







文章目录
前言
今天笔者正式接触到了NumPy,快速上手NumPy其实不多难,网上也有海量的资源可供我们去认真学习;在这里笔者就简单介绍一下NumPy(建议最好使用jupyter notebook)😊
一、NumPy是什么?
NumPy是一个为Python提供的高性能向量、矩阵和高维数据结构的科学计算包(也称为程序包或者程序库)。在之后我们用到的数据科学或者机器学习的包,都在一定程度上依赖NumPy,在之后的深度学习中的张量运算基本上都可以借助NumPy来完成。在这里我只是把它当成一个高效的运算工具。在这里笔者就简单的介绍一个NumPy这个强大的运算工具。
二、NumPy
1.引入
可能有人要说python中list不就支持数组的操作嘛,为什么还要用NumPy呢?那么下面我就举一个简单的小例子来对比一个list和NumPy。
import random
import time
import numpy as np
python_list = []
for i in range(100000000):
python_list.append(random.random())
ndarray_list = np.array(python_list)
# pythonlist求和
t1 = time.time()
a = sum(python_list)
t2 = time.time()
d1 = t2 - t1 # 用list执行完成时间
# ndarray求和
tt1 = time.time()
b = np.sum(ndarray_list)
tt2 = time.time()
d2 = tt2 - tt1 # 用NumPy执行完成时间
print(f"list执行的时间:{d1}。")
print(f"NumPy执行的时间:{d2}。")
运行结果:
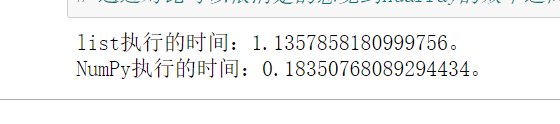
通过对比可以很清楚的感觉到ndarray的效率明显高于原生的list
这就是我们为什么使用NumPy的原因。🙂
2.NumPy的优势
通过上面引入我们可以看到ndarray的计算速度要快很多,节约了时间;
在之后的机器学习中,机器学习最大特点就是大量的数据运算,
如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。
NumPy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于python中的嵌套列表;
当数组越大,NumPy的优势就越明显。
3.NumPy的简单使用
NumPy的使用其实就是导入numpy模块就可以使用NumPy了。
import numpy as np
4.NumPy的属性
| 属性 | 作用 |
|---|---|
| shape | 显示数组维度(以元组形式显示) |
| ndim | 显示数组维数 |
| size | 显示数组中元素数量 |
| dtype | 显示数组元素的类型 |
| itemsize | 显示数组元素的长度(以字节形式展示) |
(1).shape
显示出行数和列数(以元组的形式呈现)
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
score.shape # 它会显示出行数和列数(以元组的形式呈现)(8, 5)
运行结果:

这是一个二维数组,元组中第一个代表的是有8行,第二个代表的是有5列;
当然我把它理解成有8个一维数组(每一个有5个元素)。
(2).ndim
显示出数组的维度
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
score.ndim # 它会显示出维度这个是2维
运行结果:

这是一个二维数组,所以调用ndim它会显示出2。
其实看有多少个外层嵌套的中括号,有几个就是几维数组
(3).size
显示数组中元素的数量
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
score.size # 数组中元素数量
运行结果:

其实就是维度的乘积,这是一个二维数组(8, 5):8 * 5 == 40;所以说有40个。
(4).dtype
显示出数组中元素的类型
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
score.dtype # 会显示数组元素的类型这里是int型
运行结果:

这里数组元素都是int型。
(5).itemsize
显示出数组元素的长度。
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
score.itemsize # 会显示出一个数组元素的长度(字节形式展现)int32就是4个字节
这里数组元素都是int32型,占4个字节。
属性还有很多,这里都不在详细描述。
5.NumPy的形状
ndarry有很多形状,比如一位数组,二维数组等等。
我们可以调用array来创建数组,其中嵌套使用[]来控制维度。
# 创建不同形状的数组
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([1, 2, 3, 4])
c = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(f"a 的维度:{a.ndim}")
print(f"b 的维度:{b.ndim}")
print(f"c 的维度:{c.ndim}")
运行结果:
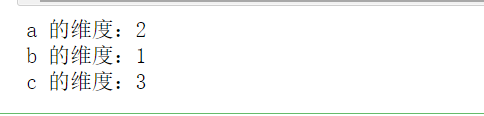
这样我们在创建数组的时候通过嵌套[]可以创建不同维度的数组。
在创建数组的时候我们可以显示的调用dtype属性设置数组元素的类型。
# 创建数组可以指定类型
import numpy as np
a = np.array([1.1, 2.2, 3.3], dtype="float32") # 指定类型为float32
print(f"a 数组的元素类型是:{a.dtype}")
运算结果:

