=time.time()
#pca特征训练 whiten=True白化处理 n_components特征
pca=PCA(n_components=0.7,whiten=True)
train_x=pca.fit_transform(train_data) #数据预处理
test_x=pca.fit_transform(test_data)
knn=KNeighborsClassifier(n_neighbors=10)
knn.fit(train_x,train_label) #训练
pre=knn.predict(test_x) #预测
acc= (pre==test_label).sum()/len(test_label)
end=time.time()
print("准确率",acc,"time",end-start)
数字手写识别
# 导入库:KNeighborsClassifier
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
%matplotlib inline
# 导入sklearn自带数据集
from sklearn import datasets
import pandas as pd
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\KNNTest\datanumber\0"
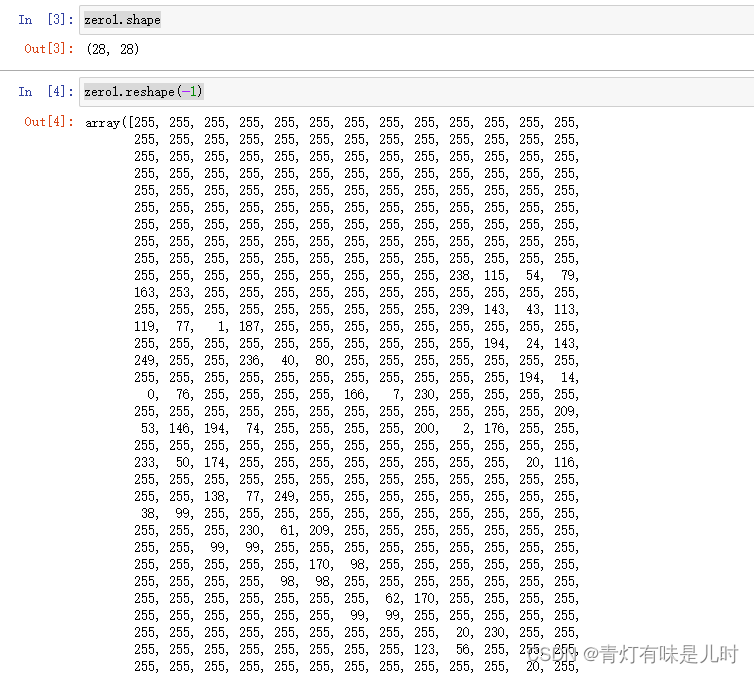
zero1=plt.imread(path+"\\0_497.bmp") #读取图片,转化数组
zero1

zero1.shape
zero1.reshape(-1)#压缩成一维
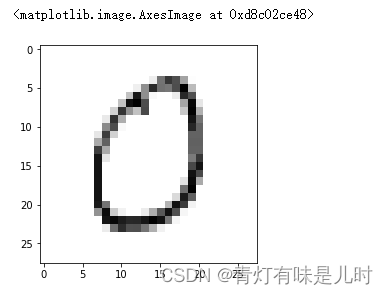
plt.imshow(zero1,cmap="gray")
x_train=[]
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\KNNTest\datanumber\0"
for i in range(1,501):#读取500图片,成为一个数组,500元素
x_train.append(plt.imread(path+"\\0_%d.bmp"%(i)))
X_train=[]
Y_train=[]
X_test=[]
Y_test=[]
path=r"xxxxxxxxx"
#读取数据,加入训练集合与测试集合
for i in range(10):#就是0-9这10个数字
for j in range(1,501):#每个里面有的数据
if j<480:#前面是训练
X_train.append(plt.imread(path+"\\%d\\%d_%d.bmp"%(i,i,j)).reshape(-1))
Y_train.append(i)
else:
X_test.append(plt.imread(path+"\\%d\\%d_%d.bmp"%(i,i,j)).reshape(-1))
Y_test.append(i)
X_train = np.array(X_train)
Y_train = np.array(Y_train)
X_test=np.array(X_test)
Y_test = np.array(Y_test)
X_train.shape
X_test.shape

n=np.random.randint(1,210)
num=X_test[n].reshape((28,28))
plt.imshow(num,cmap="gray")
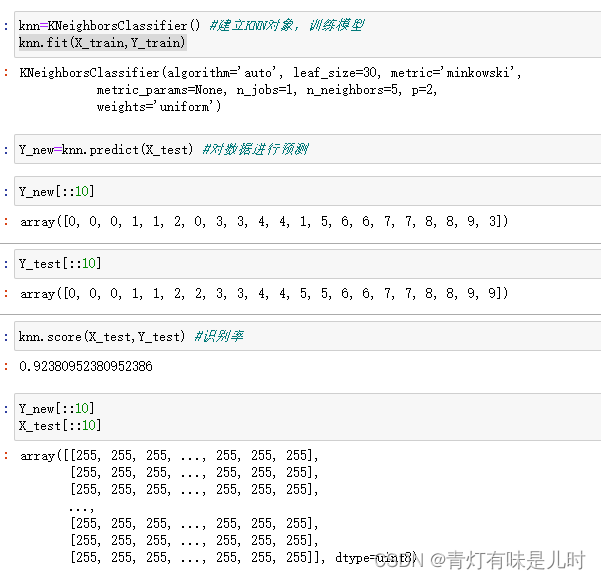
knn = KNeighborsClassifier()#建立KNN对象,训练模型
knn.fit(X_train,Y_train)
Y_new = knn.predict(K_test)
Y_new[::10]#0 10 20 30...
Y_test[::10]
knn.score(X_test,Y_test)#识别率
Y_new[::10]
X_test[::10]
plt.figure(figsize=(12,15))
im_datas=X_test[::10]
im_target=Y_test[::10]
im_predict=Y_new[::10]
for i in range(20):
plt.subplot(5,5,(i+1))
plt.imshow(im_datas[i].reshape((28,28)))
plt.title("predict:%d\n"%(im_predict[i])+"true:%d"%(im_target[i]))
plt.imsave("xxxxxxxx",zero1) #数组保存为图片

KNN测试
import pandas as pd
import sklearn
from sklearn import datasets,linear_model
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_predict
import ML
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday92\KNNTest\dat\iris_"
x_train=pd.read_csv(path+"xtrain.csv",index_col=False)
y_train=pd.read_csv(path+"ytrain.csv",index_col=False)
x_test=pd.read_csv(path+"xtest.csv",index_col=False)
y_test=pd.read_csv(path+"ytest.csv",index_col=False)
#mx=ML.mx_knn(x_train.values,y_train.values) #创造KNN
mx=ML.mx_dtree(x_train.values,y_train.values)
y_new=mx.predict(x_test.values) #预测
print(y_new)
print(y_test.values.reshape(-1))
print(((y_new==y_test.values.reshape(-1)).sum())/len(y_test.values))
















 4708
4708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











