






facenet源码
facenet精简版
参考博客
论文翻译
预训练模型下载
密码:12mh
1.训练自己的数据
先把我们所用到的代码说一下,这里我选择的是精简版的代码,所用到的代码主要是train_tripletloss和classifier,但不是其余没有比如facenet.py,lfw.py等等是需要被调用的。
首先我们需要准备好数据集,这个数据集要求的尺寸是160*160,可以是非人脸数据,然后放到指定的文件夹(在程序中可以自己选定放在哪,也可以和我选定一样)。
这里将主要的修改代码的位置贴出来:
一般来讲需要我们做的就是修改自己的路径问题,看train_tripletloss部分代码中的相应注释:
def parse_arguments(argv):
parser = argparse.ArgumentParser()
parser.add_argument('--logs_base_dir', type=str,
help='Directory where to write event logs.', default='./logs/facenet')#~/logs/facenet日志路径,运行后会在当前文件夹下生产日志文件
parser.add_argument('--models_base_dir', type=str,
help='Directory where to write trained models and checkpoints.', default='./models/facenet')#~/models/facenet生成模型的位置,训练完后会在当前文件夹下models/facenet生成几个ckpt文件的模型
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
parser.add_argument('--pretrained_model', type=str,
help='Load a pretrained model before training starts.'
#default = './weight_decay')#.',default='模型所在路径'
,default=r'D:\research\understand_facenet-master\understand_facenet\20170512-110547')#把之前百度网盘下载好的预训练模型放到自己的路径下
parser.add_argument('--data_dir', type=str,
help='Path to the data directory containing aligned face patches.',
# default='~/datasets/casia/casia_maxpy_mtcnnalign_182_160')
default = r'D:\research\understand_facenet-master\understand_facenet\my_dataset\quexian')#这个很重要,就是我们自己数据的位置,
#在quexian这个文件夹下面还有几个文件夹,每个文件夹的名称代表一类,
#如果去看lfw数据集就可以看出,他们每个文件夹代表的是人名。
parser.add_argument('--model_def', type=str,
help='Model definition. Points to a module containing the definition of the inference graph.',
default='models.inception_resnet_v1')#models.inception_resnet_v1
parser.add_argument('--max_nrof_epochs', type=int,
help='Number of epochs to run.', default=500)#500
parser.add_argument('--batch_size', type=int,
help='Number of images to process in a batch.', default=3)#90
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
parser.add_argument('--people_per_batch', type=int,
help='Number of people per batch.', default=4)#45每批次抽取多少人
parser.add_argument('--images_per_person', type=int,
help='Number of images per person.', default=15)#40#每人抽取多少张
parser.add_argument('--epoch_size', type=int,
help='Number of batches per epoch.', default=100)#批次训练1000
parser.add_argument('--alpha', type=float,
help='Positive to negative triplet distance margin.', default=0.2)
parser.add_argument('--embedding_size', type=int,
help='Dimensionality of the embedding.', default=128)
parser.add_argument('--random_crop',
help='Performs random cropping of training images. If false, the center image_size pixels from the training images are used. ' +
'If the size of the images in the data directory is equal to image_size no cropping is performed', action='store_true')
parser.add_argument('--random_flip',
help='Performs random horizontal flipping of training images.', action='store_true')
parser.add_argument('--keep_probability', type=float,
help='Keep probability of dropout for the fully connected layer(s).', default=1.0)
parser.add_argument('--weight_decay', type=float,
help='L2 weight regularization.', default=0.0)
parser.add_argument('--optimizer', type=str, choices=['ADAGRAD', 'ADADELTA', 'ADAM', 'RMSPROP', 'MOM'],
help='The optimization algorithm to use', default='ADAGRAD')
parser.add_argument('--learning_rate', type=float,
help='Initial learning rate. If set to a negative value a learning rate ' +
'schedule can be specified in the file "learning_rate_schedule.txt"', default=0.1)
parser.add_argument('--learning_rate_decay_epochs', type=int,
help='Number of epochs between learning rate decay.', default=100)
parser.add_argument('--learning_rate_decay_factor', type=float,
help='Learning rate decay factor.', default=1.0)
parser.add_argument('--moving_average_decay', type=float,
help='Exponential decay for tracking of training parameters.', default=0.9999)
parser.add_argument('--seed', type=int,
help='Random seed.', default=666)
parser.add_argument('--learning_rate_schedule_file', type=str,
help='File containing the learning rate schedule that is used when learning_rate is set to to -1.', default='data/learning_rate_schedule.txt')
# Parameters for validation on LFW
parser.add_argument('--lfw_pairs', type=str,
help='The file containing the pairs to use for validation.', default='data/pairs.txt')
parser.add_argument('--lfw_file_ext', type=str,
help='The file extension for the LFW dataset.', default='png', choices=['jpg', 'png'])
parser.add_argument('--lfw_dir', type=str,
help='Path to the data directory containing aligned face patches.', default='')
parser.add_argument('--lfw_nrof_folds', type=int,
help='Number of folds to use for cross validation. Mainly used for testing.', default=10)
return parser.parse_args(argv)
所用环境主要如下:

安装配置搭建好后,直接运行会在恢复模型的位置输入,输出的错误,无法顺利加载模型:这里需要简单修改:如下‘原始的’未原来的语句,注释掉后,改为’修改的‘语句。

这里面有几个参数比较重要;按照原论文所说images_per_person乘-people_per_batch为1800张图片,但是我们没有那么多数据,我自己只有5类数据,每类不超过100张,people_per_batch这个参数不要超过自己的类别,会报错,原文中的batchsize是90,用1800除以90得20;
因此我在设置时选择的是15*4,batchsize=3,这样可以满足原论文的nrof_batches,默认是1800/90=20批次的要求。
在这里最主要的就是选择一个合适的三元组:三元组的原理就是把学习到的特征映射成距离去不断训练。
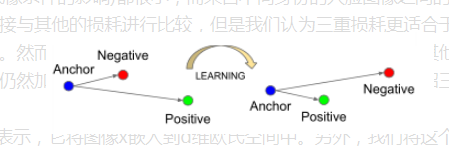
这里面的Anchor就是随机选择的一类,然后positive是选择一个和Anchor相同的一类,Negative是选择和其不同的一类。这样就构成了三元组。但是我们要尽可能的去选择和Anchor最不像的一个postive,选择一个和Anchor最像的一个Negative这样才能不断的通过训练,最后去拉近相同一类的距离,疏远不同一类的距离。
2.分类
这里面用到的代码是clasifier.py文件,可以通过刚才训练好的模型与自己的小数据集训练一个小的分类器,其原理就是利用之前训练所提取出的特征向量利用支持向量机进行分类,下面贴出主要更改的位置:
def parse_arguments(argv):
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, choices=['TRAIN', 'CLASSIFY'],
help='Indicates if a new classifier should be trained or a classification ' +
'model should be used for classification', default='CLASSIFY')#CLASSIFY更改模式,先TRAIN,运行后再CLASSIFY
parser.add_argument('--data_dir', type=str,
help='Path to the data directory containing aligned LFW face patches.',
default = r'D:\research\understand_facenet-master\understand_facenet\my_dataset\quexian')#数据集
parser.add_argument('--model', type=str,
help='Could be either a directory containing the meta_file and ckpt_file or a model protobuf (.pb) file',
default=r'D:\research\understand_facenet-master\understand_facenet\models\facenet\20200519-215056')#刚才训练好的模型注意不是最开始的百度网盘模型
parser.add_argument('--classifier_filename',
help='Classifier model file name as a pickle (.pkl) file. ' +
'For training this is the output and for classification this is an input.',
default='D:/research/understand_facenet-master/understand_facenet/pick/classifier.pkl')#运行TRAIN时会生成一个pkl文件,以备分类时用
parser.add_argument('--use_split_dataset',
help='Indicates that the dataset specified by data_dir should be split into a training and test set. ' +
'Otherwise a separate test set can be specified using the test_data_dir option.', action='store_true')
parser.add_argument('--test_data_dir', type=str,
help='Path to the test data directory containing aligned images used for testing.')
parser.add_argument('--batch_size', type=int,
help='Number of images to process in a batch.', default=3)
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
parser.add_argument('--seed', type=int,
help='Random seed.', default=666)
parser.add_argument('--min_nrof_images_per_class', type=int,
help='Only include classes with at least this number of images in the dataset', default=5)
parser.add_argument('--nrof_train_images_per_class', type=int,
help='Use this number of images from each class for training and the rest for testing', default=45)
return parser.parse_args(argv)
它有两种模式,TRAIN和CLASSIF即训练和分类两种模式,先进行TRAIN生成一个pkl文件,然后再运行CLASSIF模式去分类.
如果好奇pkl中存储的是什么我们可以用程序打开看一下:
import pickle
fr = open(r'D:\research\understand_facenet-master\understand_facenet\pick\classifier.pkl','rb') #open的参数是pkl文件的路径
inf = pickle.load(fr) #读取pkl文件的内容
print(inf)
fr.close()

这里面还是有两个参数很重要,min_nrof_images_per_class和nrof_train_images_per_class,前者还是不要超过自己的类别数目,后者在不报错的情况下尽可能大一些,从小向大依次试验的去调,因为运行时间很快,可以多做几次试验,如果顺利,精度会不断增加。这个参数的具体意思就是每一类用多少数据去训练,剩下的就是用来测试的数据,因此当然训练数据越多越好一些,一般8:2即可,然后可以发现训练和分类的打印数据显示加和就是你的一共放入数据的数目。
训练模式:

分类模式:
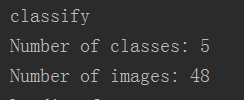
可以看出176+48就是我的数据集数目,这里通过不断的调整参数,使训练模式的图片要尽可能的多于分类模式的图片,这样分类的效果会越来越好。
数据的制作很简单:
由于同样需要数据的尺寸是160*160,这里提一下可以去resize也可以自己截图
最后说明一下,如果在训练过程中有什么错误很可能就是库的问题,更换一下应该会有所解决,欢迎大家一起讨论。
分类结果。
















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