6.NumPy的基本操作
(1).生成数组的方法
1、生成0和1
np.zeros(shape)
np.ones(shape)
2、从现有数组中生成
np.array()
np.copy() 深拷贝
np.asarray() 浅拷贝
3、生成固定范围的数组
np.linspace()
例子生成0-10区间端100个数:np.linspace(0, 10, 100)
[0, 10] 100个元素(等距离)
np.arange()
range(a, b, c)
[a, b) c步长
4、生成随机数组
分布状况-直方图
①.生成0和1的数组
数组中的元素全为0或者全为1
1、生成数组中元素全为0:
以下几种方法都有效:
参数可以是元组、列表、shape属性(控制维度),可以在生成的时候设置元素的类型。
np.zeros([3, 4])
np.zeros((3, 4))
np.zeros(shape=(3, 4), dtype="float32")
2、生成数组中元素全为1(同理):
np.ones([3, 4])
np.ones((3, 4))
np.ones(shape=(3, 4), dtype="float32")
# 生成0的数组
import numpy as np
# np.zeros([3, 4])
# np.zeros((3, 4))
np.zeros(shape=(3, 4), dtype="float32")
运行结果:
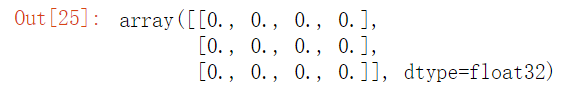
# 生成1的数组
import numpy as np
np.ones(shape=[2, 3], dtype=np.int32)
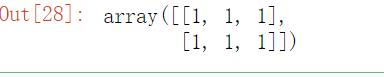
②.从现有数组生成
顾名思义就是从现有存在的数组中生成。
1、np.array() 创建数组
2、np.copy() 深拷贝
3、np.asarray() 浅拷贝
深拷贝和浅拷贝有什么区别呢?我们先看两个例子。
之前我们创建一个score数组我们就可以调用array直接生成一个一模一样的数组。
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
data1 = np.array(score)
data1
运行结果:

# 浅拷贝
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
data2 = np.asarray(score)
data2
运行结果:

我们可以看到这个浅拷贝与原数组一模一样。
但是如果我们尝试修改原数组中某个元素的值又会怎样呢?
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
data2 = np.asarray(score)
score[0 ,0] = 100 # 找到第四行第二列的那个元素并重新复制
data2
运行结果:

发现值被刚刚我们赋值的那个值覆盖掉了。
我们再来看深拷贝copy
# 深拷贝copy
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
data2 = np.copy(score)
data2
运行结果:

和原数组一样,同样的我们也对原数组进行赋值。
# 深拷贝copy
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
data2 = np.copy(score)
score[0, 0] = 100
data2
运行结果:

我们发现数组中那个元素并没有被我们刚刚赋值的那个值覆盖掉。
深拷贝与浅拷贝区别:
深拷贝:其实就是赋值的时候,不把同一个内存对象的引用赋值给另一个变量,令两个变量所指向的对象不一样,更改值的时候不相互影响,就是上面第二个例子,赋值后并没有改变。
浅拷贝:其实就是引用的对象是同一个。
我们可以通过id()方法来查看对象的地址
# 通过id方法来查看原数组,深拷贝和浅拷贝经过原数组某个元素赋值后的对象地址
import numpy as np
# 创建数组
score = np.array([
[60, 69, 66, 67, 69],
[76, 96, 89, 67, 61],
[96, 94, 78, 67, 74],
[96, 91, 90, 67, 69],
[76, 67, 75, 67, 86],
[76, 79, 84, 67, 84],
[96, 92, 93, 67, 64],
[85, 65, 83, 67, 80]]
)
arry_qian = np.asarray(score)
score[0 ,0] = 100 # 找到第四行第二列的那个元素并重新赋值
print(f"原数组地址:{id(score)}")
print(f"浅拷贝后地址:{id(arry_qian)}")
print(f"深拷贝后地址:{id(arry_shen)}")
运行结果:

