







大白话讲解三元组triplet损失函数及源码(FaceNet)
对于Facenet进行人脸特征提取,算法内容较为核心和比较难以理解的地方在于三元损失函数Triplet-loss。此损失函数原理比较简单,但是如何实施及操作就有点难以理解,本篇博客希望能够以大白话讲解此损失函数,使得刚接触此损失函数的人能够更好的理解。
- 首先我们需要明确一下几点:
(1)在深度学习训练中,我们需要尽可能的学习训练难样本,也即hard,为什么需要尽可能学习这些呢?首先这些是对损失影响比较大,如果我们学习了很多对损失函数影响比较小的样本其实效果不太好也浪费资源,比如在正负样本不均衡时,负样本很多,如果一直学习负样本的话,训练起来对损失影响比较小,所以我们会采取一些措施,比如何大神的focal loss 或者对正负样本sample。此外类似于支持向量机,我们不仅要把正负样例分开还要把最难分的样例分开。在此三元组损函数中的hard也即这个意思。
(2)作者的三元组样例是在mini_batch中找的。 - triplet-loss(三元组损失函数)的思想非常简单:通过学习使得类别内部的样本距离小于不同类别样本的距离即可。具体效果即为下图所示:

- 数学表示式是什么?
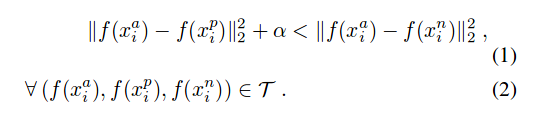
进一步的损失函数变为如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