是不是清楚了许多?我们清楚的看到浅拷贝后地址和原来一模一样;
这就说明深拷贝后,他们两个指向的对象不是一样的,内存地址也不一样。
经过copy()后,创建原数组的副本,存储到内存的另一个地址,
然后将这个地址付给这个数组。
而浅拷贝,还是同一个对象,所以内存地址一样。
③.生成固定范围的数组
1、调用np.linspace()可以生成等距离元素的数组区间[]
2、调用np.arange()类似于range(a, b, c)区间[a, b)步长c
两者的区别就是一个是闭区间,一个是左闭右开区间。
import numpy as np
np.linspace(0, 10, 5) # 等距离生成5个(0-10)个数组元素的一维数组
运行结果:

import numpy as np
np.arange(0, 10, 5) # 步长是5又因为区间形式是这样的[)
运行结果:
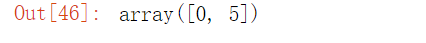
⑤.生成随机数组
有很多方法,这里就简单介绍两种。
1、均匀分布
落在每一组的可能性相等。
random.uniform(low=, high=, size=)
从一个均匀分布 [low, high) 中随机采样,左闭右开。
low: 下界,float类型,默认值为0
high: 上界,float类型,默认值为1
size: 输出样本数目,为int或元组(tuple)类型,缺省时输出一个值。
返回值:ndarray类型,其形状和参数size中的描述一致。
2、正态分布
正态分布就是一个凸函数,驼峰式。
np.random.normal(loc=, scale=, size=)
loc:均值;
scale:标准差(scale越大越矮胖,scale越小,越瘦高)
1、均匀分布,我们用matplotlib来描述一下均匀分布。
# 均匀分布
# 在[-1, 1)区间内随机生成1000000个在[-1,1)之间的数,统计数量.
import numpy as np
import matplotlib.pyplot as plt
a = np.random.uniform(low=-1, high=1, size=1000000) # 区间[-1, 1)
plt.figure(figsize=(20, 8), dpi=80)
plt.hist(a, 1000) # 1000个条形
plt.show()
运行结果:

可以看到每个数量基本一样。
2、正态分布
# 生成正态分布
# 均值1.75,标准差0.1, 100000000个数
import numpy as np
import matplotlib.pyplot as plt
b = np.random.normal(loc=1.75, scale=0.1, size=100000000)
plt.figure(figsize=(20, 8), dpi=80)
plt.hist(b, 1000) # 1000个条形
plt.show()
运行结果:

我们可以直观的看到这就是正态分布。
(2).数组的索引和切片
其实就是list的操作
# 这里以三维数组为例
# 创建一个三维数组
# 需求:索引33
import numpy as np
a1 = np.array([[[1, 2, 3], [4, 5, 6]],[[11, 22, 33], [44, 55, 66]]])
a1[1, 0, 2] # 第二个二维数组中第1个一维数组中第三个元素
运行结果:

(3).修改形状
1、ndarray.reshape() 返回新的ndarray,原始数据没有改变
reshape()函数会重新定义一个数组的形状。但是定义数组必须刚好放得下这些数据
2、ndarray.resize() 没有返回值,对原始的ndarry进行了修改
同reshape(),返回一个修改后的数组,会更改原始数组
resize() 参数中不可以有负数
3、ndarray.T 转置 行变列,列变行
举个简单例子,读者可以感受一下。
1、reshape()
# 原始数组为2行3列
import numpy as np
arry = np.array([
[1, 2, 3],
[4, 5, 6],
])
print(f"arry 维度:{arry.shape}") # (2, 3)
b = arry.reshape(3, 2, -1)
print(f"b 维度:{b.shape}") # (3, 2, 1)
b
# 重新定义成3维数组刚好能放下这些数据元素
运行结果:

2、resize()
# 原始数组为2行3列
import numpy as np
arry = np.array([
[1, 2, 3],
[4, 5, 6],
])
print(f"arry 维度:{arry.shape}")
arry.resize(2, 3, 2, 1) # 参数中不支持负数,并且无返回值;相当于直接在原数组更改
print(f"arry 维度:{arry.shape}")
arry
运行结果:

我们可以看到,数据不够填充的时候它会补零。
3、T
# 原始数组为2行3列
import numpy as np
arry = np.array([
[1, 2, 3],
[4, 5, 6],
])
print(f"arry 维度:{arry.shape}")
b = arry.T
print(f"b 维度:{b.shape}")
b
运行结果:

相当于转置
(4).类型形状
ndarray.astype(type)
ndarray序列化到本地: ndarray.tostring()
# 把float类型修改为int32
import numpy as np
a = np.array([
[1.1, 2.1, 3.1],
[4.1, 5.1, 6.1],
[7.1, 8.1, 9.1]
])
print("a 原来")
print(a)
print("a 现在")
a.astype("int32")
print(a.astype("int32"))
运行结果:

# 把a数组序列化
import numpy as np
a = np.array([
[1.1, 2.1, 3.1],
[4.1, 5.1, 6.1],
[7.1, 8.1, 9.1]
])
a.tostring()
运行结果:

(5).去重
set:这个是之前的方法
np.unique 这个是我们numpy提供的函数
# 实现数组的去重
import numpy as np
temp = np.array([[1, 2, 3, 4], [4, 4, 5, 6]])
np.unique(temp)
运行结果:

7.ndarray运算
1、逻辑运算;
2、统计运算;
3、数组间运算
(1).逻辑运算
运算符;
通用判断函数
np.all(布尔值)
只要有一个False返回False
全部True返回True
np.any()
只要有一个True返回True;
全部False才会返回False
三元运算符:
np.where(布尔值,True的位置的值, False位置的值)
复合逻辑运算
np.logical_and 逻辑与
np.logical_or 逻辑或
import numpy as np
a = np.array([
[1.1, 1.2, 0.3, -1.4],
[1.1, 0.2, -0.3, 0.4],
[3.2, -3.2, 3.1, 0.5]
])
a > 0.5 # 数组中每一个元素都要执行这条逻辑语句,然后返回一个bool
# 最终结果就是一个bool数组
运行结果:

当然也可以用bool来索引
# bool索引
# 需求:找到满足0.5的所有元素,然后对整个进行统一的赋值操作
import numpy as np
a = np.array([
[1.1, 1.2, 0.3, -1.4],
[1.1, 0.2, -0.3, 0.4],
[3.2, -3.2, 3.1, 0.5]
])
a[a > 0.5] = 1.1 # 满足条件,那么就赋值1.1
a[a > 0.5] # 打印
运行结果:

也可以进行切片处理:接上一个代码
# 判断这组数据a[0:2, 0:5]是否全是大于零的
a[0:2, 0:5] > 0
运行结果:

all
只要有一个不满足就返回False
print(np.all(a[0:2, 0:5] > 0)) # 前两行 5列是否都满足要求
a[0:2, 0:5]
运行结果

any
只要有一个满足就返回True
print(np.any(a[0:5, 0:5] > 0)) # 前5行 5列只要有一个满足
a[0:5, 0:5]
运行结果:

三目运算符
类似C++中 表达式 ?结果1:结果0;
例子:a >b ? 0:1
即如果a > b 为True 那么就是1,否则就是0、
import numpy as np
a = np.array([
[1.1, 1.2, 0.3, -1.4],
[1.1, 0.2, -0.3, 0.4],
[3.2, -3.2, 3.1, 0.5]
])
# 三元运算符
# 判断前四个大于零置为1,否则置为0
temp = a[0:4, 0:4]
np.where(temp > 0, 1, 0) # 如果满足要求,值变为1,否则变为0
b = np.where(temp > 0, 1, 0) # 如果满足要求,值变为1,否则变为0
b
运行结果:

逻辑与
相当于 and
import numpy as np
a = np.array([
[1.1, 1.2, 0.3, -1.4],
[1.1, 0.2, -0.3, 0.4],
[3.2, -3.2, 3.1, 0.5]
])
temp = a[0:4, 0:4]
np.logical_and(temp > 0.5, temp < 1) # 满足(0.5, 1)才为True
运行结果:

逻辑或
相当于 or
import numpy as np
a = np.array([
[1.1, 1.2, 0.3, -1.4],
[1.1, 0.2, -0.3, 0.4],
[3.2, -3.2, 3.1, 0.5]
])
temp = a[0:4, 0:4]
np.logical_or(temp > 0.5, temp < -0.5) # 满足任意一个都返回为True
运行结果:

(2).统计运算
要用到axis,axis = 0代表列 axis = 1 代表行统计;
可以用np.函数名或者ndarray.方法名来调用
函数:
min,
max,
sum 和
mean 平均值
median, 中位数
var, 方差
std 标准差
np.函数名
ndarray.方法名
返回位置
import numpy as np
temp = np.array(
[[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6],
[7, 8, 9, 7, 8, 9]])
# axis = 0 表示列, axis = 1表示行
# max
print(f"每一列的最大值:{temp.max(axis=0)}")
print(f"每一行的最大值:{temp.max(axis=1)}")
print(f"每一列的最大值:{np.max(temp, axis=0)}")
print(f"每一行的最大值:{np.max(temp, axis=1)}")
# min
print(f"每一列的最小值:{temp.min(axis=0)}")
print(f"每一行的最小值:{temp.min(axis=1)}")
print(f"每一列的最小值:{np.min(temp, axis=0)}")
print(f"每一行的最小值:{np.min(temp, axis=1)}")
# sum
print(f"每一列的和:{temp.sum(axis=0)}")
print(f"每一行的和:{temp.sum(axis=1)}")
print(f"每一列的和:{np.sum(temp, axis=0)}")
print(f"每一行的和:{np.sum(temp, axis=1)}")
# mean
print(f"每一列的平均值:{temp.mean(axis=0)}")
print(f"每一行的平均值:{temp.mean(axis=1)}")
print(f"每一列的平均值:{np.mean(temp, axis=0)}")
print(f"每一行的平均值:{np.mean(temp, axis=1)}")
# median
# print(f"每一列的中位数:{temp.median(axis=0)}")
# print(f"每一行的中位数:{temp.median(axis=1)}")
# 这个好像报错
# 出现这种:AttributeError: 'numpy.ndarray' object has no attribute 'median'
# 即没有median属性
print(f"每一列的中位数:{np.median(temp, axis=0)}")
print(f"每一行的中位数:{np.median(temp, axis=1)}")
# var
print(f"每一列的方差:{temp.var(axis=0)}")
print(f"每一行的方差:{temp.var(axis=1)}")
print(f"每一列的方差:{np.var(temp, axis=0)}")
print(f"每一行的方差:{np.var(temp, axis=1)}")
# std
print(f"每一列的标准差:{temp.std(axis=0)}")
print(f"每一行的标准差:{temp.std(axis=1)}")
print(f"每一列的标准差:{np.std(temp, axis=0)}")
print(f"每一行的标准差:{np.std(temp, axis=1)}")
# 返回位置
print(f"返回每一列最大值元素的位置:{temp.argmax(axis=0)}")
print(f"返回每一行最大值元素的位置:{temp.argmax(axis=1)}")
print(f"返回每一列最大值元素的位置:{np.argmax(temp, axis=0)}")
print(f"返回每一行最大值元素的位置:{np.argmax(temp, axis=1)}")
运行结果:

(3).数组间运算
1.数组与数的运算
2.数组与数组的运算
①、数组与数的运算
# 1.数组与数的运算
# 数组中每一个元素都与这个数进行运算
import numpy as np
arr = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
arr * 2 # 直接算就行哈哈
# 四则运算都遵循
运行结果:

②、数组与数组之间的运算
+ - * /
必须满足广播机制;
必须满足广播机制。
广播机制:就是为了方便不同形状的ndarray进行数学运算
当操作两个数组时,numpy会逐个比较他们的shape(构成的元组touple)满足:
1.维度相等;
2.shape(其中相对应的一个地方为1);
这里对应的就是两个数组的维度列数相对应(相等)
下面举两个例子来感受一个这个广播机制。
1、正面例子
①、对应维度相等
②、对应维度有1
③、对应维度相等 && 对应维度有1
①、对应维度相等
# 例子1、对应维度相等
# 一个三维数组(2, 4, 3)
#一个一维数组( 3)可以进行运算
#结果数组就是对应的值按照竖着取最大(2, 4, 3)
#只要是可以运算,那么就支持顺序颠倒
import numpy as np
arr1 = np.array([
[
[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]
],
[
[5, 6, 7],
[6, 7, 8],
[7, 8, 9],
[8, 9, 0]
]
])
# print(arr1.shape)
arr2 = np.array([
1, 2, 3
])
# print(arr2.shape)
# 可以进行运算
# 这里就是arr1里面每一个一维数组都和arr2 元素之间对应的做运算
# 下面的都可以试试
arr1 + arr2
# arr1 - arr2
# arr1 * arr2
# arr1 / arr2
运行结果:

②、对应维度有1
# 对应维度有1
import numpy as np
# 一个四维数组arr1(2, 1, 3, 3)
# 一个三维数组arr2( 2, 1, 1)
# 可以运算
# 结果数组(2, 2, 3, 3)
arr1 = np.array([
[
[
[1, 2, 3],
[2, 3, 4],
[3, 4, 5]
]
],
[
[
[4, 5, 6],
[5, 6, 7],
[6, 7, 8]
]
]
])
# print(arr1.shape)
arr2 = np.array([
[
[1]
],
[
[2]
]
])
# print(arr2.shape)
# 此时进行的运算就是在arr1中每一个与arr2一样的数组都要和arr2 元素对应的进行运算
arr1 + arr2
# arr1 - arr2
# arr1 * arr2
# arr1 / arr2
# print((arr1 + arr2).shape)
运行结果:

③、对应维度相等 && 对应维度有1
# 例子3、有对应相等有对应维度有1
# 一个三维数组(2, 3, 1)
# 一个三维数组(2, 1, 3)
# 结果数组(2, 3, 3)
import numpy as np
arr1 = np.array([
[
[1],
[2],
[3]
],
[
[4],
[5],
[6]
]
])
# print(arr1.shape)
arr2 = np.array([
[
[1, 2, 3]
],
[
[4, 5, 6]
]
])
# print(arr2.shape)
arr1 + arr2
# print((arr1 + arr2).shape)
# arr1 - arr2
# arr1 * arr2
# arr1 / arr2
运行结果:

2、反面例子
①、对应维度不等(不等于1)
②、满足对应维度有1,但是不都满足对应维度相等
①、对应维度不等(不等于1)
# 例子1、对应维度不等
import numpy as np
# 一个一维数组(3,)
# 一个一维数组(2,)
# 不能进行运算因为维度不相等
arr1 = np.array([
1, 2, 3
])
# print(arr1.shape)
arr2 = np.array([
1, 2, 3, 4
])
# print(arr2.shape)
arr1 + arr2
运行结果:

②、满足对应维度有1,但是不都满足对应维度相等
# 例子2、满足对应维度有1但是不满足对应维度不等
import numpy as np
# 一个三维数组(3, 4, 3)
# 一个二维数组( 2, 1)
# 不能运算,不满足对应维度相等&&对应维度有1
arr1 = np.array([
[
[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]
],
[
[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4]
],
[
[5, 5, 5],
[6, 6, 6],
[7, 7, 7],
[8, 8, 8]
]
])
# print(arr1.shape)
arr2 = np.array([
[1],
[2]
])
# print(arr2.shape)
arr1 + arr2
运行结果:

数组之间运算必须要满足“广播机制”。
8.矩阵
(1).存储矩阵;
(2).特殊矩阵;
(3).矩阵转置;
(4).矩阵的运算;
(5).矩阵和二维数组区别
(1).存储矩阵
①.可以用ndarray创建二维数组;
②.可以调用np.mat()方法创建矩阵
①.可以用ndarray创建二维数组
# 用ndarray存储矩阵
# 其实就是创建一个二维数组代替矩阵嘛
arr1 = np.array([
[60, 61],
[56, 99],
[77, 78],
[100, 98],
[14, 19],
[33, 78],
[90, 85],
[98, 76]
])
print(arr1.shape)
print(type(arr1))
运行结果:

②.可以调用np.mat()方法创建矩阵
# matrix存储矩阵
arr2 = np.mat([
[60, 61],
[56, 99],
[77, 78],
[100, 98],
[14, 19],
[33, 78],
[90, 85],
[98, 76]
])
print(arr2.shape)
print(type(arr2))
运行结果:

(2).特殊矩阵
①.对角矩阵
②.单位矩阵
③.元素全为0的矩阵
④.元素全为1的矩阵
①.对角矩阵
除对角线含有非0元素,其他位置都是0
通常用D来表示对角矩阵
在numpy提供np.diag函数来构建对角矩阵
# 1、对角矩阵
np.diag([3, 4, 5])
运行结果:

②.单位矩阵
主对角线的元素都是1,其余位置的元素都是0的矩阵
通常用I来表示单位矩阵
单位矩阵可以用np.eye()函数来生成
# 2、单位矩阵
np.eye(3, dtype=int)
运行结果:

③.元素全为0的矩阵
np.zeros()
# 3、元素全为0的矩阵
np.zeros((2, 2))
运行结果:
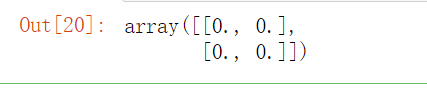
④.元素全为1的矩阵
np.ones()
# 4、元素全为1的矩阵
np.ones((2, 2))
运行结果:

(3).矩阵转置
简单来说就是行变列,列变行
numpy下提供np.transpose(矩阵)
# 矩阵的转置
import numpy as np
a = np.mat([
[2, 4],
[3, 6]
])
print(a)
b = np.transpose(a)
print("矩阵a转置过后")
print(b)
运行结果:

(4).矩阵的运算
①.数乘
②.加减
③.乘
④.点乘(内积)
①.数乘
直接用运算符即可。
# 1、数乘 直接用运算符即可
import numpy as np
a = np.mat([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
a * 5
运行结果:
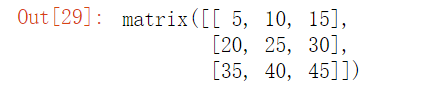
②.加减
保证同类型矩阵:行与行相等,列与列相等;对应元素相加减。
# 2、矩阵的加减
# 就是把两个矩阵中的元素按顺序逐个相加减,即把相同位置上(相同的行与列)的元素进行相加减
# 只有当两个矩阵的行列数相同时即都是(m * n)的矩阵才能够进行相加减
import numpy as np
a = np.mat([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
b = np.ones([3, 3], dtype=int)
print(f"{a.shape}, {b.shape}")
print(a + b)
print(a - b)
运行结果:

③.乘
只有满足第一个矩阵的列数 == 第二个矩阵的行数,那么这两个矩阵才能相乘。
# 矩阵与矩阵的相乘
# 只有满足第一个矩阵的列数 == 第二个矩阵的行数,那么这两个矩阵才能相乘
# 例如:m * k; k * n 那么这两个矩阵就可以进行乘法运算
# 结果矩阵(m, n)
import numpy as np
a = np.mat([
[2, 4],
[1, 2]
])
b = np.mat([
[3],
[1]
])
print(f"a shape is:{a.shape}")
print(f"b shape is:{b.shape}")
res1 = np.matmul(a, b)
# 2 * 3 + 4 * 1 == 10,1 * 3 + 2 * 1 == 5
print(res1) # 矩阵的乘法
运行结果:

④.点乘(内积)
维度相对应元素位置进行乘积
np.multiply(矩阵1, 矩阵2)
import numpy as np
a = np.mat([
[1, 2],
[3, 4]
])
b = np.mat([
[2, 2],
[2, 2]
])
res1 = np.multiply(a, b)
res1
运行结果:
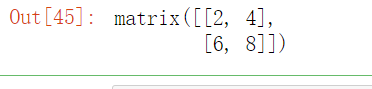
(5).矩阵和二维数组区别
矩阵是二维数组,但是二维数组不是矩阵。
举个简单的例子就是(m, k) * (k, n)
如果是矩阵满足乘法的性质可以运算;
但是如果是二维数组,因为不满足广播机制,所以会报错。
9.数组拼接与分割
1、拼接
2、分割
(1).拼接
①.水平拼接
②.垂直拼接
③.自定义拼接
①.水平拼接
按照列(行不变)水平拼接
hstack() 水平拼接
import numpy as np
# 两个一维数组
a = np.array((1, 2, 3))
b = np.array((2, 3, 4))
np.hstack((a, b)) # [1, 2, 3, 2, 3, 4]
运行结果:

②.垂直拼接
按照行(列不变)垂直拼接
vstack() 垂直拼接
# 两个两行一列的二维数组
a = np.array([
[1],
[2],
[3]
])
b= np.array([
[2],
[3],
[4]
])
np.vstack((a, b)) # 竖着拼接
运行结果:

③.自定义拼接
concatenate() 指定轴定义水平还是垂直
axis控制的是哪一个轴:0:y轴,1:x轴;
但是如果拼接的矩阵维度不相等
比如矩阵1:两行两列
矩阵2:一行两列
你要水平拼接就不能直接拼接
你要先转置矩阵2把行数转成一致的
垂直拼接同理
# 实例:合并
import numpy as np
arr = np.array([
[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]]
)
a = arr[0:2, 0:4] # 代表前两列 前4行
b = arr[4:6, 0:4] # 代表第5列和第6列 前4行
# 水平拼接行不变:放右边
# np.hstack((a, b))
# np.concatenate((a, b), axis = 1)
# 竖直拼接列不变:放下边
# np.vstack((a, b))
np.concatenate((a, b), axis = 0)
运行结果:
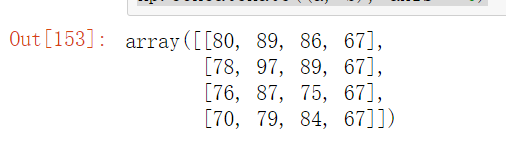
(2).分割
split
import numpy as np
x = np.arange(9) # 创建一个0-8一维数组
# np.split(x, 3) # 将x数组分成3份必须能等分
np.split(x, [3, 5, 6, 9]) # 将x数组按照后面列表索引分割
运行结果:

10.IO操作和数据处理
了解即可。
大多数数据并不是我们自己构造的而是村咋文件当中,需要通过工具获取
但是Numpy其实并不适合用来读取和处理数据,这里简单了解即可
1、Numpy读取;
2、如何处理缺失值
(1).Numpy读取
genfromtxt(文件路径, 指定分隔符)
缺失值即为nan,遇到字符串自动都变成nan了所以我们通常不用numpy来读取
# numpy读取
import numpy as np
data = np.genfromtxt("test.csv", delimiter=",")
data
# 缺失值即为nan,遇到字符串自动都变成nan了所以我们通常不用numpy来读取
运行结果:
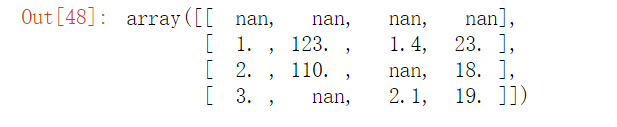
(2).如何处理缺失值
直接删除缺失值
替换/插补求均值或者中位数然后填到缺失值那个位置上
# 如何处理缺失值
# 这里我们用求平均值的方法替换缺失值
# 将每一列的平均值赋值给缺失值
import numpy as np
data = np.genfromtxt("test.csv", delimiter=",")
def get_col_avg(t):
for i in range(t.shape[1]): # 循环列数
# 计算缺失值的个数
# 缺失值不用处理
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]])
if nan_num > 0:
now_col = t[:, i] # 当前列
# 求和
now_sum = now_col[np.isnan(now_col) == False].sum()
# 和 / 个数
now_avg = now_sum / (t.shape[0] - nan_num)
# 赋值给now_col
now_col[np.isnan(now_col)] = now_avg
# 赋值给t,即更新t的当前列
t[:, i] = now_col
return t
get_col_avg(data)
运行结果:

但是还是不建议用NumPy来处理这一块的内容。后面可能会学到Pandas,用它来处理就特别简单了。🙂🙂🙂
总结
这篇文章仅靠笔者目前掌握的知识总结,其实呢NumPy的知识远不止这些;笔者呢还需要更加努力地去了解,去学习,去熟悉这些知识;在这里笔者就希望大家能够快速地了解NumPy这个强大的包。最后,笔者希望大家在学习的道路上,不论自己现在多么的菜,也不要放弃自己的梦想,坚持下去,最后一定会有回报的。加油!😊😊😊

















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











